字节真题 ZJ26-异或:使用字典树减少计算次数
题目描述:

个人分析:从输入数据看,要处理的元素个数(n)没有到达 10^9 或 10^8 级,或许可以使用暴力?但是稍微计算一下,有 10^5 * (10^5 - 1) / 2 = 10^10 / 2
个结果,说明至少运算那么多次。假设每次运算使用1ns(CPU运算速度纳秒为单位),貌似没有超时,但是加上内存分配,数组越界检查等时间,大概率超时。
需要有一种办法减少重复运算,首先需要了解异或运算的特性:(以下讨论均是正数情况,因为题目的输入范围均是正数)
a 和 b 从高位开始逐位异或,只有两者相应位上的数不同,结果才能是1。
a 和 b 某一位上 异或的结果如果是1 ,并且待比较数上相应位的数是0,说明 a 和 b 异或的结果必定大于待比较数
因为异或结果在高位上大于待比较数,低位就不需要比较了。也就是说,a 和 任何 前缀与 b 相同的数异或,结果都会大于待比较数,因为异或出来的结果
必然和 c 有共同的前缀,有这样的前缀的话,就比如比待比较数大


于是得到思路:
如果找到一种能对相同前缀元素进行计数的数据结构,就可以直接返回符合前缀条件的元素个数,减少运算。
字典树:Trie Tree 正好是满足预期的数据结构
我的思路 :
题目要输入 n 个数,求出 这 n 个数两两异或后 大于 m 的结果。
或许可以先向字典树中插入一个数 A1 ,先保证数不空,而且题目中保证了输入的数的数量大于1个,所以必能有第一个数 A1 插入字典树
对于之后输入的数 Ax (x > 1),先去字典树里找有几个和 Ax 异或后结果大于 m 的数 (寻找过程见后文),然后再把 Ax 插入到字典树中。
不怕 Ax 错过 之后的 Ax+1 , Ax+2, ......,因为Ax+1, Ax+2,...... 会遇到前面已经在字典树里的Ax,异或运算可交换,a^b = b^a
伪代码: 含义是先把A1插入字典树,之后输入的Ax,都要先去树里找和 他异或大于m 的数有多少个,并且把数量进行累积
tree.insert(A1);
int total = 0;
for( input Ax ){
total += tree.compare(Ax, m);
tree.insert(Ax);
}
output total
实操:(JDK 1.8)
1.打好框架:
输入输出流
字典树申明
- import java.util.Scanner;
- public class Xor {
- public static void main(String[] args){
- Scanner sc = new Scanner(System.in);
- TrieTree tree = new TrieTree();
- while(sc.hasNext()){
- int n = sc.nextInt();
- int m = sc.nextInt();
- long total = 0;
//插入A1- tree.insert(sc.nextInt());
- for(int i = 0; i < n - 1; i ++){
- int me = sc.nextInt();
- //找出和Ax异或后结果大于m的数有多少个,并且累加
total += tree.compare(me, m);
//插入Ax- tree.insert(me);
- }
//输出结果- System.out.println(total);
- }
- }
- private static class Node{
//有多少个数有当前前缀- public int count = 1;
//子节点- public Node[] child = new Node[2];
- }
- private static class TrieTree{
//根节点- Node root;
- public TrieTree(){
- //根节点不包含信息,卫星数据
this.root = new Node();- }
- public int compare(int tar, int m){
- }
- public void insert(int tar){
- }
- }
- }
2.具体实现
最主要的函数只有两个,insert和compare
insert很简单,比如插入 00000110000000000000000000000000(100663296),insert忽略掉最高位符号位,因为所有输入都是正数,则我们从左往右数的
第二位开始

只需要新建节点即可,每个节点的count默认是1(因为一个节点必定在某条路径上,而这条路径代表了一个数,这个数包含从根到这个节点位置形成的前缀(假设这个节点是上图的第四个节点,那么形成的前缀就是 0000 ,00000110000000000000000000000000 包含前缀 0000 ),所以这个节点的count必定 >= 1)。
再插入 00010110000000000000000000000000(369098752)
从根节点出发,如果对应位的节点已经存在,则令其count + +,如果不存在则新建
让当前节点 now 等于 root
因为 369098752 的第二位是 0(忽略最高位符号位第一位),所以 看看 now.child[0] 是否为空,发现不为空,则让now.child[0].count ++
并且让当前节点 等于 now.child[0],接着向下执行,发现当前节点(节点1)的child[0]也不为空,也让其 count++, 依此类推,到了 now = 节点3
因为 now.child[1] (369098752的第四位为1,所以取1)为空,所以新建节点,并且count 默认 = 1
于是下面有三个count = 2 的节点,表示有两个数的路径包含这些节点

- public void insert(int tar){
- Node now = root;
- root.count ++;
- //从第二位开始,忽略最高为第一位,所有输入都是正数,忽略最高符号位
- for(int i = 30; i >= 0; i --){
- //获取要插入的数的第(32 - i )位
- int res = (tar >>> i) & 1;
- //如果之前不存在节点,则新建节点,count 默认 = 1
- if(now.child[res] == null){
- now.child[res] = new Node();
- now = now.child[res];
- }else{
- //如果之前已经有节点存在,则count++
- now = now.child[res];
- now.count ++;
- }
- }
- }
compare:
假设某次比较时,字典树如下图状态,并且输入的数Ax如图所示,被比较的数m如下图

为了方便观察,只保留 Ax 和 m 的前面几位
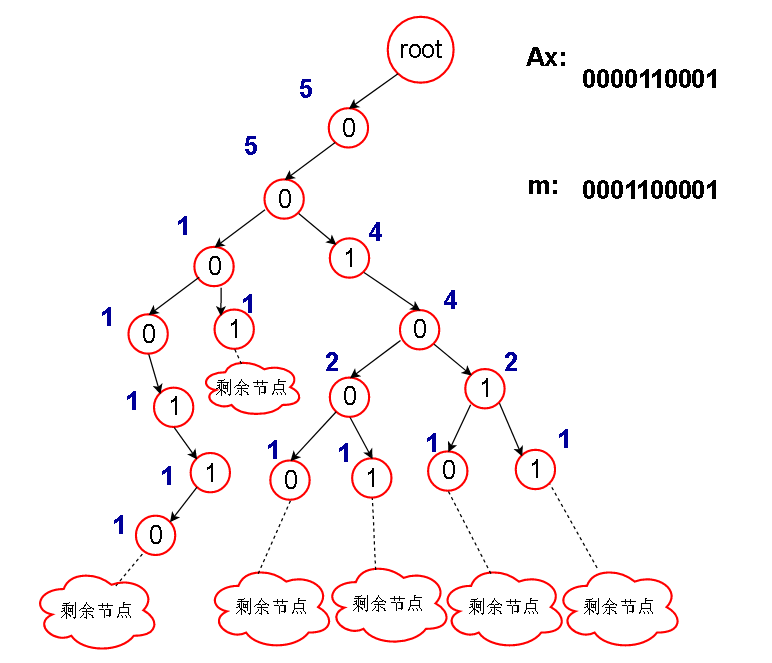
从根节点开始向下比较,也即从第二位开始比较
分如下情况:
1.假设Ax的当前位为 b , 我们的想法当然是想找到 树中当前层次的节点 b ^ 1 ,因为 (b ^ 1) ^ b = 1 ,这样的话,当前位异或的结果为1
如果待比较数m中的当前位为 0,那么Ax和节点 b ^ 1 的所有分支异或的结果都大于m(情况1)
如果待比较数m中的当前位为1,那么目前的比较结果和 m 尚且相等,继续比较下去(情况2)
2.假设 b ^ 1 节点不存在,那么只能委曲求全,走 节点 b,需要注意的是,
如果 m 的当前位为1,说明 m 大于我们能走的唯一路径的全部异或结果(情况3)
因为 b ^ b = 0 < 1 (m 当前位),说明节点 b 路径上的异或结果都要小于m,而且只能走节点 b 的路径,所以直接返回 0
如果 m 的当前位为0,则目前的比较结果和 m 尚且相等,继续比较下去(情况4)
需要注意的是,情况1不能直接返回节点 b ^ 1 的count,因为另一条路 虽然当前位异或结果 = 0,但是因为 m 的当前位也是0,所以异或结果不至于小于m
还要进行后继比较
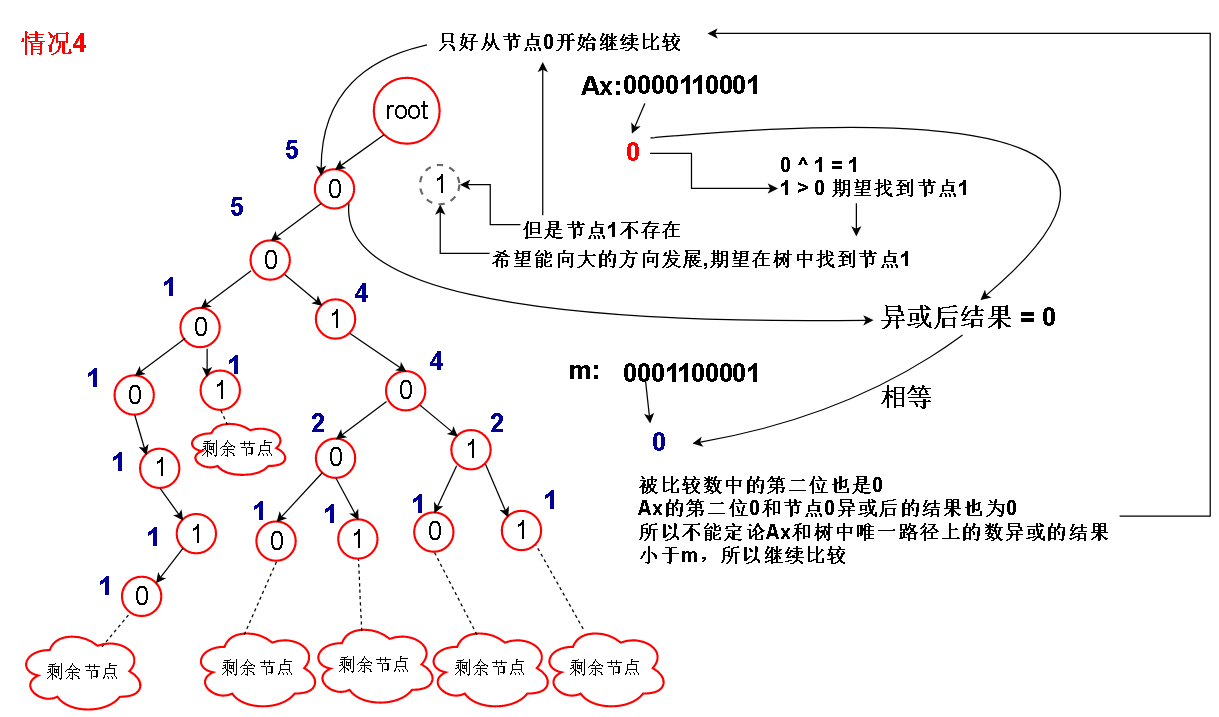
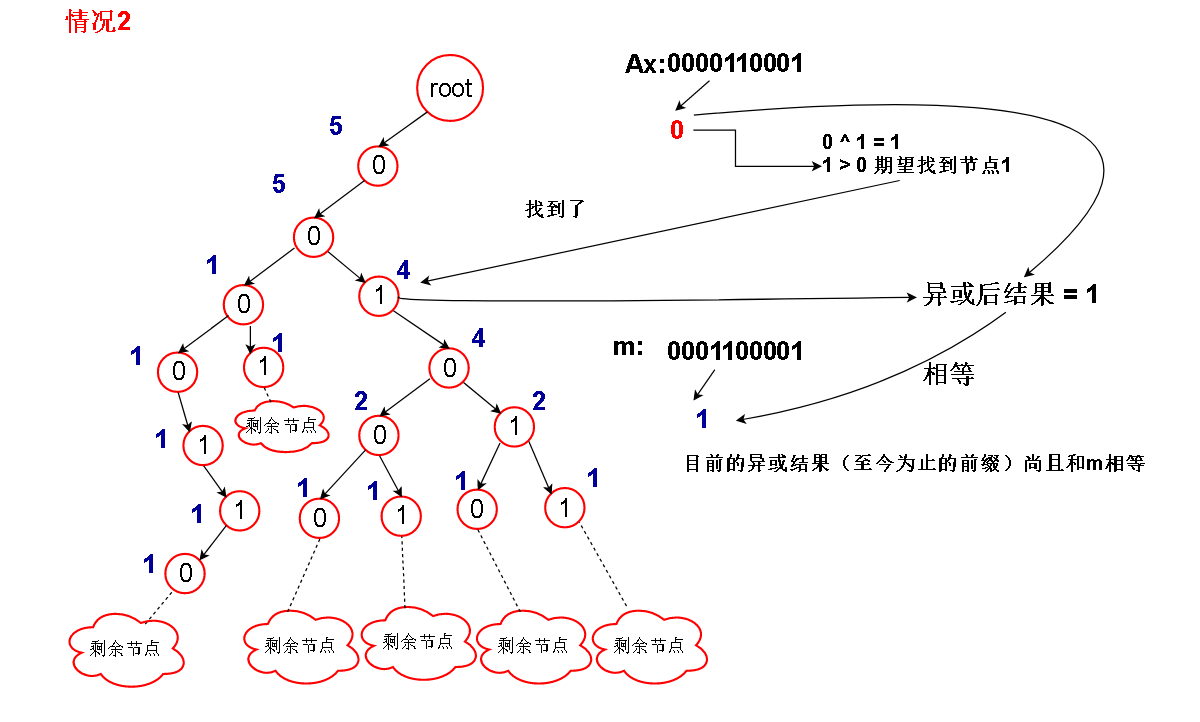
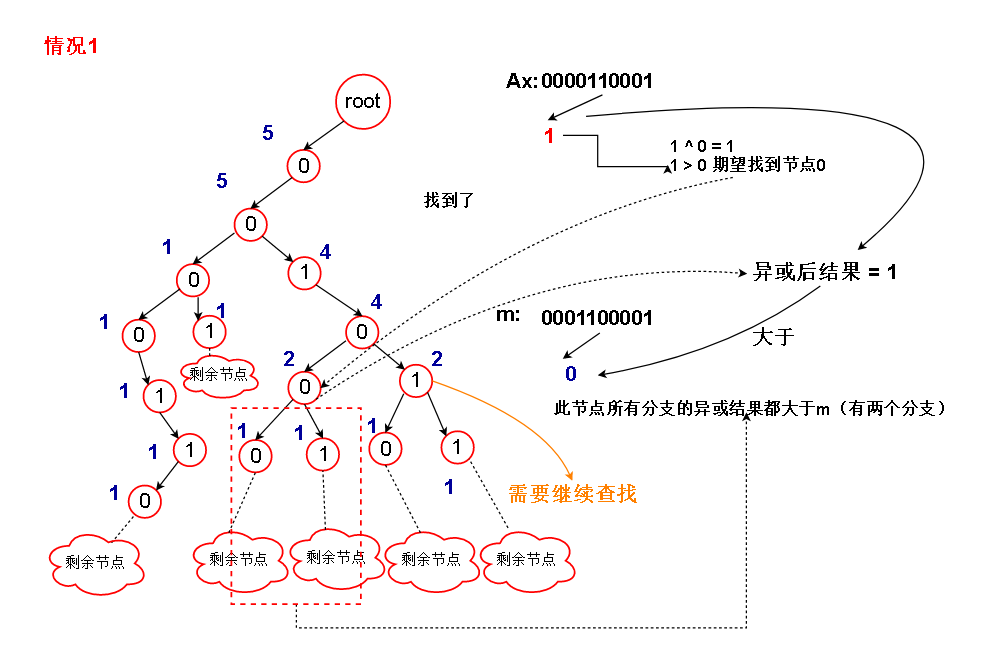
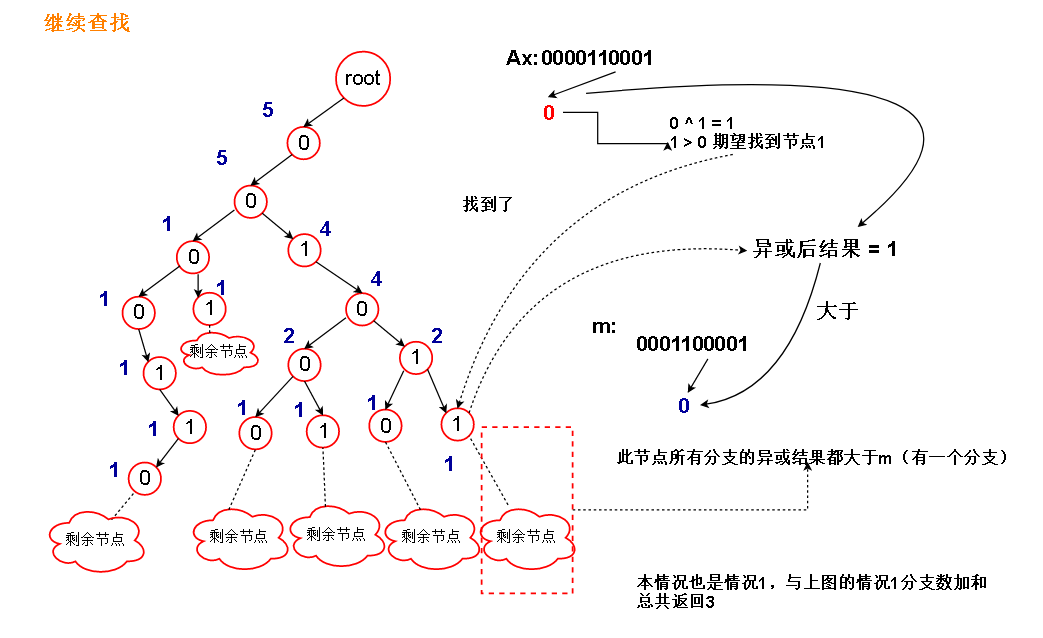
另外,如果当前的节点为空,表明已经比较到叶子节点了,但是还是没有比较出个所以然,说明异或结果与m相等,没有大于m的,返回0(情况5)
- // now : 当前前缀树中,需要开始比较的节点
- // tar : 将要插入的数,但是在调用insert插入之前,要和已经插入的数比较(当前前缀树)
- // m : 要大于的那个树
- // bit : 当前节点的儿子们表示的是对第几位的比较
- public int compare(Node now, int Ax, int m, int bit){
- //逐位比较
- for(int i = bit; i >= 0; i --){
- if(now == null){
- //空节点 表示两者相同 情况5
- return 0;
- }
- int res = (Ax >>> i) & 1;
- //存在能够 XOR 出 1 的路径, 情况1或2
- if((now.child[res ^ 1]) != null){
- //如果目标的当前位是 0,说明异或结果已经小于 Ax
if(((m >>> i) & 1) == 0){- //情况1
//但是不能单纯只返回异或结果大于m的那条路径上的分支数量
//因为当前位异或结果相等于m的那条路径上的分支可能还存在满足异或结果大于m的情况- return now.child[res ^ 1].count + compare(now.child[res], tar, m, i - 1);
- } else {
//情况2
//异或结果相等 接着找- now = now.child[res ^ 1];
- }
- } else{
- //情况3
//异或结果小于 m, 直接返回0- if(((m >>> i) & 1) == 1){
- return 0;
- }
- //情况4
//异或结果相等,接着找- now = now.child[res];
- }
- }
//默认返回0- return 0;
- }
3.结果估计
假设输入了 10 ^ 5 个数
每个Node对象占用内存 =
1.没有指针压缩,且在64位机器上
8字节markOop,8字节 Klass*,8字节数组引用,8字节int(内存对齐),共32字节
每个数占用约32位,每位需要一个节点,且输入了 10 ^ 5 个数,总共占用内存最多 = 10 ^ 5 * 32 * 32 B = 102 400 KB = 102 MB 左右
但是实际上字典树中的大部分数都有相同的前缀,真实占用的内存肯定会比 102 MB少不少 (不算上栈上内存)
实际结果:

可见内存占用为 43MB 左右,比102MB小不少。
总结:字典树可以在某些 求最大异或结果或者异或结果如何如何的关于位运算的题目中使用,以减少运算次数,网络IP地址的最长前缀查找等题目同理。
字节真题 ZJ26-异或:使用字典树减少计算次数的更多相关文章
- NEUOJ711 异星工厂 字典树+贪心
题意:你可以收集两个不相交区间的权值,区间权值是区间异或,问这两个权值和最大是多少 分析:很多有关异或求最大的题都是利用01字典树进行贪心,做这个题的时候我都忘了...最后是看别人代码的时候才想起来这 ...
- Xor Sum(讲解异或)【字典树】
Xor Sum 题目链接(点击) Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 132768/132768 K (Java/Other ...
- 蓝桥杯 第三届C/C++预赛真题(9) 夺冠概率(手工计算概率)
足球比赛具有一定程度的偶然性,弱队也有战胜强队的可能. 假设有甲.乙.丙.丁四个球队.根据他们过去比赛的成绩,得出每个队与另一个队对阵时取胜的概率表: 甲 乙 丙 丁 甲 - 0.1 0.3 0.5乙 ...
- 字典树(Trie)的学习笔记
按照一本通往下学,学到吐血了... 例题1 字典树模板题吗. 先讲讲字典树: 给出代码(太简单了...)! #include<cstdio> #include<cstring> ...
- 817E. Choosing The Commander trie字典树
LINK 题意:现有3种操作 加入一个值,删除一个值,询问pi^x<k的个数 思路:很像以前lightoj上写过的01异或的字典树,用字典树维护数求异或值即可 /** @Date : 2017- ...
- HDU6625: three arrays (字典树处理xor)
题意:给出A数组,B数组,你可以对A和B分别进行重排列,使得C[i]=A[i]^B[i]的字典序最小. 思路:对于这类题,显然需要建立字典树,然后某种形式取分治,或者贪心. 假设现在有了两颗字典树A ...
- GCPC 2013_A Boggle DFS+字典树 CSU 1457
上周比赛的题目,由于那个B题被神编译器的优化功能给卡了,就没动过这个题,其实就是个字典树嘛.当然,由于要在Boggle矩阵里得到初始序列,我还一度有点虚,不知道是用BFS还是DFS,最后发现DFS要好 ...
- HDU 5687 Problem C ( 字典树前缀增删查 )
题意 : 度熊手上有一本神奇的字典,你可以在它里面做如下三个操作: 1.insert : 往神奇字典中插入一个单词 2.delete: 在神奇字典中删除所有前缀等于给定字符串的单词 3.search: ...
- SPOJ MAXOR (分块 || 可持久化字典树 || 异或)(好题)
You are given a sequence A[1], A[2], ..., A[N]. (0 ≤ A[i] < 231, 1 ≤ N ≤ 12000). A query is defin ...
随机推荐
- flask 源码专题(十一):LocalStack和Local对象实现栈的管理
目录 04 LocalStack和Local对象实现栈的管理 1.源码入口 1. flask源码关于local的实现 2. flask源码关于localstack的实现 3. 总结 04 LocalS ...
- MYSQL 之 JDBC(一): 数据库连接(一)通过Driver接口获取数据库连接
通过Driver接口获取数据库连接 数据持久化 数据库存取技术分类 JDBC直接访问数据库 JDO技术 第三方O/R工具,如Hibernate,ibatis等JDBC是java访问数据库的基石 JDB ...
- 数据可视化之分析篇(八)Power BI数据分析应用:结构百分比分析法
https://zhuanlan.zhihu.com/p/113113765 PowerBI数据分析02:结构百分比分析法 作者:海艳 结构百分比分析法,又称纵向分析,是指同一期间财务报表中不同项目间 ...
- JavaScript图形实例:阿基米德螺线
1.阿基米德螺线 阿基米德螺线亦称“等速螺线”.当一点P沿动射线OP以等速率运动的同时,该射线又以等角速度绕点O旋转,点P的轨迹称为“阿基米德螺线”. 阿基米德螺线的笛卡尔坐标方程式为: r=10*( ...
- 循序渐进VUE+Element 前端应用开发(16)--- 组织机构和角色管理模块的处理
在前面随笔<循序渐进VUE+Element 前端应用开发(15)--- 用户管理模块的处理>中介绍了用户管理模块的内容,包括用户列表的展示,各种查看.编辑.新增对话框的界面处理和后台数据处 ...
- Java常用API(Scanner类)
Java常用API( Scanner类)1 1.Scanner类 首先给大家介绍一下什么是JavaAPI API(Application Programming Interface),应用程序编程接口 ...
- row_number() over()排序功能说明
1.row_number() over()排序功能: (1) row_number() over()分组排序功能: 在使用 row_number() over()函数时候,over()里头的分组以及排 ...
- SpringBoot2.x入门:使用MyBatis
这是公众号<Throwable文摘>发布的第25篇原创文章,收录于专辑<SpringBoot2.x入门>. 前提 这篇文章是<SpringBoot2.x入门>专辑的 ...
- pycharm控制台输出的日志全是红色的字体?
问题:logging在pycharm控制台输出的日志的字体全是红色的,怎么办? 图片描述: 解决办法:设置 -> 搜索“Console” -> 结果:改完立马生效
- ES的集群原理
文章转载自:https://www.cnblogs.com/soft2018/p/10213266.html 一.ES集群原理 查看集群健康状况:URL+ /GET _cat/health (1).E ...