Abductive Commonsense Reasoning —— 溯因推理
Abductive Commonsense Reasoning(溯因推理)
介绍
溯因推理是对不完全观察情境的最合理解释或假设的推论。
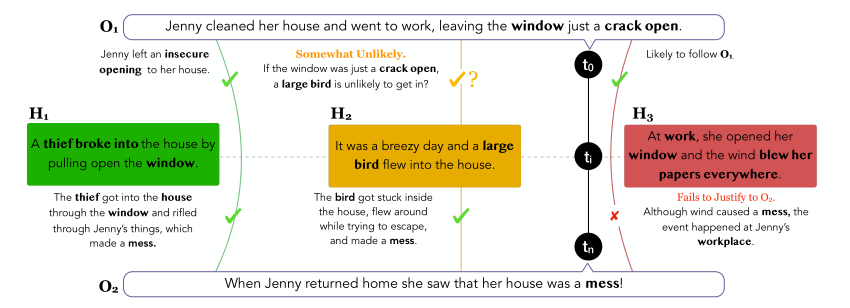
上图给出的是一个简明扼要的例子:
给定不同时间节点上的情境观测值 \(O_{1}\) 和 \(O_{2}\) ,溯因推理的任务是从给出的一众解释性假设 \(H_{1}, \space H_{2}, \space \cdots ,H_{n}\) 中选出最合理的。例如,上图在 \(t_{0}\) 时刻观测到的情境 \(O_{1}\) 是:Jenny打扫好了房间并给窗户留了条缝隙之后去工作了。而在 \(t_{n}\) 时刻,情境变成了:当Jenny回到家,发现房间里一片狼藉。针对这两个观测到的不同时间节点上情境,有若干个解释性假设 \(H_{1}, \space H_{2}, \space H_{3}\)。
- 对于假设 \(H_{1}\) ,小偷的入室盗窃(broke into)很好的承接了 \(O_{1}\) 中”未关紧窗户(a crack open)“带来的安全隐患,并很好地解释了情境 \(O_{2}\) 中房间为什么一团乱(小偷翻东西),因此看上去假设 \(H_{1}\) 非常合理的解释了情境 \(O_{1}\) 到情境 \(O_{2}\) 的转换。
- 对于假设 \(H_{2}\) ,假设中提到的大只的鸟(large bird)似乎不太可能从窗户缝隙飞进房间,但是如果不考虑情境 \(O_{1}\),该假设可以很好地解释房间乱的现象(鸟儿被困房间,为了逃离,弄得房间很乱)
- 对于假设 \(H_{3}\),前半部分(At work)可以很好地承接情境 \(O_{1}\)(Jenny去工作了,因此Jenny在工作中),但是该假设后半部分(blew her papers everywhere)完全没法解释情境 \(O_{2}\), 因为该假设完全指的是发生在办公处的事情,而情境 \(O_{2}\) 则是Jenny家中的场景。
综合以上对三个假设的考量,我们很容易得出,第一个假设是最符合情境 \(O_{1}\) 和 \(O_{2}\) 的。然而这看似简单的推理过程,对于现有的模型来说,却不是那么容易的。
虽然长期以来”溯因“这种行为被认为是人们解读、理解自然语言的核心,但受限于数据集的缺乏和模型的性能,支撑溯因自然语言推理和生成的研究却相对较少。
ART数据集
ART(叙事文本中的溯因推理——ABDUCTIVE REASONING IN NARRATIVE TEXT)是第一个用于研究叙事文本中溯因推理的大规模基准数据集。其组成如下:
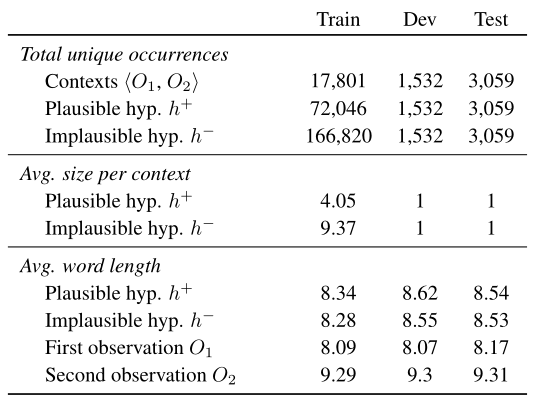
- 20K左右的叙述背景 ——成对的观察结果<\(O
_{1}\space,O_{2}\)>- 这些观察情境是根据ROCStories数据集进行编写的。ROCStories是一个由五句话组成的手动精选短篇故事的大集合。它被设计为每个故事都有一个清晰的开始和结束,这自然对应到ART数据集中的 \(O_{1},O_{2}\) 。
- 超过200K的解释性假设
- 按可能的解释性假设 \(h^{+}\) 和不太可能的解释性假设 \(h^{-}\) 进行众包。对于 \(h^{-}\) 的众包 ,要求众包工人在 \(h^{+}\) 的基础上,进行最小限度的编辑(最多改动5个单词),为每个 \(h^{+}\) 创造不可信的假设变量 \(h^{-}\)。
- 数据集分析
- 下面分别分析了对应每个观测对
任务
论文中提出的两个溯因推理任务分别是αNLI(溯因自然语言推理——Abductive Natural Language Inference)和αNLG(溯因自然语言生成 —— Abductive Natural Language Generation)。
ART数据集中每个例子按如下格式定义:
- \(O_{1}\) —— \(t_{1}\)时刻的观察
- \(O_{2}\) —— \(t_{2}\)时刻的观察
- \(h^{+}\) —— 对观察 \(O_{1}\) 和观察 \(O_{2}\) 的更合理的解释
- \(h^{-}\) —— 对观察 \(O_{1}\) 和观察 \(O_{2}\) 来说不太合理的解释
αNLI
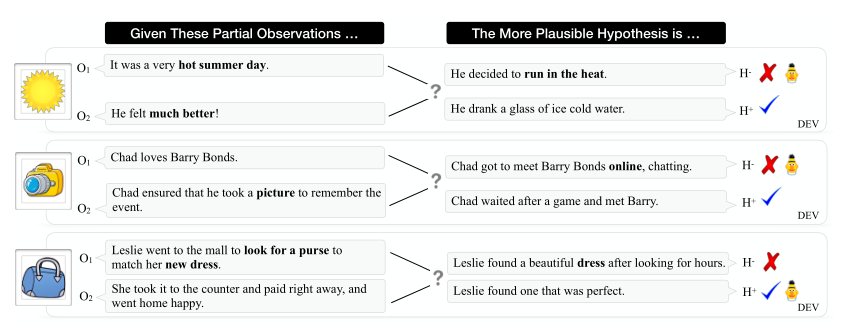
给定一对观测和一对解释性假设,αNLI的任务是选出两个假设中更有可能的那个。
在概率框架下模型的目标函数为:
\]
根据贝叶斯法则,以观测 \(O_{1}\) 为先验条件,可以重写上述公式:
\begin{aligned}
P\left(h^{i} \mid O_{1}, O_{2}\right) = \frac{P\left(O_{2}, O_{1}, h^{i}\right)}{P\left(O_{1} , O_{2}\right)} \\
=\frac{P\left(O_{2}\mid h^{i}, O_{1}\right)P\left(h^{i},O_{1}\right)}{P\left(O_{2}, O_{1}\right)} \\
=\frac{P\left(O_{2}\mid h^{i}, O_{1}\right)P\left(h^{i} \mid O_{1}\right)}{P\left(O_{2}\mid O_{1}\right)}
\end{aligned}
\end{equation}
\]
因为 \(P\left(O_{2}\mid O_{1}\right)\) 是定值,所求又是优化问题,所以可以仅考虑左侧的目标函数与右侧乘式的相关关系即可:
\]
根据上式,建立如下若干独立性假设,为αNLI任务构建一套概率模型:

- \(H_{i}\) 与 \(O_{1},O_{2}\)都无关时(模型没用到观测值)
\]
\(H_{i}\) 仅与 \(O_{1},O_{2}\)其中一个有关(模型用到了一个观测值)
线性链模型 —— \(H_{i}\) 与 \(O_{1},O_{2}\)都直接相关,但 \(O_{1} \perp O_{2}\) (模型使用两个观测值,但独立地考虑了每个观测值对假设的影响),
\]
- 全连接(模型使用两个观测值,结合两个观测值的信息选择合理的假设),目标函数为:
\]
在论文的实验中,将不同的独立性假设文本输入BERT进行编码。对于前两个概率模型,可以通过简单地将模型的输入限制为相关变量来加强独立性。另一方面,相关线性链模型将所有三个变量 \(O_{1},O_{2},H\) 都作为输入,通过限制模型的形式以加强条件独立性。具体来说,学习一个具有二分类功能的分类器:
\]
其中,\(\phi\) 和 \(\phi^{\prime}\) 为产生标量值的神经网络模型。
αNLG
给定 \(O_{1},O_{2},h^{+}\) 为一组的的训练数据,αNLG的任务就是最大化 \(O_{1},O_{2},h^{+}\) 对应的文本句在生成模型中的生成概率。同时,还可以在给定两个观测的基础上再添加背景知识 \(\text{K}\) 作为条件,模型的损失函数构造如下:
\]
其中,\(O_{1}=\left\{w_{1}^{o 1} \ldots w_{m}^{o 1}\right\}\) ,\(O_{2}=\left\{w_{1}^{o 2} \ldots w_{n}^{o 2}\right\}\),\(h^{+}=\left\{w_{1}^{h} \ldots w_{l}^{h}\right\}\),它们都由其自然语言文本对应的token组成。 \(w_{<i}^{h}\) 代表当前位置的前 \(i\) 个token,\(w_{i}^{h}\) 为当前位置 \(i\) 处的token。模型的训练目标就是最大化句子的生成概率 \(P\),也即最小化上述公式的损失 \(L\)。
实验结果
αNLI
αNLI任务被构造成了一个二分类问题。
Baseline
- SVM —— 利用Glove词嵌入,考虑词长度、词的重叠和情感特征等对两个假设选项进行选择。(50.6%)
- BOW —— 将两个观察和一个解释性假设文本串接在一起,利用Glove为串接起来的文本构建句子嵌入,再通过一个全连接网络为包含每个不同的解释性假设选项的句子的嵌入打分。(50.5%)
- Bi-LSTM + max-pooling —— 用Bi-LSTM编码句子,使用经过最大池化后的句子嵌入进行打分。(50.8%)
可以看到,传统分类器 + 上下文无关的单词嵌入的方式对解决这个二分类问题看上去几乎毫无作用(因为随机二选一都有一般的概率选对)。
实验模型
采用预训练模型GPT和BERT编码观测和解释性假设。
- 对于GPT,将观测 \(O_{1}\) 和解释性假设 \(H\) 串接在一起,然后使用 [SEP] 将其与观测 \(O_{2}\) 分隔开,以[START] 和 [SEP] 结尾。
- 对于BERT,根据不同独立性假设。有如下五种输入的构造方式:

评估
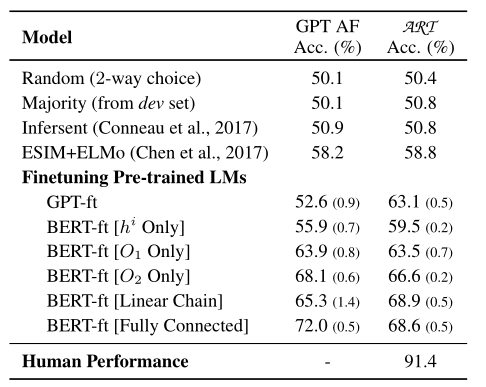
最后一列代表模型在论文提出的 \(\text{ART}\) 数据集上的表现,和前四个baseline相比,基于GPT和BERT构造的分类模型在数据集上的表现明显提高了很多,最好的BERT-ft[Linear Chain]比最佳baseline提升了10.1个百分点,达到了68.9。但是和人类的表现相比,这样的结果还是非常差的。因此,在溯因推理方面的研究还有很多工作要做。
αNLG
实验模型
\(O_{1}-O_{2}-\text{Only}\) —— 以组成两个观测值 \(O_{1}\) 和 \(O_{2}\) 的token为起始训练GPT2。
使用COMET生成ATOMIC格式(如果-那么)的知识 —— 包含常识知识的图,是一个以推理“如果-那么”的知识为主的知识库,它以事件作为节点,下列九大关系作为边:
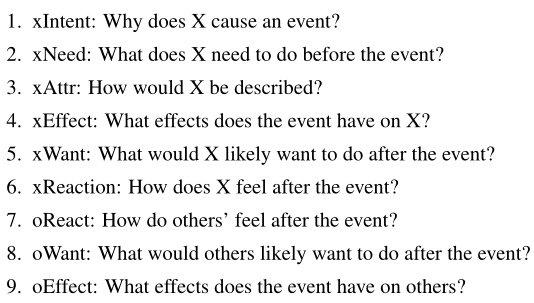
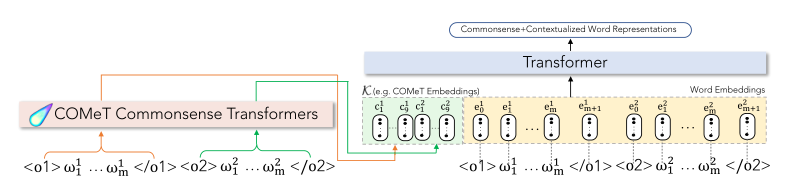
ATOMIC是对\(\text{ART}\) 数据集中的叙事上下文进行推理所需的背景常识的来源。COMET是基于ATOMIC训练的专门实现常识知识图自动构建的Transformer,这里借助COMET生成基于事件的常识推理知识,然后再GPT2中集成了COMET生成的信息用于αNLG任务。集成方式分两种:

- COMeT-Txt+GPT-2(作为文本短语的方式集成)
在单词嵌入层嵌入输入标记之后,我们在通过Transformer架构的层之前,向串接的观察序列添加18个(对应于每个观察的九个关系)自然语言文本,由GPT2进行编码。
- COMeT-Emb+GPT2(作为嵌入的方式集成)
和上面那种方式一样,不过在观察序列前添加的是18个COMeT Embedding,这允许模型在处理COMeT嵌入时学习每个token的表示——有效地将背景常识知识集成到语言模型中。
评估
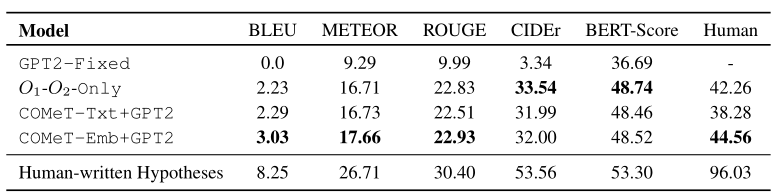
- 自动评估 —— BLEU、METEOR、ROUGE、CIDEr、BERT-Score
- 人工评估 —— 向众包人员展示成对的观察结果和一个生成的假设,要求他们标注该假设是否解释了给定的观察结果。最后一栏为对应的评估分数。人工编写的假设在96%的情况下是正确的,而我们最好的生成模型,即使有背景常识知识的增强,也只能达到45%——这表明αNLG生成任务对当前最优越的文本生成器来说尤其具有挑战性。
生成实例

结论
文章提出了第一项研究,调查基于语言的溯因推理的可行性。概念化并引入溯因自然语言推理(αNLI)——一个关注叙事语境中溯因推理的新任务。该任务被表述为一个选择题回答问题。文章还介绍了溯因自然语言生成(αNLG)——一种新的任务,需要机器为给定的观察结果生成可信的假设。为了支持这些任务,创建并引入了一个新的挑战数据集ART,它由20k个常识性叙述和200k多个解释性假设组成。在实验中,基于最先进的NLI和语言模型建立了这一新任务的Baseline,其准确率为68.9%,与人类性能(91.4%)有相当大的差距。αNLG任务要困难得多——虽然人类可以写出96%的有效解释,但是当前表现最好模型只能达到45%。文章的分析让我们对深度预训练语言模型无法执行的推理类型有了新的见解——尽管预训练模型在NLI蕴涵的密切相关但不同的任务中表现出色,但是在应对基于 \(\text{ART}\) 数据集提出的溯因推理和溯因生成任务时,表现却差强人意,这为未来的研究指出了有趣的途径。作者希望ART将成为未来基于语言的溯因推理研究的一个具有挑战性的基准,并且αNLI和αNLG任务将鼓励在人工智能系统中实现复杂推理能力的表征学习。
Abductive Commonsense Reasoning —— 溯因推理的更多相关文章
- Data visualization 课程 笔记3
Learn how humans work to create a more effective computer interface 三种reasoning的方式 Deductive Reason ...
- PGM学习之四 Factor,Reasoning
通过上一篇文章的介绍,我们已经基本了解了:Factor是组成PGM模型的基本要素:Factor之间的运算和推理是构建高维复杂PGM模型的基础.那么接下来,我们将重点理解,Factor之间的推理(Rea ...
- 美团:WSDM Cup 2019自然语言推理任务获奖解题思路
WSDM(Web Search and Data Mining,读音为Wisdom)是业界公认的高质量学术会议,注重前沿技术在工业界的落地应用,与SIGIR一起被称为信息检索领域的Top2. 刚刚在墨 ...
- [书目20160612]思考软件,创新设计——A段架构师的思考技术
高焕堂:在校时期主修统计学和信息管理,将近40年软件开发生涯.工作于亚洲和欧美各地区,专精于商业策略思考和系统架构设计.近年来,热衷于<it+设计>教育顾问和产品开发. 第1章 商业思维 ...
- [z] 人工智能和图形学、图像处理方面的各种会议的评级
转载自:『http://www.cvchina.info/2010/08/31/conference-ranking-byar/』 澳大利亚政府和澳大利亚研究理事会做的,有一定考价值. 会议名称 会议 ...
- SCI&EI 英文PAPER投稿经验【转】
英文投稿的一点经验[转载] From: http://chl033.woku.com/article/2893317.html 1. 首先一定要注意杂志的发表范围, 超出范围的千万别投,要不就是浪费时 ...
- <Natural Language Processing with Python>学习笔记一
Spoken input (top left) is analyzed, words are recognized, sentences are parsed and interpreted in c ...
- Raptor入门与安装
作为计算机导论的一部分,Raptor的图形化界面可以让编程的初学者更加容易深入理解算法,可以作为一个简单入门的学习工具. 1.Raptor是什么? Raptor( the Rapid Algorith ...
- FZU软工第五次作业-词组频率分析
目录 00.前言: 01.分工: 02.PSP表格: 03.解题思路描述与设计实现说明: 解题思路简述: 关键代码 04.附加题设计与展示: 设计的创意独到之处 实现思路 实现成果展示 05.关键代码 ...
随机推荐
- Flutter学习一之环境搭建
MacOS上搭建Flutter开发环境 1.flutter官网下载最新的安装包,https://flutter.io/sdk-archive/#macos 2.解压安装包到你想安装的目录.直接解压或者 ...
- python中闭包详解
谈谈自己的理解:python中闭包,闭包的实质 闭包这个概念好难理解,身边朋友们好多都稀里糊涂的,稀里糊涂的林老冷希望写下这篇文章能够对稀里糊涂的伙伴们有一些帮助~ 请大家跟我理解一下,如果在一个 ...
- 靠这些秋招秘笈,齐姐的学妹今年已经拿到了 8 个offer!
小齐说: 现在秋招进行时,正在找工作的小伙伴进度都怎么样了呀? 今天这篇文章是我武大的学妹今年秋招的经验分享,庆妹去年才决定转行,现在已手握 N+ 个 offer - 这篇文章干货满满,庆妹对每一块面 ...
- django 的跨域配置
1.跨域原理 #1. 首先浏览器安全策略限制js ajax跨域访问服务器 #2. 如果服务器返回的头部信息中有当前域: // 允许 http://localhost:8080 这个网站打开的页面中的j ...
- 中秋礼物!开源即时通信GGTalk安卓版全新源码!
经过连续两个多月的努力(开发.调试.测试.改bug),我们终于赶在中秋国庆之前能把全新的GGTalk Android版本献给大家. 4年之前我们就推出了GGTalk Android的第一个版本,但是功 ...
- IPV6介绍已经IPV6改造基本步骤
IPV6介绍 地址资源无限多 通常见到的124.33.24.116这种形式的是ipv4版本的地址,这种地址由32位二进制数表示. ipv6是一种新的ip地址的表示方式形如fc80::2367:7cff ...
- Webstorm破解版安装教程
Webstorm破解版: 安装包链接见:https://pan.baidu.com/s/1XJqRtM9C4M8AmH50S9dVDQ 提取码: dah3 内附安装教程, 原创文章,转载请先联系作者
- Focal loss论文解析
Focal loss是目标检测领域的一篇十分经典的论文,它通过改造损失函数提升了一阶段目标检测的性能,背后关于类别不平衡的学习的思想值得我们深入地去探索和学习.正负样本失衡不仅仅在目标检测算法中会出现 ...
- 015 01 Android 零基础入门 01 Java基础语法 02 Java常量与变量 09 Unicode编码
015 01 Android 零基础入门 01 Java基础语法 02 Java常量与变量 09 Unicode编码 本文知识点:Unicode编码以及字符如何表示? ASCII码是美国提出的标准信息 ...
- xor 和 or 有什么区别
参考:https://zhidao.baidu.com/question/67532331.html 1.定义区别: ①OR是或运算,A OR B的结果:当A.B中只要有一个或者两个都为1时,结果为1 ...