2020-06-02:千万级数据量的list找一个数据。
福哥答案2020-06-02:
对于千万级长度的数组单值查找:
序号小的,单线程占明显优势;序号大的,多线程占明显优势。
单线程时间不稳定,多线程时间稳定。
go语言测试代码如下:
package main import (
"fmt"
"math/rand"
"testing"
"time"
) const (
ARRLEN = 1000_0000
) var arr []int
var target int func init() {
arr = make([]int, ARRLEN)
rand.Seed(time.Now().UnixNano())
for i := 0; i < ARRLEN; i++ {
arr[i] = rand.Intn(10_0000_0000)
}
target = arr[9990001]
fmt.Println("初始化完成")
} //go test -v -test.run TestMutiThreadsSearch
func TestMutiThreadsSearch(t *testing.T) {
fmt.Println("多线程开始")
now := time.Now()
const MAXGE = 10000
const MAXHANG = 1000
index := -1
chindex := make(chan struct{}, 0)
ch := make(chan struct{}, MAXHANG)
f := func(i int) {
for j := 0; j < MAXGE; j++ {
if target == arr[i*MAXGE+j] {
index = i*MAXGE + j
fmt.Println("找到了-------------------", time.Now().Sub(now))
chindex <- struct{}{}
break
} }
ch <- struct{}{}
}
for i := 0; i < MAXHANG; i++ {
go f(i)
}
for i := 0; i < MAXHANG; i++ {
select {
case <-chindex: //已经找到了
i = MAXHANG
break
case <-ch:
break
}
}
if index == -1 || index == MAXHANG {
fmt.Println(target, "未找到")
} else {
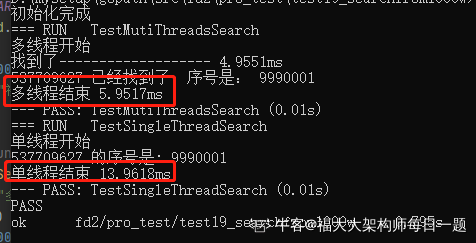
fmt.Println(target, "已经找到了,序号是:", index)
}
fmt.Println("多线程结束", time.Now().Sub(now))
} //go test -v -test.run TestSingleThreadToSum
//go test -bench=. -test.run TestSingleThreadToSum
//go test -v -cover -run TestSingleThreadToSum
func TestSingleThreadSearch(t *testing.T) {
fmt.Println("单线程开始")
now := time.Now()
//target := 5
index := -1
for i := 0; i < ARRLEN; i++ {
if target == arr[i] {
index = i
break
}
}
fmt.Println(target, "的序号是:", index)
fmt.Println("单线程结束", time.Now().Sub(now))
}
敲命令go test -v:
当查找序号为0时:

当查找序号为4990001时:

当查找序号为9990001时:
2020-06-02:千万级数据量的list找一个数据。的更多相关文章
- mysql千万级数据量查询出所有重复的记录
查询重复的字段需要创建索引,多个条件则创建组合索引,各个条件的索引都存在则不必须创建组合索引 有些情况直接使用GROUP BY HAVING则能直接解决:但是有些情况下查询缓慢,则需要使用下面其他的方 ...
- 完全用nosql轻松打造千万级数据量的微博系统(转)
原文:http://www.cnblogs.com/imxiu/p/3505213.html 其实微博是一个结构相对简单,但数据量却是很庞大的一种产品.标题所说的是千万级数据量 也并不是一千万条微博信 ...
- 完全用nosql轻松打造千万级数据量的微博系统
其实微博是一个结构相对简单,但数据量却是很庞大的一种产品.标题所说的是千万级数据量也并不是一千万条微博信息而已,而是千万级订阅关系之间发布.在看 我这篇文章之前,大多数人都看过sina的杨卫华大牛的微 ...
- (转载)MYSQL千万级数据量的优化方法积累
转载自:http://blog.sina.com.cn/s/blog_85ead02a0101csci.html MYSQL千万级数据量的优化方法积累 1.分库分表 很明显,一个主表(也就是很重要的表 ...
- MySQL 千万 级数据量根据(索引)优化 查询 速度
一.索引的作用 索引通俗来讲就相当于书的目录,当我们根据条件查询的时候,没有索引,便需要全表扫描,数据量少还可以,一旦数据量超过百万甚至千万,一条查询sql执行往往需要几十秒甚至更多,5秒以上就已经让 ...
- mysql千万级数据量根据索引优化查询速度
(一)索引的作用 索引通俗来讲就相当于书的目录,当我们根据条件查询的时候,没有索引,便需要全表扫描,数据量少还可以,一旦数据量超过百万甚至千万,一条查询sql执行往往需要几十秒甚至更多,5秒以上就已经 ...
- MYSQL千万级数据量的优化方法积累
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- [自学] MIT的EECS本科+研究生课程【持续更新中-2020.06.02】
前言 我的本科是读的电子信息工程,研究生跟着老师做项目,参与到深度学习中来,毕业后做了算法工程师,工作之后愈发发现,不论从事什么岗位,基础都很重要,但现在也没有时间再读一遍本科了,自学的话也不知道从何 ...
- 对SQLServer错误使用聚集索引的优化案例(千万级数据量)
前言: 半个月前发了文章 SQLServer聚集索引导致的插入性能低 终于等到生产环境休整半天,这篇文章是对前文的实际操作. 以下正文开始: 异常:近期发现偶尔有新数据插入超时. 分析:插入条码有多种 ...
随机推荐
- Python 爬取异步加载的数据
在我们的工作中,可能会遇到这样的情况:我们需要爬取的数据是通过ajax异步加载的,这样的话通过requests得到的只是一个静态页面,而我们需要的是ajax动态加载的数据! 那我们应该怎么办呢??? ...
- (1)为什么要使用webpack?
1.在网页中有哪些常见的静态资源? Js: .js .jsx .coffee .ts Css: .css .less .sass .scss Images: .jpg .png .gif .bmp . ...
- linux管理防火墙
操作系统环境:CentOS Linux release 7.0.1406(Core) 64位CentOS 7.0默认使用的是firewall作为防火墙,这里改为iptables防火墙步骤. 1.关闭f ...
- CSS变形动画
CSS变形动画 前言 在开始介绍CSS变形动画之前,可以先了解一下学习了它之后能做什么,有什么用,这样你看这篇文章可能会有一些动力. 学习了CSS变形动画后,你可以为你的页面做出很多炫酷的效果,如一个 ...
- springboot整合Druid(德鲁伊)配置多数据源数据库连接池
pom.xml <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-ja ...
- 带你理解Lock锁原理
同样是锁,先说说synchronized和lock的区别: synchronized是java关键字,是用c++实现的:而lock是用java类,用java可以实现 synchronized可以锁住代 ...
- MySQL(二)表的操作与简单数据操作
六大约束:主键约束.外键约束.非空约束.唯一约束.默认约束.自动增加 1.not null非空 2.defaul默认值,用于保证该字段的默认值 ; 比如年龄:1900-10-10 3.primar k ...
- xctf-pwn pwn200
刚看完题目觉得和前面的level3差不多,只是没有给libc而已... 看完大佬的exp之后整个人都不好了.....果然我还是太菜了 32位开了NX sub_8048484,read函数,明显的栈溢出 ...
- python中的subprocess.Popen()使用详解---以及注意的问题(死锁)
从python2.4版本开始,可以用subprocess这个模块来产生子进程,并连接到子进程的标准输入/输出/错误中去,还可以得到子进程的返回值. subprocess意在替代其他几个老的模块或者函数 ...
- Django创建项目时应该要做的几件事
终于可以在假期开始学习 Django 啦 !