广州商学院Python正方教务系统爬虫(获取个人信息成绩课表修改密码)
使用python的requests库简单爬取,使用xpath解析内容
可以获取个人信息、个人照片、成绩单和课表
github地址:https://github.com/PythonerKK/GZCC-Spider
首先使用浏览器开发者调试工具找到登录页面的准确地址:http://jwxw.gzcc.cn/default2.aspx
然后找到验证码的地址:http://jwxw.gzcc.cn/CheckCode.aspx
将验证码保存让用户输入即可
登录时发送POST请求,需要注意要提交一个叫__VIEWSTATE的字段,并且要携带cookies
发送POST后,如果登录成功则返回用户页面,判断即可
__VIEWSTATE=re.compile('name="__VIEWSTATE" value="(.*?)"').findall(data.text)[0]
resource=requests.post(login_url,data=post_data,cookies=cookies,headers=headers).text
if '活动报名' in resource:
print('登录成功!')
dom_tree=etree.HTML(resource)
name=dom_tree.xpath('//span[@id="xhxm"]/text()')
name=name[0]
print('欢迎回来 '+name)
return (cookies,name.split('同')[0])
else:
print('登录失败!')
exit(0)
登录成功,输出:xxx同学,你好!
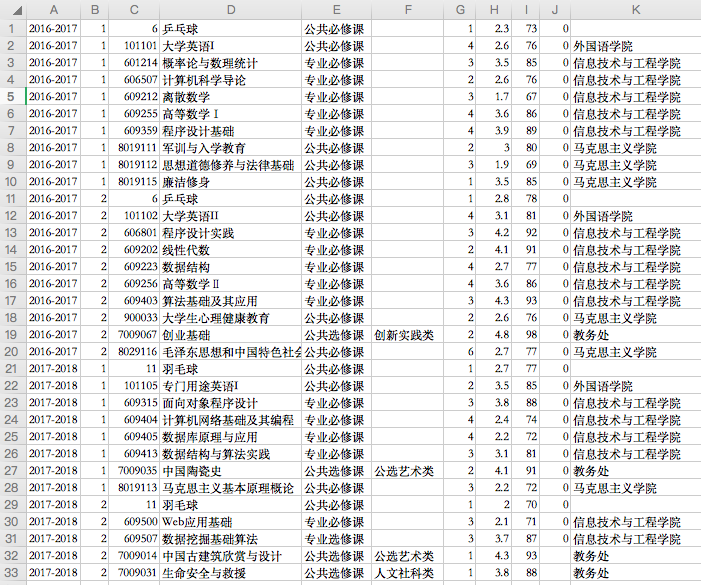
接下来需要获取个人信息、个人照片、成绩单
原理同上,注意携带cookies,成绩页面获取还需要携带__VIEWSTATE字段
效果如下:
全部代码:
# -*- coding: utf-8 -*-
"""
:author: KK
:url: http://github.com/PythonerKK
:copyright: © 2018 KK <705555262@qq.com.com>
:license: MIT, see LICENSE for more details.
"""
import requests
import re
from lxml import etree
from urllib.request import quote
import csv
def login(username,password):
'''
登录方正教务系统(广州商学院)
:param username: 学号
:param password: 密码
:return: tuple(cookies,name) 返回一个元组
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
}
login_url = 'http://jwxw.gzcc.cn/default2.aspx'
checkcode_url = 'http://jwxw.gzcc.cn/CheckCode.aspx'
data=requests.get(login_url)
__VIEWSTATE=re.compile('name="__VIEWSTATE" value="(.*?)"').findall(data.text)[0]
cookies=data.cookies
checkcode=requests.get(checkcode_url,cookies=cookies,headers=headers)
with open('checkcode.jpg','wb') as f:
f.write(checkcode.content)
code=input('请输入验证码:')
while '-' in code:
checkcode = requests.get(checkcode_url, cookies=cookies, headers=headers)
with open('checkcode.jpg', 'wb') as f:
f.write(checkcode.content)
code = input('请重新输入验证码:')
post_data={
'__VIEWSTATE':__VIEWSTATE,
'txtUserName':username,
'Textbox1':'',
'TextBox2':password,
'txtSecretCode':code,
'RadioButtonList1':'%D1%A7%C9%FA',
'Button1':'',
'lbLanguage':'',
'hidPdrs':'',
'hidsc':'',
}
resource=requests.post(login_url,data=post_data,cookies=cookies,headers=headers).text
if '活动报名' in resource:
print('登录成功!')
dom_tree=etree.HTML(resource)
name=dom_tree.xpath('//span[@id="xhxm"]/text()')
name=name[0]
print('欢迎回来 '+name)
return (cookies,name.split('同')[0])
else:
print('登录失败!')
exit(0)
def get_information(cookies,username,name):
'''
获取个人信息,并导出照片
:param cookies: cookies
:param username: 学号
:param name: 姓名
:return: None
'''
#获取用户个人信息
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Referer':'http://jwxw.gzcc.cn/xs_main.aspx?xh='+username
}
information_url='http://jwxw.gzcc.cn/xsgrxx.aspx?xh='+username+'&xm='+name+'&gnmkdm=N121501'
data=requests.get(information_url,cookies=cookies,headers=headers)
dom_tree=etree.HTML(data.text)
sex=dom_tree.xpath('//span[@id="lbl_xb"]/text()')[0]
born=dom_tree.xpath('//span[@id="lbl_csrq"]/text()')[0]
id=dom_tree.xpath('//span[@id="lbl_sfzh"]/text()')[0]
race=dom_tree.xpath('//span[@id="lbl_mz"]/text()')[0]
polity=dom_tree.xpath('//span[@id="lbl_zzmm"]/text()')[0]
academic=dom_tree.xpath('//span[@id="lbl_xy"]/text()')[0]
xi=dom_tree.xpath('//span[@id="lbl_xi"]/text()')[0]
major=dom_tree.xpath('//span[@id="lbl_zymc"]/text()')[0]
c=dom_tree.xpath('//span[@id="lbl_pyfx"]/text()')[0]
edu=dom_tree.xpath('//span[@id="lbl_CC"]/text()')[0]
phone=dom_tree.xpath('//input[@name="TELNUMBER"]/@value')[0]
school=dom_tree.xpath('//input[@name="byzx"]/@value')[0]
dorm=dom_tree.xpath('//input[@name="ssh"]/@value')[0]
email=dom_tree.xpath('//input[@name="dzyxdz"]/@value')[0]
loc_code=dom_tree.xpath('//input[@name="yzbm"]/@value')[0]
#获取用户照片
headers_image={
'Accept':'image/webp,image/apng,image/*,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Referer':'http://jwxw.gzcc.cn/xsgrxx.aspx?xh='+username+'&xm='+quote(name)+'&gnmkdm=N121501',
}
image_url=re.compile('img id="xszp" src="(.*?)"').findall(data.text)
image_url='http://jwxw.gzcc.cn/'+image_url[0]
image_url=image_url.replace('amp;','')
image_data=requests.get(image_url,headers=headers_image,cookies=cookies)
with open('photo.png', 'wb') as f:
f.write(image_data.content)
print('照片导出成功!')
from docx import Document
from docx.shared import Inches
document = Document()
document.styles['Normal'].font.name = u'黑体'
document.add_heading(name+'的个人信息',0)
pic = document.add_picture('photo.png', width=Inches(1.5))
document.add_paragraph('个人资料')
document.add_paragraph('姓名:'+name)
document.add_paragraph('性别:' + sex)
document.add_paragraph('出生:' + born)
document.add_paragraph('身份证号:' + id)
document.add_paragraph('种族:' + race)
document.add_paragraph('政治面貌:' + polity)
document.add_paragraph('系部:' + xi)
document.add_paragraph('学院:' + academic)
document.add_paragraph('专业:' + major)
document.add_paragraph('班级:' + c)
document.add_paragraph('学历:' + edu)
document.add_paragraph('手机号:' + phone)
document.add_paragraph('毕业高中:' + school)
document.add_paragraph('宿舍号:' + dorm)
document.add_paragraph('邮箱号:' + email)
document.add_paragraph('邮编:' + loc_code)
document.save(username+'个人信息.docx')
print('个人资料导出成功!')
def get_curriculum(cookies,username,name):
'''
获取学生当前课表
:param cookies:cookies
:param username: 学号
:param name: 姓名
:return: None
'''
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Referer':'http://jwxw.gzcc.cn/xs_main.aspx?xh='+username
}
curriculum_url='http://jwxw.gzcc.cn/xskbcx.aspx?xh='+username+'&xm='+password+'&gnmkdm=N121603'
data=requests.get(curriculum_url,cookies=cookies,headers=headers)
# import lxml
# dom_tree=etree.HTML(data.text)
# curriculum=dom_tree.xpath('//table[@id="Table1"]')
print(data.text)
def get_score(cookies,username,name):
'''
获取所有考试成绩,并导出csv
:param cookies: cookies
:param username: 学号
:param name: 姓名
:return: Boolean
'''
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Referer':'http://jwxw.gzcc.cn/xs_main.aspx?xh='+username
}
first_url='http://jwxw.gzcc.cn/xscjcx.aspx?xh='+username+'&xm='+name+'&gnmkdm=N121605'
data=requests.get(first_url,cookies=cookies,headers=headers)
viewstate=re.compile('name="__VIEWSTATE" value="(.*?)"').findall(data.text)
viewstate=viewstate[0]
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Referer':'http://jwxw.gzcc.cn/xscjcx.aspx?xh='+username+'&xm='+quote(name)+'&gnmkdm=N121605'
}
print(headers)
score_url='http://jwxw.gzcc.cn/xscjcx.aspx?xh='+username+'&xm='+name+'&gnmkdm=N121605'
post_data={
'__EVENTTARGET':'',
'__EVENTARGUMENT':'',
'__VIEWSTATE':viewstate,
'hidLanguage':'',
'ddlXN':'',
'ddlXQ':'',
'ddl_kcxz':'',
'btn_zcj':'%C0%FA%C4%EA%B3%C9%BC%A8'
}
scores=requests.post(score_url,cookies=cookies,headers=headers,data=post_data)
all=re.compile('<td>(.*?)</td><td>(\d+)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td></td><td></td>').findall(scores.text)
for i in all:
with open('score.csv', 'a', newline='') as f:
try:
csv_out=csv.writer(f,dialect='excel')
csv_out.writerow([i[0],i[1],i[2],i[3],i[4],i[5].replace(' ',''),i[6],i[7],i[8],i[9].replace(' ',''),i[10].replace(' ',''),i[11].replace(' ',''),i[12].replace(' ','')])
except Exception:
print('导出失败!')
return False
print('成绩导出成功!')
return True
def change_password(cookies,username,password,password1,password2):
'''
修改密码
:param cookies: cookies
:param username: 学号
:param password: 原密码
:param password1: 新密码
:param password2: 再次输入新密码
:return: None
'''
url='http://jwxw.gzcc.cn/mmxg.aspx?xh='+username+'&gnmkdm=N121502'
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Referer':'http://jwxw.gzcc.cn/xs_main.aspx?xh='+username
}
data=requests.get(url,headers=headers,cookies=cookies)
viewstate=re.compile('name="__VIEWSTATE" value="(.*?)"').findall(data.text)
viewstate=viewstate[0]
postdata={
'Button1':'%D0%DE++%B8%C4',
'__VIEWSTATE':viewstate,
'TextBox2':password,
'TextBox3':password1,
'Textbox4':password2,
}
data=requests.post(url,data=postdata,cookies=cookies,headers=headers)
print('密码修改成功!')
if __name__ == '__main__':
print('广州商学院正方教务系统登录')
username=input('请输入学号:')
password=input('请输入密码:')
cookies,name=login(username,password)
#get_information(cookies,username,name)
#get_curriculum(cookies,username,name)
#get_score(cookies,username,name)
#change_password(cookies,username,password,password1=password,password2=password)
广州商学院Python正方教务系统爬虫(获取个人信息成绩课表修改密码)的更多相关文章
- HttpClient+Jsoup模拟登陆贺州学院教务系统,获取学生个人信息
前言 注:可能学校的教务系统已经做了升级,当前的程序不知道还能不能成功获取信息,加上已经毕业,我的账户已经被注销,试不了,在这里做下思路跟过程的记录. 在我的毕业设计中”基于SSM框架贺州学院校园二手 ...
- JavaScript之正方教务系统自动化教评[插件-转载]
[声明]本插件系学院学长原创,非博主所创,发布此处,仅供学习和效仿. /** * @name:正方教务系统自动化教评-插件 * * @author:chenzhongshu * @date:2017- ...
- 以正方教务系统为例,用php模拟登陆抓取课表、空教室
课程格子和超级课程表这两个应用,想必大学生都很熟悉,使用自己的学号和教务系统的密码,就可以将自己的课表导入,随时随地都可以在手机上查看. 其实稍微了解一点php的话,我们也可以做一个类似这样的web ...
- 大学生可用来接单,利用Python实现教务系统扩容抢课!
最近一学期一次的抢课大戏又来了,几家欢乐几家愁.O(∩_∩)O哈哈~(l我每次一选就过了hah,我还是有欧的时候滴).看着他们盯着教务系统就着急,何况我们那教务系统,不想说什么.emmm 想周围的朋友 ...
- 课程助理For Windows(预览版,正方教务系统学生查分工具)
其实盖子已经开发了一个功能更强大的版本,但是那个版本依然基于正方系统,也就是说只要正方系统跪了或者张院士在网站上做点手脚,这个小工具就会失效. 今天给大家的版本虽然功能及其简单.界面极端丑陋,但是通过 ...
- python requests模拟登陆正方教务管理系统,并爬取成绩
最近模拟带账号登陆,查看了一些他人的博客,发现正方教务已经更新了,所以只能自己探索了. 登陆: 通过抓包,发现需要提交的值 需要值lt,这是个啥,其实他在访问登陆页面时就产生了 session=req ...
- Python实现简单的爬虫获取某刀网的更新数据
昨天晚上无聊时,想着练习一下Python所以写了一个小爬虫获取小刀娱乐网里的更新数据 #!/usr/bin/python # coding: utf-8 import urllib.request i ...
- HttpURLConnection模拟登录学校的正方教务系统
教务系统登录界面 如图1-1 1-1 F12-->network查看登录教务系统需要参数: __VIEWSTAT txtUserName TextBox2 txtSecretCode Radio ...
- 手把手教你使用Python网络爬虫获取招聘信息
1.前言 现在在疫情阶段,想找一份不错的工作变得更为困难,很多人会选择去网上看招聘信息.可是招聘信息有一些是错综复杂的.而且不能把全部的信息全部罗列出来,以外卖的58招聘网站来看,资料整理的不清晰. ...
随机推荐
- hadoop学习之hdfs文件系统
一.hdfs的概念 Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS. Hadoop是Apache Lucene创始人Doug Cu ...
- 自定义MVC框架之工具类-分页类的封装
以前写过一个MVC框架,封装的有点low,经过一段时间的沉淀,打算重新改造下,之前这篇文章封装过一个验证码类. 这次重新改造MVC有几个很大的收获 >全部代码都是用Ubuntu+Vim编写,以前 ...
- PHP定界符<<<eof 使用
PHP是一个Web编程语言,在编程过程中难免会遇到用echo来输出大段的html和javascript脚本的情况,如果用传统的输出方法 ——按字符串输出的话,肯定要有大量的转义符来对字符串中的引号等特 ...
- Linux服务器开启ssh服务,实现ssh远程登陆!
最近在学linux,使用ssh远程登陆linux,记录下来! 首先进入/etc目录下,/etc目录存放的是一些配置文件,比如passwd等配置文件,要想使用ssh远程登陆,需要配置/etc/ssh/s ...
- BZOJ2956: 模积和(数论分块)
题意 题目链接 Sol 啊啊这题好恶心啊,推的时候一堆细节qwq \(a \% i = a - \frac{a}{i} * i\) 把所有的都展开,直接分块.关键是那个\(i \not= j\)的地方 ...
- php 实现简单购物车功能(2)
上一篇的时候只是写了简单的加入购物车功能,购物车中产品的删除.提交订单后,库存的减少 以及客户账户的余额都没有完善, 这一篇是接着完善上一篇的,上一篇写到了购物车中删除的功能了,为了使删除的代码少敲一 ...
- Flink1.4.0连接Kafka0.10.2时遇到的问题
Flink1.4.0连接部署在Linux上的Kafka0.10.2时,报如下异常: org.apache.flink.streaming.connectors.kafka.FlinkKafkaCons ...
- 【Python】定时调度
from datetime import datetime from apscheduler.schedulers.blocking import BlockingScheduler def tick ...
- MySQL 8.0新特性之原子DDL
文章来源:爱可生云数据库 简介 MySQL8.0 开始支持原⼦ DDL(atomic DDL),数据字典的更新,存储引擎操作,写⼆进制日志结合成了一个事务.在没有原⼦DDL之前,DROP TABLE ...
- python模拟自动登录网站(urllib2)
不登录打开网页: import urllib2 request = urllib2.Request('http://www.baidu.com') response = urllib2.urlopen ...