python爬虫:爬取网站视频
python爬取百思不得姐网站视频:http://www.budejie.com/video/
新建一个py文件,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
#!/usr/bin/python# -*- coding: UTF-8 -*-import urllib,re,requestsimport sysreload(sys)sys.setdefaultencoding('utf-8')url_name = [] #url namedef get(): #获取源码 hd = {"User-Agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"} url = 'http://www.budejie.com/video/' html = requests.get(url,headers=hd).text url_content = re.compile(r'(<div class="j-r-list-c">.*?</div>.*?</div>)',re.S) #编译 url_contents = re.findall(url_content,html) #匹配 for i in url_contents: #匹配视频 url_reg = r'data-mp4="(.*?)"' #视频地址 url_items = re.findall(url_reg,i) #print url_items if url_items: #判断视频是否存在 name_reg = re.compile(r'<a href="/detail-.{8}?.html">(.*?)</a>',re.S) name_items = re.findall(name_reg,i) #print name_items[0] for i,k in zip(name_items,url_items): url_name.append([i,k]) print i,k for i in url_name: #i[1]=url i[0]=name urllib.urlretrieve(i[1],'video\\%s.mp4' % (i[0].decode('utf-8')))if __name__ == "__main__": get() |
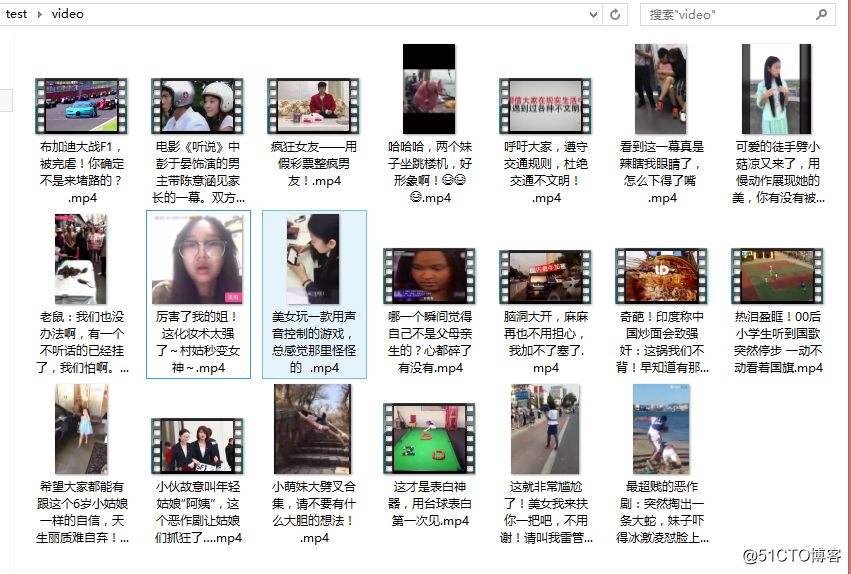
在 py 文件下新建一个 video 文件夹,执行后结果如下:
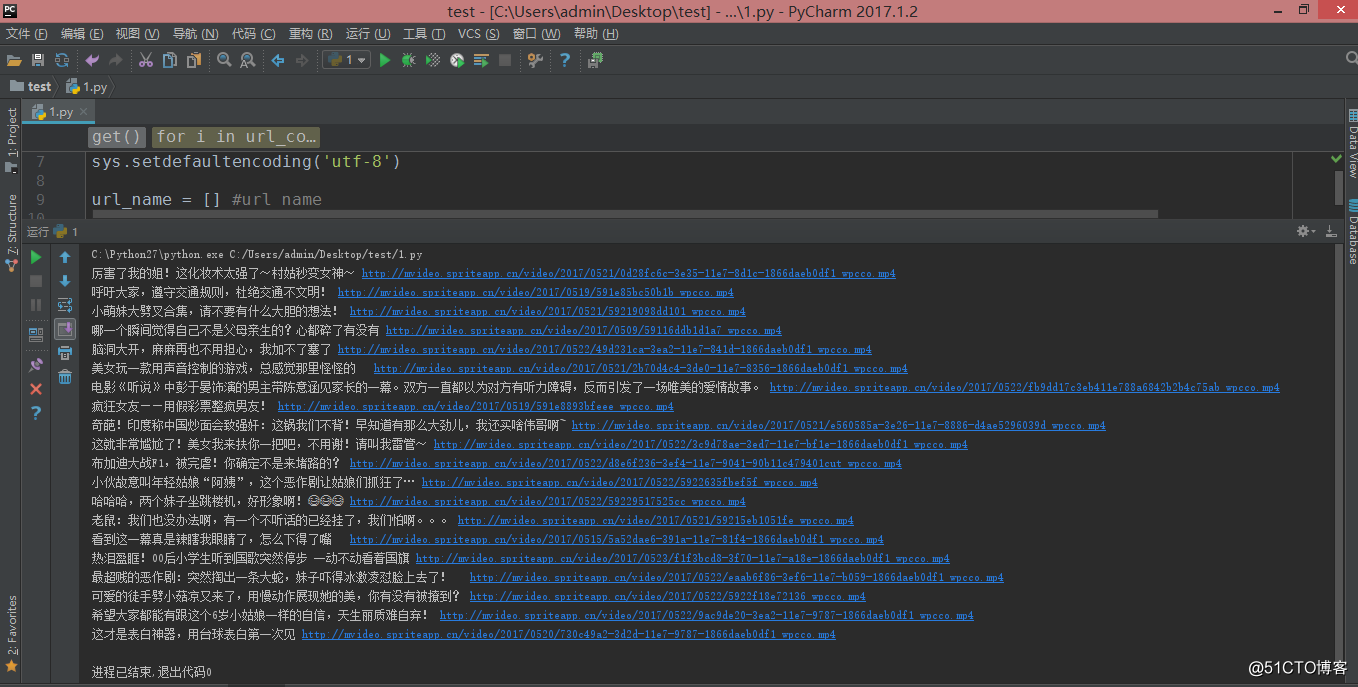
在 video 文件夹可以看到下载好的视频
注意报错:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-9: ordinal not in range(128)
解决:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
转载:http://blog.51cto.com/xiaogongju/2061754
python爬虫:爬取网站视频的更多相关文章
- Python爬虫爬取qq视频等动态网页全代码
环境:py3.4.4 32位 需要插件:selenium BeautifulSoup xlwt # coding = utf-8 from selenium import webdriverfrom ...
- 1.记我的第一次python爬虫爬取网页视频
It is my first time to public some notes on this platform, and I just want to improve myself by reco ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
随机推荐
- 批量改变图片的尺寸大小 python opencv
我目标文件夹下有一大批图片,我要把它转变为指定尺寸大小的图片,用pthon和opencv实现的. 以上为原图片. import cv2 import os # 按指定图像大小调整尺寸 def resi ...
- windows 设置tomcat为自动启动服务
1.下载免安装tomcat包,解压 2.配置环境变量: 点击新建,创建一个 变量名为:CATALINA_HOME 变量值为:tomcat解压文件的位置, 例如 F:\apache-tomcat ...
- 【转】odoo装饰器:model
model装饰器的作用是返回一个集合列表,一般用来定义自动化动作里面,该方法无ids传入. 应用举例: 定义columns langs = fields.Selection(string=" ...
- springboot 读写excel
添加两个坐标: <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</a ...
- CC3200使用MQTT的SSL加密证书可用日期修改
1. 在使用CC3200进行SSL加密的时候,需要证书,但是证书有一个截止日期,如果当前CC3200没有设置这个日期,那么证书通信会失败,需要添加代码 int setDeviceTime() { Sl ...
- iOS - Foundation相关
1.NSString A.创建的方式: stringWithFormat:格式化字符串 ,创建字符串对象在堆区域 @"jack& ...
- “腾讯WeTest助力《龙珠直播》盘点APP质量问题”
WeTest 导读 据调查数据表明,移动端用户在使用APP时如果遇到了闪退等兼容性问题,20%的用户会选择直接卸载. 2016年,被称为中国直播元年.随着各类直播平台的疯狂生长与扩散,直播产品在内容, ...
- Android Studio怎样创建App项目
然后等待大约N分钟: 默认的是Android模式, 改为Project模式更符合我们的习惯:
- 利用maven进行项目管理
下面为maven项目管理的一个结构 首先pom是路径文件,我们在编译或是运行程序时调用到jdk或一些自己写的jar包时会需要指明物理路径,这里的pom是一样的道理,同时在maven的管理下多出来了一些 ...
- python3对接聊天机器人API
详情见http://api.qingyunke.com/智能机器人API接口说明支持功能:天气.翻译.藏头诗.笑话.歌词.计算.域名信息/备案/收录查询.IP查询.手机号码归属.人工智能聊天接口地址: ...