B站自动爬取器并制作词云
效果
词云展示

弹幕展示
爬取弹幕过程
基本步骤
1.寻找视频url
2.构造请求头
3.寻找弹幕地址
4.根据弹幕地址运用正则或xpath爬取
寻找B站视频的url
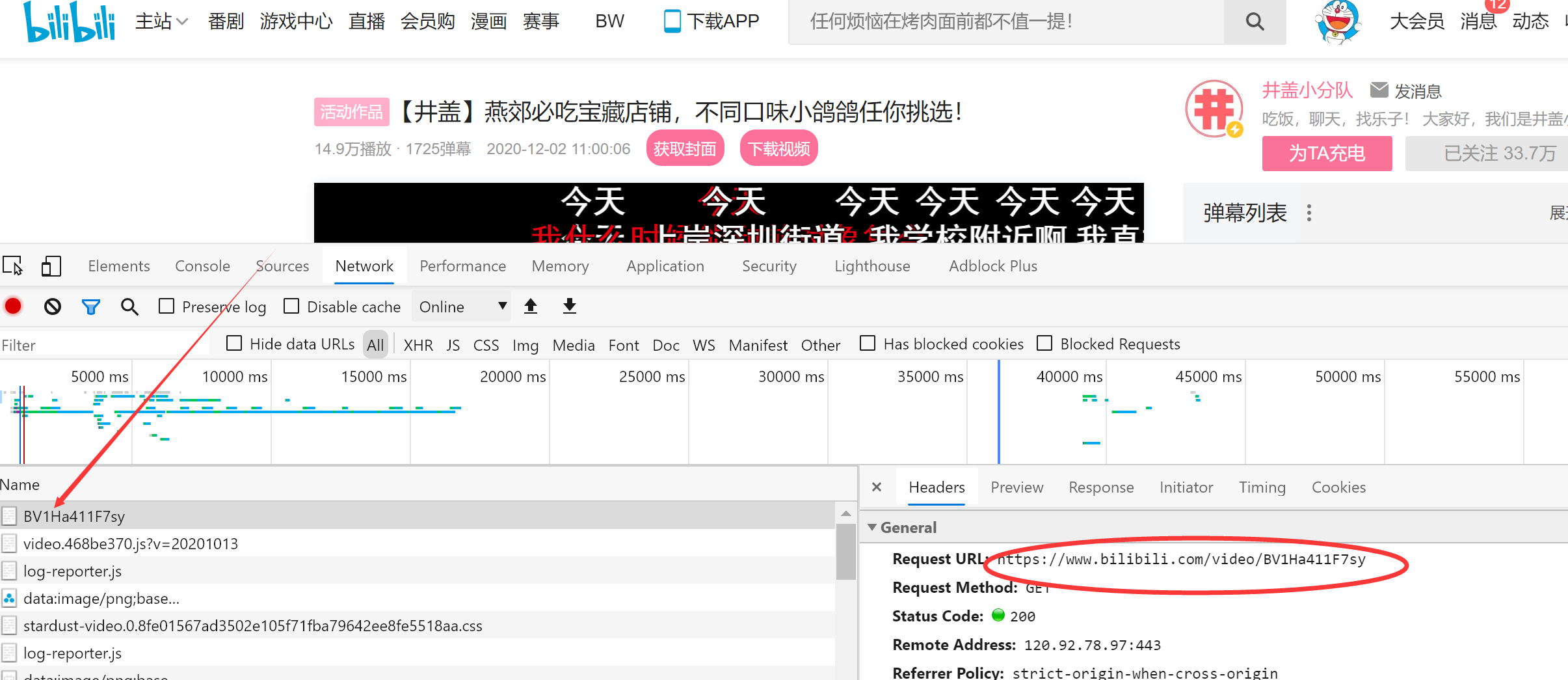
制作请求头
headers = {"User-Agent": "浏览器中的User-Agent"}
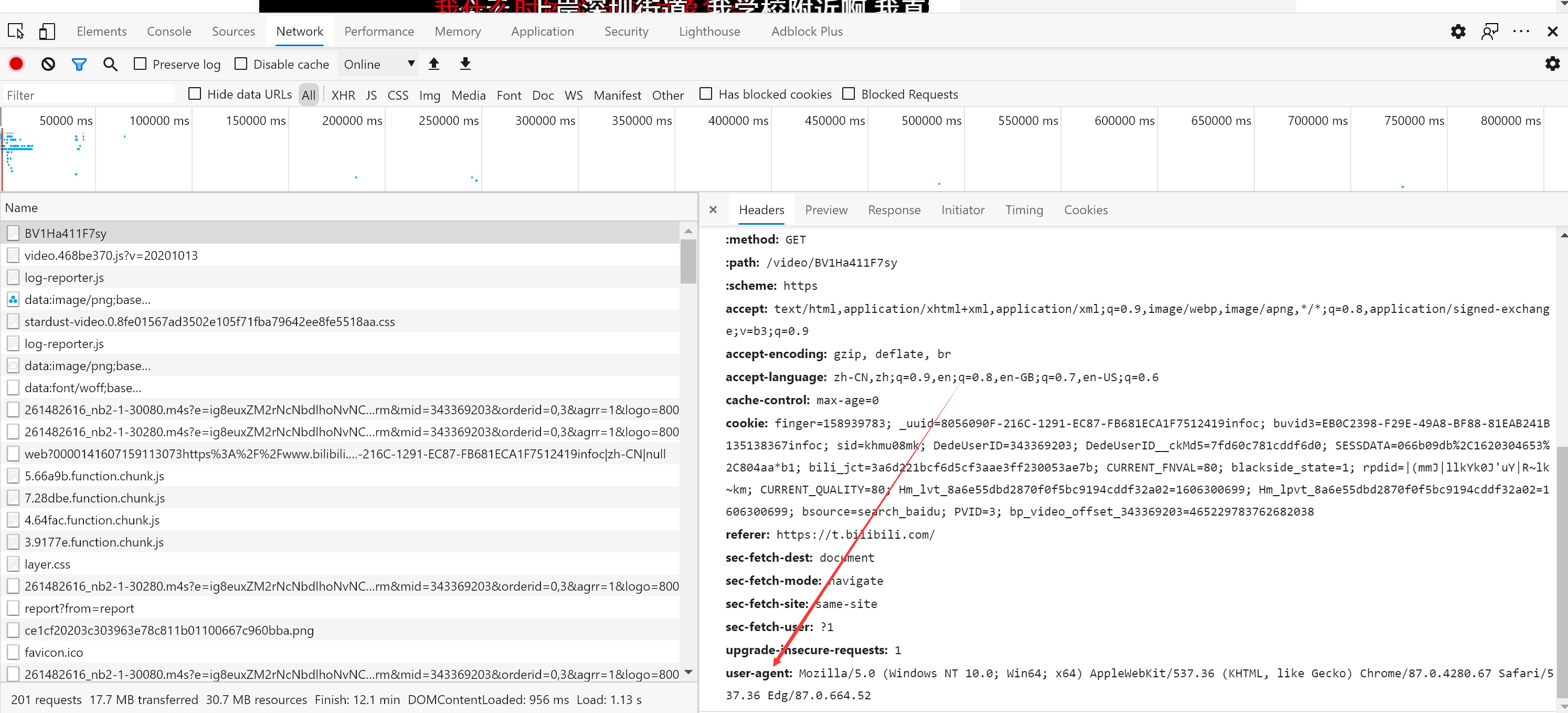
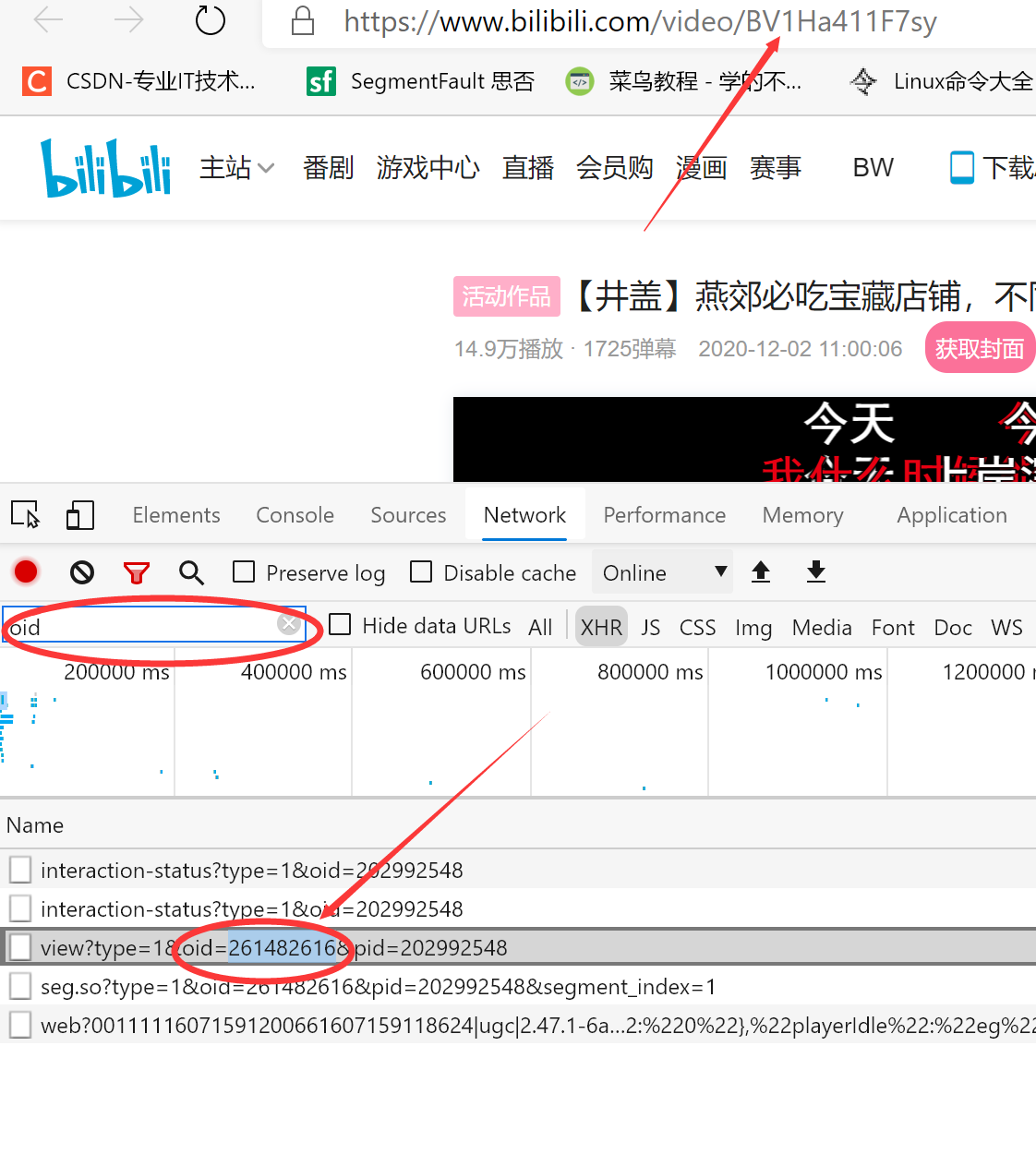
弹幕地址
1.代码通过这位博主改进的(https://www.cnblogs.com/wuren-best/p/12566297.html)
2.由于B站弹幕地址改变变得越来越难寻找到 但通过原来的弹幕地址改变下oid还是可以爬取到的
运用xpath爬取弹幕
弹幕包含在xml中的中,运用xpath取出即可

html = etree.HTML(response.content)
word_list = html.xpath("//d/text()")
词云制作
fp = open("%s弹幕.text" % self.get_tile(), 'r', encoding='utf-8')
text = fp.read()
# 字体为.TTF格式的
wd = WordCloud(background_color='white', width=300, height=316, margin=2,
font_path='钟齐段宁行书.TTF').generate(text)
plt.figure(dpi=500)
# 显示词云
plt.imshow(wd)
# 去除x,y 轴
plt.axis('off')
plt.show()
# 保存词云
wd.to_file("%s弹幕.jpg" % self.get_tile())
完整代码
# coding=utf-8
import requests
from lxml import etree
import re
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
class BiliSpider:
def __init__(self, BV, oid):
# 构造要爬取的视频url地址
self.BVurlBV = BV
self.BVurloid = oid
self.BVurl = "https://m.bilibili.com/video/" + BV
self.headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Mobile Safari/537.36"}
# 弹幕都是在一个url请求中,该url请求在视频url的js脚本中构造
def getXml_url(self):
# 获取该视频网页的内容
response = requests.get(self.BVurl, headers=self.headers)
html_str = response.content.decode()
# 使用正则找出该弹幕地址
# 弹幕地址为https://comment.bilibili.com/oid.xml
# 格式为:https://comment.bilibili.com/168087953.xml
# 我们分隔出的是地址中的弹幕文件名,即 168087953
getWord_url = self.BVurloid
# 组装成要请求的xml地址
xml_url = "https://comment.bilibili.com/{}.xml".format(getWord_url)
return xml_url
# Xpath不能解析指明编码格式的字符串,所以此处我们不解码,还是二进制文本
def parse_url(self, url):
response = requests.get(url, headers=self.headers)
# print(response.content)
return response.content
# 弹幕包含在xml中的<d></d>中,取出即可
def get_word_list(self, str):
html = etree.HTML(str)
word_list = html.xpath("//d/text()")
return word_list
# 标题及up主名
def get_tile(self):
response = requests.get(self.BVurl, headers=self.headers)
# print(response.text)
html_str = response.content.decode()
html = etree.HTML(html_str)
up_name = html.xpath('//span/text()')[1]
up_tile = html.xpath('//h1/text()')[0]
tile = []
for i in up_name, up_tile:
tile.append(i)
# print(up_name)
# print(up_tile)
# print(tile)
return tile[0]+tile[1]
# BV1ZV411a7vy 261482616
# 保存弹幕为文本格式
def save_file(self, data):
"""
保存弹幕
:param data: 弹幕信息
:return:
"""
with open("%s弹幕.text" % self.get_tile(), 'w', encoding='utf8') as f:
for line in data:
f.write(line)
f.write('\n')
# 词云
def wardcloud_(self):
fp = open("%s弹幕.text" % self.get_tile(), 'r', encoding='utf-8')
text = fp.read()
wd = WordCloud(background_color='white', width=300, height=316, margin=2,
font_path='钟齐段宁行书.TTF').generate(text)
plt.figure(dpi=500)
# 显示词云
plt.imshow(wd)
# 去除x,y 轴
plt.axis('off')
plt.show()
# 保存词云
wd.to_file("%s弹幕.jpg" % self.get_tile())
def run(self):
# 1.根据BV号获取弹幕的地址
start_url = self.getXml_url()
# 2.请求并解析数据
xml_str = self.parse_url(start_url)
# print(start_url)
word_list = self.get_word_list(xml_str)
# 3.打印
for word in word_list:
print(word)
# 4.保存
self.save_file(word_list)
# 5.词云
self.wardcloud_()
if __name__ == '__main__':
BVName = input("请输入要爬取的视频的BV号:")
oid = input("请输入要爬取的视频的oid(F12中找oid)号:")
spider = BiliSpider(BVName, oid)
spider.run()
注:BV号和oid
B站自动爬取器并制作词云的更多相关文章
- python爬取B站视频弹幕分析并制作词云
1.分析网页 视频地址: www.bilibili.com/video/BV19E… 本身博主同时也是一名up主,虽然已经断更好久了,但是不妨碍我爬取弹幕信息来分析呀. 这次我选取的是自己 唯一的爆款 ...
- 爬取B站弹幕并且制作词云
目录 爬取弹幕 1. 从手机端口进入网页爬取找到接口 2.代码 制作词云 1.文件读取 2.代码 爬取弹幕 1. 从手机端口进入网页爬取找到接口 2.代码 import requests from l ...
- 如何手动写一个Python脚本自动爬取Bilibili小视频
如何手动写一个Python脚本自动爬取Bilibili小视频 国庆结束之余,某个不务正业的码农不好好干活,在B站瞎逛着,毕竟国庆嘛,还让不让人休息了诶-- 我身边的很多小伙伴们在朋友圈里面晒着出去游玩 ...
- quotes 整站数据爬取存mongo
安装完成scrapy后爬取部分信息已经不能满足躁动的心了,那么试试http://quotes.toscrape.com/整站数据爬取 第一部分 项目创建 1.进入到存储项目的文件夹,执行指令 scra ...
- Python爬虫入门教程 25-100 知乎文章图片爬取器之一
1. 知乎文章图片写在前面 今天开始尝试爬取一下知乎,看一下这个网站都有什么好玩的内容可以爬取到,可能断断续续会写几篇文章,今天首先爬取最简单的,单一文章的所有回答,爬取这个没有什么难度. 找到我们要 ...
- Crawlspider的自动爬取
引子 : 如果想要爬取 糗事百科 的全栈数据的方法 ? 方法一 : 基于scrapy框架中的scrapy的递归爬取进行实现(requests模块递归回调parse方法) . 方法二 : 基于Crawl ...
- scrapy框架之CrawlSpider全站自动爬取
全站数据爬取的方式 1.通过递归的方式进行深度和广度爬取全站数据,可参考相关博文(全站图片爬取),手动借助scrapy.Request模块发起请求. 2.对于一定规则网站的全站数据爬取,可以使用Cra ...
- B站弹幕爬取
B站弹幕爬取 单个视频弹幕的爬取 B站弹幕都是以xml文件的形式存在的,而xml文件的请求地址是如下形式: http://comment.bilibili.com/233182992.xml ...
- python网络爬虫之使用scrapy自动爬取多个网页
前面介绍的scrapy爬虫只能爬取单个网页.如果我们想爬取多个网页.比如网上的小说该如何如何操作呢.比如下面的这样的结构.是小说的第一篇.可以点击返回目录还是下一页 对应的网页代码: 我们再看进入后面 ...
随机推荐
- 2Git分支问题
1,查看所有分支: git branch *号在哪表明当前分支在哪. 2,新建一个分支: git branch featureq(分支名) 转到该分支下: git checkout featureq ...
- Uipath_考证学习之路
写在前面 第一次考证的时候,就是为了考证而考证,从网上获取了试题,修改了一下,就通过了,对 REFramework的了解甚少,经过几周的学习,决定赶在 4.30号考证收费之前再重新考一次. 原文章发表 ...
- linux 协议栈 实现--编码小知识分析
unlikely 以及likely 作用: rcu_read_lock 以及rcu_read_unlock 作用: rcu_dereference .rcu_dereference_protecte ...
- redis重点ppt
- rgw配置删除快速回收对象
前言 做rgw测试的时候,经常会有删除文件的操作,而用默认的参数的时候,rgw是通过gc回收机制来处理删除对象的,这个对于生产环境是有好处的,把删除对业务系统的压力分摊到不同的时间点,但是测试的时候, ...
- 自动化测试_移动端测试(二)—— Appium原理
一.什么是Appium Appium是一个开源.跨平台的测试框架,可以用来测试原生及混合的移动端应用.Appium支持IOS.Android及FirefoxOS平台.Appium使用WebDriver ...
- Spring源码理论
Spring Bean的创建过程: Spring容器获取Bean和创建Bean都会调用getBean()方法. getBean()方法 1)getBean()方法内部最终调用doGetBean()方法 ...
- phpmyadmin远程代码执行漏洞(CVE-2016-5734)
简介 环境复现:https://github.com/vulhub/vulhub 线上平台:榆林学院内可使用协会内部的网络安全实验平台 phpMyAdmin是一套开源的.基于Web的MySQL数据库管 ...
- 安装mongodb扩展
curl -O https://pecl.php.net/get/mongodb-1.2.3.tgz tar zxf mongodb-1.2.3.tgzcd mongodb-1.2.3 phpize ...
- 总是说spring难学?来看完这些spring的注解及其解释,真香!
前言 用过spring的人都知道,spring简单的通过注解就可以完成很多事情,但这些东西是如何实现的呢以及如何应用到我们自己的代码中?接下来,让我们一起开启注解的旅程. 1. @Controller ...