【慕课网实战】Spark Streaming实时流处理项目实战笔记三之铭文升级版
铭文一级:
Flume概述
Flume is a distributed, reliable,
and available service for efficiently collecting(收集),
aggregating(聚合), and moving(移动) large amounts of log data
webserver(源端) ===> flume ===> hdfs(目的地)
设计目标:
可靠性
扩展性
管理性
业界同类产品的对比
(***)Flume: Cloudera/Apache Java
Scribe: Facebook C/C++ 不再维护
Chukwa: Yahoo/Apache Java 不再维护
Kafka:
Fluentd: Ruby
(***)Logstash: ELK(ElasticSearch,Kibana)
Flume发展史
Cloudera 0.9.2 Flume-OG
flume-728 Flume-NG ==> Apache
2012.7 1.0
2015.5 1.6 (*** + )
~ 1.7
Flume架构及核心组件
1) Source 收集
2) Channel 聚集
3) Sink 输出
Flume安装前置条件
Java Runtime Environment - Java 1.7 or later
Memory - Sufficient memory for configurations used by sources, channels or sinks
Disk Space - Sufficient disk space for configurations used by channels or sinks
Directory Permissions - Read/Write permissions for directories used by agent
安装jdk
下载
解压到~/app
将java配置系统环境变量中: ~/.bash_profile
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
export PATH=$JAVA_HOME/bin:$PATH
source下让其配置生效
检测: java -version
安装Flume
下载
解压到~/app
将java配置系统环境变量中: ~/.bash_profile
export FLUME_HOME=/home/hadoop/app/apache-flume-1.6.0-cdh5.7.0-bin
export PATH=$FLUME_HOME/bin:$PATH
source下让其配置生效
flume-env.sh的配置:export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
检测: flume-ng version
example.conf: A single-node Flume configuration
使用Flume的关键就是写配置文件
A) 配置Source
B) 配置Channel
C) 配置Sink
D) 把以上三个组件串起来
a1: agent名称
r1: source的名称
k1: sink的名称
c1: channel的名称
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = hadoop000
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动agent
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/example.conf \
-Dflume.root.logger=INFO,console
使用telnet进行测试: telnet hadoop000 44444
Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
Event是FLume数据传输的基本单元
Event = 可选的header + byte array
铭文二级:
Flume设计目标:可靠性,扩展性,管理性
官网:flume.apache.org -> Documentation(左栏目) -> Flume User Guide
左栏为目录,较常用的有:
Flume Sources:avro、exec、kafka、netcat
Flume Channels:memory、file、kafka
Flume Sinks:HDFS、Hive、logger、avro、ElasticSearch、Hbase、kafka
注意:每个source、channel、sink都有custom自定义类型
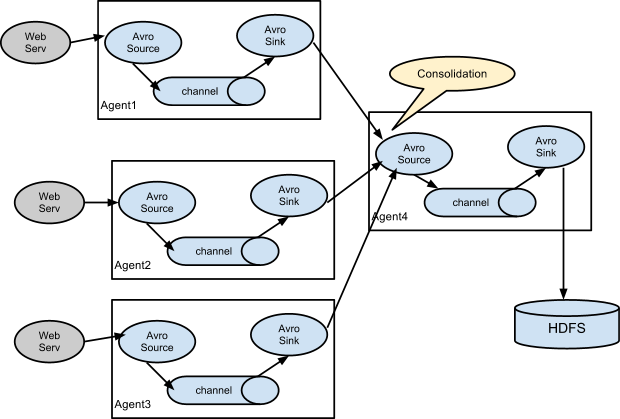
Setting multi-agent flow

Consolidation
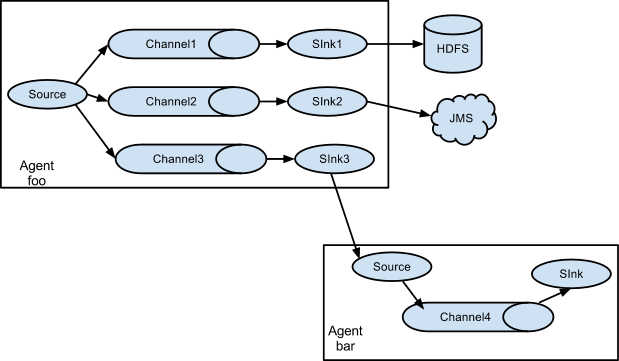
Multiplexing the flow
实战准备=>
1.前置要求为以上铭文一4点,Flume的下载可以在cdh5里wget下来
wget http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.5.0.tar.gz
2.安装jdk,指令:tar -zxvf * -C ~/app/ ,最后勿忘:source ~/.bash_profile
配置cp flume-env.sh.template flume-env.sh ,export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
3.检测是否安装成功:flume-ng version
实战步骤=>
实战需求:从指定的网络端口采集数据输出到控制台
配置文件(创建example.conf于conf文件夹中,主要是看官网!):
1、a1.后面的source、channel、sink、均有"s"
2、后面连接是,sources后面的channel有"s",sink后面的chanel无"s"
启动agent=>
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/example.conf \
-Dflume.root.logger=INFO,console
启动另一终端ssh上,使用telnet进行监听: telnet hadoop000 44444
原本的终端输入内容,可以在此终端接受到
【慕课网实战】Spark Streaming实时流处理项目实战笔记三之铭文升级版的更多相关文章
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十之铭文升级版
铭文一级: 第八章:Spark Streaming进阶与案例实战 updateStateByKey算子需求:统计到目前为止累积出现的单词的个数(需要保持住以前的状态) java.lang.Illega ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记七之铭文升级版
铭文一级: 第五章:实战环境搭建 Spark源码编译命令:./dev/make-distribution.sh \--name 2.6.0-cdh5.7.0 \--tgz \-Pyarn -Phado ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十四之铭文升级版
铭文一级: 第11章 Spark Streaming整合Flume&Kafka打造通用流处理基础 streaming.conf agent1.sources=avro-sourceagent1 ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记二之铭文升级版
铭文一级: 第二章:初识实时流处理 需求:统计主站每个(指定)课程访问的客户端.地域信息分布 地域:ip转换 Spark SQL项目实战 客户端:useragent获取 Hadoop基础课程 ==&g ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十六之铭文升级版
铭文一级: linux crontab 网站:http://tool.lu/crontab 每一分钟执行一次的crontab表达式: */1 * * * * crontab -e */1 * * * ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十五之铭文升级版
铭文一级:[木有笔记] 铭文二级: 第12章 Spark Streaming项目实战 行为日志分析: 1.访问量的统计 2.网站黏性 3.推荐 Python实时产生数据 访问URL->IP信息- ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十二之铭文升级版
铭文一级: ======Pull方式整合 Flume Agent的编写: flume_pull_streaming.conf simple-agent.sources = netcat-sources ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十一之铭文升级版
铭文一级: 第8章 Spark Streaming进阶与案例实战 黑名单过滤 访问日志 ==> DStream20180808,zs20180808,ls20180808,ww ==> ( ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记九之铭文升级版
铭文一级: 核心概念:StreamingContext def this(sparkContext: SparkContext, batchDuration: Duration) = { this(s ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记八之铭文升级版
铭文一级: Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, ...
随机推荐
- 28- foreach里面实现一次遍历两个链表
由于业务需求,要在一个foreach里面实现一次遍历两个链表:后台传来的是连个list: 分别是 <c:set var = "i" value = "0" ...
- pthreads v3下一些坑和需要注意的地方
一.子线程无法访问父线程的全局变量,但父线程可以访问子线程的变量 <?php class Task extends Thread { public $data; public function ...
- 更改AVD默认路径
默认情况下,安卓模拟器镜像文件会放到%userprofile%\.android下,例如当前Win7登录用户为administrator 则%userprofile%为 c:\users\admini ...
- abp ef codefirst Value cannot be null. Parameter name: connectionString
错误原因是abp生成的项目是mvc类型的,但在使用时,选择了vue去开发,所以在abp上重新生成了一个vue项目,把原有的mvc项目给删掉了,没有将新生成的vue类型的项目的文件覆盖掉原有的mvc其他 ...
- 包含了重复的“Content”项。.NET SDK 默认包含你项目目录中的“Content”项。可从项目文件中删除这些项;如果希望将其显式包含在项目文件中,可将“EnableDefaultContentItems”属性设置为“false”
从.netcore 1.1 升级到2.0时遇到该问题. 参考http://www.cnblogs.com/xishuai/p/visual-studio-for-mac.html 根据提示可知(我是看 ...
- C#做一个写txt文件流的测试,为什么配置低的机器写入的还快
测试机:笔记本i7 8G 固态硬盘 由于采取读码写入txt方式, 读码频率挺高,文件名为日期格式,当前采用每次读码打开文件写入的方式, 为什么没用sb,因为怕断电情况的数据丢失.所以采取每条存入的方式 ...
- js 箭头函数
箭头函数 ES6标准新增了一种新的函数:Arrow Function(箭头函数). x => x * x相当于: function (x) { return x * x; }箭头函数相当于匿名函 ...
- Android开发之自定义Dialog简单实现
本文着重研究了自定义对话框,通过一下步骤即可清晰的理解原理,通过更改界面设置和style类型,可以应用在各种各样适合自己的App中. 首先来看一下效果图: 首先是activity的界面 点击了上述图片 ...
- sFlow-rt安装部署
sFlow技术是一种以设备端口为基本单元的数据流随机采样的流量监控技术,不仅可以提供完整的第二层到第四层甚至全网范围内的实时流量信息,而且可以适应超大网络流量(如大于10Gbit/s)环境下的流量 ...
- CF Round #510 (Div. 2)
前言:没想到那么快就打了第二场,题目难度比CF Round #509 (Div. 2)这场要难些,不过我依旧菜,这场更是被\(D\)题卡了,最后\(C\)题都来不及敲了..最后才\(A\)了\(3\) ...