MySQL复制以及调优
一. 简介
MySQL自带复制方案,带来好处有:
数据备份。
负载均衡。
分布式数据。
概念介绍:
主机(master):被复制的数据库。
从机(slave):复制主机数据的数据库。
复制步骤:
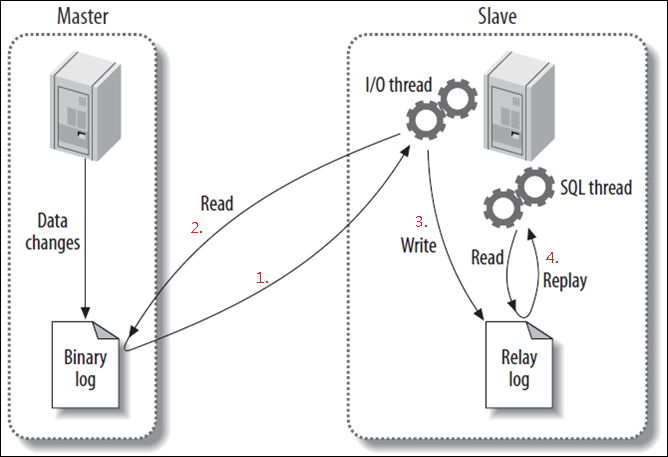
(1). master记录更改的明细,存入到二进制日志(binary log)。
(2). master发送同步消息给slave。
(3). slave收到消息后,将master的二进制日志复制到本地的中继日志(relay log)。
(4). slave重现中继日志中的消息,从而改变数据库的数据。
下面放一张经典的图片来说明这一过程:
二. 实现复制
实现复制有以下步骤:
1.设置MySQL主库的二进制日志以及server-id
MySQL配置文件一般存放在/etc/my.cnf
# 在[mysqld]下面添加配置选项
[mysqld]
server-id=1
log-bin=mysql-bin.log
server-id是数据库在整个数据库集群中的唯一标示,必须保持唯一。
重启MySQL。
注:如果MySQL配置文件中已经配置过此文件,则可以跳过此步。
2.新建复制账号
在主库里面新建用于从库复制主库数据的账号,并授予复制权限。
mysql> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO user_name@'host' IDENTIFIED BY 'password';
3.设置MySQL主库server-id
和第二步配置一样,要注意的地方有两点:
- 如果不需要从库作为别的从库的主库的话,则不需要配置二进制日志。
- 很多时候复制并不需要复制主库的全部数据库(特别是mysql的信息配置库)。因此可以配置replicate_do_db来指定复制的数据库
4.从库初始化主库的数据
如果数据量不算大的情况下,可以使用mysqldump工具导出主库数据,然后导入到从库里面。
mysqldump --single-transaction --triggers --master-data databasename > data.sql
如果数据量大的情况下应该使用Xtrabackup去进行数据库的导出,此处不做介绍。
可能会有同学问,为什么不直接使用二进制日志进行初始化呢?
- 如果我们主库运行了比较长的一段时间,并不太适合使用从库根据二进制日志进行复制数据,直接使用二进制日志去初始化从库会比较耗费时间和性能。
- 更多的情况下,主库的二进制日志的配置项没有打开,因此也就不存在以前操作的二进制日志。
5.开启复制
从库执行下面命令
mysql> CHANGE MASTER TO MASTER_HOST='host',
-> MASTER_USER='user',
-> MASTER_PASSWORD='password',
-> MASTER_LOG_FILE='mysql-bin.000001',
-> MASTER_LOG_POS=0;
注意最后的两个命令:MASTER_LOG_FILE和MASTER_LOG_POS,表示从库的从哪个二进制文件开始读取,偏移量从那里开始,这两个参数可以从我们导入的SQL里面找到。

开启复制
start slave;
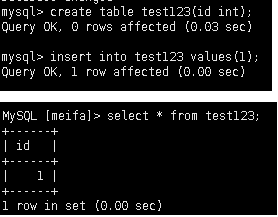
这时候就完成了复制,在主库更新一个数据或者新增数据在从库都可以查询到结果。
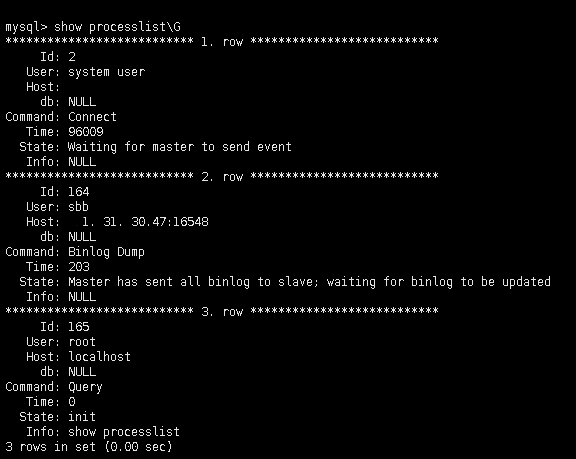
在主库上也可以查询的到复制线程的状态。
三. 复制的日志格式
MySQL复制的日志格式有三种,根据主库存放数据的方式不同有以下三种:
| 复制方式 | 特点 | 优点 | 缺点 |
|---|---|---|---|
| row | 基于行的格式复制,记录需要修改的每行的数据信息。 如果一个SQL修改了2w行的数据,那么就会记录2w行的日志格式 | 保证了数据的强一致性,且由于记录的是执行后的结果,在从库上执行还原也会比较快 | 日志记录数量很多,主从之间的传输需要更多的时间。 |
| statement | 基于段的日志格式复制,也就是记录下更改的SQL记录,而不是更改的行的记录。 | 日志记录量最小。 | 对于一些输出结果不确定的函数,在从库上执行一遍很可能会出现问题,如uuid,从库根据日志还原主库数据的时候需要执行一遍SQL,时间相对较慢。 |
| mixed | 混合上面两种日志格式记录记录日志,至于什么时候使用哪种日志方式由MySQL本身决定。 | 可以平衡上面两种日志格式的优缺点。 |
mysql5.7以前默认使用statement格式。
设置方式,可以在配置文件设置(首选):
binlog_format=ROW
或临时设置全局变量(当前mysql连接有效):
查看日志格式
mysql > show variables like 'binlog_format';
设置日志格式
mysql > set binlog_format='row';
由于两个主从服务器一般都会放在同一个机房里面,两者之间同步的速度会会比较快,为保证强一致性,应该首选行的日志格式记录(row),保证传输素速度可以选择混合方式(mixed)。
而行的日志格式有下面三种记录方式:
| 记录方式 | 特点 |
|---|---|
| minimal | 只记录被修改列的数据 |
| full | 记录被修改的行的全部列的数据 |
| noblob | 特点同上,只是如果没有修改blob和text类型的列的情况下,不会记录这些列的数据(也就是大数据列) |
mysql默认是full,最好修改成minimal。
binlog_row_image=minimal
四. 主从复制延迟
由于主库和从库之间不在同一个主机上,数据同步之间不可以避免地具有延迟,解决的方法有添加缓存,业务层的跳转等待,如果非得从数据库层面去减缓延迟问题,可以从复制时候的三大步骤(主库产生日志,主从传输日志,从库还原日志内容)入手:
1.主库写入到日志的速度
控制主库的事务大小,分割大事务为多个小事务。
如插入20w的数据,改成插入多次5000行(可以利用分页的思路)
2.二进制日志在主从之间传输时间
主从之间尽量在同一个机房或地域。
日志格式改用MIXED,且设置行的日志格式未minimal,原理详见上面的日志格式介绍。
3.减少从库还原日志的时间
在MySQL5.7版本后可以利用逻辑时钟方式分配SQL多线程。
设置逻辑时钟:slave_parallel_type=‘logical_clock’;
设置复制线程个数:slave_parallel_workers=4;
五. 需要注意的地方
- 重启MySQL最好切换未MySQL用户再进行操作,不然文件启动后会有权限问题。
- 搭建好MySQL的环境后就设置好配置里的log-bin选项,这样以后如果数据库需要从库的复制,就不需要重启数据库,打断业务的进行。
- 需要打开主库的防火墙的对应的mysql端口。
- 由于从库同步主库的方式,监听主库发送的信息,而不是轮询,因此如果出现通信出现了故障,重新连接后如果主库没有进行数据更改的操作,从库不会同步数据,因此可以通过插入空事务的方式同步数据。
欢迎各位来我博客查看本文
MySQL复制以及调优的更多相关文章
- mysql数据库性能调优总结积累
mysql数据库的调优大概可以分为四大块 0 架构调优 ---根据业务 读写分库分表 ---主从 读写分离 1 配置的调优 ---开启缓存查询 设置缓存大小 ---最大连接数设置 ---数据库引 ...
- MySQL 数据库规范--调优篇(终结篇)
前言 这篇是MySQL 数据库规范的最后一篇--调优篇,旨在提供我们发现系统性能变弱.MySQL系统参数调优,SQL脚本出现问题的精准定位与调优方法. 目录 1.MySQL 调优金字塔理论 2.MyS ...
- MySQL 数据库性能调优
MySQL 数据库性能调优 MySQL性能 最大数据量 最大并发数 优化的范围有哪些 存储.主机和操作系统方面: 应用程序方面: 数据库优化方面: 优化维度 数据库优化维度有四个: 优化选择: 数据库 ...
- 一文了解MySQL性能测试及调优中的死锁处理方法,你还看不明白?
一文了解MySQL性能测试及调优中的死锁处理方法,你还看不明白? 以下从死锁检测.死锁避免.死锁解决3个方面来探讨如何对MySQL死锁问题进行性能调优. 死锁检测 通过SQL语句查询锁表相关信息: ( ...
- 看MySQL的参数调优及数据库锁实践有这一篇足够了
史上最强MySQL参数调优及数据库锁实践 1. 应用优化 1.2 减少对MySQL的访问 1.2.1 避免对数据进行重复检索 1.2.2 增加cache层 1.3 负载均衡 1.3.1 利用MySQL ...
- MySQL Innodb引擎调优
介绍: Innodb给MYSQL提供了具有提交,回滚和崩溃恢复能力的事务安全(ACID兼容)存储引擎.Innodb锁定在行级并且也在SELECT语句提供一个Oracle风格一致的非锁定读.这些特色增加 ...
- mysql数据库索引调优
一.mysql索引 1.磁盘文件结构 innodb引擎:frm格式文件存储表结构,ibd格式文件存储索引和数据. MyISAM引擎:frm格式文件存储表结构,MYI格式文件存储索引,MYD格式文件存储 ...
- tomcat 线程数与 mysql 连接数综合调优
目前线上系统包含 数据收集+数据分析+中心服务,三个均为 tomcat,共用一个mysql服务. 由于tomcat最大线程数200 *3 =600,最大并发时,会有600个jdbc连接.当然这是极端情 ...
- Mysql之explain调优
Explain调优 使用explain语法,对SQL进行解释,根据其结果进行调优: MySQL 表关联的算法是 Nest Loop Join,是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该 ...
随机推荐
- 20169207《Linux内核原理与分析》第三周作业
这周主要对于以往的知识进行了复习,包括开始的Linux基础,以及对需要学习的新知识进行了复习,也对markdown的语法进行了初步的了解.开始学习markdown的一些基本语法和Linux的一些常用命 ...
- 《计算机科学基础》学习笔记_Part 1 Computer and Data
Technorati Tags: 计算机科学基础,读书笔记 Chapter 1. Introduction Ø 计算机:黑盒,Output Data=f(Input Data, Program) Ø ...
- QT中的线程与事件循环理解(2)
1. Qt多线程与Qobject的关系 每一个 Qt 应用程序至少有一个事件循环,就是调用了QCoreApplication::exec()的那个事件循环.不过,QThread也可以开启事件循环.只不 ...
- 基于MATLAB的腐蚀膨胀算法实现
本篇文章要分享的是基于MATLAB的腐蚀膨胀算法实现,腐蚀膨胀是形态学图像处理的基础,腐蚀在二值图像的基础上做“收缩”或“细化”操作,膨胀在二值图像的基础上做“加长”或“变粗”的操作. 什么是二值图像 ...
- Java Application和Java Applet的区别
Java Applet和Java Application在结构方面的主要区别表现在: (1)运行方式不同.Java Applet程序不能单独运行,它必须依附于一个用HTML语言编写的网页并嵌入其中,通 ...
- iOS 项目国际化(多语言支持)
按下图步骤创建好后使用如下代码即可实现国际化:self.infoLB.text = NSLocalizedString("key", comment: "") ...
- Delphi FastReport报表常用方法
Delphi FastReport报表常用方法 作者及来源: EasyPass - 博客园 收藏到→_→: 摘要: Delphi FastReport报表常用方法 点击这里! ...
- Linux-用户及权限
1. 用户组 RHEL 7/CentOS 7系统中的用户组有如下3类: 超级用户,UID 0:系统的超级用户. 系统用户,UID 1-999:系统中系统服务由不同用户运行,更加安全,默认被限制不能登录 ...
- MySQL--Percona-XtraDB-Cluster使用xtrabackup来添加节点
虽然PXC支持在线增加群集节点,但是目前尚未解决wsrep_sst_method=xtrabackup 或wsrep_sst_method=mysqldump时报错的问题,因此尝试手动完成xtraba ...
- WPF自定义Window窗体样式
资源文件代码: <ResourceDictionary xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation ...