《T-GCN: A Temporal Graph Convolutional Network for Traffic Prediction》 代码解读
论文链接:https://arxiv.org/abs/1811.05320
博客原作者Missouter,博客链接https://www.cnblogs.com/missouter/,欢迎交流。
解读了一下这篇论文github上关于T-GCN的代码,主要分为main文件与TGCN文件两部分,后续有空将会更新其他部分作为baseline代码的解读(鸽)。
1、main.py
# -*- coding: utf-8 -*-
import pickle as pkl
import tensorflow as tf
import pandas as pd
import numpy as np
import math
import os
import numpy.linalg as la
from input_data import preprocess_data,load_sz_data,load_los_data
from tgcn import tgcnCell
#from gru import GRUCell from visualization import plot_result,plot_error
from sklearn.metrics import mean_squared_error,mean_absolute_error
#import matplotlib.pyplot as plt
import time time_start = time.time()
###### Settings ######
flags = tf.app.flags
FLAGS = flags.FLAGS
flags.DEFINE_float('learning_rate', 0.001, 'Initial learning rate.')
flags.DEFINE_integer('training_epoch', 1, 'Number of epochs to train.')
flags.DEFINE_integer('gru_units', 64, 'hidden units of gru.')
flags.DEFINE_integer('seq_len',12 , ' time length of inputs.')
flags.DEFINE_integer('pre_len', 3, 'time length of prediction.')
flags.DEFINE_float('train_rate', 0.8, 'rate of training set.')
flags.DEFINE_integer('batch_size', 32, 'batch size.')
flags.DEFINE_string('dataset', 'los', 'sz or los.')
flags.DEFINE_string('model_name', 'tgcn', 'tgcn')
model_name = FLAGS.model_name
data_name = FLAGS.dataset
train_rate = FLAGS.train_rate
seq_len = FLAGS.seq_len
output_dim = pre_len = FLAGS.pre_len
batch_size = FLAGS.batch_size
lr = FLAGS.learning_rate
training_epoch = FLAGS.training_epoch
gru_units = FLAGS.gru_units
开头部分用于设置训练基本参数;使用flag对参数进行设置与说明。
if data_name == 'sz':
data, adj = load_sz_data('sz')
if data_name == 'los':
data, adj = load_los_data('los') time_len = data.shape[0]
num_nodes = data.shape[1]
data1 =np.mat(data,dtype=np.float32) #### normalization
max_value = np.max(data1)
data1 = data1/max_value
trainX, trainY, testX, testY = preprocess_data(data1, time_len, train_rate, seq_len, pre_len) totalbatch = int(trainX.shape[0]/batch_size)
training_data_count = len(trainX)
这部分导入数据集并对数据进行归一化,input_data文件中导入函数如下:
def load_sz_data(dataset):
sz_adj = pd.read_csv(r'data/sz_adj.csv',header=None)
adj = np.mat(sz_adj)
sz_tf = pd.read_csv(r'data/sz_speed.csv')
return sz_tf, adj def load_los_data(dataset):
los_adj = pd.read_csv(r'data/los_adj.csv',header=None)
adj = np.mat(los_adj)
los_tf = pd.read_csv(r'data/los_speed.csv')
return los_tf, adj
其中preprocess_data函数根据main函数开头设置的训练集、测试集比例对数据集进行分割:
def preprocess_data(data, time_len, rate, seq_len, pre_len):
train_size = int(time_len * rate)
train_data = data[0:train_size]
test_data = data[train_size:time_len] trainX, trainY, testX, testY = [], [], [], []
for i in range(len(train_data) - seq_len - pre_len):
a = train_data[i: i + seq_len + pre_len]
trainX.append(a[0 : seq_len])
trainY.append(a[seq_len : seq_len + pre_len])
for i in range(len(test_data) - seq_len -pre_len):
b = test_data[i: i + seq_len + pre_len]
testX.append(b[0 : seq_len])
testY.append(b[seq_len : seq_len + pre_len]) trainX1 = np.array(trainX)
trainY1 = np.array(trainY)
testX1 = np.array(testX)
testY1 = np.array(testY)
return trainX1, trainY1, testX1, testY1
接着定义了TGCN函数:
def TGCN(_X, _weights, _biases):
###
cell_1 = tgcnCell(gru_units, adj, num_nodes=num_nodes)
cell = tf.nn.rnn_cell.MultiRNNCell([cell_1], state_is_tuple=True)
_X = tf.unstack(_X, axis=1)
outputs, states = tf.nn.static_rnn(cell, _X, dtype=tf.float32)
m = []
for i in outputs:
o = tf.reshape(i,shape=[-1,num_nodes,gru_units])
o = tf.reshape(o,shape=[-1,gru_units])
m.append(o)
last_output = m[-1]
output = tf.matmul(last_output, _weights['out']) + _biases['out']
output = tf.reshape(output,shape=[-1,num_nodes,pre_len])
output = tf.transpose(output, perm=[0,2,1])
output = tf.reshape(output, shape=[-1,num_nodes])
return output, m, states
函数开头首先引入了TGCN的计算单元,tgcnCell的解读将在后文进行;使用tf.nn.rnn_cell.MultiRNNCell实现多层神经网络;对输入数据进行处理,创建由RNNCell指定的循环神经网络。接着对每个循环神经网络的输出进行处理,首先重塑结果张量,tf.reshape中参数-1表示计算该维度的大小,以使总大小保持不变;第二维为点的数量,第三维为GRU单元的数量,再紧接上一层张量重塑的结果继续进行重塑,得到由长度为GRU数量列表组成的列表,使用tf.matmul将输出矩阵乘以权重矩阵,biases为偏差,接着重塑输出张量为第二维为数据点的数量,第三维为预测长度的矩阵,再置换输出矩阵,使用transpose按照[0,2,1]重新排列尺寸,进一步重塑为由数据点数目长度列表组成的列表,得到最终输出结果。
紧接着下一段使用占位符定义输入与标签,随机初始化权重与偏差:
inputs = tf.placeholder(tf.float32, shape=[None, seq_len, num_nodes])
labels = tf.placeholder(tf.float32, shape=[None, pre_len, num_nodes]) weights = {
'out': tf.Variable(tf.random_normal([gru_units, pre_len], mean=1.0), name='weight_o')}
biases = {
'out': tf.Variable(tf.random_normal([pre_len]),name='bias_o')}
if model_name == 'tgcn':
pred,ttts,ttto = TGCN(inputs, weights, biases) y_pred = pred
lambda_loss = 0.0015
Lreg = lambda_loss * sum(tf.nn.l2_loss(tf_var) for tf_var in tf.trainable_variables())
label = tf.reshape(labels, [-1,num_nodes])
loss = tf.reduce_mean(tf.nn.l2_loss(y_pred-label) + Lreg)
对应论文公式(详见上篇博客):
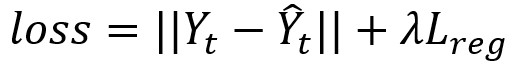
定义均方根误差:
error = tf.sqrt(tf.reduce_mean(tf.square(y_pred-label)))
optimizer = tf.train.AdamOptimizer(lr).minimize(loss)
对迭代训练过程进行初始化:
variables = tf.global_variables()
saver = tf.train.Saver(tf.global_variables()) #
#sess = tf.Session()
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.333)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
sess.run(tf.global_variables_initializer())
out = 'out/%s'%(model_name)
#out = 'out/%s_%s'%(model_name,'perturbation')
path1 = '%s_%s_lr%r_batch%r_unit%r_seq%r_pre%r_epoch%r'%(model_name,data_name,lr,batch_size,gru_units,seq_len,pre_len,training_epoch)
path = os.path.join(out,path1)
if not os.path.exists(path):
os.makedirs(path)
其中global_variables用于获取程序中的变量,配合train.Saver将训练好的模型参数保存起来,以便以后进行验证或测试。tf.GPUOptions用于限制GPU资源的使用,不过为什么要限制使用三分之一的显存尚不清楚,算训练小技巧嘛?初始化模型的参数后设置输出路径与文件名,不详细讨论。
文件中的评估模块定义了论文实验部分的指标:均方根误差、平均绝对误差、准确率、确定系数与可方差值。
def evaluation(a,b):
rmse = math.sqrt(mean_squared_error(a,b))
mae = mean_absolute_error(a, b)
F_norm = la.norm(a-b,'fro')/la.norm(a,'fro')
r2 = 1-((a-b)**2).sum()/((a-a.mean())**2).sum()
var = 1-(np.var(a-b))/np.var(a)
return rmse, mae, 1-F_norm, r2, var
接下来就是常见的训练部分:
for epoch in range(training_epoch):
for m in range(totalbatch):
mini_batch = trainX[m * batch_size : (m+1) * batch_size]
mini_label = trainY[m * batch_size : (m+1) * batch_size]
_, loss1, rmse1, train_output = sess.run([optimizer, loss, error, y_pred],
feed_dict = {inputs:mini_batch, labels:mini_label})
batch_loss.append(loss1)
batch_rmse.append(rmse1 * max_value) # Test completely at every epoch
loss2, rmse2, test_output = sess.run([loss, error, y_pred],
feed_dict = {inputs:testX, labels:testY})
test_label = np.reshape(testY,[-1,num_nodes])
rmse, mae, acc, r2_score, var_score = evaluation(test_label, test_output)
test_label1 = test_label * max_value#反归一化
test_output1 = test_output * max_value
test_loss.append(loss2)
test_rmse.append(rmse * max_value)
test_mae.append(mae * max_value)
test_acc.append(acc)
test_r2.append(r2_score)
test_var.append(var_score)
test_pred.append(test_output1) print('Iter:{}'.format(epoch),
'train_rmse:{:.4}'.format(batch_rmse[-1]),
'test_loss:{:.4}'.format(loss2),
'test_rmse:{:.4}'.format(rmse),
'test_acc:{:.4}'.format(acc))
if (epoch % 500 == 0):
saver.save(sess, path+'/model_100/TGCN_pre_%r'%epoch, global_step = epoch) time_end = time.time()
print(time_end-time_start,'s')
附带对每个周期训练结果的测试、对结果的反归一化,训练设置为每训练500层保存一次模型,并对训练得到的参数指标进行打印与保存。代码最后还给出了可视化数据指标的方法,即将数据指标写入csv文件中:
b = int(len(batch_rmse)/totalbatch)
batch_rmse1 = [i for i in batch_rmse]
train_rmse = [(sum(batch_rmse1[i*totalbatch:(i+1)*totalbatch])/totalbatch) for i in range(b)]
batch_loss1 = [i for i in batch_loss]
train_loss = [(sum(batch_loss1[i*totalbatch:(i+1)*totalbatch])/totalbatch) for i in range(b)] index = test_rmse.index(np.min(test_rmse))
test_result = test_pred[index]
var = pd.DataFrame(test_result)
var.to_csv(path+'/test_result.csv',index = False,header = False)
#plot_result(test_result,test_label1,path)
#plot_error(train_rmse,train_loss,test_rmse,test_acc,test_mae,path) print('min_rmse:%r'%(np.min(test_rmse)),
'min_mae:%r'%(test_mae[index]),
'max_acc:%r'%(test_acc[index]),
'r2:%r'%(test_r2[index]),
'var:%r'%test_var[index])
至此对论文对应代码main文件的解读就结束了。
2、tgcn.py
此文件只定义了一个TGCN计算单元的类,初始化部分不作详谈:
# -*- coding: utf-8 -*- #import numpy as np
import tensorflow as tf
from tensorflow.contrib.rnn import RNNCell
from utils import calculate_laplacian class tgcnCell(RNNCell):
"""Temporal Graph Convolutional Network """ def call(self, inputs, **kwargs):
pass
-
def __init__(self, num_units, adj, num_nodes, input_size=None,
act=tf.nn.tanh, reuse=None): super(tgcnCell, self).__init__(_reuse=reuse)
self._act = act
self._nodes = num_nodes
self._units = num_units
self._adj = []
self._adj.append(calculate_laplacian(adj)) @property
def state_size(self):
return self._nodes * self._units @property
def output_size(self):
return self._units
重点之一在于对GRU单元的定义:
def __call__(self, inputs, state, scope=None):
with tf.variable_scope(scope or "tgcn"):
with tf.variable_scope("gates"):
value = tf.nn.sigmoid(
self._gc(inputs, state, 2 * self._units, bias=1.0, scope=scope))
r, u = tf.split(value=value, num_or_size_splits=2, axis=1)
with tf.variable_scope("candidate"):
r_state = r * state
c = self._act(self._gc(inputs, r_state, self._units, scope=scope))
new_h = u * state + (1 - u) * c
return new_h, new_h
代码还原论文中tgcn单元的计算过程(详见上一篇博客):

参数中state对应论文中上一时刻的状态,即ht-1。variable_scope使得多个变量得以有相同的命名;上述代码中tf.nn.sigmoid语句为激活函数,用于进行图卷积GC;tf.split语句用于
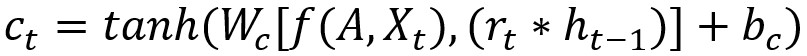
函数最后返回最新状态ht。
图卷积过程最后被定义:
def _gc(self, inputs, state, output_size, bias=0.0, scope=None):
## inputs:(-1,num_nodes) inputs = tf.expand_dims(inputs, 2)
## state:(batch,num_node,gru_units)
state = tf.reshape(state, (-1, self._nodes, self._units))
## concat
x_s = tf.concat([inputs, state], axis=2)
input_size = x_s.get_shape()[2].value
## (num_node,input_size,-1)
x0 = tf.transpose(x_s, perm=[1, 2, 0])
x0 = tf.reshape(x0, shape=[self._nodes, -1]) scope = tf.get_variable_scope()
with tf.variable_scope(scope):
for m in self._adj:
x1 = tf.sparse_tensor_dense_matmul(m, x0)
# print(x1)
x = tf.reshape(x1, shape=[self._nodes, input_size,-1])
x = tf.transpose(x,perm=[2,0,1])
x = tf.reshape(x, shape=[-1, input_size])
weights = tf.get_variable(
'weights', [input_size, output_size], initializer=tf.contrib.layers.xavier_initializer())
x = tf.matmul(x, weights) # (batch_size * self._nodes, output_size)
biases = tf.get_variable(
"biases", [output_size], initializer=tf.constant_initializer(bias, dtype=tf.float32))
x = tf.nn.bias_add(x, biases)
x = tf.reshape(x, shape=[-1, self._nodes, output_size])
x = tf.reshape(x, shape=[-1, self._nodes * output_size])
return x
函数开头对特征矩阵进行构建:使用expand_dims增加输入维度,再使用将当前状态转化为第二维为数据点数量,第三维为gru单元数量的列表,使用concat在第二个维度拼接张量,最后得到一个长度为数据点数量的列表。get_variable_scope获取变量后,将得到的特征矩阵与邻接矩阵相乘。在tf.nn.bias_add处激活得到两层GCN,对应公式:
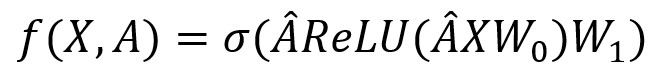
最终返回输出值x。此函数经历了很多张量的形式转换,对应论文空间关系建模过程。
关于论文中TGCN部分代码的解读结束了,模块化的编程对于学习实验手法有很多值得学习的地方,对于TGCN本身的实现、涉及张量的处理变换也有很多可以借鉴的地方。
《T-GCN: A Temporal Graph Convolutional Network for Traffic Prediction》 代码解读的更多相关文章
- 《T-GCN: A Temporal Graph Convolutional Network for Traffic Prediction》 论文解读
论文链接:https://arxiv.org/abs/1811.05320 最近发现博客好像会被CSDN和一些奇怪的野鸡网站爬下来?看见有人跟爬虫机器人单方面讨论问题我也蛮无奈的.总之原作者Misso ...
- 【论文笔记】Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition 2018-01-28 15:4 ...
- Two-Stream Adaptive Graph Convolutional Network for Skeleton-Based Action Recognition
Two-Stream Adaptive Graph Convolutional Network for Skeleton-Based Action Recognition 摘要 基于骨架的动作识别因为 ...
- Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition (ST-GCN)
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition 摘要 动态人体骨架模型带有进行动 ...
- Graph Convolutional Network
How to do Deep Learning on Graphs with Graph Convolutional Networks https://towardsdatascience.com/h ...
- GCN(Graph Convolutional Network)的简单公式推导
第一步:从前一个隐藏层到后一个隐藏层,对结点进行特征变换 第二步:对第一步进行具体实现 第三步:对邻接矩阵进行归一化(行之和为1) 邻接矩阵A的归一化,可以通过度矩阵D来实现(即通过D^-1*A来实现 ...
- GCN: Graph Convolutional Network
从CNN到GCN的联系与区别: https://www.zhihu.com/question/54504471/answer/332657604 更加详解Laplacian矩阵: https://ww ...
- GRAPH CONVOLUTIONAL NETWORK WITH SEQUENTIAL ATTENTION FOR GOAL-ORIENTED DIALOGUE SYSTEMS
面向领域特定目标的对话系统通常需要建模三种类型的输入,即(i)与领域相关的知识库,(ii)对话的历史(即话语序列)和(iii)需要生成响应的当前话语. 在对这些输入进行建模时,当前最先进的模型(如Me ...
- 关于Graph Convolutional Network的初步理解
为给之后关于图卷积网络的科研做知识积累,这里写一篇关于GCN基本理解的博客.GCN的本质是一个图网络中,特征信息的交互+与传播.这里的图指的不是图片,而是数据结构中的图,图卷积网络的应用非常广泛 ,经 ...
随机推荐
- vue :没有全局变量的计数器
created: created () { let num = null this.mFun(num) }, methods: methods:{ mFun(m){ if (m === null) { ...
- tomcat 认证爆破之custom iterator使用
众所周知,BurpSuite是渗透测试最基本的工具,也可是神器,该神器有非常之多的模块:反正,每次翻看大佬们使用其的骚操作感到惊叹,这次我用其爆破模块的迭代器模式来练练手[不喜勿喷] 借助vulhub ...
- python txt装换成excel
工作中,我们需要经常吧一些导出的数据文件,例如sql查出来的结果装换成excel,用文件发送.这次为大家带上python装换excel的脚本 记得先安装wlwt模块,适用版本,python2-3 #c ...
- SpringBoot + Spring Cloud Eureka 服务注册与发现
什么是Spring Cloud Eureka Eureka是Netflix公司开发的开源服务注册发现组件,服务发现可以说是微服务开发的核心功能了,微服务部署后一定要有服务注册和发现的能力,Eureka ...
- Python 写入excel时的字体格式设置
转自:https://blog.csdn.net/kuangzhi9124/article/details/81940919 下面代码设置了单元格的字体.位置居中.框线,可以将格式调成自己需要的 im ...
- Linux企业运维人员最常用命令汇总
本文目录 线上查询及帮助命令 文件和目录操作命令 查看文件及内容处理命令 文件压缩及解压缩命令 信息显示命令 搜索文件命令 用户管理命令 基础网络操作命令 深入网络操作命令 有关磁盘与文件系统的命令 ...
- SpringCloud系列使用Eureka进行服务治理
1. 什么是微服务? "微服务"一词来自国外的一篇博文,网站:https://martinfowler.com/articles/microservices.html 如果您不能看 ...
- 渲染导航菜单的同时给每个菜单绑定不同的router跳转
这个问题一开始的时候,我总想着router跳转只有两种方式 一种@click,一种router-link 然后我想着@click,绑定一个事件,事件下面无法确定我当前是哪个菜单,解决不了. 然后< ...
- Mybatis-Plus中Wrapper的方法
public interface EntityService extends IService<TbEntity>{ }entityService.update(entity,Condit ...
- Django学习路16_获取学生所在的班级名
在 urls.py 中先导入getgrades from django.conf.urls import url from app5 import views urlpatterns = [ url( ...