踩过无数坑实现的哈夫曼压缩(JAVA)
最近可能又是闲着没事干了,就想做点东西,想着还没用JAVA弄过数据结构,之前搞过算法,就试着写写哈夫曼压缩了。
本以为半天就能写出来,结果,踩了无数坑,花了整整两天时间!!orz。。。不过这次踩坑,算是又了解了不少东西,更觉得在开发中学习是最快的了。
注:代码已上传至github:https://github.com/leo6033/Java_Project
话不多说,进入正题
首先先来讲讲哈夫曼树
哈夫曼树属于二叉树,即树的结点最多拥有2个孩子结点。若该二叉树带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。

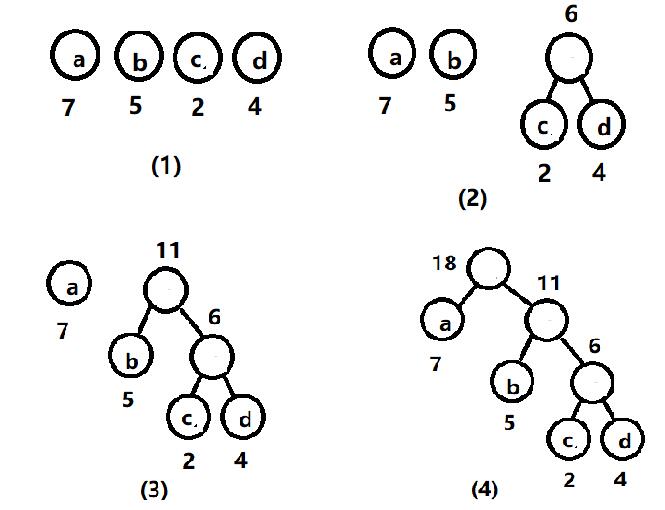
哈夫曼树的构造
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 w1、w2、…、wn,则哈夫曼树的构造规则为:
(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
哈夫曼编码
在数据通信中,需要将传送的文字转换成二进制的字符串,用0,1码的不同排列来表示字符。例如,需传送的报文为“HELLO WORLD”,这里用到的字符集为“D,E,H,L,O,R,W”,各字母出现的次数为{1,1,1,3,2,1,1}。现要求为这些字母设计编码。要区别7个字母,最简单的二进制编码方式是等长编码,固定采用3位二进制,可分别用000、001、010、011、100、101、110对“D,E,H,L,O,R,W”进行编码发送,当对方接收报文时再按照三位一分进行译码。显然编码的长度取决报文中不同字符的个数。若报文中可能出现26个不同字符,则固定编码长度为5。然而,传送报文时总是希望总长度尽可能短。在实际应用中,各个字符的出现频度或使用次数是不相同的,如A、B、C的使用频率远远高于X、Y、Z,自然会想到设计编码时,让使用频率高的用短编码,使用频率低的用长编码,以优化整个报文编码。

此时D->0000 E->0001 W->001 H->110 R->111 L->01 0->02
固定三位时编码长度为30,而时候哈夫曼编码后,编码长度为27,很明显长度缩小了,得到优化。
下面就是代码实现
HuffmanCompress.java
package 哈夫曼; import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.util.Arrays;
import java.util.HashMap;
import java.util.PriorityQueue; public class HuffmanCompress {
private PriorityQueue<HufTree> queue = null; public void compress(File inputFile, File outputFile) {
Compare cmp = new Compare();
queue = new PriorityQueue<HufTree>(, cmp); // 映射字节及其对应的哈夫曼编码
HashMap<Byte, String> map = new HashMap<Byte, String>(); int i, char_kinds = ;
int char_tmp, file_len = ;
FileInputStream fis = null;
FileOutputStream fos = null;
DataOutputStream oos = null; HufTree root = new HufTree();
String code_buf = null; // 临时储存字符频度的数组
TmpNode[] tmp_nodes = new TmpNode[]; for (i = ; i < ; i++) {
tmp_nodes[i] = new TmpNode();
tmp_nodes[i].weight = ;
tmp_nodes[i].Byte = (byte) i;
} try {
fis = new FileInputStream(inputFile);
fos = new FileOutputStream(outputFile);
oos = new DataOutputStream(fos); /*
* 统计字符频度,计算文件长度
*/
while ((char_tmp = fis.read()) != -) {
tmp_nodes[char_tmp].weight++;
file_len++;
}
fis.close();
// 排序,将频度为0的字节放在最后,同时计算除字节的种类,即有多少个不同的字节
Arrays.sort(tmp_nodes);
for (i = ; i < ; i++) {
if (tmp_nodes[i].weight == ) {
break;
}
HufTree tmp = new HufTree();
tmp.Byte = tmp_nodes[i].Byte;
tmp.weight = tmp_nodes[i].weight;
queue.add(tmp);
}
char_kinds = i; if (char_kinds == ) {
oos.writeInt(char_kinds);
oos.writeByte(tmp_nodes[].Byte);
oos.writeInt(tmp_nodes[].weight);
} else {
// 建树
createTree(queue);
root = queue.peek();
// 生成哈夫曼编码
hufCode(root, "", map);
// 写入字节种类
oos.writeInt(char_kinds);
for (i = ; i < char_kinds; i++) {
oos.writeByte(tmp_nodes[i].Byte);
oos.writeInt(tmp_nodes[i].weight);
}
oos.writeInt(file_len);
fis = new FileInputStream(inputFile);
code_buf = "";
while ((char_tmp = fis.read()) != -) {
code_buf += map.get((byte) char_tmp);
while (code_buf.length() >= ) {
char_tmp = ;
for (i = ; i < ; i++) {
char_tmp <<= ;
if (code_buf.charAt(i) == '')
char_tmp |= ;
}
oos.writeByte((byte) char_tmp);
code_buf = code_buf.substring();
}
}
// 最后编码长度不够8位的时候,用0补齐
if (code_buf.length() > ) {
char_tmp = ;
for (i = ; i < code_buf.length(); ++i) {
char_tmp <<= ;
if (code_buf.charAt(i) == '')
char_tmp |= ;
}
char_tmp <<= ( - code_buf.length());
oos.writeByte((byte) char_tmp);
}
oos.close();
fis.close();
} } catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} public void extract(File inputFile, File outputFile) {
Compare cmp = new Compare();
queue = new PriorityQueue<HufTree>(, cmp); int i;
int file_len = ;
int writen_len = ;
FileInputStream fis = null;
FileOutputStream fos = null;
DataInputStream ois = null; int char_kinds = ;
HufTree root=new HufTree();
byte code_tmp;
try {
fis = new FileInputStream(inputFile);
ois = new DataInputStream(fis);
fos = new FileOutputStream(outputFile); char_kinds = ois.readInt();
// 字节只有一种
if (char_kinds == ) {
code_tmp = ois.readByte();
file_len = ois.readInt();
while ((file_len--) != ) {
fos.write(code_tmp);
}
} else {
for (i = ; i < char_kinds; i++) {
HufTree tmp = new HufTree();
tmp.Byte = ois.readByte();
tmp.weight = ois.readInt();
System.out.println("Byte: "+tmp.Byte+" weight: "+tmp.weight);
queue.add(tmp);
} createTree(queue); file_len = ois.readInt();
root = queue.peek();
while (true) {
code_tmp = ois.readByte();
for (i = ; i < ; i++) {
//这里为什么是&128呢?
//我们是按编码顺序走的,1向右,0向左,对于一串byte编码有8位,那最高位就是2^7,就是128
//所以通过位运算来判断该位是0还是1
//之前我想错了,从后面开始走,结果乱码,压缩在这块也卡了好久orz
if ((code_tmp&)==) {
root = root.rchild;
} else {
root = root.lchild;
}
if (root.lchild == null && root.rchild == null) {
fos.write(root.Byte);
++writen_len;
if (writen_len == file_len)
break;
root = queue.peek();
}
code_tmp <<= ;
}
if (writen_len == file_len)
break;
}
}
fis.close();
fos.close(); } catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
} } public void createTree(PriorityQueue<HufTree> queue) {
while (queue.size() > ) {
HufTree min1 = queue.poll();
HufTree min2 = queue.poll();
System.out.print(min1.weight + " " + min2.weight + " "); HufTree NodeParent = new HufTree();
NodeParent.weight = min1.weight + min2.weight;
NodeParent.lchild = min1;
NodeParent.rchild = min2; queue.add(NodeParent);
}
} public void hufCode(HufTree root, String s, HashMap<Byte, String> map) {
if (root.lchild == null && root.rchild == null) {
root.code = s;
System.out.println("节点" + root.Byte + "编码" + s);
map.put(root.Byte, root.code); return;
}
if (root.lchild != null) {
hufCode(root.lchild, s + '', map);
}
if (root.rchild != null) {
hufCode(root.rchild, s + '', map);
} } }
Compare.java
package 哈夫曼;
import java.util.Comparator;
public class Compare implements Comparator<HufTree>{
@Override
public int compare(HufTree o1, HufTree o2) {
if(o1.weight < o2.weight)
return -;
else if(o1.weight > o2.weight)
return ;
return ;
}
}
这里涉及到JAVA中优先对列的重载排序,我之前一直按照C++中的重载来写,结果发现发现压缩后的大小是原文件的3倍!!!!然后还一直以为是压缩过程的问题,疯狂看压缩过程哪里错了,最后输出了下各字符的编码才发现问题,耗了我整整一天TAT。。附上一个对优先队列重载讲解的链接https://blog.csdn.net/u013066244/article/details/78997869
HufTree.java
package 哈夫曼;
public class HufTree{
public byte Byte; //以8位为单元的字节
public int weight;//该字节在文件中出现的次数
public String code; //对应的哈夫曼编码
public HufTree lchild,rchild;
}
//统计字符频度的临时节点
class TmpNode implements Comparable<TmpNode>{
public byte Byte;
public int weight;
@Override
public int compareTo(TmpNode arg0) {
if(this.weight < arg0.weight)
return ;
else if(this.weight > arg0.weight)
return -;
return ;
}
}
test.java
package 哈夫曼;
import java.io.File;
public class test {
public static void main(String[] args) {
// TODO Auto-generated method stub
HuffmanCompress sample = new HuffmanCompress();
// File inputFile = new File("C:\\Users\\long452a\\Desktop\\opencv链接文档.txt");
// File outputFile = new File("C:\\Users\\long452a\\Desktop\\opencv链接文档.rar");
// sample.compress(inputFile, outputFile);
File inputFile = new File("C:\\Users\\long452a\\Desktop\\opencv链接文档.rar");
File outputFile = new File("C:\\Users\\long452a\\Desktop\\opencv链接文档1.txt");
sample.extract(inputFile, outputFile);
}
}
踩过无数坑实现的哈夫曼压缩(JAVA)的更多相关文章
- 赫夫曼树JAVA实现及分析
一,介绍 1)构造赫夫曼树的算法是一个贪心算法,贪心的地方在于:总是选取当前频率(权值)最低的两个结点来进行合并,构造新结点. 2)使用最小堆来选取频率最小的节点,有助于提高算法效率,因为要选频率最低 ...
- 源码编译安装lnmp环境(nginx-1.14.2 + mysql-5.6.43 + php-5.6.30 )------踩了无数坑,重装了十几次服务器才会的,不容易啊!
和LAMP不同的是,LNMP中的N指的是Nginx(类似于Apache的一种web服务软件),并且php是作为一个独立服务存在的,这个服务叫做php-fpm,Nginx直接处理静态请求,动态请求会转发 ...
- 倒排索引PForDelta压缩算法——基本假设和霍夫曼压缩同
PForDelta算法 PForDelta算法最早由Heman在2005年提出,它允许同时对整个chunk数据(例128个数)进行压缩处理.基础思想是对于一个chunk的数列(例128个),认为其中占 ...
- Java实现哈夫曼编码和解码
最近无意中想到关于api返回值加密的问题,譬如我们的api需要返回一些比较敏感或者重要不想让截获者得到的信息,像如果是做原创图文的,文章明文返回的话则有可能被抓包者窃取. 关于请求时加密的方式比较多, ...
- 那些年我们一起踩过的坑(javascript常见的陷阱)
1.object最后一个逗号 定义object直接量或json,最后一个逗号多写了,在ie下会报错,高级浏览器则不会,给只使用chrome调试的同学敲个警钟.踩了无数次这个坑了. 2.自动加分号 ...
- 项目中踩过的坑之-sessionStorage
总想写点什么,却不知道从何写起,那就从项目中踩过的坑开始吧,希望能给可能碰到相同问题的小伙伴一点帮助. 项目情景: 有一个id,要求通过当前网页打开一个新页面(不是当前页面),并把id传给打开的新页面 ...
- web开发实战--弹出式富文本编辑器的实现思路和踩过的坑
前言: 和弟弟合作, 一起整了个智慧屋的小web站点, 里面包含了很多经典的智力和推理题. 其实该站点从技术层面来分析的话, 也算一个信息发布站点. 因此在该网站的后台运营中, 富文本的编辑器显得尤为 ...
- "开发路上踩过的坑要一个个填起来————持续更新······(7月30日)"
欢迎转载,请注明出处! https://gii16.github.io/learnmore/2016/07/29/problem.html 踩过的坑及解决方案记录在此篇博文中! 个人理解,如有偏颇,欢 ...
- 【转载】Fragment 全解析(1):那些年踩过的坑
http://www.jianshu.com/p/d9143a92ad94 Fragment系列文章:1.Fragment全解析系列(一):那些年踩过的坑2.Fragment全解析系列(二):正确的使 ...
随机推荐
- Excel:函数中的万金油:INDEX+SMALL+IF+ROW
很多人在Excel中用函数公式做查询的时候,都必然会遇到的一个大问题,那就是一对多的查找/查询公式应该怎么写?大多数人都是从VLOOKUP.INDEX+MATCH中入门的,纵然你把全部的多条件查找 ...
- python 基础数据类型之list
python 基础数据类型之list: 1.列表的创建 list1 = ['hello', 'world', 1997, 2000] list2 = [1, 2, 3, 4, 5 ] list3 = ...
- Tomcat权威指南-读书摘要系列10
Tomcat集群 一些集群技术 DNS请求分配 TCP网络地址转换请求分配 Mod_proxy_balance负载均衡与故障复原 JDBC请求分布与故障复原
- bzoj千题计划185:bzoj1260: [CQOI2007]涂色paint
http://www.lydsy.com/JudgeOnline/problem.php?id=1260 区间DP模型 dp[l][r] 表示涂完区间[l,r]所需的最少次数 从小到大们枚举区间[l, ...
- python 玩具代码
脚本语言的第一行,目的就是指出,你想要你的这个文件中的代码用什么可执行程序去运行它,就这么简单 #!/usr/bin/python是告诉操作系统执行这个脚本的时候,调用/usr/bin下的python ...
- Python核心编程——Chapter16
好吧,在拜读完<Python网络编程基础>之后,回头再搞一搞16章的网络编程吧. Let‘s go! 16.4.修改书上示例的TCP和UDP客户端,使得服务器的名字不要在代码里写死,要允许 ...
- ASP.Net巧用窗体母版页
背景:每个网页的基本框架结构类似: 浏览网站的时候会发现,好多网站中,每个网页的基本框架都是一样的,比如,最上面都是网站的标题,中间是内容,最下面是网站的版权.开发提供商等信息: 在这些网页中,表头. ...
- ASP.NET MVC3-Music Store中英文教程 [下载]
翻译原文档名: MVC Music Store版本: ASP.NET MVC3概述Mvc Music Store 是一个为WEB开发人员一步一步介绍和解释如何使用MVC和Visual Web开发的应用 ...
- 问题:经典类的对象明明没有__class__属性,却可以调用。
这个问题得深入python源码才能看. class a: pass aa =a() print dir(aa)#aa只有doc和module属性 print aa.__class__#__main__ ...
- 云计算--hbase shell
具体的 HBase Shell 命令如下表 1.1-1 所示: 下面我们将以“一个学生成绩表”的例子来详细介绍常用的 HBase 命令及其使用方法. 这里 grad 对于表来说是一个列,course ...