Python爬虫教程-26-Selenium + PhantomJS
Python爬虫教程-26-Selenium + PhantomJS
- 动态前端页面 :
- JavaScript:
JavaScript一种直译式脚本语言,是一种动态类型、弱类型、基于原型的语言,内置支持类型。它的解释器被称为JavaScript引擎,为浏览器的一部分,广泛用于客户端的脚本语言,最早是在HTML(标准通用标记语言下的一个应用)网页上使用,用来给HTML网页增加动态功能 - jQuery:
jQuery是一个快速、简洁的JavaScript框架,是继Prototype之后又一个优秀的JavaScript代码库(或JavaScript框架)。jQuery设计的宗旨是“write Less,Do More”,即倡导写更少的代码,做更多的事情。它封装JavaScript常用的功能代码,提供一种简便的JavaScript设计模式,优化HTML文档操作、事件处理、动画设计和Ajax交互 - ajax:
Ajax 即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),是指一种创建交互式网页应用的网页开发技术。
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。
通过在后台与服务器进行 - DHTML:
DHTML是Dynamic HTML的简称,就是动态的html(标准通用标记语言下的一个应用),是相对传统的静态的html而言的一种制作网页的概念。所谓动态HTML(Dynamic HTML,简称DHTML),其实并不是一门新的语言,它只是HTML、CSS和客户端脚本的一种集成,即一个页面中包括html+css+javascript(或其它客户端脚本),其中css和客户端脚本是直接在页面上写而不是链接上相关文件。DHTML不是一种技术、标准或规范,只是一种将目前已有的网页技术、语言标准整合运用,制作出能在下载后仍然能实时变换页面元素效果的网页设计概念
- JavaScript:
Python 采集动态数据
- 从 JavaScript 代码入手采集
- Python 第三方库运行 JavaScript,直接采集你在浏览器看到的页面
Selenium + PhantomJS
- Selenium:web 自动化测试工具
- Selenium 官方文档:https://www.seleniumhq.org/docs/
- Selenium 的功能:
- 1.自动加载页面
- 2.获取数据
- 3.截屏
- PhantomJS:基于 Webkit 的无界面浏览器
- 由 Selenium 操作 PhantomJS
Selenium 的安装
- 如果使用的是 Anaconda:
- 进入当前环境:(我的环境名为learn,如果只有一个base环境,忽略此步)
activate learn
- 安装 selenium
conda install selenium
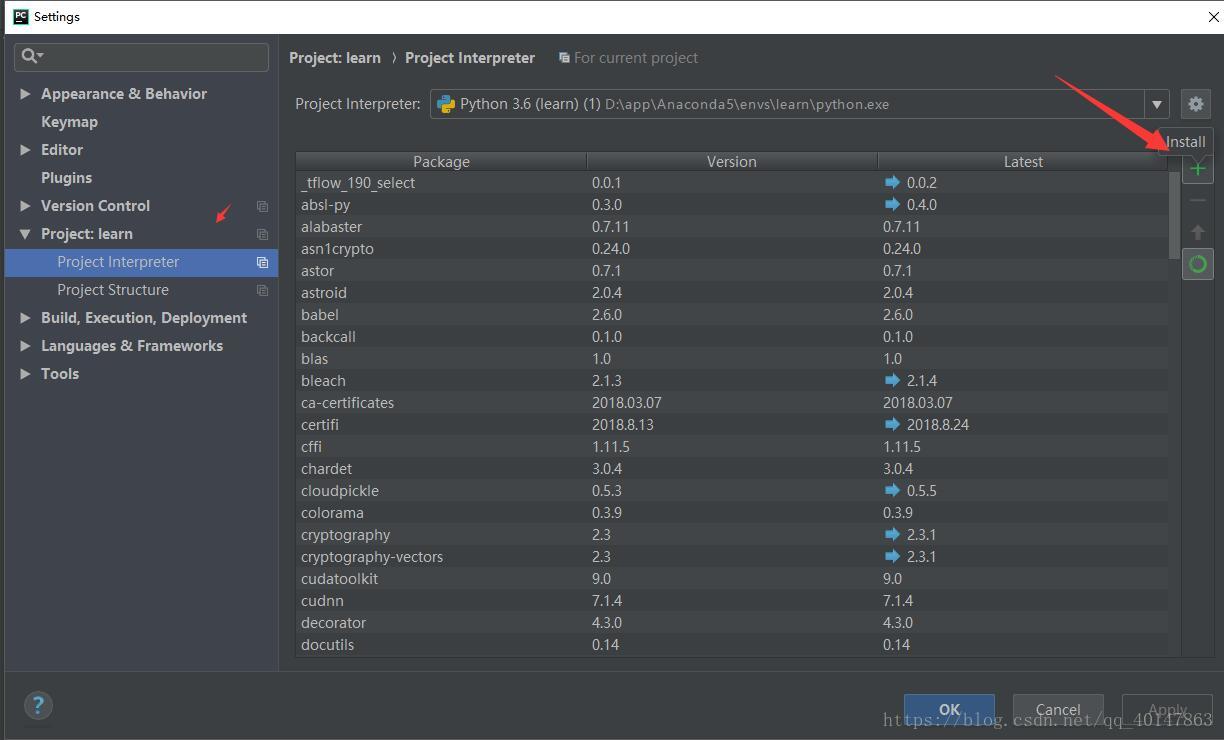
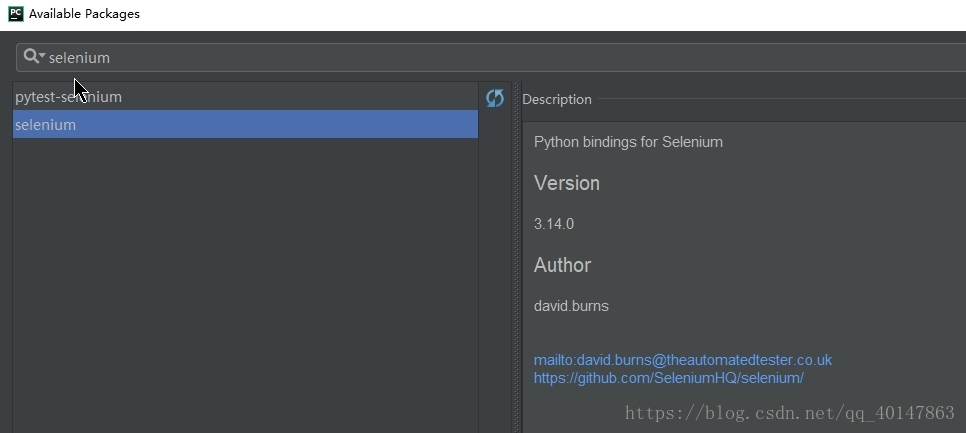
- 当然也可以直接在 Pycharm 进行安装
- 【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】 >【selenium】>【install】
- 具体操作截图:
PhantomJS 的安装
- 下载地址:http://phantomjs.org/download.html
- 根据自己操作系统版本下载,解压即可用
Selenium 的使用
- Selenium 库有一个 WebDriver 的 API
- WebDriver 可以跟页面上的元素进行各种交互,用它可以来进行爬取
- 注意:使用 PhantomJS 时自动按照环境变量查找相应浏览器,如果没有配置环境变量就将路径作为参数
- 案例代码28dhtml.py文件:https://xpwi.github.io/py/py爬虫/py28dhtml.py
# Selenium 的使用
# 通过 WebDriver 操作百度进行查找
from selenium import webdriver
import time
# 通过 Keys 模拟键盘
# 也就是放入需要输入的东西,就不用键盘输入了
from selenium.webdriver.common.keys import Keys
# 操作哪个浏览器就对哪个浏览器创建一个实例,这里是 PhantomJS
# 自动按照环境变量查找相应浏览器,如果没有配置环境变量就将路径作为参数
driver = webdriver.PhantomJS(executable_path=r"D:\app\phantomjs-2.1.1-windows\bin\phantomjs.exe")
driver.get("http://www.baidu.com")
# 通过函数查找 title 标签
print("Title: {0}".format(driver.title))
运行结果
注意:如果没有配置环境变量就将自己的路径作为参数
红字不是出错,打印 title 成功才算使用成功

更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-26-Selenium + PhantomJS的更多相关文章
- [Python爬虫] 之一 : Selenium+Phantomjs动态获取网站数据信息
本人刚才开始学习爬虫,从网上查询资料,写了一个利用Selenium+Phantomjs动态获取网站数据信息的例子,当然首先要安装Selenium+Phantomjs,具体的看 http://www.c ...
- [Python爬虫] 之八:Selenium +phantomjs抓取微博数据
基本思路:在登录状态下,打开首页,利用高级搜索框输入需要查询的条件,点击搜索链接进行搜索.如果数据有多页,每页数据是20条件,读取页数 然后循环页数,对每页数据进行抓取数据. 在实践过程中发现一个问题 ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- Python爬虫教程-28-Selenium 操纵 Chrome
我觉得本篇是很有意思的,闲着没事来看看! Python爬虫教程-28-Selenium 操纵 Chrome PhantomJS 幽灵浏览器,无界面浏览器,不渲染页面.Selenium + Phanto ...
- python爬虫动态html selenium.webdriver
python爬虫:利用selenium.webdriver获取渲染之后的页面代码! 1 首先要下载浏览器驱动: 常用的是chromedriver 和phantomjs chromedirver下载地址 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
随机推荐
- 一篇在一个Excel表中创建多个sheet的代码
package projectUtil; import org.apache.commons.lang3.StringUtils; import org.apache.poi.hssf.usermod ...
- ngx_echo_module
https://github.com/openresty/echo-nginx-module echo $echo_request_body
- Android中调用高德导航(组件)
btn_.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View view) { //调用 ...
- SuperMap iClient for JavaScript 之关联查询
人们常说,计划赶不上变化.同样的,在项目中,使用的数据也是在不断变化的,尤其是属性信息的改变.就比如说,地图上的地物,它的空间信息在比较长的时间内,都不会发生变化,他的属性信息在初期不完整或者与后来的 ...
- Github提交PullRequest
Github提交PullRequest工作流程: 以Kubernetes为例 1. Fork Kubernetes到自己的Github目录 访问:https://github.com/kubern ...
- Robot Framework自动化测试四(分层思想)
谈到Robot Framework 分层的思想,就不得不提“关键字驱动”. 关键字驱动: 通过调用的关键字不同,从而引起测试结果的不同. 在上一节的selenium API 中所介绍的方法其实就是关 ...
- Python文件的I/o
文章内容参考了教程:http://www.runoob.com/python/python-basic-syntax.html#commentform Python 文件I/O 本章只讲述所有基本的的 ...
- 关于javascript中时间格式和时间戳的转换
当前时间获取的各种函数: var myDate = new Date();myDate.getYear(); //获取当前年份(2位),已经不推荐使用myDate.getFullYear ...
- Linux中让普通用户拥有超级用户的权限
问题 假设用户名为:ali 如果用户名没有超级用户权限,当输入 sudo + 命令 时, 系统提示: ali is not in the sudoers file. This incident wi ...
- hihocoder #1529 : 不上升序列
Description 给定一个长度为 n 的非负整数序列 a[1..n]. 你每次可以花费 1 的代价给某个 a[i] 加1或者减1. 求最少需要多少代价能将这个序列变成一个不上升序列. Solut ...