Apache Hudi与Apache Flink集成
感谢王祥虎@wangxianghu 投稿
Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目。是当前最为热门的数据湖框架之一。
1. 为何要解耦
Hudi自诞生至今一直使用Spark作为其数据处理引擎。如果用户想使用Hudi作为其数据湖框架,就必须在其平台技术栈中引入Spark。放在几年前,使用Spark作为大数据处理引擎可以说是很平常甚至是理所当然的事。因为Spark既可以进行批处理也可以使用微批模拟流,流批一体,一套引擎解决流、批问题。然而,近年来,随着大数据技术的发展,同为大数据处理引擎的Flink逐渐进入人们的视野,并在计算引擎领域获占据了一定的市场,大数据处理引擎不再是一家独大。在大数据技术社区、论坛等领地,Hudi是否支持使用flink计算引擎的的声音开始逐渐出现,并日渐频繁。所以使Hudi支持Flink引擎是个有价值的事情,而集成Flink引擎的前提是Hudi与Spark解耦。
同时,纵观大数据领域成熟、活跃、有生命力的框架,无一不是设计优雅,能与其他框架相互融合,彼此借力,各专所长。因此将Hudi与Spark解耦,将其变成一个引擎无关的数据湖框架,无疑是给Hudi与其他组件的融合创造了更多的可能,使得Hudi能更好的融入大数据生态圈。
2. 解耦难点
Hudi内部使用Spark API像我们平时开发使用List一样稀松平常。自从数据源读取数据,到最终写出数据到表,无处不是使用Spark RDD作为主要数据结构,甚至连普通的工具类,都使用Spark API实现,可以说Hudi就是用Spark实现的一个通用数据湖框架,它与Spark的绑定可谓是深入骨髓。
此外,此次解耦后集成的首要引擎是Flink。而Flink与Spark在核心抽象上差异很大。Spark认为数据是有界的,其核心抽象是一个有限的数据集合。而Flink则认为数据的本质是流,其核心抽象DataStream中包含的是各种对数据的操作。同时,Hudi内部还存在多处同时操作多个RDD,以及将一个RDD的处理结果与另一个RDD联合处理的情况,这种抽象上的区别以及实现时对于中间结果的复用,使得Hudi在解耦抽象上难以使用统一的API同时操作RDD和DataStream。
3. 解耦思路
理论上,Hudi使用Spark作为其计算引擎无非是为了使用Spark的分布式计算能力以及RDD丰富的算子能力。抛开分布式计算能力外,Hudi更多是把 RDD作为一个数据结构抽象,而RDD本质上又是一个有界数据集,因此,把RDD换成List,在理论上完全可行(当然,可能会牺牲些性能)。为了尽可能保证Hudi Spark版本的性能和稳定性。我们可以保留将有界数据集作为基本操作单位的设定,Hudi主要操作API不变,将RDD抽取为一个泛型, Spark引擎实现仍旧使用RDD,其他引擎则根据实际情况使用List或者其他有界数据集。
解耦原则:
1)统一泛型。Spark API用到的JavakRDD<HoodieRecord>,JavaRDD<HoodieKey>,JavaRDD<WriteStatus>统一使用泛型I,K,O代替;
2)去Spark化。抽象层所有API必须与Spark无关。涉及到具体操作难以在抽象层实现的,改写为抽象方法,引入Spark子类实现。
例如:Hudi内部多处使用到了JavaSparkContext#map()方法,去Spark化,则需要将JavaSparkContext隐藏,针对该问题我们引入了HoodieEngineContext#map()方法,该方法会屏蔽map的具体实现细节,从而在抽象成实现去Spark化。
3)抽象层尽量减少改动,保证hudi原版功能和性能;
4)使用HoodieEngineContext抽象类替换JavaSparkContext,提供运行环境上下文。
4.Flink集成设计
Hudi的写操作在本质上是批处理,DeltaStreamer的连续模式是通过循环进行批处理实现的。为使用统一API,Hudi集成flink时选择攒一批数据后再进行处理,最后统一进行提交(这里flink我们使用List来攒批数据)。
攒批操作最容易想到的是通过使用时间窗口来实现,然而,使用窗口,在某个窗口没有数据流入时,将没有输出数据,Sink端难以判断同一批数据是否已经处理完。因此我们使用flink的检查点机制来攒批,每两个barrier之间的数据为一个批次,当某个子任务中没有数据时,mock结果数据凑数。这样在Sink端,当每个子任务都有结果数据下发时即可认为一批数据已经处理完成,可以执行commit。
DAG如下:
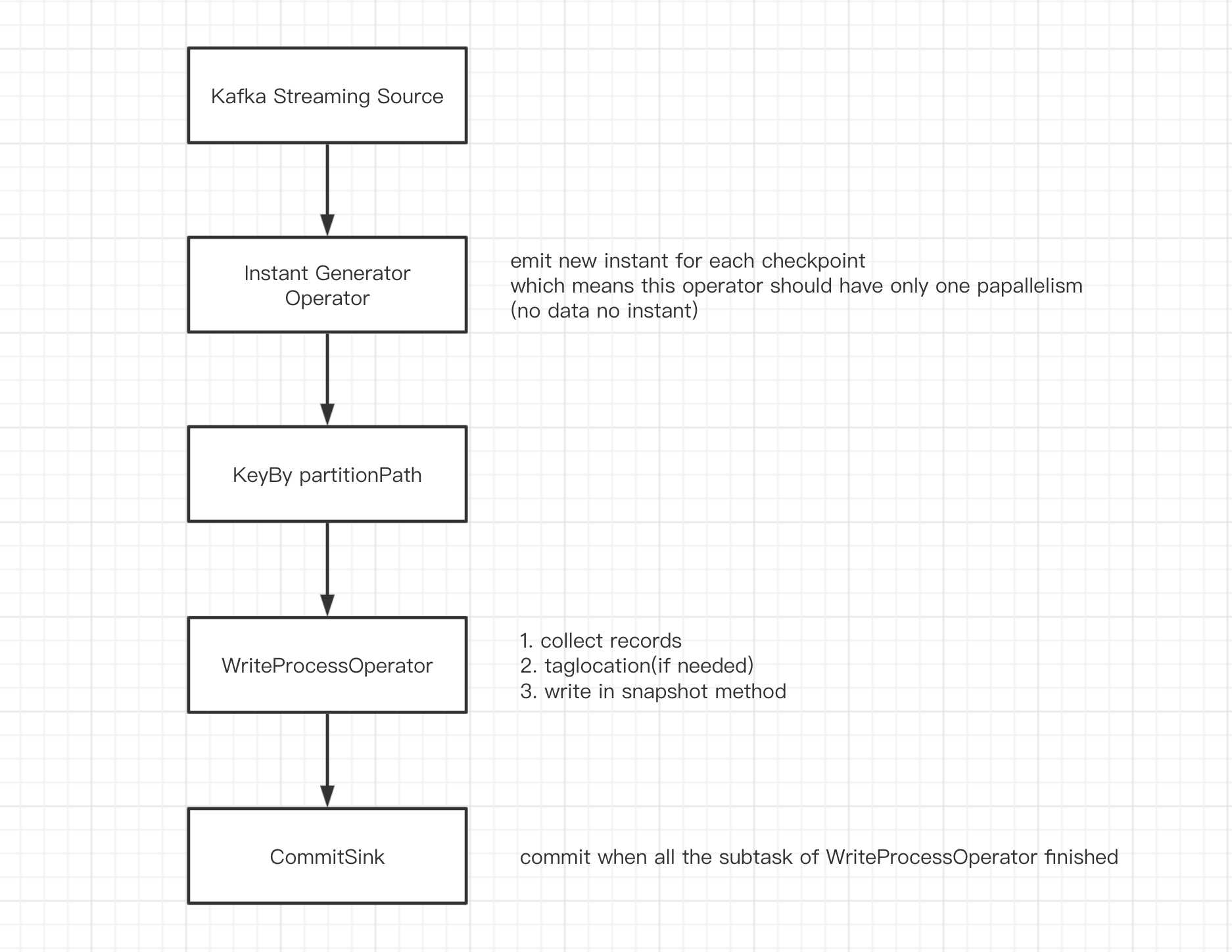
source 接收kafka数据,转换成
List<HoodieRecord>;InstantGeneratorOperator 生成全局唯一的instant.当上一个instant未完成或者当前批次无数据时,不创建新的instant;
KeyBy partitionPath 根据
partitionPath分区,避免多个子任务写同一个分区;WriteProcessOperator 执行写操作,当当前分区无数据时,向下游发送空的结果数据凑数;
CommitSink 接收上游任务的计算结果,当收到
parallelism个结果时,认为上游子任务全部执行完成,执行commit.
注:
InstantGeneratorOperator和WriteProcessOperator 均为自定义的Flink算子,InstantGeneratorOperator会在其内部阻塞检查上一个instant的状态,保证全局只有一个inflight(或requested)状态的instant.WriteProcessOperator是实际执行写操作的地方,其写操作在checkpoint时触发。
5. 实现示例
1) HoodieTable
/**
* Abstract implementation of a HoodieTable.
*
* @param <T> Sub type of HoodieRecordPayload
* @param <I> Type of inputs
* @param <K> Type of keys
* @param <O> Type of outputs
*/
public abstract class HoodieTable<T extends HoodieRecordPayload, I, K, O> implements Serializable {
protected final HoodieWriteConfig config;
protected final HoodieTableMetaClient metaClient;
protected final HoodieIndex<T, I, K, O> index;
public abstract HoodieWriteMetadata<O> upsert(HoodieEngineContext context, String instantTime,
I records);
public abstract HoodieWriteMetadata<O> insert(HoodieEngineContext context, String instantTime,
I records);
public abstract HoodieWriteMetadata<O> bulkInsert(HoodieEngineContext context, String instantTime,
I records, Option<BulkInsertPartitioner<I>> bulkInsertPartitioner);
......
}
HoodieTable 是 hudi的核心抽象之一,其中定义了表支持的insert,upsert,bulkInsert等操作。以 upsert 为例,输入数据由原先的 JavaRDD<HoodieRecord> inputRdds 换成了 I records, 运行时 JavaSparkContext jsc 换成了 HoodieEngineContext context.
从类注释可以看到 T,I,K,O分别代表了hudi操作的负载数据类型、输入数据类型、主键类型以及输出数据类型。这些泛型将贯穿整个抽象层。
2) HoodieEngineContext
/**
* Base class contains the context information needed by the engine at runtime. It will be extended by different
* engine implementation if needed.
*/
public abstract class HoodieEngineContext {
public abstract <I, O> List<O> map(List<I> data, SerializableFunction<I, O> func, int parallelism);
public abstract <I, O> List<O> flatMap(List<I> data, SerializableFunction<I, Stream<O>> func, int parallelism);
public abstract <I> void foreach(List<I> data, SerializableConsumer<I> consumer, int parallelism);
......
}
HoodieEngineContext 扮演了 JavaSparkContext 的角色,它不仅能提供所有 JavaSparkContext能提供的信息,还封装了 map,flatMap,foreach等诸多方法,隐藏了JavaSparkContext#map(),JavaSparkContext#flatMap(),JavaSparkContext#foreach()等方法的具体实现。
以map方法为例,在Spark的实现类 HoodieSparkEngineContext中,map方法如下:
@Override
public <I, O> List<O> map(List<I> data, SerializableFunction<I, O> func, int parallelism) {
return javaSparkContext.parallelize(data, parallelism).map(func::apply).collect();
}
在操作List的引擎中其实现可以为(不同方法需注意线程安全问题,慎用parallel()):
@Override
public <I, O> List<O> map(List<I> data, SerializableFunction<I, O> func, int parallelism) {
return data.stream().parallel().map(func::apply).collect(Collectors.toList());
}
注:map函数中抛出的异常,可以通过包装SerializableFunction<I, O> func解决.
这里简要介绍下 SerializableFunction:
@FunctionalInterface
public interface SerializableFunction<I, O> extends Serializable {
O apply(I v1) throws Exception;
}
该方法实际上是 java.util.function.Function 的变种,与java.util.function.Function 不同的是 SerializableFunction可以序列化,可以抛异常。引入该函数是因为JavaSparkContext#map()函数能接收的入参必须可序列,同时在hudi的逻辑中,有多处需要抛异常,而在Lambda表达式中进行 try catch 代码会略显臃肿,不太优雅。
6.现状和后续计划
6.1 工作时间轴
2020年4月,T3出行(杨华@vinoyang,王祥虎@wangxianghu)和阿里巴巴的同学(李少锋@leesf)以及若干其他小伙伴一起设计、敲定了该解耦方案;
2020年4月,T3出行(王祥虎@wangxianghu)在内部完成了编码实现,并进行了初步验证,得出方案可行的结论;
2020年7月,T3出行(王祥虎@wangxianghu)将该设计实现和基于新抽象实现的Spark版本推向社区(HUDI-1089);
2020年9月26日,顺丰科技基于T3内部分支修改完善的版本在 Apache Flink Meetup(深圳站)公开PR, 使其成为业界第一个在线上使用Flink将数据写hudi的企业。
2020年10月2日,HUDI-1089 合并入hudi主分支,标志着hudi-spark解耦完成。
6.2 后续计划
1)推进hudi和flink集成
将flink与hudi的集成尽快推向社区,在初期,该特性可能只支持kafka数据源。
2)性能优化
为保证hudi-spark版本的稳定性和性能,此次解耦没有太多考虑flink版本可能存在的性能问题。
3)类flink-connector-hudi第三方包开发
将hudi-flink的绑定做成第三方包,用户可以在flink应用中以编码方式读取任意数据源,通过这个第三方包写入hudi。
Apache Hudi与Apache Flink集成的更多相关文章
- 重磅!Vertica集成Apache Hudi指南
1. 摘要 本文演示了使用外部表集成 Vertica 和 Apache Hudi. 在演示中我们使用 Spark 上的 Apache Hudi 将数据摄取到 S3 中,并使用 Vertica 外部表访 ...
- Apache Hudi助力nClouds加速数据交付
1. 概述 在nClouds上,当客户的业务决策取决于对近实时数据的访问时,客户通常会向我们寻求有关数据和分析平台的解决方案.但随着每天创建和收集的数据量都在增加,这使得使用传统技术进行数据分析成为一 ...
- Apache Hudi重磅特性解读之存量表高效迁移机制
1. 摘要 随着Apache Hudi变得越来越流行,一个挑战就是用户如何将存量的历史表迁移到Apache Hudi,Apache Hudi维护了记录级别的元数据以便提供upserts和增量拉取的核心 ...
- Apache Hudi使用简介
Apache Hudi使用简介 目录 Apache Hudi使用简介 数据实时处理和实时的数据 业务场景和技术选型 Apache hudi简介 使用Aapche Hudi整体思路 Hudi表数据结构 ...
- 恭喜!Apache Hudi社区新晋两位Committer
1. 介绍 经过Apache Hudi项目委员会讨论及投票,向WangXiangHu和LiWei 2人发出Committer邀请,2人均已接受邀请并顺利成为Committer,也使得Apache Hu ...
- 基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse. 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse. 在深 ...
- Apache Hudi 0.5.1版本重磅发布
历经大约3个月时间,Apache Hudi 社区终于发布了0.5.1版本,这是Apache Hudi发布的第二个Apache版本,该版本中一些关键点如下 版本升级 将Spark版本从2.1.0升级到2 ...
- 官宣!ASF官方正式宣布Apache Hudi成为顶级项目
马萨诸塞州韦克菲尔德(Wakefield,MA)- 2020年6月 - Apache软件基金会(ASF).350多个开源项目和全职开发人员.管理人员和孵化器宣布:Apache Hudi正式成为Apac ...
- 重磅!解锁Apache Flink读写Apache Hudi新姿势
感谢阿里云 Blink 团队Danny Chan的投稿及完善Flink与Hudi集成工作. 1. 背景 Apache Hudi 是目前最流行的数据湖解决方案之一,Data Lake Analytics ...
随机推荐
- UVA 11292-Dragon of Loowater (贪心)
Once upon a time, in the Kingdom of Loowater, a minor nuisance turned into a major problem. The shor ...
- 2020重新出发,NOSQL,redis高并发系统的分析和设计
高并发系统的分析和设计 任何系统都不是独立于业务进行开发的,真正的系统是为了实现业务而开发的,所以开发高并发网站抢购时,都应该先分析业务需求和实际的场景,在完善这些需求之后才能进入系统开发阶段. 没有 ...
- css动画实现吃豆豆
话不多说,直接上代码:(作为一个初学者写的代码,多么0基础都能看的懂吧.) HTML部分 <!DOCTYPE html> <html lang=en> <head> ...
- Solr专题(四)Solr安全设置
因为solr的admin界面默认只需要知道ip和端口就能直接访问,如果被别有用心的人盯上就很容易给你的系统带来重大的破坏,所以我们应该限制访问. 请注意本例使用的是Solr7. Solr集成了以下几 ...
- Roadblocks(POJ 3255)
原题如下: Roadblocks Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 19314 Accepted: 6777 ...
- linux账户的锁定和解锁、禁用账号
l——lock锁定 S——STATUS查看 u——unlock解锁 1.通过passwd命令锁定和解锁: [root@localhost ~]# passwd -S abc ——passwd -S ...
- spring官网在线学习文档翻译
Core Technologies (核心技术) Version 5.0.8.RELEASE 版本5.0.8RELEASE This part of the reference documentati ...
- Unit1:Android
unit1 1.安卓版本 最新数据访问维基百科 2008年,android1.0 2011年,android3.0,平板失败 同年10月,android4.0,无差别使用 2014年,android5 ...
- 从一次编译出发梳理概念: Jetty,Jersey,hk2,glassFish,Javax,Jakarta
从一次编译出发梳理概念: Jetty,Jersey,hk2,glassFish,Javax,Jakarta 目录 从一次编译出发梳理概念: Jetty,Jersey,hk2,glassFish,Jav ...
- k8s Docker 安装
k8s Docker 安装 一.运行环境 Centos 7.7 虚拟机内核为 3.10 基础组件版本: k8s.gcr.io/kube-apiserver:v1.16.0 k8s.gcr.io/kub ...