第14.4节 使用IE浏览器获取网站访问的http信息
上节《第14.3节 使用google浏览器获取网站访问的http信息》中介绍了使用Google浏览器怎么获取网站访问的http相关报文信息,本节介绍IE浏览器中怎么获取相关信息。以上节为基础,部分http相关知识在此不再介绍。
步骤1:登录网站并打开准备获取信息的网页
步骤2:在网页上按F12或选择对应内容后鼠标右键选择检查元素(如下图)
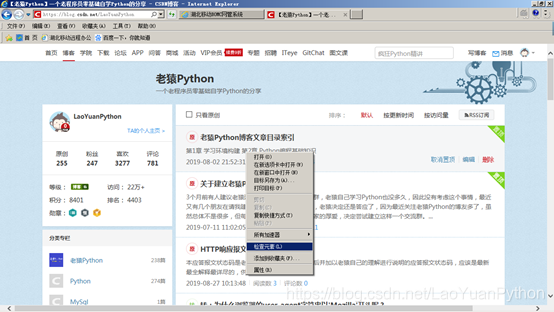
打开开发者工具并点击下图左上角蓝色标记的“启用网络流量捕获”的按钮开始捕获网页的网络报文:

回到网页访问窗口刷新页面再回到开发者工具窗口禁用捕获,防止捕获多余的网络信息干扰分析。选择第一条网络报文(如下图):
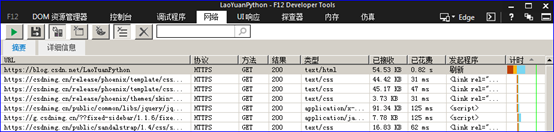
鼠标双击打开,获得该请求的具体信息如下图:
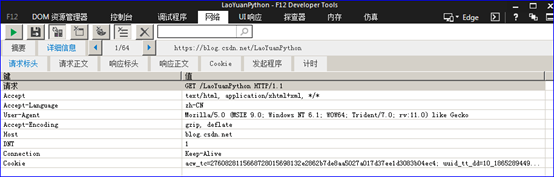
选择下图黄色标记的“响应标头”,出现响应报文头信息如下:

这样就获取了IE浏览器的请求报文相关信息,同样可以获取响应报文的信息。获取这些信息后,我们可以复制相关信息用于Python应用中模拟浏览器访问网站。
本节老猿介绍的案例是基于IE11版本的,当然浏览器的不同版本上述界面会有所差异,但总体应该差不多。除Google和IE外的其他浏览器老猿没有研究,不知道是否有开发者工具,如果有相关功能应该也差不多的。
老猿Python,跟老猿学Python!
博客地址:https://blog.csdn.net/LaoYuanPython
老猿Python博客文章目录:https://blog.csdn.net/LaoYuanPython/article/details/98245036
请大家多多支持,点赞、评论和加关注!谢谢!
第14.4节 使用IE浏览器获取网站访问的http信息的更多相关文章
- 第14.7节 Python模拟浏览器访问实现http报文体压缩传输
一. 引言 在<第14.6节 Python模拟浏览器访问网页的实现代码>介绍了使用urllib包的request模块访问网页的方法.但上节特别说明http报文头Accept-Encodin ...
- YII2.0 获取当前访问地址/IP信息
假设我们当前页面的访问地址是:http://localhost/CMS/public/index.php?r=news&id=1 一. 1.获取当前域名:echo Yii::app()-> ...
- 第14.5节 利用浏览器获取的http信息构造Python网页访问的http请求头
一. 引言 在<第14.3节 使用google浏览器获取网站访问的http信息>和<第14.4节 使用IE浏览器获取网站访问的http信息>中介绍了使用Google浏览器和IE ...
- 第14.17节 爬虫实战3: request+BeautifulSoup实现自动获取本机上网公网地址
一. 引言 一般情况下,没有特殊要求的客户,宽带服务提供商提供的上网服务,给客户家庭宽带分配的地址都是一个宽带服务提供商的内部服务地址,真正对外访问时通过NAT进行映射到一个公网地址,如果我们想确认自 ...
- 第14.6节 使用Python urllib.request模拟浏览器访问网页的实现代码
Python要访问一个网页并读取网页内容非常简单,在利用<第14.5节 利用浏览器获取的http信息构造Python网页访问的http请求头>的方法构建了请求http报文的请求头情况下,使 ...
- 第14.1节 通过Python爬取网页的学习步骤
如果要从一个互联网前端开发的小白,学习爬虫开发,结合自己的经验老猿认为爬虫学习之路应该是这样的: 一. 了解HTML语言及css知识 这方面的知识请大家通过w3school 去学习,老猿对于html总 ...
- 第14.9节 Python中使用urllib.request+BeautifulSoup获取url访问的基本信息
利用urllib.request读取url文档的内容并使用BeautifulSoup解析后,可以通过一些基本的BeautifulSoup对象输出html文档的基本信息.以博文<第14.6节 使用 ...
- 第14.18节 爬虫实战4: request+BeautifulSoup+os实现利用公众服务Wi-Fi作为公网IP动态地址池
写在前面:本文相关方法为作者独创,仅供参考学习爬虫技术使用,请勿用作它途,禁止转载! 一. 引言 在爬虫爬取网页时,有时候希望不同的时候能以不同公网地址去爬取相关的内容,去网上购买地址资源池是大部分人 ...
- 第14.16节 爬虫实战2:赠人玫瑰,手留余香! request+BeautifulSoup实现csdn博文自动点赞
写在前面:本文仅供参考学习,请勿用作它途,禁止转载! 在<第14.14节 爬虫实战准备:csdn博文点赞过程http请求和响应信息分析>老猿分析了csdn博文点赞处理的http请求和响应报 ...
随机推荐
- .net core中的哪些过滤器
前言 书承接上文,咱们上回说到,.net core中各种日志框架, 今天我讲讲.net core中的内置过滤器吧! 1.什么是过滤器? ASP.NET Core中的筛选器允许代码在请求处理管道中的特定 ...
- CentOS6.x 安装 nginx-1.19.4
1.下载nginx http://nginx.org/en/download.html wget http://nginx.org/download/nginx-1.19.4.tar.gz 2.解压 ...
- ostringstream、istringstream、stringstream(转)
看一下C++风格的串流控制,C++引入了ostringstream.istringstream.stringstream这三个类,要使用他们创建对象就必须包含sstream.h头文件. istring ...
- 理解 Linux 的硬链接与软链接(转)
Linux 的文件与目录 现代操作系统为解决信息能独立于进程之外被长期存储引入了文件,文件作为进程创建信息的逻辑单元可被多个进程并发使用.在 UNIX 系统中,操作系统为磁盘上的文本与图像.鼠标与键盘 ...
- uboot——初始化阶段
start.S |-------------设置cpu状态 |--------------开cache |--------------获得启动方式 |------------------------- ...
- parted分区对齐
分区提示未对齐 [root@lab8106 ceph]# parted /dev/sdd GNU Parted 3.1 Using /dev/sdd Welcome to GNU Parted! Ty ...
- python-网络安全编程第一天(requests模块)
前言 感觉现在做好多CTF题都需要python去写工具,正好期末考试放假利用空余时间来学学. requests简介 Requests是用python语言基于urllib编写的,采用的是Apache2 ...
- [head first 设计模式]第二章 观察者模式
[head first 设计模式]第二章 观察者模式 假如我们有一个开发需求--建造一个气象观测站展示系统.需求方给我们提供了一个WeatherObject对象,能够自动获得最新的测量数据.而我们要建 ...
- guitar pro系列教程(十二):如何设置Guitar Pro的不完全小节
当我们新建一个GTP谱的时候,我们肯定是要用到节拍,是的,一个乐谱节拍设置的好不好,将直接影响你的乐谱效果好不好,设置节拍的步骤我们之前也有讨论过,今天主要跟大家讲的便是不完全小节. 不完全小节顾名思 ...
- Lambda表达式(一)入门认识篇
Lambda表达式(一)入门认识篇 Lambda简介 Lambda 表达式是 JDK8 的一个新特性,可以取代大部分的匿名内部类,写出更优雅的 Java 代码,尤其在集合的遍历和其他集合操作中,可以极 ...