mysql单列去重复group by分组取每组前几条记录加order by排序
mysql分组取每组前几条记录(排名) 附group by与order by的研究,需要的朋友可以参考下
--按某一字段分组取最大(小)值所在行的数据
复制代码代码如下:
/*
数据如下:
name val memo
a 2 a2(a的第二个值)
a 1 a1--a的第一个值
a 3 a3:a的第三个值
b 1 b1--b的第一个值
b 3 b3:b的第三个值
b 2 b2b2b2b2
b 4 b4b4
b 5 b5b5b5b5b5
*/
--创建表并插入数据:
复制代码代码如下:
create table tb(name varchar(10),val int,memo varchar(20))
insert into tb values('a', 2, 'a2(a的第二个值)')
insert into tb values('a', 1, 'a1--a的第一个值')
insert into tb values('a', 3, 'a3:a的第三个值')
insert into tb values('b', 1, 'b1--b的第一个值')
insert into tb values('b', 3, 'b3:b的第三个值')
insert into tb values('b', 2, 'b2b2b2b2')
insert into tb values('b', 4, 'b4b4')
insert into tb values('b', 5, 'b5b5b5b5b5')
go
--一、按name分组取val最大的值所在行的数据。
复制代码代码如下:
--方法1:select a.* from tb a where val = (select max(val) from tb where name = a.name) order by a.name
--方法2:
select a.* from tb a where not exists(select 1 from tb where name = a.name and val > a.val)
--方法3:
select a.* from tb a,(select name,max(val) val from tb group by name) b where a.name = b.name and a.val = b.val order by a.name
--方法4:
select a.* from tb a inner join (select name , max(val) val from tb group by name) b on a.name = b.name and a.val = b.val order by a.name
--方法5
select a.* from tb a where 1 > (select count(*) from tb where name = a.name and val > a.val ) order by a.name
/*
name val memo
---------- ----------- --------------------
a 3 a3:a的第三个值
b 5 b5b5b5b5b5
*/
本人推荐使用1,3,4,结果显示1,3,4效率相同,2,5效率差些,不过我3,4效率相同毫无疑问,1就不一样了,想不搞了。
--二、按name分组取val最小的值所在行的数据。
复制代码代码如下:
--方法1:select a.* from tb a where val = (select min(val) from tb where name = a.name) order by a.name
--方法2:
select a.* from tb a where not exists(select 1 from tb where name = a.name and val < a.val)
--方法3:
select a.* from tb a,(select name,min(val) val from tb group by name) b where a.name = b.name and a.val = b.val order by a.name
--方法4:
select a.* from tb a inner join (select name , min(val) val from tb group by name) b on a.name = b.name and a.val = b.val order by a.name
--方法5
select a.* from tb a where 1 > (select count(*) from tb where name = a.name and val < a.val) order by a.name
/*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
b 1 b1--b的第一个值
*/
--三、按name分组取第一次出现的行所在的数据。
复制代码代码如下:
select a.* from tb a where val = (select top 1 val from tb where name = a.name) order by a.name
/*
name val memo
---------- ----------- --------------------
a 2 a2(a的第二个值)
b 1 b1--b的第一个值
*/
--四、按name分组随机取一条数据。
复制代码代码如下:
select a.* from tb a where val = (select top 1 val from tb where name = a.name order by newid()) order by a.name/*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
b 5 b5b5b5b5b5
*/
--五、按name分组取最小的两个(N个)val
复制代码代码如下:
select a.* from tb a where 2 > (select count(*) from tb where name = a.name and val < a.val ) order by a.name,a.valselect a.* from tb a where val in (select top 2 val from tb where name=a.name order by val) order by a.name,a.val
select a.* from tb a where exists (select count(*) from tb where name = a.name and val < a.val having Count(*) < 2) order by a.name
/*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
a 2 a2(a的第二个值)
b 1 b1--b的第一个值
b 2 b2b2b2b2
*/
--六、按name分组取最大的两个(N个)val
复制代码代码如下:
select a.* from tb a where 2 > (select count(*) from tb where name = a.name and val > a.val ) order by a.name,a.val
select a.* from tb a where val in (select top 2 val from tb where name=a.name order by val desc) order by a.name,a.val
select a.* from tb a where exists (select count(*) from tb where name = a.name and val > a.val having Count(*) < 2) order by a.name
/*
name val memo
---------- ----------- --------------------
a 2 a2(a的第二个值)
a 3 a3:a的第三个值
b 4 b4b4
b 5 b5b5b5b5b5
*/
--七,假如整行数据有重复,所有的列都相同(例如下表中的第5,6两行数据完全相同)。
按name分组取最大的两个(N个)val
复制代码代码如下:
/*
数据如下:
name val memo
a 2 a2(a的第二个值)
a 1 a1--a的第一个值
a 1 a1--a的第一个值
a 3 a3:a的第三个值
a 3 a3:a的第三个值
b 1 b1--b的第一个值
b 3 b3:b的第三个值
b 2 b2b2b2b2
b 4 b4b4
b 5 b5b5b5b5b5
*/
附:mysql “group by ”与"order by"的研究
这两天让一个数据查询难了。主要是对group by 理解的不够深入。才出现这样的情况
这种需求,我想很多人都遇到过。下面是我模拟我的内容表

我现在需要取出每个分类中最新的内容
select * from test group by category_id order by `date`
结果如下

明显。这不是我想要的数据,原因是msyql已经的执行顺序是
引用
写的顺序:select ... from... where.... group by... having... order by..
执行顺序:from... where...group by... having.... select ... order by...
所以在order by拿到的结果里已经是分组的完的最后结果。
由from到where的结果如下的内容。
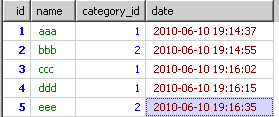
到group by时就得到了根据category_id分出来的多个小组


到了select的时候,只从上面的每个组里取第一条信息结果会如下

即使order by也只是从上面的结果里进行排序。并不是每个分类的最新信息。
回到我的目的上 --分类中最新的信息
根据上面的分析,group by到select时只取到分组里的第一条信息。有两个解决方法
1,where+group by(对小组进行排序)
2,从form返回的数据下手脚(即用子查询)
由where+group by的解决方法
对group by里的小组进行排序的函数我只查到group_concat()可以进行排序,但group_concat的作用是将小组里的字段里的值进行串联起来。
select group_concat(id order by `date` desc) from `test` group by category_id

再改进一下
select * from `test` where id in(select SUBSTRING_INDEX(group_concat(id order by `date` desc),',',1) from `test` group by category_id ) order by `date` desc

子查询解决方案
select * from (select * from `test` order by `date` desc) `temp` group by category_id order by `date` desc

mysql单列去重复group by分组取每组前几条记录加order by排序的更多相关文章
- mysql分组取每组前几条记录(排名)
1.创建表 create table tb( name varchar(10), val int, memo varchar(20) ); 2.插入数据 insert into tb values(' ...
- Mysql SQL分组取每组前几条记录
按name分组取最大的两个val: [比当前记录val大的条数]小于2条:即当前记录为为分组中的前两条 > (select count(*) from tb where name = a.nam ...
- mysql分组取每组前几条记录(排序)
首先来造一部分数据,表mygoods为商品表,cat_id为分类id,goods_id为商品id,status为商品当前的状态位(1:有效,0:无效). CREATE TABLE `mygoods` ...
- MYSQL 按某个字段分组,然后取每组前3条记录
先初始化一些数据,表名为 test ,字段及数据为: SQL执行结果为:每个 uid 都只有 3 条记录. SQL语句为: SELECT * FROM test main WHERE ...
- SQL分组取每组前一(或几)条记录(排名)
mysql分组取每组前几条记录(排名) 附group by与order by的研究 http://www.jb51.net/article/31590.htm --按某一字段分组取最大(小)值所在行的 ...
- MySQL 先按某字段分组,再取每组中前N条记录
按 gpcode每组 取每组 f4 最大的那条记录: 方法一: select * from calcgsdataflash a where gscode = 'LS_F' and ymd >= ...
- [mysql] 先按某字段分组再取每组中前N条记录
From: http://blog.chinaunix.net/uid-26729093-id-4294287.html 请参考:http://bbs.csdn.net/topics/33002126 ...
- MySQL 分组后取每组前N条数据
与oracle的 rownumber() over(partition by xxx order by xxx )语句类似,即:对表分组后排序 创建测试emp表 1 2 3 4 5 6 7 8 9 ...
- 记一次有意思的 SQL 实现 → 分组后取每组的第一条记录
开心一刻 今天,朋友气冲冲的走到我面前 朋友:我不是谈了个女朋友,谈了三个月嘛,昨天我偷看她手机,你猜她给我备注什么 我:备注什么? 朋友:舔狗 2 号! 我一听,气就上来了,说道:走,找她去,这婆娘 ...
随机推荐
- [转载]python property
@property 简单解释. http://python.jobbole.com/80955/
- UFLDL 教程三总结与答案
主成分分析(PCA)是一种能够极大提升无监督特征学习速度的数据降维算法.更重要的是,理解PCA算法,对实现白化算法有很大的帮助,很多算法都先用白化算法作预处理步骤.这里以处理自然图像为例作解释. 1. ...
- mysql 基础使用
mysql服务器本地root用户默认没有密码,使用 "mysql -u root -p" 即可登陆.linux本地用户可以以任意用户名登陆mysql,但是没有任何权限,没有意义.m ...
- ember.js路由无效的解决思路
进入今天的问题,就是route ember中就一个html,单页面程序(spa),所以页面的跳转,也可以叫做页面的路由,其实就是在这一个html中,不断的进行html的插入和删除了(个人理解) emb ...
- $.extend()、$.fn和$.fn.extend()
理解$.extend().$.fn和$.fn.extend() 原文链接:http://caibaojian.com/jquery-extend-and-jquery-fn-extend.ht ...
- STL string的构造函数
前几天在网上,一位网友问我几个问题如下: , 'A'); string S1 = "abcdefg"; , ); ); cout << "s0 = " ...
- $\mathscr{F}$类
$\mathscr{F}$类:在单位元盘$B(0,1)$中满足$$f(0)=0,f'(0)=1$$ 的双全纯函数的全体.
- Arcgis与CityEngine安装破解
Arcgis与CityEngine共存,实现同时破解 作为一个GIS背景的技术人员,以前安装了无数次的Arcgis DeskTop,到了新公司后,今天主管让我学习下CityEngine,学渣的我之前没 ...
- ******IT公司面试题汇总+优秀技术博客汇总
滴滴面试题:滴滴打车数据库如何拆分 前端时间去滴滴面试,有一道题目是这样的,滴滴每天有100万的订单,如果让你去设计数据库,你会怎么去设计? 当时我的想法是根据用户id的最后一位对某个特殊的值取%操作 ...
- gulp
npm install -g gulp // 全局安装gulp 是为了执行 gulp 任务npm install gulp --save-dev // 本地安装gulp 是为了调用 gulp 插件 - ...