在Scrapy项目【内外】使用scrapy shell命令抓取 某网站首页的初步情况
Windows 10家庭中文版,Python 3.6.3,Scrapy 1.5.0,
时隔一月,再次玩Scrapy项目,希望这次可以玩的更进一步。
本文展示使用在 Scrapy项目内、项目外scrapy shell命令抓取知乎首页的初步情况,重要的一点是,在项目内抓取时,没有response可用。
在项目【外】执行抓取命令
scrapy shell https://www.zhihu.com
得到结果(部分):因为知乎的反爬虫功能,得到了400错误,访问失败。
INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0}
[]
2018-08-20 09:11:54 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-08-20 09:11:54 [scrapy.core.engine] INFO: Spider opened
2018-08-20 09:11:59 [scrapy.core.engine] DEBUG: Crawled (400) <GET https://www.zhihu.com> (referer: None)
可用对象如下图:存在response!

在项目【内】执行抓取命令
scrapy shell https://www.zhihu.com
注意,项目使用scrapy startproject命令创建,已经在其settings.py中添加了USER_AGENT配置项。
得到结果(部分):多了很多内容,还包括USER_AGENT设置。最后服务器返回200,表示页面访问成功。
INFO: Overridden settings: {'BOT_NAME': 'newssci', 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'NEWSPIDER_MODULE': 'newssci.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['newssci.spiders'], 'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36-480'}
[]
2018-08-20 09:12:23 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-08-20 09:12:23 [scrapy.core.engine] INFO: Spider opened
2018-08-20 09:12:24 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.zhihu.com/robots.txt> (referer: None)
2018-08-20 09:12:24 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://www.zhihu.com>
可用对象如下图:没有response对象!还少了spider对象!
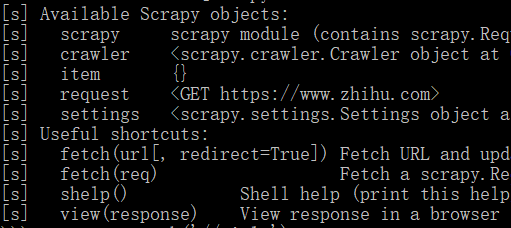
没有response对象,感觉什么也做不了了,网页也无法分析了。
总结
看来,还是需要到 项目外 使用scrapy shell命令来对网页做分析才是。不过,对于这种反爬虫的网站,在命令中添加上USER_AGENT配置项,然后就可以用response来做分析了。
项目外添加USER_AGENT配置项的命令如下:-s
scrapy shell -s USER_AGENT="Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36-480" https://www.zhihu.com
结果如下:发生了一次重定向,所以有302。
INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36-480'}
[scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.zhihu.com/signup?next=%2F> from <GET https://www.zhihu.com>
[scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.zhihu.com/signup?next=%2F> (referer: None)
发现了response对象可用:指明是针对其后的那个200网址的
[s] response <200 https://www.zhihu.com/signup?next=%2F>
使用response对象:获取页面title成功!
>>> response.xpath('//title/text()')
[<Selector xpath='//title/text()' data='知乎 - 发现更大的世界'>]
在Scrapy项目【内外】使用scrapy shell命令抓取 某网站首页的初步情况的更多相关文章
- Shell 命令行统计 apache 网站日志访问IP以及IP归属地
Shell 命令行统计 apache 网站日志访问IP以及IP归属地 我的一个站点用 apache 服务跑着,积攒了很多的日志.我想用 shell 看看有哪些人访问过我的站点,并且他来自哪里. 因为日 ...
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- android adb命令 抓取系统各种 log
getLog.bat: adb root adb remount adb wait-for-device adb logcat -v time > C:\log.txt 在Android中不同的 ...
- Shell脚本 | 抓取log文件
在安卓应用的测试过程中,遇到 Crash 或者 ANR 后,想必大家都会通过 adb logcat 命令来抓取日志定位问题.如果直接使用 logcat 命令的话,默认抓取出的 log 文件包含安卓运行 ...
- 重构后的程序:通过rsync命令抓取日志文件
push.sh #!/bin/bash function push() { local ip=$ local user=$ local password=$ local path=$ local lo ...
- 重构前的程序:通过rsync命令抓取日志文件
基本概况: 我有一台服务器每天每个小时都会生成一个日志文件,这些日志文件会被保留2天,超过2天会被一个程序压缩放到备份目录,日志文件的文件名是有命名要求的,例如:project_log.2013010 ...
- shell爬虫--抓取某在线文档所有页面
在线教程一般像流水线一样,页面有上一页下一页的按钮,因此,可以利用shell写一个爬虫读取下一页链接地址,配合wget将教程所有内容抓取. 以postgresql中文网为例.下面是实例代码 #!/bi ...
- shell脚本抓取网页信息
利用shell脚本分析网站数据 # define url time=$(date +%F) mtime=$(date +%T) file=/abc/shell/abc/abc_$time.log ht ...
- git 常用命令--抓取分支-为自己记录(二)
二:抓取分支: 多人协作时,大家都会往master分支上推送各自的修改.现在我们可以模拟另外一个同事,可以在另一台电脑上(注意要把SSH key添加到github上)或者同一台电脑上另外一个目录克隆, ...
随机推荐
- beta NO1
031602111 傅海涛 1.今天进展 笔记颜色统一,解决笔记的同步性和完整性 2.存在问题 office文档转换的时间问题 3.明天安排 增加新功能和完善之前的功能 4.心得体会 接口真难 031 ...
- Redis分布式锁的实现
前段时间,我在的项目组准备做一个类似美团外卖的拼手气红包[第X个领取的人红包最大],基本功能实现后,就要考虑这一操作在短时间内多个用户争抢同一资源的并发问题了,类似于很多应用如淘宝.京东的秒杀活动场景 ...
- [转帖]Git数据存储的原理浅析
Git数据存储的原理浅析 https://segmentfault.com/a/1190000016320008 写作背景 进来在闲暇的时间里在看一些关系P2P网络的拓扑发现的内容,重点关注了Ma ...
- 【JavaService】使用Java编写部署windows服务
如果你玩windows系统,你对服务这个东西并不会陌生,服务可以帮我们做很多事情,在不影响用户正常工作的情况下,可以完成很多我们需要的需求. 众所周知,微软的visio studio内置的Servic ...
- 【刷题】BZOJ 2151 种树
Description A城市有一个巨大的圆形广场,为了绿化环境和净化空气,市政府决定沿圆形广场外圈种一圈树.园林部门得到指令后,初步规划出n个种树的位置,顺时针编号1到n.并且每个位置都有一个美观度 ...
- 「NOI2018」你的名字
「NOI2018」你的名字 题目描述 小A 被选为了\(ION2018\) 的出题人,他精心准备了一道质量十分高的题目,且已经 把除了题目命名以外的工作都做好了. 由于\(ION\) 已经举办了很多届 ...
- 学习Spring Boot:(十九)Shiro 中使用缓存
前言 在 shiro 中每次去拦截请求进行权限认证的时候,都会去数据库查询该用户的所有权限信息, 这个时候就是有一个问题了,因为用户的权限信息在短时间内是不可变的,每次查询出来的数据其实都是重复数据, ...
- Oracle和SQL SERVER在SQL语句上的差别
Oracle与Sql server都遵循SQL-92标准:http://owen.sj.ca.us/rkowen/howto/sql92F.html,但是也有一些不同之处,差别如下: Oracle中表 ...
- vue单页面应用项目优化总结(转载)
转载自:https://blog.csdn.net/qq_42221334/article/details/81907901这是之前在公司oa项目优化时罗列的优化点,基本都已经完成,当时花了点心思整理 ...
- 【CSS】盒子模型的计算
1.标准盒子的尺寸计算 盒子自身的尺寸:内容的宽高+两侧内边距+两侧边框 盒子在页面中占位的尺寸:内容的宽高+两侧内边距+两侧边框+两侧外边距 <!DOCTYPE html> <ht ...