【原创】Hadoop的IO模型(数据序列化,文件压缩)
数据序列化
我们知道,数据在分布式系统上运行程序数据是需要在机器之间通过网络传输的,这些数据必须被编码成一个个的字节才可以进行传输,这个其实就是我们所谓的数据序列化。数据中心中,最稀缺的资源就是网络带宽!在数据量巨大的分布式系统中,数据的紧凑高效传输和解析十分重要。
什么是数据的序列化?
数据的序列化简单点来说就是根据一套协议,在客户端上将内存中的数据编码成字节码,然后将这些字节码通过网络传输到另外一台服务器上,另外一台服务器通过相同的协议将这些字节码翻译成相应的数据存在内存中。一般来水,数据序列化需要满足以下四个条件。
(1) 紧凑。序列化出来的字节尽量的少。
(2) 快速。编码速度和解码速度要快。
(3) 可扩展。如果我增加了新的序列化协议,我们可以在原有的基础上进行扩展。
(4) 支持互操作。我们需要在不同语言所编写的程序之间能够使用相同的序列化协议。
为什么不用Java的序列化?
Java Jdk内部也提供了一套序列化的方法,为什么我们在hadoop程序中不适用java的序列化方法?这是因为java的序列化方法比较重,重表现在他将很多的信息都冗余到了最后编码出来的字节码中,这样就不满足紧凑的条件。所以说,在hadoop中,他自己提供了一套序列化方法,这套序列化的方法都实现了一个接口Writable接口。
Writable接口
public interface Writable {
void write(DataOutput var1) throws IOException;
void readFields(DataInput var1) throws IOException;
}
我们可以看到Writable接口又两个方法。write(DataOutput var1)方法是将对象数据编码成字节,readFields(DataInput var1)方法是一个逆的过程,就是将字节码反序列化内存中的数据。我们知道接口是没有具体的实现的,在Hadoop框架中,他已经默认帮我们实现了Java基本类型的Writable封装,对String类型的封装Text类,以及对Array和Map集合类型的Writable封装。
基本类型:
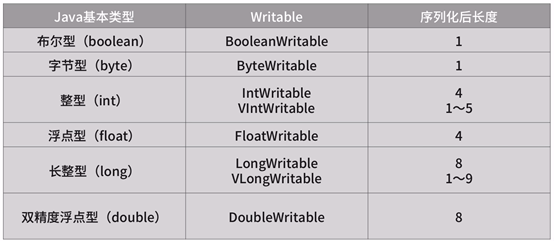
String类型:
String不是一个基本类型,而是一个char数组,为了方便使用,hadoop也在内部进行了封装。
集合类型:
集合类型的封装。我们在序列化的时候,首先将集合的大小写入进去,然后再将几何中的元素依次的序列化。
自定义Writable类型:
自定义Writable封装类一般由基本类型,集合类型和引用类型组成。
通用Writable类型:
在java中我们又object这个超类,在hadoop中我们也有类似的类型,即ObjectWritable。该类型处理了null,java数组,字符串String,java基本类型,枚举和Writable的子类6种情况。如果我们数据的类型是这6种中的一种,我们可以直接将数据标记为ObjectWritable类型,但是使用这种方法序列化会造成资源的浪费。因为ObjectWritable首先会将类名进行序列化,通常一个类的完整类名是非常长的,最后才将这个类的数据进行序列化,会造成资源浪费。
所以在日常使用中一般不使用ObjectWritable类型,而使用GenericWritable。GenericWritable使用的场景是我们大多数使用的场景,他适用于类型的数量不是很多,而且事先可以知道,这样我们就可以通过一个静态的数组,将所有事先知道的类型都列举出来,然后在序列化的时候使用数组下标代替类名序列化。数组的下标可以用一个字节存储,这样就大大缩小了序列化后的长度。
文件压缩
我们知道我们很多mr任务的输出都是hdfs上的文件,如果我们使用压缩格式存储文件可以大大的减少对存储的使用。如果我们在数据传输之前对数据进行压缩,也可以减少数据在网路上传输的大小。常用的与hadoop结合的压缩算法有以下的几种。

文件分片
文件分片对于mr的执行效率十分重要。如果文件不支持分片,则会产生两个问题:
(1) 一个map只能处理一个文件,Map处理时间厂。
(2) 牺牲了数据本地性,一个大文件的多个块存在不同的节点上,如果文件不能分片,则需要将所有的块通过网络传输到一个Map上计算。
选择合理的压缩格式
综合节约磁盘空间,网络带宽和mr的执行效率,一般使用如下的压缩格式:
(1)对于经常访问的数据 使用LZO+索引的方式存储。因为他解压速度比较快,我们读取文件里的数据也就比较快。
(2)对于不经常访问的数据,比如历史比较久远的数据,采用bzip2压缩存储。
(3)Map和Reduce中间的数据传输,采用Snappy压缩。因为他压缩速度和解压所读都非常快。
【原创】Hadoop的IO模型(数据序列化,文件压缩)的更多相关文章
- HADOOP中的CRC数据校验文件
Hadoop系统为了保证数据的一致性,会对文件生成相应的校验文件(.crc文件),并在读写的时候进行校验,确保数据的准确性.在本地find -name *.crc -print 看 比如我们遇到的这个 ...
- NIO【同步非阻塞io模型】关于 文件io 的总结
1.前言 这一篇随笔是写 NIO 关于文件输入输出的总结 /* 总结: 1.io操作包括 socket io ,file io ; 2.在nio模型,file io使用fileChannel 管道 , ...
- Java NIO学习系列六:Java中的IO模型
前文中我们总结了linux系统中的5中IO模型,并且着重介绍了其中的4种IO模型: 阻塞I/O(blocking IO) 非阻塞I/O(nonblocking IO) I/O多路复用(IO multi ...
- [大牛翻译系列]Hadoop(16)MapReduce 性能调优:优化数据序列化
6.4.6 优化数据序列化 如何存储和传输数据对性能有很大的影响.在这部分将介绍数据序列化的最佳实践,从Hadoop中榨出最大的性能. 压缩压缩是Hadoop优化的重要部分.通过压缩可以减少作业输出数 ...
- IO编程、操作文件或目录、序列化、JSON
IO中指Input/Output,即输入和输出:涉及到数据交换的地方,通常是磁盘.网络等,就需要IO接口 1.由于CPU和内存的速度远远高于外设的速度,所以,在IO编程中,存在速度严重不匹配问题.eg ...
- 【原创 Hadoop&Spark 动手实践 3】Hadoop2.7.3 MapReduce理论与动手实践
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop基础-MapReduce的数据倾斜解决方案
Hadoop基础-MapReduce的数据倾斜解决方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据倾斜简介 1>.什么是数据倾斜 答:大量数据涌入到某一节点,导致 ...
- IO模型详解
IO编程包括: 文件读写 操作 StringIO 和 BytesIO 内存中 操作文件和目录 OS 序列化 json pickling 操作系统内核空间(缓冲区)收发数据: 内核态(内核空间)---- ...
- Hadoop的IO操作
Hadoop的API官网:http://hadoop.apache.org/common/docs/current/api/index.html 相关的包 org.apache.hadoop.io ...
随机推荐
- loj#6261. 一个人的高三楼(NTT+组合数学)
题面 传送门 题解 统计\(k\)阶前缀和,方法和这题一样 然后这里\(n\)比较大,那么把之前的柿子改写成 \[s_{j,k}=\sum_{i=1}^ja_i{j-i+k-1\choose j-i} ...
- CentOS 下安装 Hexo 博客
前言: 之前一直使用Wordpress架构作为博客网站架构,但是现在频频爆出漏洞.实在是不敢用也不想用了,然后群里面有小伙伴用的是 Github 搭建 Hexo 架构博客.就写了这个教程,给自己做个参 ...
- rejected –non-fast-forward解决方法
Eclipse 是一个开放源代码的.基于Java的可扩展开发平台.就其本身而言,它只是一个框架和一组服务,用于通过插件组件构建开发环境.幸运的是,Eclipse 附带了一个标准的插件集,包括Java开 ...
- win10安装express遇到的问题。
昨天在centos上成功安装了express,今天想在win10上面装一个,死活安装不了 express可以正常安装,但是每次安装express-generator的时候一直报错 659 silly ...
- 封装log4j支持记录到testng
一.初始方案 自动化中需要把日志通过testng的Reporter.log来记录日志在报告中展示.开始是新增了一个日志类: ReporterLog.class import org.slf4j.Log ...
- python update()
Python 字典 update() 函数把字典参数 dict2 的 key/value(键/值) 对更新到字典 dict 里. dict.update(dict2) 如果dict2里的键和dict1 ...
- Oracle远程数据建物化视图(materialized)创建简单记录,以及DBLINK的创建
目的:实现远程数据库访问及其相应表的定时同步 一.远程数据库dblink的创建 select * from dba_db_links; select * from user_sys_privs;--查 ...
- 《大数据日知录》读书笔记-ch3大数据常用的算法与数据结构
布隆过滤器(bloom filter,BF): 二进制向量数据结构,时空效率很好,尤其是空间效率极高.作用:检测某个元素在某个巨量集合中存在. 构造: 查询: 不会发生漏判(false negativ ...
- PHP面向对象的基本思路
第一步:识别对象 ——任何实体都可以被识别为一个对象 第二步:识别对象的属性 ——对象里面存储的数据被识别为属性 ——对于不同的业务逻辑,关注的数据不同,独享里面存储的属性也不同 第三步:识别对象的行 ...
- centos7 配置php-fpm
1.复制相应的文件cp /usr/local/php7/etc/php-fpm.conf.default /usr/local/php7/etc/php-fpm.confcp /usr/local/p ...