Spark核心组件通识概览
在说Spark之前,笔者在这里向对Spark感兴趣的小伙伴们建议,想要了解、学习、使用好Spark,Spark的官网是一个很好的工具,几乎能满足你大部分需求。同时,建议学习一下scala语言,主要基于两点:1. Spark是scala语言编写的,要想学好Spark必须研读分析它的源码,当然其他技术也不例外;2. 用scala语言编写Spark程序相对于用Java更方便、简洁、开发效率更高(后续我会针对scala语言做单独讲解)。书归正传,下面整体介绍一下Spark生态圈。
Apache Spark是一种快速、通用、可扩展、可容错的、基于内存迭代计算的大数据分析引擎。首先强调一点, Spark目前是一个处理数据的计算引擎, 不做存储。首先咱们通过一张图来看看目前Spark生态圈都包括哪些核心组件:
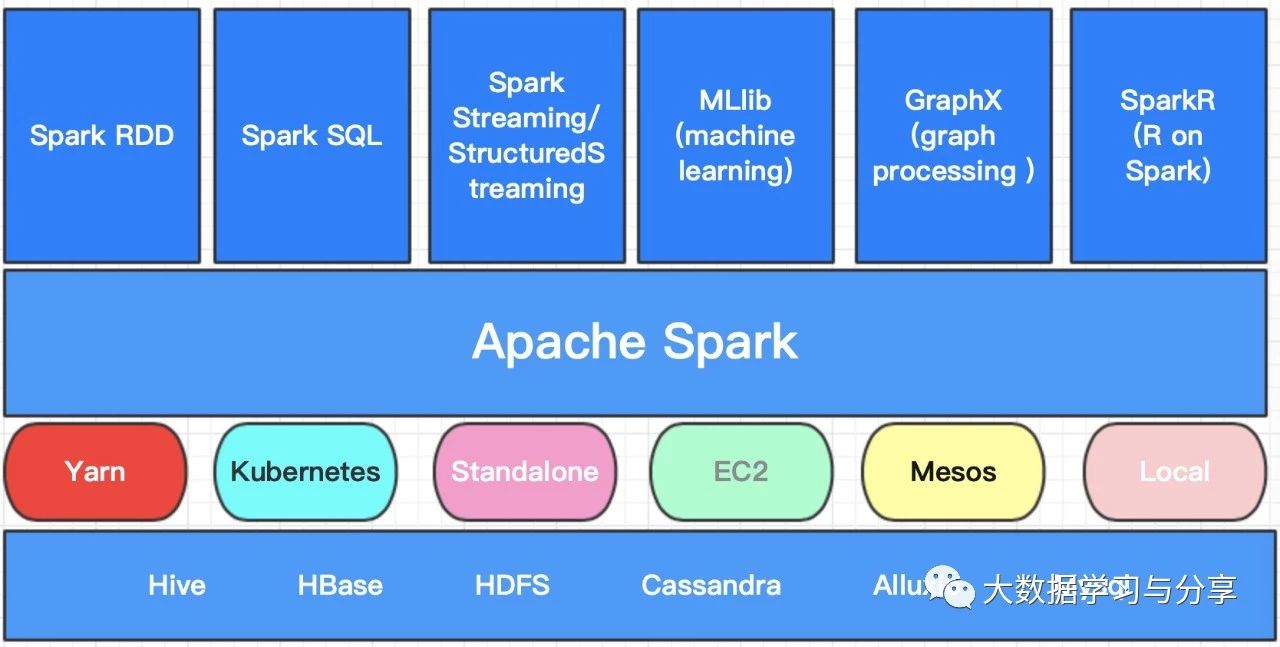
本篇文章先简单介绍一下各个组件的使用场景,后续笔者会单独详解其中的核心组件,以下所讲均基于Spark2.X版本。
Spark RDD和Spark SQL
Spark RDD和Spark SQL多用于离线场景,但Spark RDD即可以处理结构化数据也可以处理非结构数据,但Spark SQL是处理结构化数据的,内部通过dataset来处理分布式数据集
SparkStreaming和StructuredStreaming
用于流式处理,但强调一点Spark Streaming是基于微批处理来处理数据的,即使Structured Streaming在实时方面作了一定优化,但就目前而言,相对于Flink、Storm,Spark的流式处理准备确实准实时处理
MLlib
用于机器学习,当然pyspark也有应用是基于python做数据处理
GraphX
用于图计算
Spark R
基于R语言进行数据处理、统计分析的
下面介绍一下Spark的特性
快
实现DAG执行引擎,基于内存迭代式计算处理数据,Spark可以将数据分析过程的中间结果保存在内存中,从而不需要反复的从外部存储系统中读写数据,相较于mapreduce能更好地适用于机器学习和数据挖掘和等需要迭代运算的场景。易用
支持scala、java、python、R多种语言;支持多种高级算子(目前有80多种),使用户可以快速构建不同应用;支持scala、python等shell交互式查询通用
Spark强调一站式解决方案,集批处理、流处理、交互式查询、机器学习及图计算于一体,避免多种运算场景下需要部署不同集群带来的资源浪费容错性好
在分布式数据集计算时通过checkpoint来实现容错,当某个运算环节失败时,不需要从头开始重新计算【往往是checkpoint到HDFS上】兼容性强
可以运行在Yarn、Kubernetes、Mesos等资源管理器上,实现Standalone模式作为内置资源管理调度器,支持多种数据源
关注微信公众号:大数据学习与分享,获取更多技术干货
Spark核心组件通识概览的更多相关文章
- [Spark Core] Spark 核心组件
0. 说明 [Spark 核心组件示意图] 1. RDD resilient distributed dataset , 弹性数据集 轻量级的数据集合,逻辑上的集合.等价于 list 没有携带数据. ...
- Spark核心组件
Spark核心组件 1.RDD resilient distributed dataset, 弹性分布式数据集.逻辑上的组件,是spark的基本抽象,代表不可变,分区化的元素集合,可以进行并行操作.该 ...
- 【原】Spark Rpc通信源码分析
Spark 1.6+推出了以RPCEnv.RPCEndpoint.RPCEndpointRef为核心的新型架构下的RPC通信方式.其具体实现有Akka和Netty两种方式,Akka是基于Scala的A ...
- 前端进阶笔记(一)---JS语言通识
一.语言按照语法分类 1.非形式语言:中文 英文 2.形式语言:乔姆斯基谱系(四种文法 上下文包含文法) 0型 无限制文法 1型 上下文相关文法 2型 上下文无关文法 正则文法 二 产生式(BNF) ...
- linux通识
linux是服务器应用领域的开源且免费的多用户多任务操作系统的内核. 以下是对上述论断的解释: 操作系统 简言之,操作系统乃是所有计算设备的大管家,小到智能手表,大到航天航空设备,所有需要操控硬件的地 ...
- java IO流体系--通识篇
1.I/O流是什么 Java的I/O流是实现编程语言的输入/输出的基础能力,操作的对象有外部设备.存储设备.网络连接等等,是所有服务器端的编程语言都应该具备的基础能力. I = Input(输入),输 ...
- Spark内核| 调度策略| SparkShuffle| 内存管理| 内存空间分配| 核心组件
1. 调度策略 TaskScheduler会先把DAGScheduler给过来的TaskSet封装成TaskSetManager扔到任务队列里,然后再从任务队列里按照一定的规则把它们取出来在Sched ...
- 《大数据Spark企业级实战 》
基本信息 作者: Spark亚太研究院 王家林 丛书名:决胜大数据时代Spark全系列书籍 出版社:电子工业出版社 ISBN:9787121247446 上架时间:2015-1-6 出版日期:20 ...
- 【大数据】Spark内核解析
1. Spark 内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spa ...
随机推荐
- Navicat 闲置时间过长会卡死
前段时间使用navicat连接线上的数据库,Navicat 闲置时间过长会卡死.解决方案:选中数据库,右键点击 编辑连接,修改保持连接间隔为 20秒.非常 so easy ! 1. 选中数据库,右键点 ...
- 不用写代码也能做表单 —— 加载meta即可
做增删改查要写多少代码? 一个表单一套代码,十个表单十套代码吗? 我这么懒,怎么会写这么多代码? 我想做到:即使一百个表单也只需要一套代码(而且不需要复制粘贴).实现多个表单,只需要加载不同的meta ...
- .NET Core表达式树的梳理
最近要重写公司自己开发的ORM框架:其中有一部分就是查询的动态表达式:于是对这方面的东西做了一个简单的梳理 官网的解释: 表达式树以树形数据结构表示代码,其中每一个节点都是一种表达式,比如方法调用和 ...
- Codeforces Round #670 (Div. 2) 深夜掉分(A - C题补题)
1406A. Subset Mex https://codeforces.com/contest/1406/problem/A Example input 4 6 0 2 1 5 0 1 3 0 1 ...
- Linux实战(13):Centos8安装FFmpeg
此文章所做的操作参考漏网的鱼:参考链接 步骤1:安装RPMfusion Yum存储库 RHEL或兼容发行版(如CentOS)上启用EPEL. dnf -y install https://downlo ...
- Docker之简单操作
安装完Docker后,我们就可以与Docker进行交互来创建和管理容器等操作. 容器生命周期管理: 创建一个新的容器并运行一个命令 docker run [OPTIONS] IMAGE [COMMAN ...
- Python爬取股票信息,并实现可视化数据
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今 ...
- 高德AR & 车道级导航技术演进与实践
2020云栖大会于9月17日-18日在线上举行,阿里巴巴高德地图携手合作伙伴精心组织了"智慧出行"专场,为大家分享高德地图在打造基于DT+AI和全面上云架构下的新一代出行生活服务平 ...
- 自定义springboot - starter 实现日志打印,并支持动态可插拔
1. starter 命名规则: springboot项目有很多专一功能的starter组件,命名都是spring-boot-starter-xx,如spring-boot-starter-loggi ...
- Leetcode PHP题解--D125 107. Binary Tree Level Order Traversal II
val = $value; } * } */ class Solution { private $vals = []; /** * @param TreeNode $root * @return In ...