为你的机器学习模型创建API服务
1. 什么是API
当调包侠们训练好一个模型后,下一步要做的就是与业务开发组同学们进行代码对接,以便这些‘AI大脑’们可以顺利的被使用。然而往往要面临不同编程语言的挑战,例如很常见的是调包侠们用Python训练模型,开发同学用Java写业务代码,这时候,Api就作为一种解决方案被使用。
简单地说,API可以看作是顾客与商家之间的联系方式。如果顾客以预先定义的格式提供输入信息,则商家将获得顾客的输入信息并向其提供结果。
从本质上讲,API非常类似于web应用程序,但它没有提供一个样式良好的HTML页面,而是倾向于以标准数据交换格式返回数据,比如JSON、XML等。
接下来让我们看看如何将机器学习模型(在Python中开发的)封装为一个API。
首先需要明白什么是Web服务?Web服务是API的一种形式,只是它假定API驻留在服务器上,并且可以使用。Web API、Web服务——这些术语通常可以互换使用。
Flask——Python中的Web服务框架。它不是Python中唯一的一个Web框架,其它的例如Django、Falcon、Hug等。Flask框架带有一个内置的轻量级Web服务器,它需要最少的配置,因此在本文中将使用Flask框架来开发我们的模型API。
2. 创建一个简单模型
以一个kaggle经典的比赛项目:泰坦尼克号生还者预测为例,训练一个简单的模型。
以下是整个机器学习模型的API代码目录树:
首先,我们需要导入训练集并选择特征。因为本文主要是介绍机器学习模型API的编写,所以模型训练过程并不做为重点内容,因此我们只选择其中的'Age', 'Sex', 'Embarked', 'Survived' 这四个特征来构造训练集。
import pandas as pd # 导入训练集并选择特征
url = "http://s3.amazonaws.com/assets.datacamp.com/course/Kaggle/train.csv"
df = pd.read_csv(url)
include = ['Age', 'Sex', 'Embarked', 'Survived']
df_ = df[include]
然后,是一个简单的数据处理过程。
这里主要是对类别型特征进行One-hot编码,对连续型特征进行空缺值填充。
categoricals = []
for col, col_type in df_.dtypes.iteritems():
if col_type == 'O':
categoricals.append(col)
else:
df_[col].fillna(0, inplace=True) df_ohe = pd.get_dummies(df_, columns=categoricals, dummy_na=True)
最后,是模型的训练以及持久化保存。
模型采用的是逻辑回归,使用sklearn.externals.joblib将模型保存为序列化文件.pkl。需要注意的是,如果传入的请求不包含所有可能的category变量值,那么在预测时,get_dummies()生成的dataframe的列数比训练得到分类器的列数少,这会导致运行报错发生。所以在模型训练期间还需要持久化训练集One-hot后的列名列表。
from sklearn.linear_model import LogisticRegression
from sklearn.externals import joblib dependent_variable = 'Survived'
x = df_ohe[df_ohe.columns.difference([dependent_variable])]
y = df_ohe[dependent_variable]
lr = LogisticRegression()
lr.fit(x, y) # 保存模型
joblib.dump(lr, 'model.pkl')
print("Model dumped!") # 把训练集中的列名保存为pkl
model_columns = list(x.columns)
joblib.dump(model_columns, 'model_columns.pkl')
print("Models columns dumped!")
到此,我们的model.py的代码部分构造完毕。
3. 基于Flask框架创建API服务
使用Flask部署模型服务,需要写一个函数predict(),并完成以下两件事:
- 当应用程序启动时,将已持久化的模型加载到内存中;
- 创建一个API站点,该站点接受输入变量的请求后,将输入转换为适当的格式,并返回预测。
更具体地说,需要API的输入如下(一个由JSON组成的列表):
[
{"Age": 85, "Sex": "male", "Embarked": "S"},
{"Age": 24, "Sex": '"female"', "Embarked": "C"},
{"Age": 3, "Sex": "male", "Embarked": "C"},
{"Age": 21, "Sex": "male", "Embarked": "S"}
]
而模型API的输出如下:
{"prediction": [0, 1, 1, 0]}
import traceback
import sys import pandas as pd
from flask import request
from flask import Flask
from flask import jsonify app = Flask(__name__) @app.route('/predict', methods=['POST']) # Your API endpoint URL would consist /predict
def predict():
if lr:
try:
json_ = request.json
query = pd.get_dummies(pd.DataFrame(json_))
query = query.reindex(columns=model_columns, fill_value=0)
prediction = list(lr.predict(query))
return jsonify({'prediction': str(prediction)})
except:
return jsonify({'trace': traceback.format_exc()})
else:
print('Train the model first')
return 'No model here to use'
我们已经在“/predict”API中包含了所有必需的元素,现在只需编写主类即可。
from sklearn.externals import joblib
if __name__ == '__main__':
try:
port = int(sys.argv[1])
except:
port = 8000
lr = joblib.load('model.pkl') # Load "model.pkl"
print('Model loaded')
model_columns = joblib.load('model_columns.pkl') # Load "model_columns.pkl"
print('Model columns loaded')
app.run(host='192.168.100.162', port=port, debug=True)
到此,我们的机器学习模型API已经创建完毕,flask_api.py的代码部分也已构造完毕。但在进一步深入之前,让我们回顾一下之前的所有操作:
- 加载了泰坦尼克数据集并选择了四个特征。
- 进行了必要的数据预处理。
- 训练了一个逻辑回归分类器模型并将其序列化。
- 持久化训练集中的列名的列表。
- 使用Flask编写了一个简单的API,该API通过接收一个由JSON组成的列表,预测一个人是否在沉船中幸存。
4. API的有效性测试
首先运行我们的模型API服务,我们通过Pycharm来启动上一小节编写完成的flask_api.py:
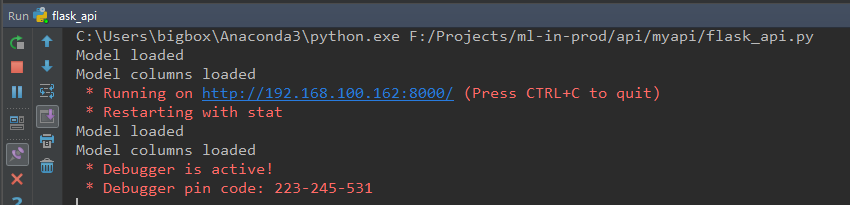
可以看到,在启动API服务后,模型以及列名被顺利的加载到了内存中。
之后可以通过Postman软件模拟网页请求,通过传递测试数据来观察模型API是否能正常返回预测信息。具体操作如下:
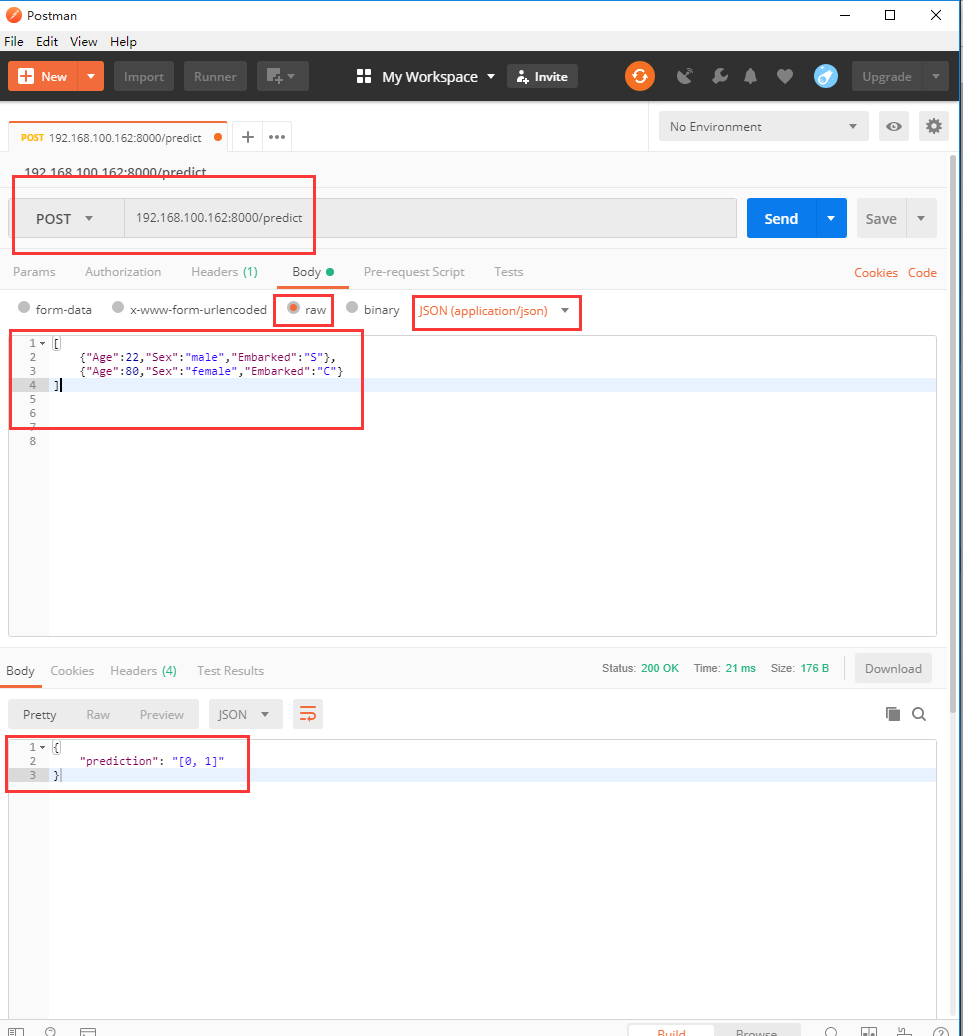
可以看到,模型API顺利的接收到了POST请求并发送预测结果。
当然,除了Postman以外,我们也可以编写Python脚本request_api.py完成API测试:
import requests
years_exp = [{"Age": 22, "Sex": "male", "Embarked": "S"},
{"Age": 22, "Sex": "female", "Embarked": "C"},
{"Age": 80, "Sex": "female", "Embarked": "C"},
{"Age": 22, "Sex": "male", "Embarked": "S"},
{"Age": 22, "Sex": "female", "Embarked": "C"},
{"Age": 80, "Sex": "female", "Embarked": "C"},
{"Age": 22, "Sex": "male", "Embarked": "S"},
{"Age": 22, "Sex": "female", "Embarked": "C"},
{"Age": 80, "Sex": "female", "Embarked": "C"},
{"Age": 22, "Sex": "male", "Embarked": "S"},
{"Age": 22, "Sex": "female", "Embarked": "C"},
{"Age": 80, "Sex": "female", "Embarked": "C"},
{"Age": 22, "Sex": "male", "Embarked": "S"},
{"Age": 22, "Sex": "female", "Embarked": "C"},
{"Age": 80, "Sex": "female", "Embarked": "C"},
]
response = requests.post(url='http://192.168.100.162:8000/predict', json=years_exp)
result = response.json()
print('model API返回结果:', result)
同样我们顺利地接收到了模型的返回结果:

这证明我们的机器学习API已经顺利开发完毕,接下来要做的就是交给业务开发组的同学来使用了。
5. 总结
本文介绍了如何从机器学习模型构建一个API。尽管这个API很简单,但描述的还算相对清晰。
此外,除了可以对模型预测部分构建API以外,也可以对训练过程构建一个API,包括通过发送超参数、发送模型类型等让客户来构建属于自己的机器学习模型。当然,这也将是我下一步要做的事情。
为你的机器学习模型创建API服务的更多相关文章
- Kubernetes入门(四)——如何在Kubernetes中部署一个可对外服务的Tensorflow机器学习模型
机器学习模型常用Docker部署,而如何对Docker部署的模型进行管理呢?工业界的解决方案是使用Kubernetes来管理.编排容器.Kubernetes的理论知识不是本文讨论的重点,这里不再赘述, ...
- 使用Flask构建机器学习模型API
1. Python环境设置和Flask基础 使用"Anaconda"创建一个虚拟环境.如果你需要在Python中创建你的工作流程,并将依赖项分离出来,或者共享环境设置," ...
- 使用ASP.NET web API创建REST服务(二)
Creating a REST service using ASP.NET Web API A service that is created based upon the architecture ...
- 使用ASP.NET web API创建REST服务(三)
本文档来源于:http://www.cnblogs.com/madyina/p/3390773.html Creating a REST service using ASP.NET Web API A ...
- ASP.NET---如何使用web api创建web服务
1 首先创建asp.net web空项目,并且创建模拟数据,我在工程下面创建了一个Models文件夹,在文件夹Nodels下面创建类Product和Repository 具体如下: [Serializ ...
- ASP.NET Core Web API + Angular 仿B站(二)后台模型创建以及数据库的初始化
前言: 本系列文章主要为对所学 Angular 框架的一次微小的实践,对 b站页面作简单的模仿. 本系列文章主要参考资料: 微软文档: https://docs.microsoft.com/zh-cn ...
- 用PMML实现机器学习模型的跨平台上线
在机器学习用于产品的时候,我们经常会遇到跨平台的问题.比如我们用Python基于一系列的机器学习库训练了一个模型,但是有时候其他的产品和项目想把这个模型集成进去,但是这些产品很多只支持某些特定的生产环 ...
- 用PMML实现python机器学习模型的跨平台上线
python信用评分卡(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_camp ...
- 如何对SAP Leonardo上的机器学习模型进行重新训练
Jerry之前的两篇文章介绍了如何通过Restful API的方式,消费SAP Leonardo上预先训练好的机器学习模型: 如何在Web应用里消费SAP Leonardo的机器学习API 部署在SA ...
随机推荐
- Python+Selenium笔记(十六)屏幕截图
(一) 方法 方法 简单说明 save_screenshot(filename) 获取当前屏幕截图并保存为指定文件 filename:路径/文件名 get_screenshot_as_base64 ...
- Sql server在使用sp_executesql @sql执行文本sql时,报错: Could not find database ID 16, name '16'. The database may be offline. Wait a few minutes and try again.
最近在公司项目中使用exec sp_executesql @sql执行一段文本sql的时候老是报错: Could not find database ID 16, name '16'. The dat ...
- 存储过程使用 in 添加多个参数的情况处理方式【转】
原文连接:http://www.jb51.net/article/41472.htm -->情景 ① 通过刚才的SQL递归方式,我们已经可以将一个组织机构和其全部下级单位查询出来:假设每个组织机 ...
- Beyond Compare 4 使用方法
一 : 二 : 三 :
- 【转】Spring学习---Bean配置的三种方式(XML、注解、Java类)介绍与对比
[原文]https://www.toutiao.com/i6594205115605844493/ Spring学习Bean配置的三种方式(XML.注解.Java类)介绍与对比 本文将详细介绍Spri ...
- mybatis 中的<![CDATA[ ]]>
在使用mybatis 时我们sql是写在xml 映射文件中,如果写的sql中有一些特殊的字符的话,在解析xml文件的时候会被转义,但我们不希望他被转义,所以我们要使用<![CDATA[ ]]&g ...
- js 小数计算时出现多余的数据
根据资料显示:是由于十进制换算成二进制,处理后,再由二进制换算成十进制时,造成的误差. 得出:所以(0.1+0.2)!=0.3 而是=0.30000000000000004的结果 解决方法: 参考:h ...
- UltraEdit 换行替换
需求:想在每行结尾添加 '), 方案:在查找栏填写(^r^n) 替换栏('),^r^n) 效果:
- Geometric Search
几何搜索 平衡搜索树(BST)在几何方面的应用,处理的内容变成几何对象,像点,矩形. 1d range search 先来看一维的情况,一维的范围搜索是后面的基础,处理的对象是在一条线上的点.这是符号 ...
- Geth命令用法-参数详解 and 以太坊源码文件目录
本文是对以太坊客户端geth命令的解析 命令用法 geth [选项] 命令 [命令选项] [参数-] 版本 1.7.3-stable 命令 account 管理账户 attach 启动交互式JavaS ...