Kafka 探险 - 生产者源码分析: 核心组件
这个 Kafka 的专题,我会从系统整体架构,设计到代码落地。和大家一起杠源码,学技巧,涨知识。希望大家持续关注一起见证成长!
我相信:技术的道路,十年如一日!十年磨一剑!
往期文章
前言
我们说 Kafka 是一个消息队列,其实更加确切的说:是 Broker 这个核心部件。为何这么说?你会发现我们可以通过控制台、 Java 代码、 C++ 代码、甚至是 Socket 向 Broker 写入消息,只要我们遵从了 Kafka 写入消息的协议,就可以将消息发送到 Kafka 队列中。
用专业一点的话术来说,Kafka 定义了一个应用层的网络协议,只要我们基于传输层构造出符合这个协议的数据,就是合法的 Kafka 消息。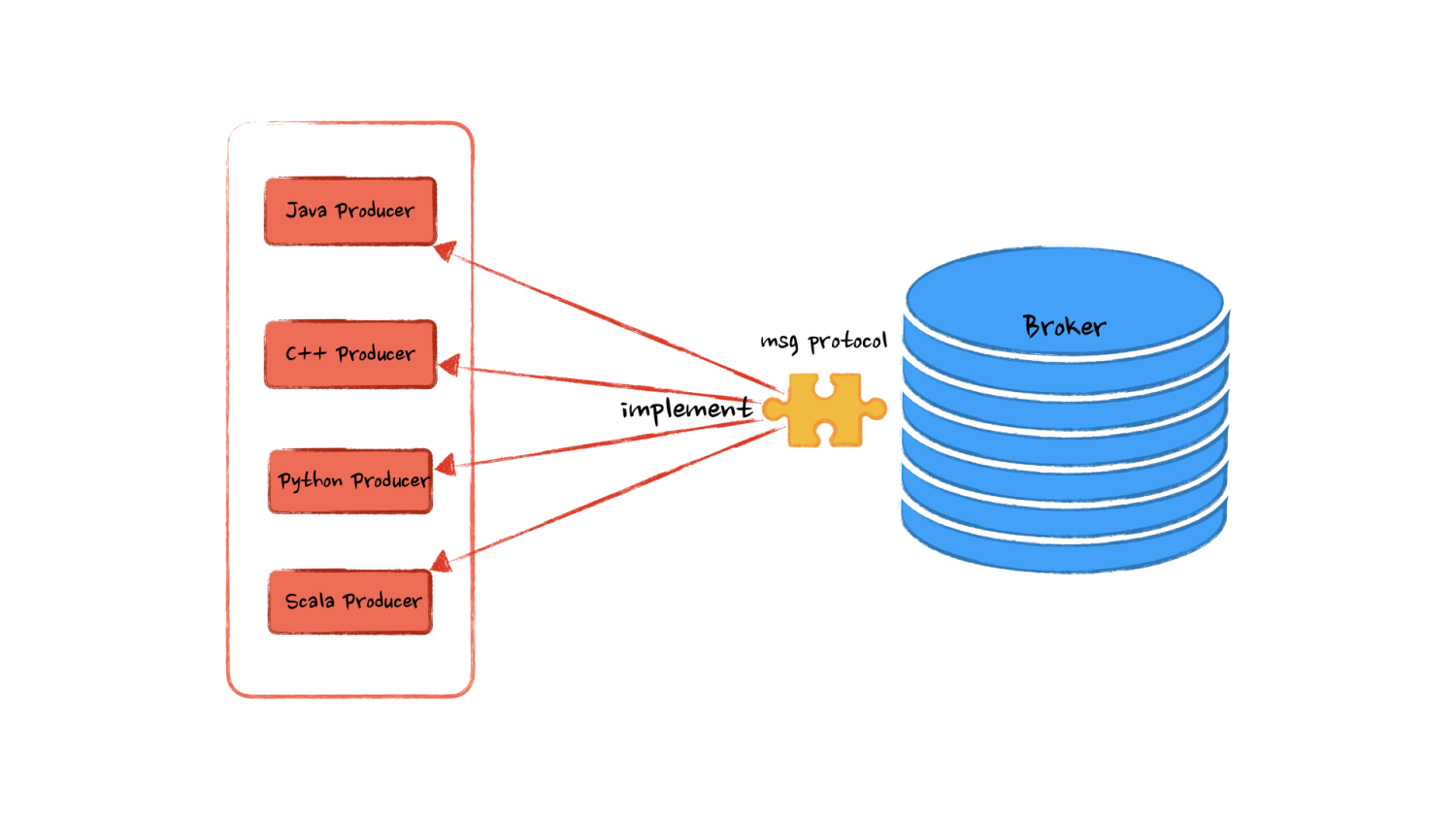
所以说我们写入 Kafka 消息的只是一个生产者的客户端,他的形式多种多样,有 Java ,Python,C++ 等多种实现,那么我们每次发消息难道还需要自己去实现这套发送消息的协议么?显然 Kafka 官方已经考虑到这个问题了,为了给我们提供 开箱即用 的消息队列,官方已经帮我们写好了各种语言的优质生产者实现,例如我们今天要讨论的 Java 版本的实现。
思考
前面提到 Kafka 帮我们实现了各个版本的生产者代码,其实他也可以完全不提供这份代码,因为核心的队列的功能已经实现了,这些客户端的代码也可以完全交由用户自己实现。
那么假如没有官方代码,我们又该实现一些什么功能,有哪些接口,哪些方法,以及如何组织这些代码呢。带着这样的问题我们一起来思考一下!一般对于这种带有数据流转的设计,我会从 由谁产生? 什么数据? 通往哪去? 如何保证通路可靠? 这几个方面来考虑。
消息自然是通过应用程序构造出来并提供给生产者,生产者首先要知道需要将消息发送到哪个 Broker 的哪个 Topic,以及 Topic 的具体 Partition 。那么必然需要配置客户端的 Broker集群地址 ,需要发送的 Topic 名称 ,以及 消息的分区策略 ,是指定到具体的分区还是通过某个 key hash 到不同的分区。
知道了消息要通往哪,还需要知道发送的是什么格式的消息,是字符串还是数字或是被序列化的二进制对象。 消息序列化 将需要消息序列化成字节数组才方便在网络上传输,所以要配置生产者的消息序列化策略,最好是可以通过传递枚举或者类名的方式自动构造序列化器,便于后续序列化过程的扩展。
从上面一篇文章 《Kafka 探险 - 架构简介》 了解到:消息队列常常用于多个系统之间的异步调用,那么这种调用关系就没有强实时依赖。由于发消息到 Kafka 会产生 网络 I/O ,相对来说比较耗时,那么消息发送这一动作除了同步调用, 是否也可以设置为异步,提高生产者的吞吐呢? 。并且大量消息发送场景, 我们可以设置一个窗口,窗口可以是时间维度也可以是消息数量维度,将消息积攒起来批次发送,减少网络 I/O 次数,提高吞吐量。
最后呢为了保证消息可以最大程度的成功发送到 Broker ,我们还需要一些 失败重试机制 ,例如失败后放到重试队列中,隔一段时间尝试再次发送。
理清思路
通过上面的分析,我们会有一个大致的认识,应该会有哪些方法,以及底层的大致的设计会分为哪几个部分。但是不够清楚,不够明晰。
首先总结一下实现客户端的几个要点在于:
- 配置 Broker 基础信息:集群地址、Topic、Partition
- 消息序列化,通过可扩展的序列化器实现
- 消息异步写入缓冲区,网络 I/O 线程实现消息发送
- 消息发送的失败重试机制
话不多说,用一张图画出各个核心模块以及他们之间的交互顺序: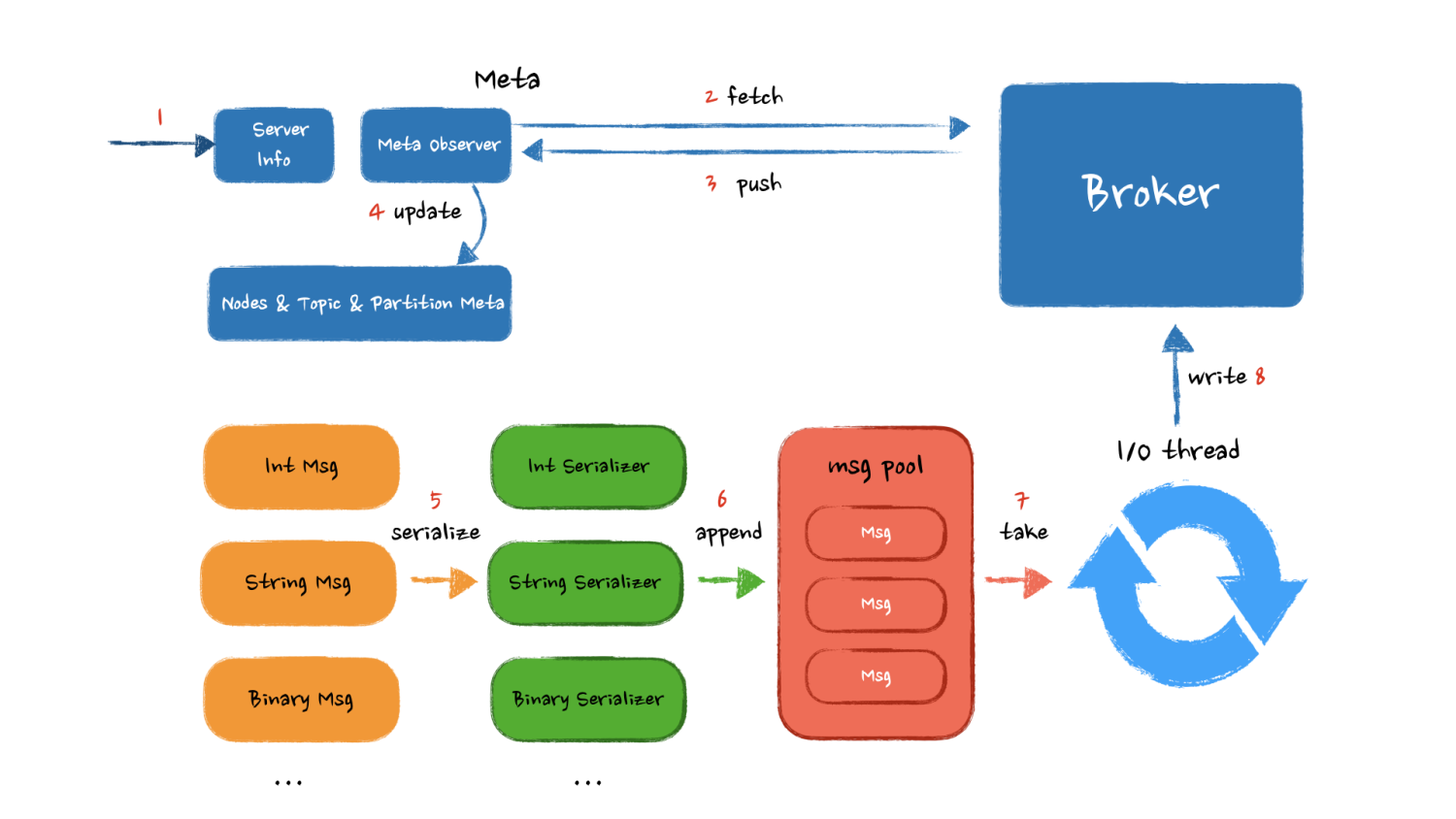
用户设定 Kafka 集群信息,生产者从 Kafka Broker 上拉取 可用 Kafka 节点、Topic 以及 Partition 对应关系。缓存到生产者成员变量中,如果 Broker 集群有扩容,或者有机器下线需要重新获取这些服务信息。
客户端根据用户设置的序列化器,对消息进行序列化,之后异步的将消息写入到客户端缓冲区。缓冲区内的消息到达一定的数量或者到达一个时间窗口后,网络 I/O 线程将消息从缓冲区取走,发送到 Broker 。
以上就是我对于一个 Kafka 生产者实现的思考,接下来看看官方的代码设计与我们的思路有何差别,他又是为什么这么设计。
官方设计
其实经过上面的思考和整理,我们的设计已经非常接近 Kafka 的官方设计了,官方的模块拆分的更加细致,功能更加独立。
核心组件
首先看一眼 KafkaProducer 类中有哪些成员变量,这些变量就是 Producer 的核心组件。
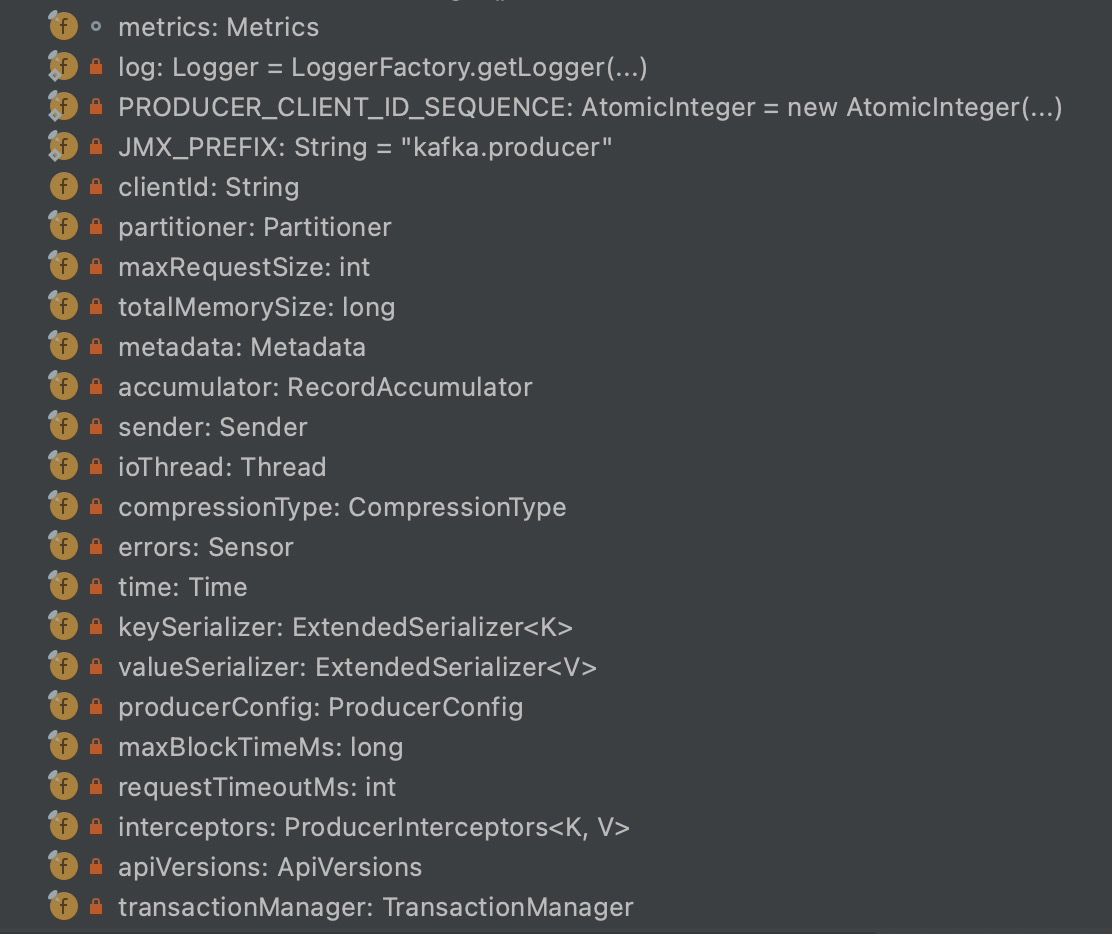
其中核心字段的解释如下:
clinetId :标识发送者Id
metric :统计指标
partitioner :分区器作用是决定消息发到哪个分区。有 key 则按照 key 的 hash ,否则使用 roundrobin
key/value Serializer :消息 key/value 序列化器
interceptors :发送之前/后对消息的统一处理
maxRequestSize :可以发送的最大消息,默认值是1M,即影响一个消息 Record 的大小,此值在服务端也是有限制的。
maxBlockTimeMs :buffer满了或者等待metadata信息的,超时的补偿机制
accumulator :累积缓冲器
networkClient :包装的网络层
sender :网络 I/O 线程
发送流程
发送一条消息的时候,数据又是怎样在这些组件之间进行流转的呢?
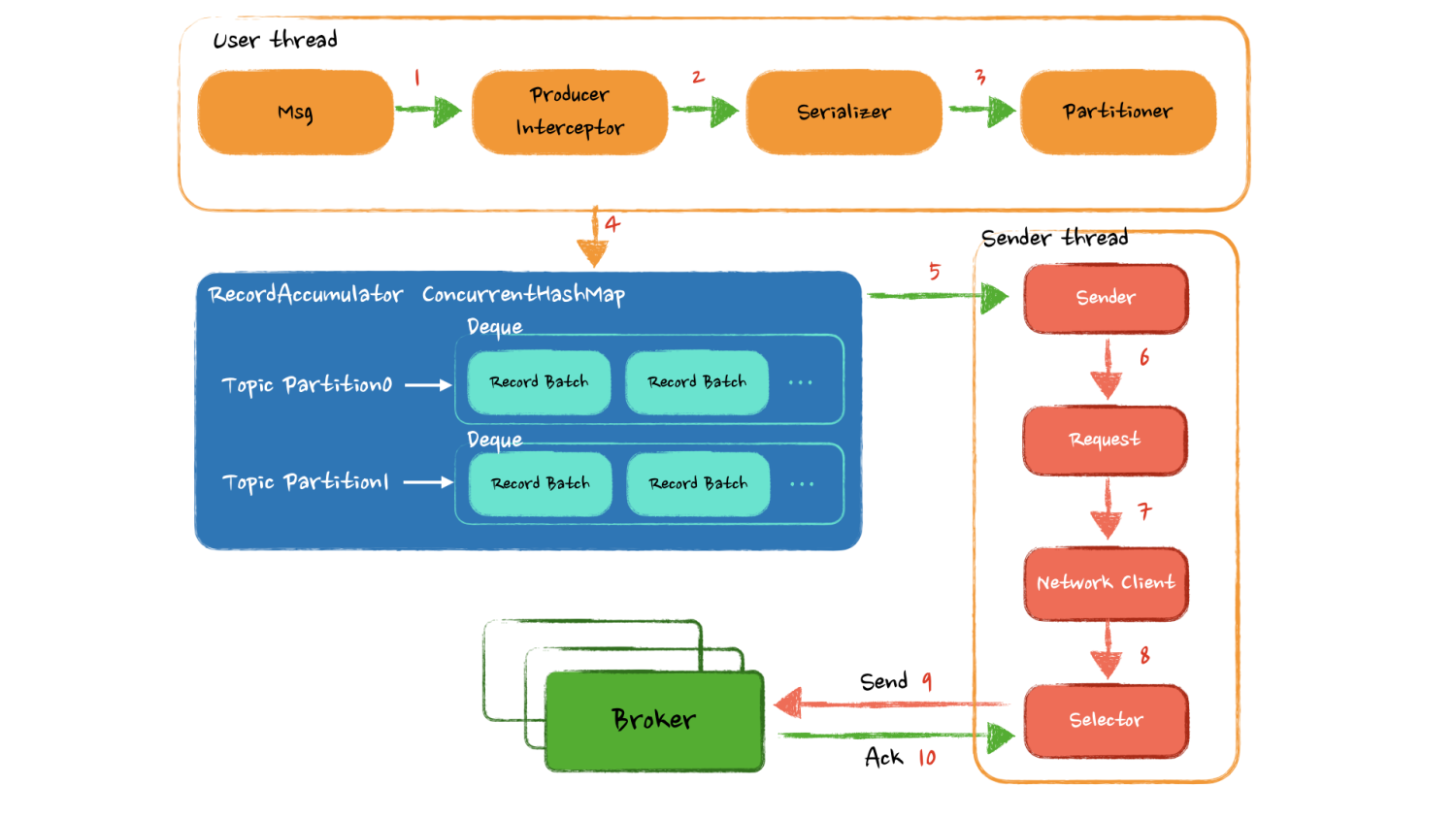
Producer调用 send 方法后,在从 Broker 获取的 Metadata 有效情况下,经过拦截器和序列化后,被分区器放到了一个缓冲区的特定位置,缓冲区由一个 ConcurrentHashMap 构成,key 为主题分区,value 是一个 deque 存放消息缓存块。从客户端角度来看如果无需关心发送结果,发送流程就已经结束了。
接下来是独立的Sender线程负责从缓冲中获取足量的数据调用 Network Client 封装层去真正发送数据,这里使用了 Java8 的 NIO 网络模型发送数据。
可以看到整个逻辑的关键点在于 RecordAccumulator 如何进行消息缓存,一般的成熟框架和中间件中都会有一套自己的内存管理机制,比如 Netty 也有一套复杂而又精妙的内存管理抽象层,这里的缓冲区也是一样的道理,主要需要去看看 Kafka 如何去做内存管理。
另外需要关注 Sender 从缓冲里以什么样的逻辑获取数据,来达到尽量少的网络交互发送尽量多的数据。还有网络失败又是如何保证数据的可靠性的。这个地方也是我们的设计和官方实现的差距,对于网络 I/O 的精心优化。
目前的篇幅已经比较长了,为了大家方便阅读理解,本篇主要从和大家一起思考如何设计一个 Kafka Producer 以及官方是如何实现的,我们之间的差距是什么,更需要关注的点是什么。通过自己的思考和对比更加能认识到不足学习到新的点!
尾声(唠叨)
这篇文章从周内就开始了,后面断断续续每天写了点,只是每天回去的确实有点晚,偶尔还给我整个失眠,精神状态不太好,周五六点多饭都没吃直接回家睡觉了,确实好困,希望下周能休息好。
这周的工作压力也很大,主要是需要推动很多上下游协同,还需要定方案。经常在想怎么交涉?怎么修改方案大家会认同?怎样说服他们? 是压力也是锻炼,说明这方面欠缺的较多,该补!
下篇文章主要会写 KafkaProducer 的缓存内存管理机制,Meta 信息更新机制,以及网络 I/O 模型的设计。敬请期待~
另外:大家也可以关注下我的微信公众号哦~ 技术分享和个人思考都会第一时间同步!

Kafka 探险 - 生产者源码分析: 核心组件的更多相关文章
- 高吞吐量的分布式发布订阅消息系统Kafka之Producer源码分析
引言 Kafka是一款很棒的消息系统,今天我们就来深入了解一下它的实现细节,首先关注Producer这一方. 要使用kafka首先要实例化一个KafkaProducer,需要有brokerIP.序列化 ...
- Kafka 0.8源码分析—ZookeeperConsumerConnector
1.HighLevelApi High Level Api是多线程的应用程序,以Topic的Partition数量为中心.消费的规则如下: 一个partition只能被同一个ConsumersGrou ...
- Kafka#4:存储设计 分布式设计 源码分析
https://sites.google.com/a/mammatustech.com/mammatusmain/kafka-architecture/4-kafka-detailed-archite ...
- Kafka源码分析(二) - 生产者
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 目录 系列文章目录 一. 使用方式 step 1: 设置必要参数 step 2: 创建KafkaProduc ...
- kafka原理和实践(三)spring-kafka生产者源码
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- apache kafka源码分析-Producer分析---转载
原文地址:http://www.aboutyun.com/thread-9938-1-1.html 问题导读1.Kafka提供了Producer类作为java producer的api,此类有几种发送 ...
- Kafka源码分析及图解原理之Producer端
一.前言 任何消息队列都是万变不离其宗都是3部分,消息生产者(Producer).消息消费者(Consumer)和服务载体(在Kafka中用Broker指代).那么本篇主要讲解Producer端,会有 ...
- 源码分析 Kafka 消息发送流程(文末附流程图)
温馨提示:本文基于 Kafka 2.2.1 版本.本文主要是以源码的手段一步一步探究消息发送流程,如果对源码不感兴趣,可以直接跳到文末查看消息发送流程图与消息发送本地缓存存储结构. 从上文 初识 Ka ...
- Kafka源码分析系列-目录(收藏不迷路)
持续更新中,敬请关注! 目录 <Kafka源码分析>系列文章计划按"数据传递"的顺序写作,即:先分析生产者,其次分析Server端的数据处理,然后分析消费者,最后再补充 ...
随机推荐
- Unity2D 人物移动切换人物图片
勾选Constraints_freeze Rotation_z轴锁定,防止碰撞偏移. public float moveSpeed = 3f;//定义移动速度 priv ...
- Linux查看、开启、关闭防火墙操作
一.防火墙区别 CentOS6自带的防火墙是iptables,CentOS7自带的防火墙是firewall. iptables:用于过滤数据包,属于网络层防火墙. firewall:底层还是使用 ip ...
- 面试 04-HTTP协议
04-HTTP协议 一面中,如果有笔试,考HTTP协议的可能性较大. #前言 一面要讲的内容: HTTP协议的主要特点 HTTP报文的组成部分 HTTP方法 get 和 post的区别 HTTP状态码 ...
- Acunetix 11手动导入Burp suite抓取的网页
设置爬取 因为Burp的代理默认配置拦截所有请求,需要先来关闭这个功能,在Proxy标签页面中,选择Intercept子标签页面,点击 Intercept is on按钮. 使用配置好代理服务器的浏览 ...
- 安装篇一:安装VMware12
#1.安装VMware12 前提:安装不了的解决办法(进入BIOS系统,把虚拟化技术那一项修改为enable) 说明:安装流程(自定义安装) #2.网络适配器设置 虚拟网络编 ...
- js对flv提取h264、aac音视频流
FLV提取里面的h264视频流 FLV和MP4支持的编码 流媒体和媒体文件的区别 流媒体是指将一连串的多媒体资料压缩后,经过互联网分段发送资料,在互联网上即时传输影音以供观赏的一种技术与过程,此技术使 ...
- easyui字典js 切换 jsp页面显示的内容
在列表中直接切换 formatter: function (value) {var name;if(value==0){name='待审批'}else if(value==1){name='通过'}e ...
- 解决 Idea 下 Lombok 无法使用
解决: 第一步,项目导入 Lombok 依赖 <dependency> <groupId>org.projectlombok</groupId> <ar ...
- Flowable 简介
一.Flowable 入门介绍 官网地址:https://www.flowable.org/ Flowable6.3中文教程:https://tkjohn.github.io/flowable-use ...
- 【代码周边】npm是What?
社区 程序员自古以来就有社区文化: 社区的意思是:拥有共同职业或兴趣的人们,自发组织在一起,通过分享信息和资源进行合作.虚拟社区的参与者经常会在线讨论相关话题,或访问某些网站.前端程序员也有社区,世界 ...