用代码来实践Web缓存
Web缓存是可以自动保存常见文档副本的HTTP设备。当Web请求抵达缓存时,如果本地有“已缓存的副本”,就可以从本地存储设备而不是原始服务器中提取这个文档。
上面是《HTTP权威指南》中对Web缓存的定义,缓存的好处主要有以下几点:
- 减少了冗余数据的传输;
- 减少了客户端的网络请求,也降低了原始服务器的压力;
- 降低了时延,页面加载更快。
总结一下就是省流量,省带宽,还贼快。那么缓存是如何工作的呢?客户端和服务端是如何协调缓存的时效性的呢?下面我们用代码来一步一步揭晓缓存的工作原理。
一、浏览器缓存
当我们在浏览器地址栏敲入localhost:8080/test.txt并回车时,我们是向指定的服务端发起对text.txt文件的请求,
服务端在接收到这个请求之后,找到了这个文件并准备返回给客户端,并通过设置Cache-Control和Expires两个response header告诉客户端这个文件要缓存下来,在过期之前别跟我要了。
首先我们看一下项目目录:
|-- Cache|-- index.js|-- assets|-- index.html|-- test.txt
具体实现代码如下:
<!-- index.html -->...<a href="./test.txt">test.txt</a>...
// index.jsconst http = require('http');const path = require('path');const fs = require('fs');http.createServer((req, res) => {const requestUrl = path.join(__dirname, '/assets', path.normalize(req.url));fs.stat(requestUrl, (err, stats) => {if (err || !stats.isFile) {res.writeHead(404, 'Not Found');res.end();} else {const readStream = fs.createReadStream(requestUrl);const maxAge = 10;const expireDate = new Date(new Date().getTime() + maxAge * 1000).toUTCString();res.setHeader('Cache-Control', `max-age=${maxAge}, public`);res.setHeader('Expires', expireDate);readStream.pipe(res);}});}).listen(8080);
那Cache-Control和Expires这个两个response header又代表什么意思呢?Cache-Control:max-age=500表示设置缓存存储的最大周期为500秒,超过这个时间缓存被认为过期。Expires:Tue, 23 Feb 2021 01:23:48 GMT表示在Tue, 23 Feb 2021 01:23:48 GMT这个日期之后文档过期。
启动server后,在浏览器访问localhost:8080/index.html,这时是第一次访问,没有缓存,所以服务器返回完整的资源。

我们点击超链接访问test.txt:

因为是第一次访问,所以没有缓存,这个时候我们点击返回按钮回到index.html:

发现不同了吗?这个时候NetWork中Size已经变成了disk cache,说明命中了浏览器缓存,也就是强缓存,这个时候再点击超链接访问test.txt,如果在设置的过期时间10s以内,就能看到命中浏览器缓存,如果超过10s,就会重新从服务器获取资源。
这里说明一点,浏览器的前进后退按钮会一直从缓存中读取资源,而忽略设置的缓存规则。也就是说刚才如果我从localhost:8080/test.txt页面通过浏览器返回按钮回到localhost:8080/index.html页面,会发现不管过多久Network都是disk cache,同样再点击浏览器前进按钮进入localhost:8080/test.txt页面,哪怕超过设置的过期时间也还是from disk cache。
注意:
Cache-Control的优先级大于Expires,因为时差原因还有服务端时间和客户端时间可能不一致会导致Expires判断缓存有效性不准确。但是Expires兼容http1.0,Cache-Control兼容到http1.1,所以一般还是两个都设置。
二、协商缓存
上面我们设置过缓存时限后,如果缓存过期了怎么办呢?你可能会说,过期了就重新从服务端获取资源啊。但是也有可能缓存时间过期了,但是资源并没有变化,所以我们还要引入其他的策略来处理这种情况,那就是协商缓存也就是弱缓存。
我们梳理一下协商缓存的流程:
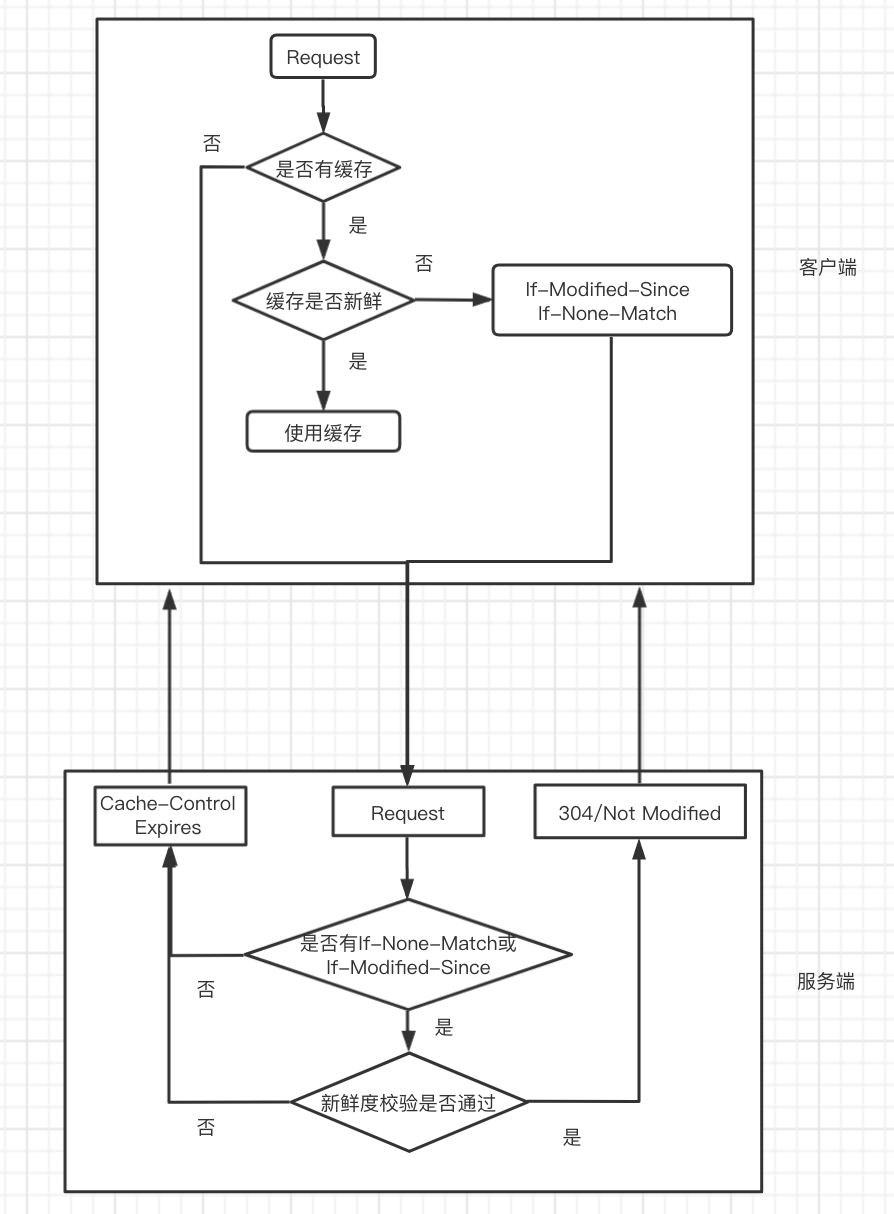
当服务端第一次返回资源时,除了设置Cache-Control和Expires响应头之外,还会设置Last-Modified(资源更新时间)和ETag(资源摘要或资源版本)两个响应头,分别代表资源的最近一次变更时间和实体标签。当客户端没有命中强缓存时,会重新像服务端发起请求,并携带If-modified-Since和If-None-Match两个请求头,服务端拿到这两个请求头会跟之前设置的Last-Modified和ETag作比较,如果不匹配,说明缓存不可用,重新返回资源,反之说明缓存有效,返回304响应码,告知缓存可以继续使用,并更新缓存有效时间。
下面我们看一下具体代码实现:
const http = require('http');const path = require('path');const fs = require('fs');const crypto = require('crypto');// 生成entity digestfunction generateDigest(requestUrl) {let hash = '2jmj7l5rSw0yVb/vlWAYkK/YBwk';let len = 0;fs.readFile(requestUrl, (err, data) => {if (err) {console.error(error);throw new Error(err);} else {len = Buffer.byteLength(data, 'utf8');hash = crypto.createHash('sha1').update(data, 'utf-8').digest('base64').substring(0, 27);}});return '"' + len.toString(16) + '-' + hash + '"';}// 响应文件function responseFile(requestUrl, stats, res) {const readStream = fs.createReadStream(requestUrl);const maxAge = 10;const expireDate = new Date(new Date().getTime() + maxAge * 1000).toUTCString();res.setHeader('Cache-Control', `max-age=${maxAge}, public`);res.setHeader('Expires', expireDate);res.setHeader('Last-Modified', stats.mtime);res.setHeader('ETag', generateDigest(requestUrl));readStream.pipe(res);}// 判断新鲜度function isFresh(requestUrl, stats, req) {const ifModifiedSince = req.headers['if-modified-since'];const ifNoneMatch = req.headers['if-none-match'];if (!ifModifiedSince && !ifNoneMatch) {//如果没有相应的请求头,应该返回全新的资源return false;} else if (ifNoneMatch && ifNoneMatch !== generateDigest(requestUrl)) {//如果ETag不匹配(资源内容发生改变),表示缓存不新鲜return false;} else if (ifModifiedSince && ifModifiedSince !== stats.mtime.toString()) {//如果资源更新时间不匹配,表示缓存不新鲜return false;}return true;}http.createServer((req, res) => {const requestUrl = path.join(__dirname, '/assets', path.normalize(req.url));fs.stat(requestUrl, (err, stats) => {if (err || !stats.isFile) {res.writeHead(404, 'Not Found');res.end();} else {if (isFresh(requestUrl, stats, req)) {// 缓存新鲜,告知客户端没有缓存可用,不返回响应实体res.writeHead(304, 'Not Modified');res.end();} else {// 缓存不新鲜,重新返回资源responseFile(requestUrl, stats, res);}}});}).listen(8080);
从代码中可以看到ETag和Last-Modified都是用于协商缓存的校验的,ETag基于实体标签,一般可以通过版本号,或者资源摘要来指定;Last-Modified则是基于资源的最后修改时间。
这时访问localhost:8080/test.txt文件,当命中强缓存后,等待10s钟,再次访问,服务器返回304,而非200,表明协商缓存生效。

此时修改test.txt文件,再次访问,服务器返回200,页面展示最新的test.txt文件内容。

总结一下:
ETag能更精确地判断资源到底有没有变化,且优先级高于Last-Modified;- 基于摘要实现的
ETag相对较慢,更占资源; Last-Modified精确到秒,对亚秒级的资源更新的缓存新鲜度判断无能为力;ETag兼容到http1.1,Last-Modified兼容到http1.0。
注意:本文中通过超链接访问
test.txt是因为,如果直接在地址栏访问该资源,浏览器会在request headers中设置cache-control:max-age=0,这样永远不会命中浏览器缓存。本文测试浏览器:Chrome 版本 88.0.4324.192
参考:
用代码来实践Web缓存的更多相关文章
- 基于Spring的Web缓存
缓存的基本思想其实是以空间换时间.我们知道,IO的读写速度相对内存来说是非常比较慢的,通常一个web应用的瓶颈就出现在磁盘IO的读写上.那么,如果我们在内存中建立一个存储区,将数据缓存起来,当浏览器端 ...
- 浅谈web缓存(转)
这是一篇知识性的文档,主要目的是为了让Web缓存相关概念更容易被开发者理解并应用于实际的应用环境中.为了简要起见,某些实现方面的细节被简化或省略了.如果你更关心细节实现则完全不必耐心看完本文,后面参考 ...
- 什么是Web缓存控制(基于HTTP头域)
这是一篇转载的知识性的文档,主要目的是为了让Web缓存相关概念更容易被开发者理解并应用于实际的应用环境中.为了简要起见,某些实现方面的细节被简化或省略了.如果你更关心细节实现则完全不必耐心看完本文,后 ...
- Web缓存加速指南(转载)
这是一篇知识性的文档,主要目的是为了让Web缓存相关概念更容易被开发者理解并应用于实际的应用环境中.为了简要起见,某些实现方面的细节被简化或省略了.如果你更关心细节实现则完全不必耐心看完本文,后面参考 ...
- 作为前端应当了解的Web缓存知识
缓存优点 通常所说的Web缓存指的是可以自动保存常见http请求副本的http设备.对于前端开发者来说,浏览器充当了重要角色.除此外常见的还有各种各样的代理服务器也可以做缓存.当Web请求到达缓存时, ...
- Web 技术人员需知的 Web 缓存知识(转)
最近的译文距今已有4年之久,原文有一定的更新.今天踩着前辈们的肩膀,再次把这篇文章翻译整理下.一来让自己对web缓存的理解更深刻些,二来让大家注意力稍稍转移下,不要整天HTML5, 面试题啊叨啊叨的~ ...
- Web 技术人员需知的Web 缓存知识
最近的译文距今已有4年之久,原文有一定的更新.今天踩着前辈们的肩膀,再次把这篇文章翻译整理下.一来让自己对web缓存的理解更深刻些,二来让大家注意力稍稍转移下,不要整天HTML5, 面试题啊叨啊叨的~ ...
- Web开发人员需知的Web缓存知识
最近的译文距今已有4年之久,原文有一定的更新.今天踩着前辈们的肩膀,再次把这篇文章翻译整理下.一来让自己对web缓存的理解更深刻些,二来让大家注意力稍稍转移下,不要整天HTML5, 面试题啊叨啊叨的~ ...
- 前端开发者应当了解的 Web 缓存知识
缓存优点 通常所说的Web缓存指的是可以自动保存常见http请求副本的http设备.对于前端开发者来说,浏览器充当了重要角色.除此外常见的还有各种各样的代理服务器也可以做缓存.当Web请求到达缓存时, ...
随机推荐
- 5.2 spring5源码--spring AOP源码分析二--切面的配置方式
目标: 1. 什么是AOP, 什么是AspectJ 2. 什么是Spring AOP 3. Spring AOP注解版实现原理 4. Spring AOP切面原理解析 一. 认识AOP及其使用 详见博 ...
- 基于Qt的tcp客户端和服务器实现摄像头帧数据处理(客户端部分)
项目简述 实现客户端调用摄像头,并以帧的形式将每一帧传输到服务端,服务端将图片进行某些处理后再返回给客户端.(客户端与服务端通信代码部分参考<Qt5 开发及实例>) 项目步骤 客户端的编写 ...
- Eclipse无法查看Servlet源代码的解决方案
在Apache官方网站中选择你对应的tomacat版本下载对应的Tomcat的源码 下载Source Code Distributions下的zip 将下载的zip文件复制到lib文件夹下 在提示页面 ...
- CF-1332 F. Independent Set
F. Independent Set 题意 一颗 n 个节点的树,求出每个\(edge-induced~subgraph\)的独立集个数之和. \(edge-induced~subgraph\)含义是 ...
- Educational Codeforces Round 97 (Rated for Div. 2) E. Make It Increasing(最长非下降子序列)
题目链接:https://codeforces.com/contest/1437/problem/E 题意 给出一个大小为 \(n\) 的数组 \(a\) 和一个下标数组 \(b\),每次操作可以选择 ...
- Educational Codeforces Round 88 (Rated for Div. 2) B. New Theatre Square(贪心)
题目链接:https://codeforces.com/contest/1359/problem/B 题意 有一块 $n \times m$ 的地板和两种瓷砖: $1 \times 1$,每块花费为 ...
- K8s Deployment YAML 名词解释
Deployment 简述 Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义 (declarative) 方法,用来替代以前的 ReplicationControlle ...
- OpenStack Train版-8.安装neutron网络服务(控制节点)
安装neutron网络服务(controller控制节点192.168.0.10) 创建neutron数据库 mysql -uroot CREATE DATABASE neutron; GRANT A ...
- leetcode347 python
通过维护最小堆排序,使用heapq模块 一般使用规则:创建列表 heap = [] 函 数 ...
- hdu-1941 Find the Shortest Common Superstring
The shortest common superstring of 2 strings S 1 and S 2 is a string S with the minimum number of ch ...