支持向量机SMO算法实现(注释详细)
一:SVM算法
(一)见西瓜书及笔记
(二)统计学习方法及笔记
(三)推文https://zhuanlan.zhihu.com/p/34924821
(四)推文
支持向量机原理(一) 线性支持向量机
支持向量机原理(二) 线性支持向量机的软间隔最大化模型
二:SMO算法
(一)见西瓜书及笔记
(二)统计学习方法及笔记
(三)见机器学习实战及笔记
(四)推文
支持向量机原理(四)SMO算法原理
三:代码实现(一)SMO中的辅助函数
(一)加载数据集
import numpy as np
import matplotlib.pyplot as plt #一:SMO算法中的辅助函数
#加载数据集
def loadDataSet(filename):
dataSet = np.loadtxt(filename)
m,n = dataSet.shape
data_X = dataSet[:,:n-]
data_Y = dataSet[:,n-] return data_X,data_Y
(二)随机选取一个J值,作为α_2的下标索引
#随机选取一个数J,为后面内循环选取α_2做辅助(如果α选取不满足条件,就选择这个方法随机选取)
def selectJrand(i,m): #主要就是根据α_1的索引i,从所有数据集索引中随机选取一个作为α_2的索引
j = i
while j==i:
j = np.int(np.random.uniform(,m)) #从0~m中随机选取一个数,是进行整数化的
print("random choose index for α_2:%d"%(j))
return j #由于这里返回随机数,所以后面结果 可能导致不同
(三)根据关于α_1与α_2的优化问题对应的约束问题分析,对α进行截取约束

def clipAlpha(aj,H,L): #根据我们的SVM算法中的约束条件的分析,我们对获取的aj,进行了截取操作
if aj > H:
aj = H
if aj < L:
aj = L
return aj
四:代码实现(二)SMO中的支持函数
(一)定义一个数据结构,用于保存所有的重要值
#首先我们定义一个数据结构(类),来保存所有的重要值
class optStruct:
def __init__(self,data_X,data_Y,C,toler): #输入参数分别是数据集、类别标签、常数C用于软间隔、和容错率toler
self.X = data_X
self.label = data_Y
self.C = C
self.toler = toler #就是软间隔中的ε,调节最大间隔大小
self.m = data_X.shape[]
self.alphas = np.zeros(self.m) #存放每个样本点的α值
self.b = #存放阈值
self.eCache = np.zeros((self.m,)) #用于缓存误差,每个样本点对应一个Ei值,第一列为标识符,标志是否为有效值,第二列存放有效值
(二)计算每个样本点k的Ek值,就是计算误差值=预测值-标签值
#计算每个样本点k的Ek值,就是计算误差值=预测值-标签值
def calcEk(oS,k):
# 根据西瓜书6.,我们可以知道预测值如何使用α值进行求解
fxk = np.multiply(oS.alphas,oS.label).T@(oS.X@oS.X[k,:])+oS.b #np.multiply之后还是(m,),(oS.X@oS.X[k,:])之后是(m,),通过转置(,m)@(m,)-->实数后+b即可得到预测值fx
#获取误差值Ek
Ek = fxk - oS.label[k]
return Ek
(三)重点:内循环的启发式方法,获取最大差值|Ei-Ej|对应的Ej的索引J
#内循环的启发式方法,获取最大差值|Ei-Ej|对应的Ej的索引J
def selectJ(i,oS,Ei): #注意我们要传入第一个α对应的索引i和误差值Ei,后面会用到
maxK = - #用于保存临时最大索引
maxDeltaE = #用于保存临时最大差值--->|Ei-Ej|
Ej = #保存我们需要的Ej误差值 #重点:这里我们是把SMO最后一步(根据最新阈值b,来更新Ei)提到第一步来进行了,所以这一步是非常重要的
oS.eCache[i] = [1,Ei]
#开始获取各个Ek值,比较|Ei-Ej|获取Ej的所有
#获取所有有效的Ek值对应的索引
validECacheList = np.where(oS.eCache[:,]!=)[] #根据误差缓存中第一列非0,获取对应的有效误差值
if len(validECacheList) > : #如果有效误差缓存长度大于1(因为包括Ei),则正常进行获取j值,否则使用selectJradn方法选取一个随机J值
for k in validECacheList:
if k == i: #相同则不处理
continue
#开始计算Ek值,进行对比,获取最大差值
Ek = calcEk(oS,k)
deltaE = abs(Ei - Ek)
if deltaE > maxDeltaE: #更新Ej及其索引位置
maxK = k
maxDeltaE = deltaE
Ej = Ek
return maxK,Ej #返回我们找到的第二个变量α_2的位置
else: #没有有效误差缓存,则随机选取一个索引,进行返回
j = selectJrand(i,oS.m)
Ej = calcEk(oS,j)
return j,Ej
(四)实现更新Ek操作
#实现更新Ek操作,因为除了最后我们需要更新Ei之外,我们在内循环中计算α_1与α_2时还是需要用到E1与E2,
#因为每次的E1与E2由于上一次循环中更新了α值,所以这一次也是需要更新E1与E2值,所以单独实现一个更新Ek值的方法还是有必要的
def updateEk(oS,k):
Ek = calcEk(oS,k)
oS.eCache[k] = [,Ek] #第一列1,表示为有效标识
五:代码实现(三)SMO中的内循环函数
外循环是要找违背KKT条件最严重的样本点(每个样本点对应一个α),这里我们将外循环的该判别条件放入内循环中考虑。
(一)补充违背KKT条件选取
对于SVM中的KKT条件如下:

一般来说,我们首先选择违反0<αi<C⇒yig(xi)=1这个条件的点。
如果这些支持向量都满足KKT条件,再选择违反αi=0⇒yig(xi)≥1和 αi=C⇒yig(xi)≤1的点。
(二)分析0<αi<C⇒yig(xi)=1条件
对于上面违反KKT条件实际应用时的两种情况(或状态):
1. 0<αi⇒yig(xi)>1违背KKT条件
之所以不考虑α<c的情况,因为当yig(xi)>1时,必然出现α≠c,又因为0<α<c,所以我们只用考虑0<α⇒yig(xi)>1即可。
2. αi <C⇒yig(xi)<1违背KKT条件
之所以不考虑α>0的情况,因为当yig(xi)<1时,必然出现α≠0,又因为0<α<c,所以我们只用考虑α<C⇒yig(xi)<1即可。
(三)软间隔分析(同上)
相比较于硬间隔状态,多了一个松弛变量,所以我们考虑的时候加上该松弛变量即可。
1. 0<αi⇒yig(xi)>1+ξ违背KKT条件
2. αi <C⇒yig(xi)<1-ξ违背KKT条件
(四)代码分析
if ((oS.label[i]*Ei < -oS.toler) and (oS.alphas[i] < oS.C)) or\
((oS.label[i]*Ei > oS.toler) and (oS.alphas[i] > )): #注意:对于硬间隔,我们直接和1对比,对于软间隔,我们要和1 +或- ε对比
这里的代码和我们上面分析的违背KKT条件有所不同,所以下面进行推导:
主要看Ei的公式:Ei=g(xi)-yi
如(二)(三)分析可以知道,我们将进入优化的条件(即违背KKT条件)写成代码中形式:
(yiEi<-toler且α<C)或(yiEi>toler且α>C)
条件中yiEi=yi(g(xi)-yi)=yig(xi)-yi2
由于yi=±1,所以yi2=1
最后,我们就可以将代码中的原条件化简为:
(yig(xi)<1-toler且α<C)或(yig(xi)>1+toler且α>C)
即我们在(三)中的形式
(六)分析内循环中η值的性质
#计算η值=k_11+k_22-2k_12
eta = oS.X[i]@oS.X[i] + oS.X[j]@oS.X[j] - 2.0*oS.X[i]@oS.X[j] #eta性质可以知道是>=0的,所以我们只需要判断是否为0即可
if eta <= :
print("eta <= 0")
return
由下述η化简可以知道:
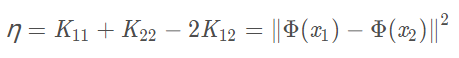
η的取值范围必然是η>=0。
又因为我们在推导SVM算法中知道:
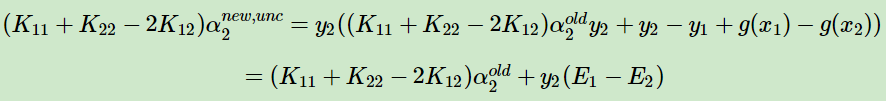
当η=0时,我们要求解的α无法更新,所以,我们只需要η>0即可。
所以,代码中判断η<=0时,不符合条件,退出即可。
(五)代码实现
#三:实现内循环函数,相比于外循环,这里包含了主要的更新操作
def innerL(i,oS): #由外循环提供i值(具体选取要违背kkT<这里实现>,使用交替遍历<外循环中实现>)---提供α_1的索引
Ei = calcEk(oS,i) #计算E1值,主要是为了下面KKT条件需要使用到 #如果下面违背了KKT条件,则正常进行α、Ek、b的更新,重点:后面单独说明下面是否满足违反KKT条件
if ((oS.label[i]*Ei < -oS.toler) and (oS.alphas[i] < oS.C)) or\
((oS.label[i]*Ei > oS.toler) and (oS.alphas[i] > 0)): #注意:对于硬间隔,我们直接和1对比,对于软间隔,我们要和1 +或- ε对比
#开始在内循环中,选取差值最大的α_2下标索引
j,Ej = selectJ(i,oS,Ei)
#因为后面要修改α_1与α_2的值,但是后面修改阈值b的时候需要用到新旧两个值,所以我们需要在更新α值之前进行保存旧值
alphaIold = oS.alphas[i].copy()
alphaJold = oS.alphas[j].copy() #分析约束条件(是对所有α都适用),一会对我们新的α_2进行截取纠正,注意:α_1是由α_2推出的,所以不需要进行验证了。
#如果y_1!=y_2异号时:
if oS.label[i] != oS.label[j]:
L = max(,alphaJold-alphaIold)
H = min(oS.C,oS.C+alphaJold-alphaIold)
else: #如果y_1==y_2同号时
L = max(,alphaJold+alphaIold-oS.C)
H = min(oS.C,alphaJold+alphaIold)
#上面就是将α_j调整到L,H之间
if L==H: #如果L==H,之间返回0,跳出这次循环,不进行改变(单值选择,没必要)
return #计算η值=k_11+k_22-2k_12
eta = oS.X[i]@oS.X[i] + oS.X[j]@oS.X[j] - 2.0*oS.X[i]@oS.X[j] #eta性质可以知道是>=0的,所以我们只需要判断是否为0即可
if eta <= :
print("eta <= 0")
return #当上面所有条件都满足以后,我们开始正式修改α_2值,并更新对应的Ek值
oS.alphas[j] += oS.label[j]*(Ei-Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
updateEk(oS,j) #查看α_2是否有足够的变化量,如果没有足够变化量,我们直接返回,不进行下面更新α_1,注意:因为α_2变化量较小,所以我们没有必要非得把值变回原来的旧值
if abs(oS.alphas[j] - alphaJold) < 0.00001:
print("J not move enough")
return #开始更新α_1值,和Ek值
oS.alphas[i] += oS.label[i]*oS.label[j]*(alphaJold-oS.alphas[j])
updateEk(oS,i) #开始更新阈值b,正好使用到了上面更新的Ek值
b1 = oS.b - Ei - oS.label[i] * (oS.alphas[i] - alphaIold) * oS.X[i] @ oS.X[i] - oS.label[j] * (
oS.alphas[j] - alphaJold) * oS.X[i] @ oS.X[j] b2 = oS.b - Ej - oS.label[i] * (oS.alphas[i] - alphaIold) * oS.X[i] @ oS.X[j] - oS.label[j] * (
oS.alphas[j] - alphaJold) * oS.X[j] @ oS.X[j] #根据统计学习方法中阈值b在每一步中都会进行更新,
#.当新值alpha_1不在界上时(<alpha_1<C),b_new的计算规则为:b_new=b1
#.当新值alpha_2不在界上时( < alpha_2 < C),b_new的计算规则为:b_new = b2
#.否则当alpha_1和alpha_2都不在界上时,b_new = /(b1+b2)
if oS.alphas[i] > and oS.alphas[i] < oS.C:
oS.b = b1
elif oS.alphas[j] > and oS.alphas[j] < oS.C:
oS.b = b2
else:
oS.b = /*(b1+b2) #注意:这里我们应该根据b_new更新一次Ei,但是我们这里没有写,因为我们将这一步提前到了最开始,即selectJ中 #以上全部更新完毕,开始返回标识
return
return #没有违背KKT条件
六:代码实现(四)SMO中的外循环函数
(一)交替遍历
交替遍历一种方式是在所有的数据集上进行单遍扫描,另一种是在非边界上(不在边界0或C上的值)进行单遍扫描
交替遍历:
交替是通过一个外循环来选择第一个alpha值的,并且其选择过程会在两种方式之间交替:
一种方式是在所有数据集上进行单遍扫描,
另一种方式则是在非边界alpha中实现单遍扫描,所谓非边界alpha指的是那些不等于边界0或C的alpha值。
对整个数据集的扫描相当容易,
而实现非边界alpha值的扫描时,首先需要建立这些alpha值的列表,然后对这个表进行遍历。
同时,该步骤会跳过那些已知不变的alpha值。
(二)代码实现
#四:开始外循环,由于我们在内循环中实现了KKT条件的判断,所以这里我们只需要进行交替遍历即可
#交替遍历一种方式是在所有的数据集上进行单遍扫描,另一种是在非边界上(不在边界0或C上的值)进行单遍扫描
# 交替遍历:
# 交替是通过一个外循环来选择第一个alpha值的,并且其选择过程会在两种方式之间交替:
# 一种方式是在所有数据集上进行单遍扫描,
# 另一种方式则是在非边界alpha中实现单遍扫描,所谓非边界alpha指的是那些不等于边界0或C的alpha值。
# 对整个数据集的扫描相当容易,
# 而实现非边界alpha值的扫描时,首先需要建立这些alpha值的列表,然后对这个表进行遍历。
# 同时,该步骤会跳过那些已知不变的alpha值。
def smoP(data_X,data_Y,C,toler,maxIter):
oS = optStruct(data_X,data_Y,C,toler)
iter =
entireSet = True #标志是否应该遍历整个数据集
alphaPairsChanged = #标志一次循环中α更新的次数
#开始进行迭代
#当iter >= maxIter或者((alphaPairsChanged == ) and not entireSet)退出循环
#前半个判断条件很好理解,后面的判断条件中,表示上一次循环中,是在整个数据集中遍历,并且没有α值更新过,则退出
while iter < maxIter and ((alphaPairsChanged > ) or entireSet):
alphaPairsChanged =
if entireSet: #entireSet是true,则在整个数据集上进行遍历
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS) #调用内循环
print("full dataset, iter: %d i:%d,pairs changed:%d"%(iter,i,alphaPairsChanged))
iter += #无论是否更新过,我们都计算迭代一次
else: #遍历非边界值
nonBounds = np.where((oS.alphas>) & (oS.alphas<C))[] #获取非边界值中的索引
for i in nonBounds: #开始遍历
alphaPairsChanged += innerL(i,oS)
print("non bound, iter: %d i:%d,pairs changed:%d"%(iter,i,alphaPairsChanged))
iter += #无论是否更新过,我们都计算迭代一次 #下面实现交替遍历
if entireSet:
entireSet = False
elif alphaPairsChanged == : #如果是在非边界上,并且α更新过。则entireSet还是False,下一次还是在非边界上进行遍历。可以认为这里是倾向于非边界遍历,因为非边界遍历的样本更符合内循环中的违反KKT条件
entireSet = True print("iteration number: %d"%iter) return oS.b,oS.alphas
七:根据α实现求解权重W值
(一)公式
根据西瓜书中6.37:
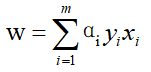
求解权重向量
(二)代码实现
def calcWs(alphas,data_X,data_Y):
#根据西瓜书6.37求W
m,n = data_X.shape
w = np.zeros(n)
for i in range(m):
w += alphas[i]*data_Y[i]*data_X[i].T return w
八:测试SMO算法的实现
data_X,data_Y = loadDataSet("testSet.txt")
C = 0.6
toler = 0.001
maxIter =
b,alphas = smoP(data_X,data_Y,C,toler,maxIter)
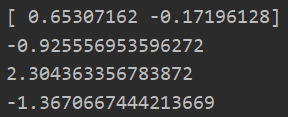
ws = calcWs(alphas,data_X,data_Y) #含有随机操作,所以有多种可能性结果
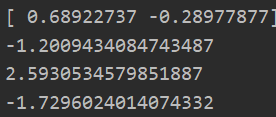
print(ws)
test = data_X[]@ws+b
print(test)
test = data_X[]@ws+b
print(test)
test = data_X[]@ws+b
print(test)
九:绘制图像和支持向量
(一)代码实现
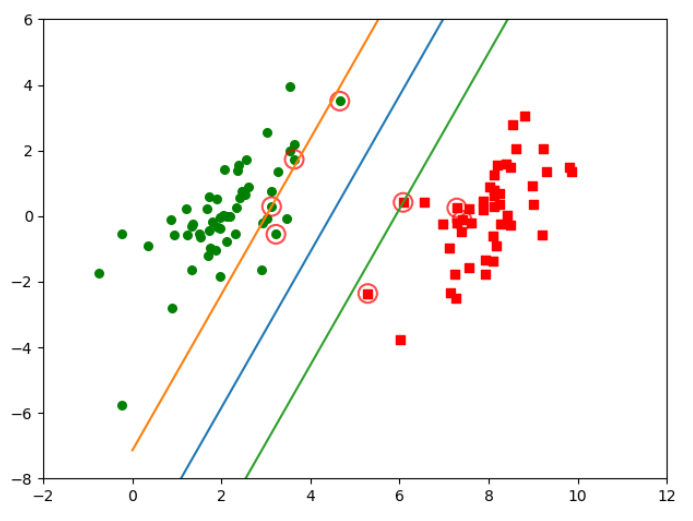
#绘制图像
def plotFigure(weights, b,toler,data_X,data_Y):
m,n = data_X.shape
# 进行数据集分类操作
cls_1x = data_X[np.where(data_Y==)]
cls_1y = data_Y[np.where(data_Y==)]
cls_2x = data_X[np.where(data_Y!=)]
cls_2y = data_Y[np.where(data_Y!=)] plt.scatter(cls_1x[:,].flatten(), cls_1x[:,].flatten(), s=, c='r', marker='s')
plt.scatter(cls_2x[:,].flatten(), cls_2x[:,].flatten(), s=, c='g') # 画出 SVM 分类直线
xx = np.arange(, , 0.1)
# 由分类直线 weights[] * xx + weights[] * yy1 + b = 易得下式
yy1 = (-weights[] * xx - b) / weights[]
# 由分类直线 weights[] * xx + weights[] * yy2 + b + = 易得下式
yy2 = (-weights[] * xx - b - - toler) / weights[]
# 由分类直线 weights[] * xx + weights[] * yy3 + b - = 易得下式
yy3 = (-weights[] * xx - b + + toler) / weights[]
plt.plot(xx, yy1.T)
plt.plot(xx, yy2.T)
plt.plot(xx, yy3.T) # 画出支持向量点
for i in range(m):
if alphas[i] > 0.0:
plt.scatter(data_X[i, ], data_X[i, ], s=, c='none', alpha=0.7, linewidth=1.5, edgecolor='red') plt.xlim((-, ))
plt.ylim((-, ))
plt.show() plotFigure(ws,b,toler,data_X,data_Y)
(二)图像显示
支持向量机SMO算法实现(注释详细)的更多相关文章
- 支持向量机-SMO算法简化版
SMO:序列最小优化 SMO算法:将大优化问题分解为多个小优化问题来求解 SMO算法的目标是求出一系列的alpha和b,一旦求出这些alpha,就很容易计算出权重向量w,并得到分隔超平面 工作原理:每 ...
- 机器学习之支持向量机(二):SMO算法
注:关于支持向量机系列文章是借鉴大神的神作,加以自己的理解写成的:若对原作者有损请告知,我会及时处理.转载请标明来源. 序: 我在支持向量机系列中主要讲支持向量机的公式推导,第一部分讲到推出拉格朗日对 ...
- 统计学习方法c++实现之六 支持向量机(SVM)及SMO算法
前言 支持向量机(SVM)是一种很重要的机器学习分类算法,本身是一种线性分类算法,但是由于加入了核技巧,使得SVM也可以进行非线性数据的分类:SVM本来是一种二分类分类器,但是可以扩展到多分类,本篇不 ...
- 机器学习——支持向量机(SVM)之Platt SMO算法
Platt SMO算法是通过一个外循环来选择第一个alpha值的,并且其选择过程会在两种方式之间进行交替: 一种方式是在所有数据集上进行单遍扫描,另一种方式则是在非边界alpha中实现单遍扫描. 所谓 ...
- 支持向量机原理(四)SMO算法原理
支持向量机原理(一) 线性支持向量机 支持向量机原理(二) 线性支持向量机的软间隔最大化模型 支持向量机原理(三)线性不可分支持向量机与核函数 支持向量机原理(四)SMO算法原理 支持向量机原理(五) ...
- SVM-非线性支持向量机及SMO算法
SVM-非线性支持向量机及SMO算法 如果您想体验更好的阅读:请戳这里littlefish.top 线性不可分情况 线性可分问题的支持向量机学习方法,对线性不可分训练数据是不适用的,为了满足函数间隔大 ...
- [笔记]关于支持向量机(SVM)中 SMO算法的学习(一)理论总结
1. 前言 最近又重新复习了一遍支持向量机(SVM).其实个人感觉SVM整体可以分成三个部分: 1. SVM理论本身:包括最大间隔超平面(Maximum Margin Classifier),拉格朗日 ...
- 支持向量机(Support Vector Machine)-----SVM之SMO算法(转)
此文转自两篇博文 有修改 序列最小优化算法(英语:Sequential minimal optimization, SMO)是一种用于解决支持向量机训练过程中所产生优化问题的算法.SMO由微软研究院的 ...
- 机器学习算法整理(七)支持向量机以及SMO算法实现
以下均为自己看视频做的笔记,自用,侵删! 还参考了:http://www.ai-start.com/ml2014/ 在监督学习中,许多学习算法的性能都非常类似,因此,重要的不是你该选择使用学习算法A还 ...
随机推荐
- python0.1
python基础 python是一种高级编程语言,而编程语言分为3种 编程语言 编程语言是一种人与计算机沟通的工具. 编程就是就将人的需求通过攥写编程语言命令计算机完成指令. 编程的意义在于将人类的生 ...
- 防火墙识别、负载均衡识别、waf识别
防火墙识别: 通过发送SYN和ACK数据包并分析回包可以大概判断端口是否被防火墙过滤,对应关系如下表: Python代码实现: #!/usr/bin/python from scapy.all imp ...
- Python3-shelve模块-持久化字典
Python3中的shelve提供了持久化字典对象 和字典基本一个样,只不过数据保存在了文件中,没什么好说的,直接上代码 注: 1.打开文件后不要忘记关闭文件 2.键只能是字符串,值可以是任何值 3. ...
- 【Spring注解驱动开发】关于BeanPostProcessor后置处理器,你了解多少?
写在前面 有些小伙伴问我,学习Spring是不是不用学习到这么细节的程度啊?感觉这些细节的部分在实际工作中使用不到啊,我到底需不需要学习到这么细节的程度呢?我的答案是:有必要学习到这么细节的程度,而且 ...
- Codeforces Round #652 (Div. 2) 总结
A:问正n边形的一条边和x轴平行的时候有没有一条边和y轴重合,直接判断n是否是4的倍数 #include <iostream> #include <cstdio> #inclu ...
- 并发05--JAVA并发容器、框架、原子操作类
一.ConcurrentHashMap的实现原理与使用 1.为什么要使用ConsurrentHashMap 两个原因,hashMap线程不安全(多线程并发put时,可能造成Entry链表变成环形数据结 ...
- vue全家桶(2.3)
3.4.嵌套路由 实际生活中的应用界面,通常由多层嵌套的组件组合而成.同样地,URL 中各段动态路径也按某种结构对应嵌套的各层组件,例如: 再来看看下面这种更直观的嵌套图: 接下来我们需要实现下面这种 ...
- js语法基础入门(5.2)
5.2.循环结构 当一段代码被重复调用多次的时候,可以用循环结构来实现,就像第一个实例中出现的场景一样,需要重复询问对方是否有空,这样就可以使用循环结构来搞定 5.2.1.for循环语句 //语法结构 ...
- 学习前端的时候,突然想起了Sharepoint母版页里的占位符,算知识的融会不?
今天看到这个段话,我就想起来当时学习Sharepoint的时候,总是搞不明白我们老师讲的那个母版页里的占位符到底是干啥的.现在看到了类似的东西,让我想起来了之前一直搞不懂的东西,很感慨. (完)
- css3条件判断_@supports的用法/Window.CSS.supports()的使用
为了判断浏览器是否支持css3的一些新属性样式,当不兼容该样式的时候,我们可以更优雅的降级处理.这就需要使用到css3的条件判断功能:在css中支持@supports标记.或者在js中使用CSS.su ...