ES6快到碗里来---一个简单的爬虫指南
学习ES6的时候,没少看ES6入门,到现在也就明白了个大概(惭愧脸)。这里不谈ES6,只谈怎么把ES6的页面爬下来放到一起成为一个离线文档。
之前居然没注意过作者把这本书开源了。。瞎耽误功夫。。。地址
通俗易懂_小白friendly_
node 爬虫入门
如果你之前没有用node写过一个爬虫,可以从这篇文章开始。Node.JS 妹子图爬虫(1),除了核心模块外,文章中还用到cheerio这个库来分析访问的页面。cheerio是一个类似于jquery的库,但是运行在node上。而这里主要用到:
node的
http模块fs模块- ES6promise的一些知识。
show time!
分析要抓的页面路径
这里就放在浏览器上了,当然也可以用http放在后端,F12可以发现,所有链接在一个ol元素里,如图:
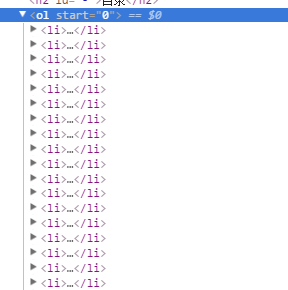
所以把所有链接地址存到数组里的代码如下:(在控制台输入)
var links=[];
Array.from($("[start='0'] a")).forEach(function(e){links.push(e.getAttribute("href"))});
JSON.stringfy(links)//便于复制数组
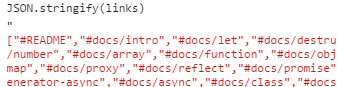
服务端
新建一个js文件。接下来就是陪links玩了。首先我们写出了以下的渣代码,不过还好可以跑
var fs = require('fs'),http = require('http');
var links = ["#README", "#docs/intro", "#docs/let", "#docs/destructuring", "#docs/string", "#docs/regex", "#docs/number", "#docs/array", "#docs/function", "#docs/object", "#docs/symbol", "#docs/set-map", "#docs/proxy", "#docs/reflect", "#docs/promise", "#docs/iterator", "#docs/generator", "#docs/generator-async", "#docs/async", "#docs/class", "#docs/decorator", "#docs/module", "#docs/module-loader", "#docs/style", "#docs/spec", "#docs/arraybuffer", "#docs/simd", "#docs/reference"];
var allInOne = "",
host = "http://es6.ruanyifeng.com/";
var realLinks = links.map(function(link) { return link.slice(1) + '.md' });//迷之reallinks
console.log(links.length);
现在你就可以先在命令行里node getES6了,除了得到数组长度外并没有什么用。
请求
有了原料之后,开始下锅了,我们的构想是,写一个循环来依次请求这些页面,然后把得到的html字符串写到一起:
var allInOne = "",
n = 0;//数数用
for(let link of links) {
n++;
allInOne += getHTML(host + link, n);
}
}
接下来实现getHtml这个函数:
function getHTML(url, n, id = "body") {
var promise = new Promise(function(resolve, reject) {//不清楚的看http://es6.ruanyifeng.com/#docs/promise
var pageStr = '';//用于放html或md文件
var req = http.get(url, function(res) {//发起请求
res.setEncoding('utf8');
var status = res.statusCode;
if(status == '200') {
res.on('data', function(chunk) {
pageStr += chunk;
});
res.on('end', function(data) {
allInOne += pageStr;
fs.appendFile(`./page/${n}.md`, pageStr, 'utf8', function(e) {//将文件保存到本地的page文件夹下,后缀是md?
console.log(e);
});
console.log(`finish load ${url}`);
resolve();
});
}
});
});
return promise;
}
将上面两个个代码片段拼到一起,可以先node ES6跑跑看了,是不是与期望不符?下回再说。
ES6快到碗里来---一个简单的爬虫指南的更多相关文章
- python (1)一个简单的爬虫: python 在windows下 创建文件夹并写入文件
1.一个简单的爬虫:爬取豆瓣的热门电影的信息 写在前面:如何创建本来存在的文件夹并写入 t_path = "d:/py/inn" #本来不存在inn,先定义路径,然后如果不存在,则 ...
- Python并发编程-一个简单的爬虫
一个简单的爬虫 #网页状态码 #200 正常 #404 网页找不到 #502 504 import requests from multiprocessing import Pool def get( ...
- python爬虫系列(1)——一个简单的爬虫实例
本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片. 1. 概述 本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片.下载图片的步骤如下: 获取网页html文本内容:分析html中 ...
- 【转】使用webmagic搭建一个简单的爬虫
[转]使用webmagic搭建一个简单的爬虫 刚刚接触爬虫,听说webmagic很不错,于是就了解了一下. webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代 ...
- 用node.js从零开始去写一个简单的爬虫
如果你不会Python语言,正好又是一个node.js小白,看完这篇文章之后,一定会觉得受益匪浅,感受到自己又新get到了一门技能,如何用node.js从零开始去写一个简单的爬虫,十分钟时间就能搞定, ...
- nodejs实现一个简单的爬虫
nodejs是js语言,实现一个爬出非常的方便. 步骤 1. 使用nodejs的request模块,获取目标页面的html代码:https://github.com/request/request 2 ...
- 爬虫浅谈一:一个简单c#爬虫程序
这篇文章只是简单展示一个基于HTTP请求如何抓取数据的文章,如觉得简单的朋友,后续我们再慢慢深入研究探讨. 图1: 如图1,我们工作过程中,无论平台网站还是企业官网,总少不了新闻展示.如某天产品经理跟 ...
- 一个简单java爬虫爬取网页中邮箱并保存
此代码为一十分简单网络爬虫,仅供娱乐之用. java代码如下: package tool; import java.io.BufferedReader; import java.io.File; im ...
- Python网络爬虫 - 一个简单的爬虫例子
下面我们创建一个真正的爬虫例子 爬取我的博客园个人主页首页的推荐文章列表和地址 scrape_home_articles.py from urllib.request import urlopen f ...
随机推荐
- MessageFormat.format()和String.format()
MessageFormat 提供了以与语言无关方式生成连接消息的方式.使用此方法构造向终端用户显示的消息. MessageFormat 获取一组对象,格式化这些对象,然后将格式化后的字符串插入到模式中 ...
- web-day12
第12章WEB12-JSP&EL&JSTL篇 今日任务 商品信息的显示 教学导航 教学目标 掌握JSP的基本的使用 掌握EL的表达式的用法 掌握JSTL的常用标签的使用 教学方法 案例 ...
- Docker windows下安装并搭建Nodejs的webapp
一.关于Docker 什么是Docker?Docker 采用go语言编写,是一个开源的应用容器引擎.让开发者可以快速打包他们的应用以及依赖包到一个封装的可移植的容器Image中,然后发布到任何流行的机 ...
- TypeScript开发环境搭建(Visual studio code)
使用Visual Studio Code搭建TypeScript开发环境 1.TypeScript是干什么的 ? TypeScript是由微软Anders Hejlsberg(安德斯·海尔斯伯格,也是 ...
- 差值的再议-Hermite差值
1. 插值法 插值法又称“内插法”,是利用函数f (x)在某区间中已知的若干点的函数值,作出适当的特定函数,在区间的其他点上用这特定函数的值作为函数f (x)的近似值,这种方法称为插值法. 如果这特定 ...
- bootstrap增删改查
<!DOCTYPE html><html> <head> <meta charset="utf-8" /> <title> ...
- 保存到Excel文件中
OLEObject ole_object , ole_workbooks ole_object = CREATE OLEObjectIF ole_object.ConnectToNewObject(& ...
- MCU_存储器
MCU的存储器用途: RAM:数据存储器,和计算机的内存差不多,主要是用来存放程序运行产生的过程数据,掉电后会丢失数据,因此程序在上电后需要进行初始化.程序中的全局变量占据着RAM中的固定空间,局部变 ...
- [require-js]向下滑动ajax加载的javascript实现
define(function(){ function ScrollMoreInfo($wraper , loadDataFunc , json_ids , perNum , tpl_info) { ...
- Http站点转Https站点教程
https://blog.csdn.net/tanga842428/article/details/79273226 Http站点转Https站点教程 2018年02月28日 12:04:35 坦GA ...