ADF 第五篇:转换数据
映射数据流(Mapping Data Flow)的核心功能是转换数据,数据流的结构分为Source、转换和Sink(也就是Destination),这种结构非常类似于SSIS的数据流。
在数据流中,数据就像流水(stream)一样,从上一个组件,流向下一个组件。组件之间有graph相连接,把各个组件连接为一个转换流(transformation stream),在数据流面板中,graph显示为一根线,用于表示数据从一个组件流向另一个组件的路径。
转换组件是数据流的核心组件,每一个转换组件都有输入和输出,接收上一个路径上的组件输入的数据,并向下一个路径上的组件输出数据。
一,创建映射数据流面板
打开一个数据工厂,切换到Author面板中,从“Factory Resources”中选择“Data flows”,从后面的“...” (Actions)中选择“New mapping dataflow”,新建数据流面板:
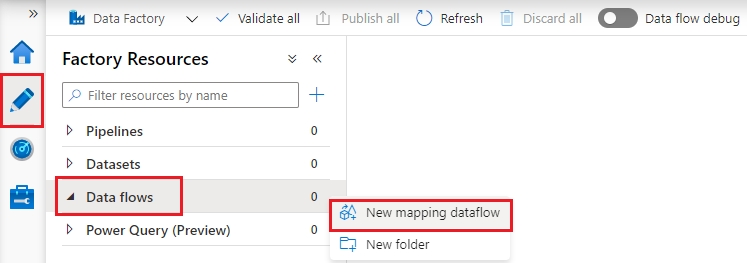
初始的数据流面板如下图所示,dataflow1是数据流面板的名称,面板的中央是画布,可以向画布中添加Source、转换组件和Sink(destination)。
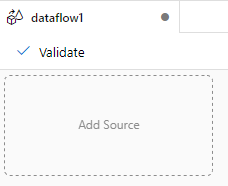
二,为数据流组件添加Source
从dataflow的面板中点击“Add Source”为数据流添加源, 添加数据源之后,source1是源的名称,右下方有一个“+”号,表示为源添加转换功能。
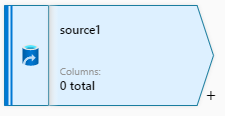
在选中Source之后,面板中央的下方区域显示为Source的属性面板,
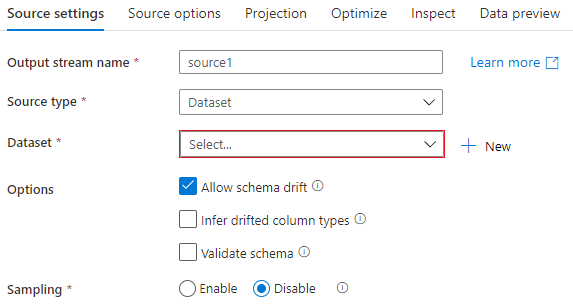
1,Source setting 面板
Source settings 用于设置Source的属性,常用的Source属性是Source type(源类型),最常用的类型是Dataset,表示从Dataset中获取数据。
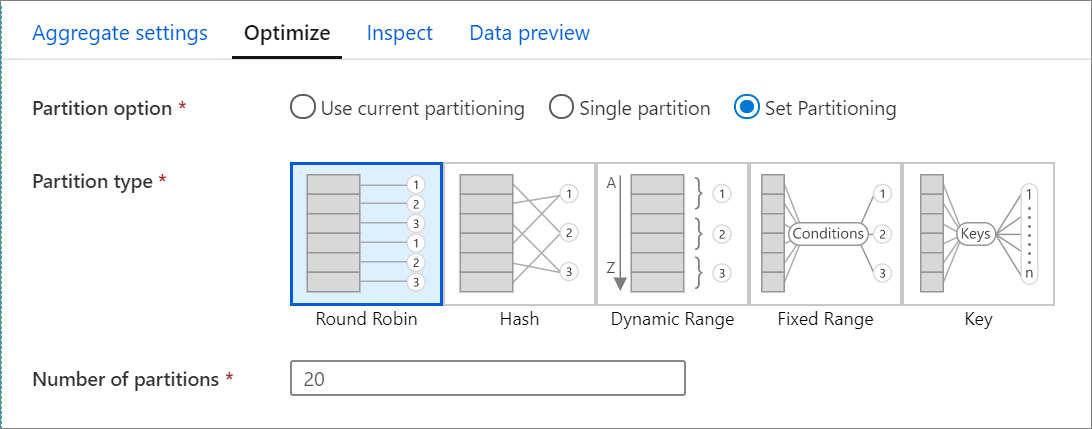
2,Optimize 面板
Optimize 选项卡 用于设置分区架构
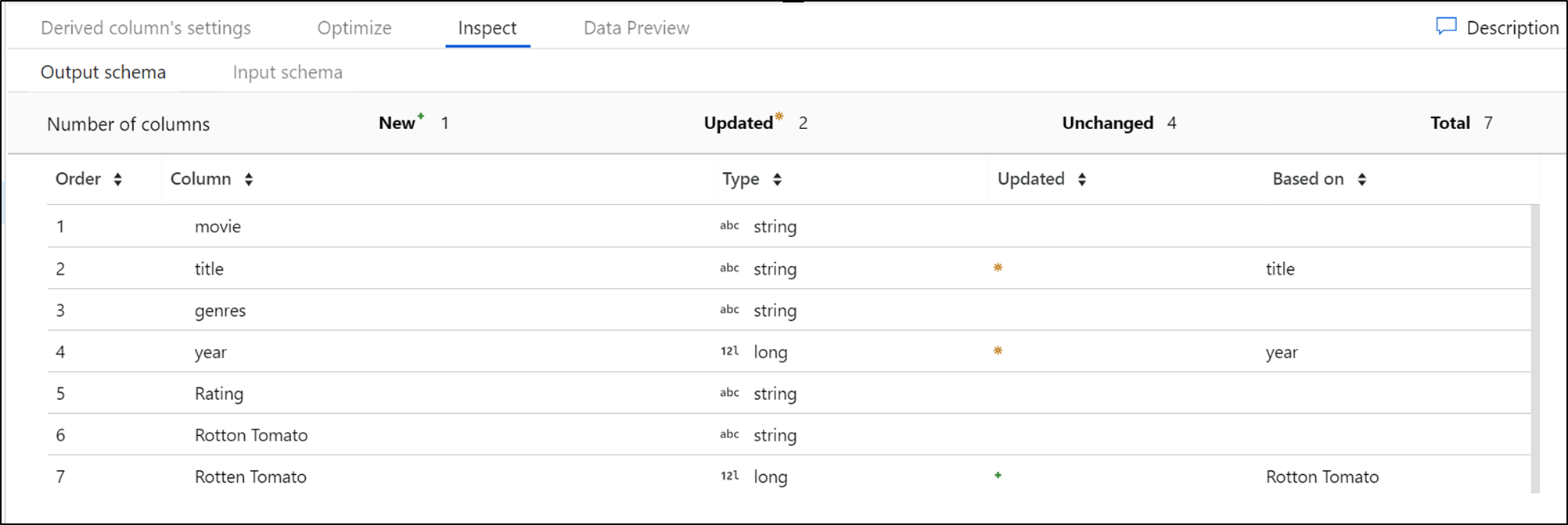
3,Inspect面板
Inspect 选项卡用于显示数据流的元数据,该选项卡是一个只读的视图,从该选项卡中可以看到数据流的列数量(column counts),列变化、增加的列、类的数据类型、列的顺序等。
三,添加转换功能
点击Source右小角的“+”号,为源添加转换功能,这是数据流的核心功能,常用的转换功能分为四组:Multiple inputs/outputs、Schema modifier、Row modifier和Destination。
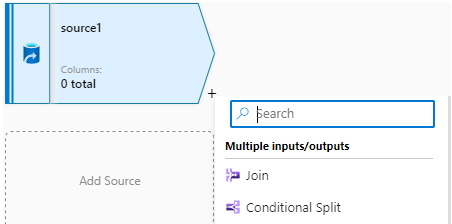
1,多输入/输出(Multiple inputs/outputs)
- Join:用于表示连接,把多个Source(Input)连接成一个输出流
- Conditional Split:条件拆分,把一个Source 按照条件拆分成多个输出流
- Exists:需要两个输入Left stream和Right stream,按照指定的条件和Exist type输出数据,如果Exist type是Exists,那么表示输出Left Stream存在于Right stream的数据;如果Exist type是Doesn't exist,那么表示输出Left stream不存在于Right stream的数据。
- Union:把多个输入合并
- Lookup:需要两个输入,Primary stream和Lookup stream,把Primary stream中存在于Lookup stream中的数据输出。
2,Schema Modifier
对列进行修改:
- Derive Column:派生列
- Select:选择列
- Aggregate:对源中的数据进行聚合运算
- SurrogateKey:根据源的主键生成代理主键
- Pivot和Unpivot:透视和逆透视
- Windows:定义数据流中基于窗口的列的聚合
- Flatten:平展数据,例如,把JSON字段平展,生成多个字段
- Rank:排名
3,Row Moifier
对行进行修改:
- Filter:过滤行
- Sort:对行进行排序
- Alter Row:修改行,设置针对行的插入、删除、更新和更新插入(upsert)策略
4,Destination
Sink:用于设置数据存储的目标
四,运行和监控数据流
数据流实际上是Pipeline中的一个Activity,只有在Pipeline中创建数据流Activity,才能开始Debug,并设置触发器。
1,调式数据流
在发布(publish)之前,需要对数据流进行调试,把数据流的“Data flow debug”设置为启用:

调试完成之后,发布数据流,就可以把数据流保存到数据工厂中。
2,添加数据流Activity
在Pipeline中面板中添加Data flow 活动,
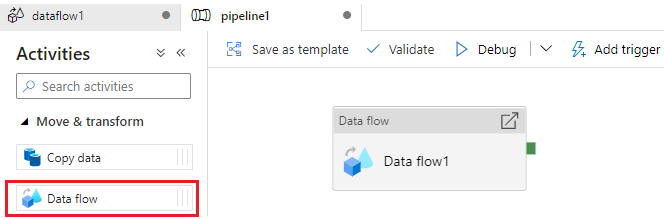
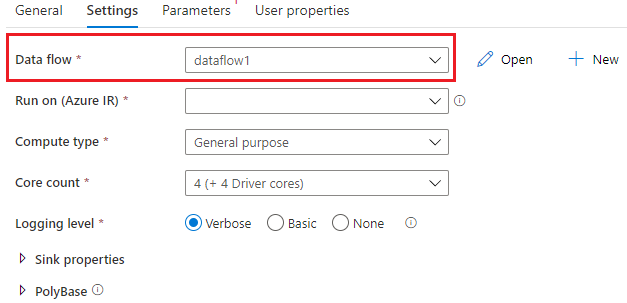
在Data flow活动的Settings选项卡中,在“Data flow”中设置引用的数据流,Run on (Azure IR) 用于设置IR,并可以设置日志级别(Logging Level),Verbose是默认选项,表示记录详细的日志。
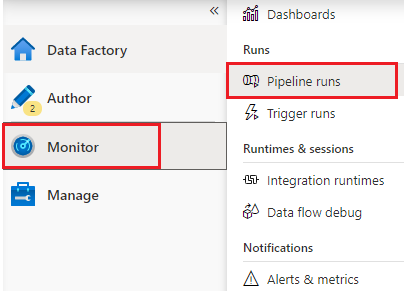
3,监控数据路
监控数据流其实就是在Pipeline runs中查看管道执行的情况
参考文档:
Transform data using mapping data flows
ADF 第五篇:转换数据的更多相关文章
- R学习笔记 第五篇:数据变换和清理
在使用R的分组操作之前,首先要了解R语言包,包实质上是实现特定功能的,预先写好的代码库(library),R拥有大量的软件包,许多包都是由某一领域的专家编写的,但并不是所有的包都有很高的质量的,在使用 ...
- 第五篇:数据备份、pymysql模块
http://www.cnblogs.com/linhaifeng/articles/7525619.html#_label3 一 IDE工具介绍 生产环境还是推荐使用mysql命令行,但为了方便我们 ...
- python、第五篇:数据备份、pymysql模块
一 IDE工具介绍 生产环境还是推荐使用mysql命令行,但为了方便我们测试,可以使用IDE工具 下载链接:https://pan.baidu.com/s/1bpo5mqj 掌握: #1. 测试+链接 ...
- ADF 第七篇:控制流
Azure Data Factory 系列博客: ADF 第一篇:Azure Data Factory介绍 ADF 第二篇:使用UI创建数据工厂 ADF 第三篇:Integration runtime ...
- EnjoyingSoft之Mule ESB开发教程系列第五篇:控制消息的流向-数据路由
目录 1. 使用场景 2. 基于消息头的路由 2.1 使用JSON提交订单的消息 2.2 使用XML提交订单的消息 2.3 使用Choice组件判断订单格式 3. 基于消息内容的路由 4. 其他控制流 ...
- 解剖SQLSERVER 第五篇 OrcaMDF里读取Bits类型数据(译)
解剖SQLSERVER 第五篇 OrcaMDF里读取Bits类型数据(译) http://improve.dk/reading-bits-in-orcamdf/ Bits类型的存储跟SQLSERVE ...
- 第十五篇 Integration Services:SSIS参数
本篇文章是Integration Services系列的第十五篇,详细内容请参考原文. 简介在前一篇,我们使用SSDT-BI将第一个SSIS项目My_First_SSIS_Project升级/转换到S ...
- 第五篇 Integration Services:增量加载-Deleting Rows
本篇文章是Integration Services系列的第五篇,详细内容请参考原文. 在上一篇你学习了如何将更新从源传送到目标.你同样学习了使用基于集合的更新优化这项功能.回顾增量加载记住,在SSIS ...
- Pyhton开发【第五篇】:Python基础之杂货铺
Python开发[第五篇]:Python基础之杂货铺 字符串格式化 Python的字符串格式化有两种方式: 百分号方式.format方式 百分号的方式相对来说比较老,而format方式则是比较先进 ...
随机推荐
- 数据恢复当选EasyRecovery,设备不再受限
我们在逐渐适应信息电子化的同时,也有一些潜在的麻烦接踵而来,其中较为常见的就是文件和数据的保存问题. 显然,设备的存储空间是有限的,这就不可避免地会出现数据被删除.覆盖或丢失的现象,如果丢失的是重要数 ...
- MindManager 2021 版新增了哪些功能
MindManager Windows 21是一款强大的可视化工具和思维导图软件,在工作应用中有出色的表现.今天就带大家来看下这个新版本增加了哪些功能? 1.新增现代主题信息样式MindManager ...
- 苹果电脑怎么给浏览器安装Folx扩展程序
Folx是一款MacOS专用的老牌综合下载管理软件,它的软件界面简洁,应用简单方便,下载管理及软件设置灵活而强大.Folx不但能够进行页面链接下载.Youtube视频下载,而且还是专业的BT下载工具. ...
- jQuery 第五章 实例方法 详解内置队列queue() dequeue() 方法
.queue() .dequeue() .clearQueue() ------------------------------------------------------------------ ...
- 合并2个数组为1个无重复元素的有序数组--Go对比Python
Go实现: 1 package main 2 3 import ( 4 "fmt" 5 "sort" 6 ) 7 8 func main() { 9 var a ...
- Java中CLASS_PATH与注释的使用
一.CLASS_PATH的使用 我们在安装jdk的时候,通常情况下只是在电脑的环境变量中新建一个系统变量JAVA_HOME,这个变量用于储存jdk的/bin文件夹之前路径,然后在path中使用这个系统 ...
- 【操作系统】先来先服务和短作业优先算法(C语言实现)
[操作系统] 先来先服务算法和短作业优先算法实现 介绍: 1.先来先服务 (FCFS: first come first service) 如果早就绪的进程排在就绪队列的前面,迟就绪的进程排在就绪队列 ...
- 教你C 语言简单编程速成
我们将所有的 C 语言要素放置到一份易读的备忘录上. 1972 年,丹尼斯·里奇Dennis Ritchie任职于贝尔实验室Bell Labs,在几年前,他和他的团队成员发明了 Unix .在创建了一 ...
- sentinel整合dubbo
<dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-dubbo-a ...
- Linux服务器学习----tomcat 服务配置实验报告(一)
一.实验目的 1. 掌握 tomcat 服务的搭建 二.实验内容 1. 搭建一台缓存 tomcat 服务器 三.实验环境1. tomcat 服务器 centos7 对应主机 ip 为 10.10.64 ...