Python爬虫教程-14-爬虫使用filecookiejar保存cookie文件(人人网)
Python爬虫教程-14-爬虫使用filecookiejar保存cookie文件(人人网)
- 上一篇介绍了利用CookieJar访问人人网,本篇将使用filecookiejar将cookie以文件形式保存
- 自动使用cookie登录,使用步骤:
- 1.打开登录页面后,通过用户名密码登录
- 2.自动提取反馈回来的cookie
- 3.利用提取的cookie登录个人信息页面
- 创建cookiejar实例
- 生成cookie的管理器
- 创建http请求管理器
- 创建https请求的管理器
- 创建请求管理器
- 通过输入用户名和密码,获取cookie
- 代码:
# 创建cookiejar的实例
cookie = cookiejar.CookieJar()
# 常见cookie的管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
# 创建http请求的管理器
http_handler = request.HTTPHandler()
# 生成https管理器
https_handler = request.HTTPSHandler()
# 创建请求管理器
opener = request.build_opener(http_handler,https_handler,cookie_handler)
创建handle后,使用opener打开,打开后相应的业务由相应的handle处理
cookie作为一个变量打印出来
- 案例v14cookie4文件:https://xpwi.github.io/py/py爬虫/py14cookie4.py
# 使用cookiejar
# cookie作为一个变量打印出来
from urllib import request,parse
from http import cookiejar
# 创建cookiejar的实例
cookie = cookiejar.CookieJar()
# 常见cookie的管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
# 创建http请求的管理器
http_handler = request.HTTPHandler()
# 生成https管理器
https_handler = request.HTTPSHandler()
# 创建请求管理器
opener = request.build_opener(http_handler,https_handler,cookie_handler)
def login():
# 负责首次登录,输入用户名和密码,用来获取cookie
url = 'http://www.renren.com/PLogin.do'
id = input('请输入用户名:')
pw = input('请输入密码:')
data = {
# 参数使用正确的用户名密码
"email": id,
"password": pw
}
# 把数据进行编码
data = parse.urlencode(data)
# 创建一个请求对象
req = request.Request(url,data=data.encode('utf-8'))
# 使用opener发起请求
rsp = opener.open(req)
# 以上代码就可以进一步获取cookie了,cookie在哪呢?cookie在opener里
def getHomePage():
# 地址是用在浏览器登录后的个人信息页地址
url = "http://www.renren.com/967487029/profile"
# 如果已经执行login函数,则opener自动已经包含cookie
rsp = opener.open(url)
html = rsp.read().decode()
with open("rsp1.html", "w", encoding="utf-8")as f:
# 将爬取的页面
print(html)
f.write(html)
if __name__ == '__main__':
login()
# 执行完login之后,会得到授权之后的cookie,下一步打印出来
print(cookie)
for item in cookie:
print(type(item))
print(item)
for i in dir(item):
print(i)
我们使用print(i)打印出来了cookie的所有属性
下面介绍常用的属性
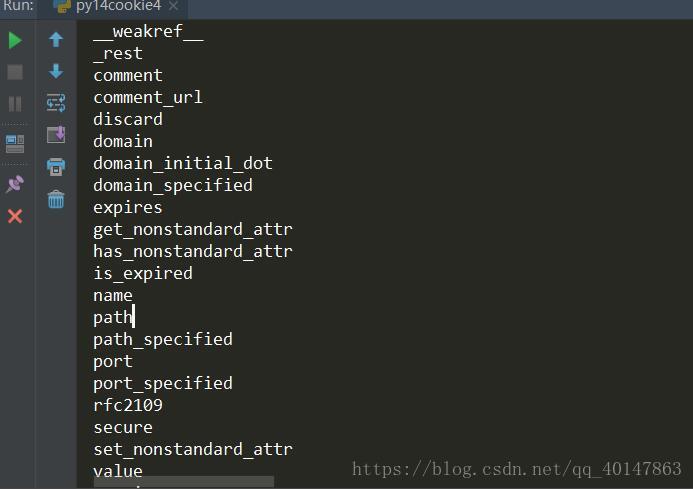
cookie的属性
- name:名称
- value:值
- domain:可以访问此cookie的域名
- path:可以访问此cookie的页面路径
- expires:过期时间
- size:大小
- http:字段
cookie的值虽然可以自己修改,但是修改后就会导致和服务器端数据不一致,而使cookie无效,最终登录失败
cookie的保存-FileCookieJar
- 将cookie以文件形式保存
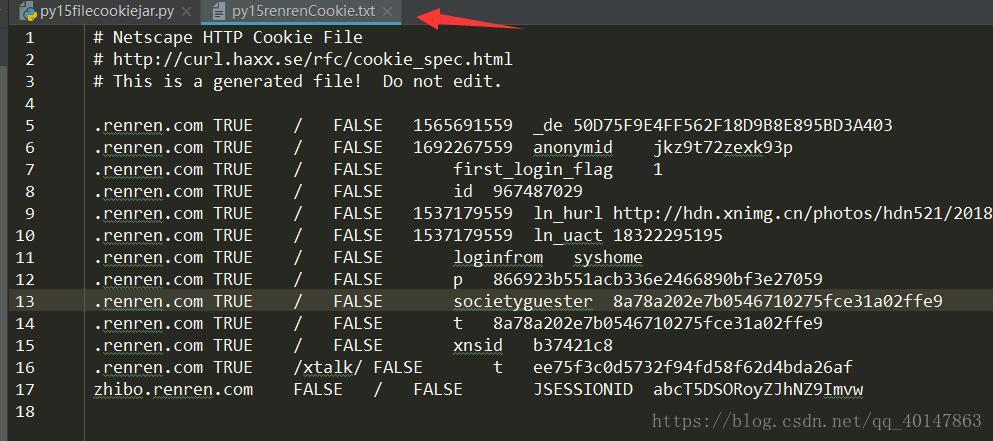
- 案例v15filecookiejar文件:https://xpwi.github.io/py/py爬虫/py15filecookiejar.py
# 使用filecookiejar
from urllib import request,parse
from http import cookiejar
# 创建cookiejar的实例
filename = "py15renrenCookie.txt"
cookie = cookiejar.MozillaCookieJar(filename)
# 常见cookie的管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
# 创建http请求的管理器
http_handler = request.HTTPHandler()
# 生成https管理器
https_handler = request.HTTPSHandler()
# 创建请求管理器
opener = request.build_opener(http_handler,https_handler,cookie_handler)
def login():
# 负责首次登录,输入用户名和密码,用来获取cookie
url = 'http://www.renren.com/PLogin.do'
id = input('请输入用户名:')
pw = input('请输入密码:')
data = {
# 参数使用正确的用户名密码
"email": id,
"password": pw
}
# 把数据进行编码
data = parse.urlencode(data)
# 创建一个请求对象
req = request.Request(url,data=data.encode('utf-8'))
# 使用opener发起请求
rsp = opener.open(req)
'''
保存cookie到文件
两个参数:
ignore_discard:表示及时cookie将要被丢弃,是否保存下来
ignore_expires:表示如果该文件中cookie已经过期,是否保存下来
'''
cookie.save(ignore_discard=True, ignore_expires=True)
if __name__ == '__main__':
login()
运行结果
本篇使用filecookiejar将cookie以文件形式保存
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-14-爬虫使用filecookiejar保存cookie文件(人人网)的更多相关文章
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- Python 基础教程 —— 网络爬虫入门篇
前言 Python 是一种解释型.面向对象.动态数据类型的高级程序设计语言,它由 Guido van Rossum 于 1989 年底发明,第一个公开发行版发行于 1991 年.自面世以后,Pytho ...
- Python 简明教程 --- 14,Python 数据结构进阶
微信公众号:码农充电站pro 个人主页:https://codeshellme.github.io 如果你发现特殊情况太多,那很可能是用错算法了. -- Carig Zerouni 目录 前几节我们介 ...
- Python爬虫教程-05-python爬虫实现百度翻译
使用python爬虫实现百度翻译功能 python爬虫实现百度翻译: python解释器[模拟浏览器],发送[post请求],传入待[翻译的内容]作为参数,获取[百度翻译的结果] 通过开发者工具,获取 ...
- 大爽Python入门教程 1-4 习题
大爽Python入门公开课教案 点击查看教程总目录 1 [思考]方向变换 小明同学站在平原上,面朝北方,向左转51次之后(每次只转90度), 小明面朝哪里?小明转过了多少圈? (360度为一圈,圈数向 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
随机推荐
- 基础篇:6.7)形位公差-检测方法Measurement
本章目的:了解行为公差的检测方法,简单评估公司和制作方的检测能力. 1.形位公差检测规定 形状和位置公差检测规定GB/T 1958 -2004 2.形位公差的种类 3.形位公差的测量仪器 人工测量仪器 ...
- Go语言内置类型和函数
内置类型 内置函数 Go 语言拥有一些不需要进行导入操作就可以使用的内置函数.它们有时可以针对不同的类型进行操作,例如:len.cap 和 append,或必须用于系统级的操作,例如:panic.因此 ...
- 2017-2018 ACM-ICPC, Asia Daejeon Regional Contest
题目传送门 只打了三个小时. A. Broadcast Stations B. Connect3 补题:zz 题解:因为格子是4*4的,而且每次落子的位置最多是只有四个,再加上剪枝,情况不会很多,直接 ...
- 转 zabbix 用户建立和中文化
1. 1 登陆和配置用户 简介 本章你会学习如何登陆Zabbix,以及在Zabbix内建立一个系统用户. 登陆 这是Zabbix的“欢迎”界面.输入用户名 Admin 以及密码 zabbix 以作 ...
- ftp发送文件包括中文名
public void sendwordToftp() { try { Json json = new Json(); String file ...
- elasticsearch安装及与springboot2.x整合
关于elasticsearch是什么.elasticsearch的原理及elasticsearch能干什么,就不多说了,主要记录下自己的一个使用过程. 1.安装 elasticsearch是用java ...
- Kafka 0.9 新特性
Kafka发布0.9了,这一重磅消息,让小伙伴们激动不已,来看看这个版本有哪些值得关注的地方吧! 一.安全特性 在0.9之前,Kafka安全方面的考虑几乎为0,在进行外网传输时,只好通过Linux的防 ...
- datepicker97切换年月日再连续点击下拉中日期的bug出现问题
解决办法: function wdateOption(fmt){ if(fmt===undefined){fmt="yyyy-MM-dd"} return{ dateFmt:fmt ...
- c++ 常用的遍历,删除,分割等等文件处理函数代码实现
原文作者:aircraft 原文链接:https://www.cnblogs.com/DOMLX/p/9622851.html 删除文件目录函数: void myDeleteDirectory(CSt ...
- Unity游戏接入Steam成就
在接入Steam成就,其实有些地方是有坑点的,而且steam官网给的是c++代码的接入教程.如果是老鸟的话,接入还并不是很难. 但是对于新手其实还是比较痛苦的,网上这方面的资料很少.这里我给总结下,u ...