Hadoop(一) HADOOP简介
1. HADOOP背景介绍
1.1 什么是HADOOP
- HADOOP是apache旗下的一套开源软件平台
- HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
- HADOOP的核心组件有
- HDFS(分布式文件系统)
- YARN(运算资源调度系统)
- MAPREDUCE(分布式运算编程框架)
- 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
- HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
- 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
1.2 HADOOP产生背景
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
- Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
- 云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。
1.3 HADOOP在大数据、云计算中的位置和关系
- 现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
- 而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
1.4 国内外HADOOP应用案例介绍
1、HADOOP应用于数据服务基础平台建设
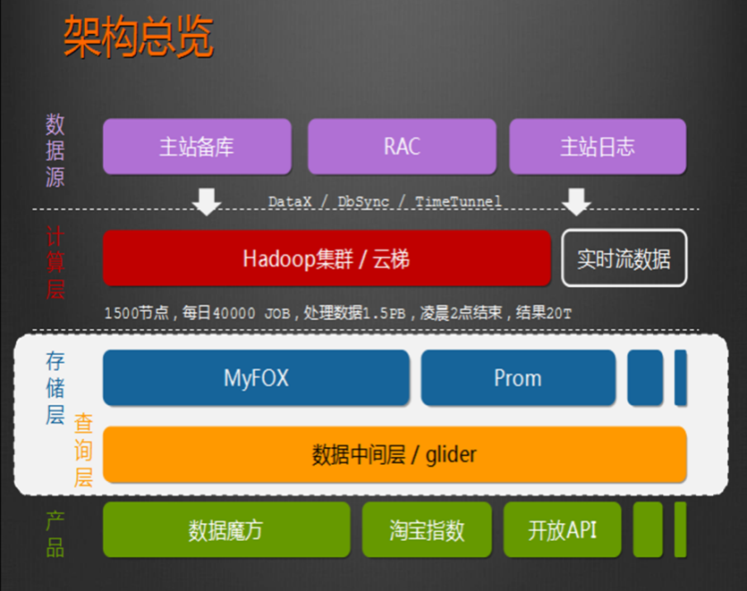
2/HADOOP用于用户画像

3、HADOOP用于网站点击流日志数据挖掘
1.6 HADOOP生态圈以及各组成部分的简介
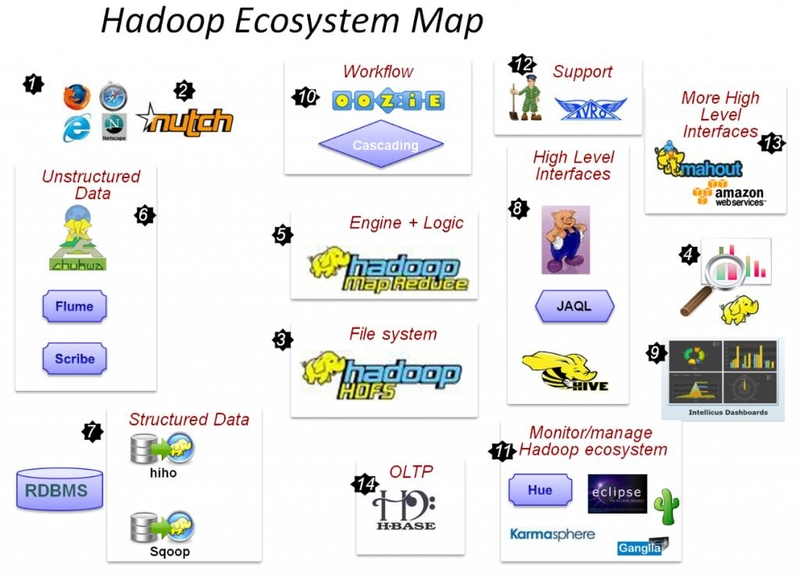
重点组件:
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
HADOOP(hdfs、MAPREDUCE、yarn) 元老级大数据处理技术框架,擅长离线数据分析
Zookeeper 分布式协调服务基础组件
Hbase 分布式海量数据库,离线分析和在线业务通吃
Hive sql 数据仓库工具,使用方便,功能丰富,基于MR延迟大
Sqoop数据导入导出工具
Flume数据采集框架
Hadoop(一) HADOOP简介的更多相关文章
- Hadoop开发环境简介(转)
1.Hadoop开发环境简介 1.1 Hadoop集群简介 Java版本:jdk-6u31-linux-i586.bin Linux系统:CentOS6.0 Hadoop版本:hadoop-1.0.0 ...
- 【云计算 Hadoop】Hadoop 版本 生态圈 MapReduce模型
忘的差不多了, 先补概念, 然后开始搭建集群实战 ... . 一 Hadoop版本 和 生态圈 1. Hadoop版本 (1) Apache Hadoop版本介绍 Apache的开源项目开发流程 : ...
- hadoop基础----hadoop实战(七)-----hadoop管理工具---使用Cloudera Manager安装Hadoop---Cloudera Manager和CDH5.8离线安装
hadoop基础----hadoop实战(六)-----hadoop管理工具---Cloudera Manager---CDH介绍 简介 我们在上篇文章中已经了解了CDH,为了后续的学习,我们本章就来 ...
- Hadoop: Hadoop Cluster配置文件
Hadoop配置文件 Hadoop的配置文件: 只读的默认配置文件:core-default.xml, hdfs-default.xml, yarn-default.xml 和 mapred-defa ...
- [Linux][Hadoop] 将hadoop跑起来
前面安装过程待补充,安装完成hadoop安装之后,开始执行相关命令,让hadoop跑起来 使用命令启动所有服务: hadoop@ubuntu:/usr/local/gz/hadoop-$ ./sb ...
- Hadoop:搭建hadoop集群
操作系统环境准备: 准备几台服务器(我这里是三台虚拟机): linux ubuntu 14.04 server x64(下载地址:http://releases.ubuntu.com/14.04.2/ ...
- [Hadoop 周边] Hadoop资料收集【转】
原文网址: http://www.iteblog.com/archives/851 最直接的学习参考网站当然是官网啦: http://hadoop.apache.org/ Hadoop http:// ...
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- hadoop数据[Hadoop] 实际应用场景之 - 阿里
上班之余抽点时间出来写写博文,希望对新接触的朋友有帮助.明天在这里和大家一起学习一下hadoop数据 Hadoop在淘宝和支付宝的应用从09年开始,用于对海量数据的离线处置,例如对日志的分析,也涉及内 ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
随机推荐
- eclipse 访问GitHub 问题
- Android sdk测试方法链接
https://blog.csdn.net/u013059441/article/details/79030998?utm_source=blogxgwz0
- 学JS的心路历程 - JS的Class
没错,你没有看错,虽然前面说JS是原型继承,但在ES6以后新增了class关键字!!! 不过底层实作仍然是以原型继承方式进行,所以基本上算是一个语法糖. 今天我们就来看一下如何使用吧! class 首 ...
- Ubuntu系统下手动释放内存
有时候,像mongo这种,对内存只吃不吐的,我们要手动释放一下. drop_caches的详细文档如下:Writing to this will cause the kernel to drop cl ...
- spring boot springmvc视图
pring boot 在springmvc的视图解析器方面就默认集成了ContentNegotiatingViewResolver和BeanNameViewResolver,在视图引擎上就已经集成自动 ...
- Webpack Loaders
[Webpack Loaders] 1.Query parameters Loader can be passed query parameters via a query string (just ...
- FP增加的索引
1.优化FP_BOM中第839行执行过慢问题,且会出现ORA-01652: 无法通过 128 (在表空间 STGTEMP 中) 扩展 temp 段ORA-06512: 在 "STG.FP_B ...
- hibernate mysql视图操作
hibernate对视图操作,首先建立数据库视图 视图v_invite: create view pintu.v_invite asselect cp.user_id as be_user_id,ca ...
- Hibernate一对多单向关联和双向关联映射方法及其优缺点 (待续)
一对多关联映射和多对一关联映射实现的基本原理都是一样的,既是在多的一端加入一个外键指向一的一端外键,而主要的区别就是维护端不同.它们的区别在于维护的关系不同: 一对多关联映射是指在加载一的一端数据的同 ...
- mybatis 插件安装与使用
安装 1.在MarketPlace 中搜索 MyBatipse 安装 2.下载MyBatipse 插件 使用 ......