[过程记录]Centos7 下 Hadoop分布式集群搭建
过程如下:
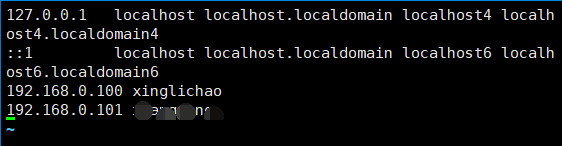
配置hosts
vim /etc/hosts
格式:
ip hostname
ip hostname
设置免密登陆
首先:每台主机使用ssh命令连接其余主机
ssh 用户名@主机名
提示是否连接:输入yes
提示输入密码:输入被请求连接主机的密码
成功过后
就会在本机的~目录下生成 .ssh文件夹
然后在master的主机上进入 ~/.ssh 目录
执行:
ssh-keygen -t rsa
回车回车再回车
得到 id_rsa id_rsa.pub 两个文件
复制一份 id_rsa.pub
cp id_rsa.pub authorized_keys
修改权限
修改.ssh权限
chmod -R 700 .ssh
修改quthorized_keys权限
chmod 600 authorized_keys
尝试ssh连接本机
ssh root@xinglichao

成功免密登陆
然后将 authorized_keys 分发到其他主机
scp ~/.ssh/authorized_keys root@****:~/.ssh
同样尝试ssh连接其余主机,全部可以免密登陆

下载好hadoop并解压到指定文件夹下

master以及其余主机上配置 /etc/profile
首先找到java的安装路径
[root@xinglichao-centos ~]# which java
/usr/bin/java
[root@xinglichao-centos ~]# ls -lrt /usr/bin/java
lrwxrwxrwx. 1 root root 22 9月 25 18:42 /usr/bin/java -> /etc/alternatives/java
[root@xinglichao-centos ~]# ls -lrt /etc/alternatives/java
lrwxrwxrwx. 1 root root 71 9月 25 18:42 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/bin/java

然后编辑profile
vim /etc/profile
添加JAVA_HOME以及HADOOP_HOME

source一下使配置文件生效
source /etc/profile
master上修改hadoop的配置文件:hadoop-env.sh
vim /usr/apache/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
增加内容
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
export HADOOP_HOME=/usr/apache/hadoop-2.7.5

测试hadoop
hadoop
master上修改hadoop中的slaves文件,指定为另外主机名(此处不贴截图了)
vim /etc/hadoop/hadoop-2.7.5/etc/hadoop/slaves
master主机创建name节点文件夹,slaves节点创建data文件夹
master:
mkdir -p hadoop/hadoop-2.7.5/node/dfs/name
slaves:
mkdir -p hadoop/hadoop-2.7.5/node/dfs/data
master中修改与hadoop-env.sh同文件夹下的core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://xinglichao:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.5/node</value>
</property>
</configuration>
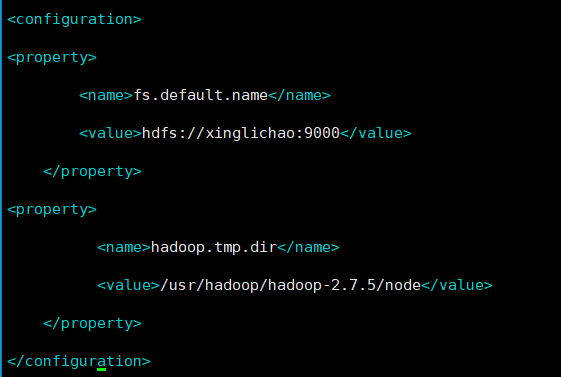
master中修改与hadoop-env.sh同文件夹下的修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hadoop-2.7.5/node/dfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hadoop-2.7.5/node/dfs/data</value>
</property>
</configuration>
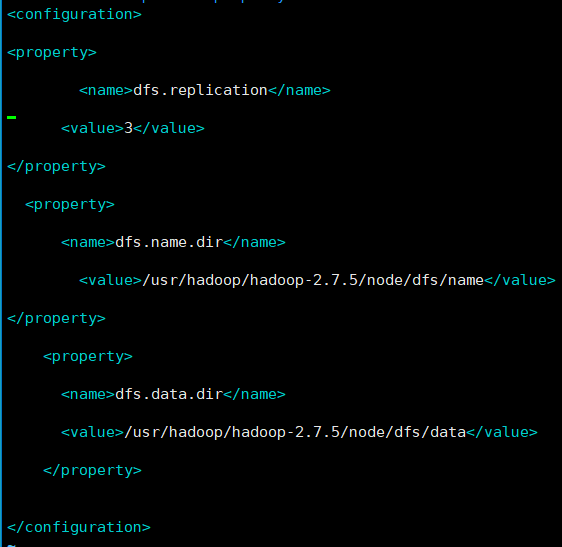
复制mapred-site.xml.template一份为mapred-site.xml,并修改为
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
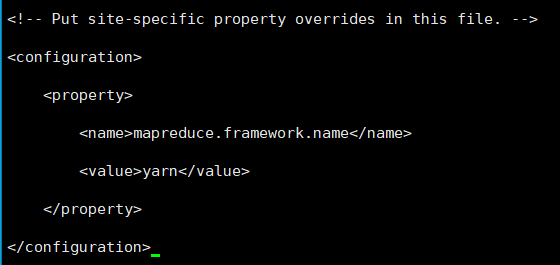
master中修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>xinglichao</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
分发hadoop到其他slaves主机
scp -r /etc/hadoop/hadoop-2.7.5 root@****:/etc/hadoop/
在master上格式化文件系统
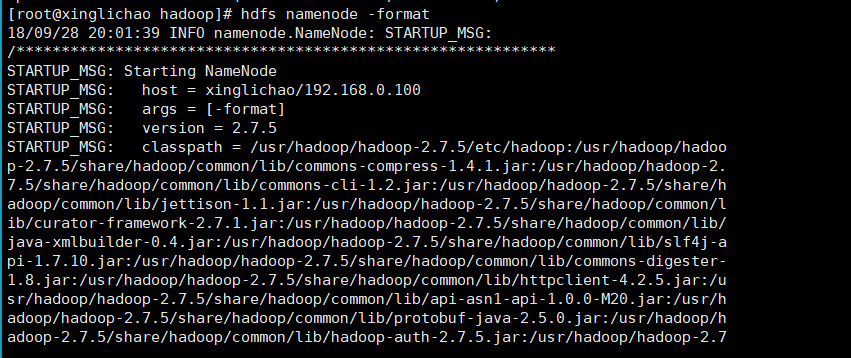
hdfs namenode -format
此时出现问题:找不到java
/usr/hadoop/hadoop-2.7.5/bin/hdfs:行304: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/bin/java: 没有那个文件或目录
再查看下java的安装路径
发现:原来是在上一路径下的jre文件夹下
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/bin/java
修改hadoop中hadoop-env.sh
在JAVA_HOME后添加 /jre (注:此处的路径与上面的不同,理由在下面)

另外:
当我执行 jps命令查看节点运行状态时发现jps不是内部命令,于是更新了java
yum install java-1.8.0-openjdk-devel.x86_64
上图的路径是已经配置了新版本的java路径后的文件
再次格式化文件系统:hdfs namenode -formate
jps一下,至此算是成功了

后续的使用就是创建工程文件夹,上传文件到HDFS,写MapReduce,执行代码(参考:hadoop单机伪分布式与真分布式系统下运行MR代码)
本节完......
[过程记录]Centos7 下 Hadoop分布式集群搭建的更多相关文章
- Centos 7下Hadoop分布式集群搭建
一.关闭防火墙(直接用root用户) #关闭防火墙 sudo systemctl stop firewalld.service #关闭开机启动 sudo systemctl disable firew ...
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- hadoop分布式集群搭建前期准备(centos7)
那玩大数据,想做个大数据的从业者,必须了解在生产环境下搭建集群哇?由于hadoop是apache上的开源项目,所以版本有些混乱,听说都在用Cloudera的cdh5来弄?后续研究这个吧,就算这样搭建不 ...
- Hadoop框架:单服务下伪分布式集群搭建
本文源码:GitHub·点这里 || GitEE·点这里 一.基础环境 1.环境版本 环境:centos7 hadoop版本:2.7.2 jdk版本:1.8 2.Hadoop目录结构 bin目录:存放 ...
- hadoop分布式集群搭建(2.9.1)
1.环境 操作系统:ubuntu16 jdk:1.8 hadoop:2.9.1 机器:3台,master:192.168.199.88,node1:192.168.199.89,node2:192.1 ...
- Hadoop分布式集群搭建_1
Hadoop是一个开源的分布式系统框架 一.集群准备 1. 三台虚拟机,操作系统Centos7,三台主机名分别为k1,k2,k3,NAT模式 2.节点分布 k1: NameNode DataNode ...
- kettle在centos7下部署分布式集群
首先安装三台centos7 ,分别配置好静态ip ssh免密码登录 关闭防火墙 具体步骤这里不多说了 关于centos7配置静态ip大家可以参考:https://www.cnblogs. ...
- centos7下Zookeeper+sheepdog集群搭建
zookeeper 安装命令 yum install zookeeper -y (版本:zookeeper.x86_64 3.4.6-1) yum install zo ...
随机推荐
- 【转】#pragma的用法
在所有的预处理指令中,#Pragma 指令可能是最复杂的了,它的作用是设定编译器的状态或者是指示编译器完成一些特定的动作.#pragma指令对每个编译器给出了一个方法,在保持与C和C++语言完全兼容的 ...
- 【转】四款经典3.7v锂电池充电电路图详解
3.7v锂电池充电电路图(一) 1.锂电池的充电: 根据锂电池的结构特性,最高充电终止电压应为4.2V,不能过充,否则会因正极的锂离子拿走太多,而使电池报废.其充放电要求较高,可采用专用的恒流.恒压充 ...
- 【ARC079F】Namori Grundy
Description 题目链接 大意:给一张基环外向树.要求给每一个点确定一个值,其值为所有后继点的\(\text{mex}\).求是否存在确定权值方案. Solution 首先,对于叶子节点,其权 ...
- 洛谷 P4389 付公主的背包 解题报告
P4389 付公主的背包 题目背景 付公主有一个可爱的背包qwq 题目描述 这个背包最多可以装\(10^5\)大小的东西 付公主有\(n\)种商品,她要准备出摊了 每种商品体积为\(V_i\),都有\ ...
- python---django中自带分页类使用
请先看在学习tornado时,写的自定义分页类:思路一致: python---自定义分页类 1.基础使用: 后台数据获取: from django.core.paginator import Pagi ...
- hdu 5290 Bombing plan
http://acm.hdu.edu.cn/showproblem.php?pid=5290 题意: 一棵树,每个点有一个权值wi,选择点i即可破坏所有距离点i<=wi的点,问破坏所有点 最少需 ...
- 那些年的 网络通信之 UDP 数据报包传输---
下面是 一个多线程,基于 UDP 用户数据报包 协议 的 控制台聊天小程序 import java.io.*; import java.net.*; class Send implements Run ...
- elasticsearch-dump 迁移es数据 (elasticdump)
elasticsearch 部分查询语句 # 获取集群的节点列表: curl 'localhost:9200/_cat/nodes?v' # 列出所有索引: curl 'localhost:9200/ ...
- 第8月第12天 python json.dumps danmu
1.json.dumps return JsonResponse({ 'status': WechatMessage.POST_METHOD_REQUIRED[1], 'status_code': W ...
- 使用 scm-manager 搭建 git/svn 代码管理仓库(二)
主要介绍scm的配置. 1.配置为在Windows服务中启动scm-manager的启动方式有多种,可以在DOS(即命令行CMD模式)中启动,也可以在Windows服务中启动. 下面我们采用Windo ...