Spark Streaming的PIDRateEstimator与backpressure
PIDRateEstimator是Spark Streaming用来实现backpressure的关键组件。
看了一些博客文章,感觉对它的解释都没有说到要点,还是自己来研究一下比较好。
首先,需要搞清楚的一个问题是Spark Streaming的backpressure是想让系统达到怎么样的一种状态。这个问题不明确,PIDRateEstimator的作用就搞不清楚。
backpressure的目标
首先,backpressure这套机制是系统(由应用程序和物理资源组成的整体)的内在性质对Spark Streaming的吞吐量的限制,而并非是某种优化。可以认为,在固定的资源下(CPU、内存、IO),Spark Streaming程序存在吞吐量的上限。
放在非micro-batch的情况下考虑,这意味着存在一个最大处理速度,RateEstimator认为这个速度的单位为records/second (不过实际上,每条消息的处理所耗的时间可能差别很大,所以这个速度的单位用records/second实际上是可能并不合适,可能是一种过度的简化)。
放在Spark Streaming的micro-batch的情况下,由于调度器每隔batch duration的时间间隔生成一个micro-batch,这个吞吐率的上限意味着每个batch总的消息数量存在上限。如果给每个batch分配率的消息总数超过这个上限,每秒处理消息条数是不变的,只会使得batch的处理时间延长,这样对于系统没有什么好处,反而由于每个batch太大而可能导致OOM。
当达到这个最大处理速度时,表现就是batch duration等于batch的计算阶段所花的时间,也就是batch duration == batch processing time。
那么backpressure的目标,就是使得系统达到上边这个状态(这个并非完全对,下面的分析会给出具体的状态)。它不会使得系统的累积未处理的数据减少,也不会使得系统的吞吐率提高(在不引起OOM,以及不计算GC的开销的情况下,当processing time > batch duration时,系统的吞吐量已经达到最高)。而只是使得系统的实际吞吐量稳定在最大吞吐量(除非你手动设置的rate的最大值小于最大吞吐量)
PIDRateEstimator
首先,要明确PID控制器的作用。
引用一篇blog的说法:
PID控制器是一个在工业控制应用中常见的反馈回路部件。
这个控制器把收集到的数据和一个参考值进行比较,然后把这个差别用于计算新的输入值,
这个新的输入值的目的是可以让系统的数据达到或者保持在参考值。
PID控制器可以根据历史数据和差别的出现率来调整输入值,使系统更加准确而稳定。
重点在于它的目的是调整输入,比而使得系统的某个我们关注的目标指标到目标值。
PID的控制输出的公式为
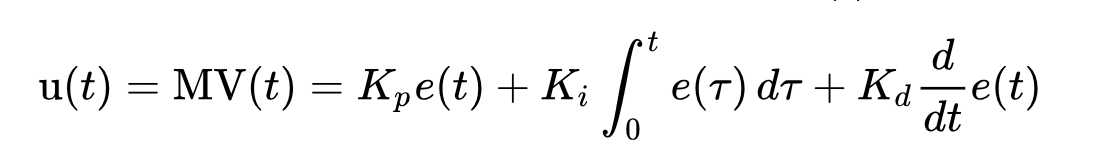
这里u(t)为PID的输出。

SP是setpoint, 就是参考值
PV是 process variable, 也就是测量值。
A PID controller continuously calculates an error value e(t) as the difference between a desired setpoint (SP) and a measured process variable (PV) and applies a correction based on proportional, integral, and derivative terms (denoted P, I, and D respectively), hence the name.
计算逻辑
首先,看下RateEstimator的compute方法的定义

private[streaming] trait RateEstimator extends Serializable {
/**
* Computes the number of records the stream attached to this `RateEstimator`
* should ingest per second, given an update on the size and completion
* times of the latest batch.
*
* @param time The timestamp of the current batch interval that just finished
* @param elements The number of records that were processed in this batch
* @param processingDelay The time in ms that took for the job to complete
* @param schedulingDelay The time in ms that the job spent in the scheduling queue
*/
def compute(
time: Long,
elements: Long,
processingDelay: Long,
schedulingDelay: Long): Option[Double]
}
看下参数的含义
- time: 从它的来源看,它来源于BatchInfo的processingEndTime, 准确含义是 “Clock time of when the last job of this batch finished processing”,也就是这个batch处理结束的时间
- elements: 这个batch处理的消息条数
- processingDelay: 这个job在实际计算阶段花的时间(不算调度延迟)
- schedulingDelay:这个job花在调度队列里的时间
PIDRateEstimator是获取当前这个结束的batch的数据,然后估计下一个batch的rate(注意,下一个batch并不一定跟当前结束的batch是连续两个batch,可能会有积压未处理的batch)。
PIDRateEstimator对于PID控制器里的"error"这个值是这么计算的:
// in seconds, should be close to batchDuration
val delaySinceUpdate = (time - latestTime).toDouble / 1000 // in elements/second
val processingRate = numElements.toDouble / processingDelay * 1000 // In our system `error` is the difference between the desired rate and the measured rate
// based on the latest batch information. We consider the desired rate to be latest rate,
// which is what this estimator calculated for the previous batch.
// in elements/second
val error = latestRate - processingRate val historicalError = schedulingDelay.toDouble * processingRate / batchIntervalMillis // in elements/(second ^ 2)
val dError = (error - latestError) / delaySinceUpdate val newRate = (latestRate - proportional * error -
integral * historicalError -
derivative * dError).max(minRate)
这里的latestRate是指PID控制器为上一个batch,也就是当前结束的batch,在生成这个batch的时候估计的处理速度。
所以上边代码中,latestRate就是参考值, processingRate就是测量值。
这里为什么如此计算我还是没搞清楚,因为latestRate是一个变化的值,不知道这样在数学上会对后边的积分、微分项的含义造成什么影响。
error何时为0
可以推导出来当batchDuration = processingDelay时候,这里的error为零。
推导过程为:
latestRate实际上等于numElements / batchDuration,因为numElements是上次生成job时根据这个latestRate(也就是当时的estimated rate)算出来的。
那么 error = (numElements / batchDuaration) - (numElements/processingDelay) 这里的processingDelay就是processing time
所以,当processingDelay等于batchDuration时候,error为零。
但是error为零时,PID的输出不一定为零,因为需要考虑到历史误差和误差的变化。这里刚结束的batch可能并非生成后就立即被执行,而是在调度队列里排了一会队,所以还是需要考虑schedulingDelay,它反应了历史误差。
那么什么时候达到稳定状态呢?
当PID输出为0时,newRate就等于latestRate,此时系统达到了稳定状态,error为零,historicalError和dError都为0。
这意味着:
- 没有schedulingDelay,意味着job等待被调度的时间为0. 如果没有累积的未执行的job,那么schedulingDelay大致等于0.
- error为零,意味着batchDuration等于processingDelay
- dError为零,在error等于0时,意味着上一次计算的error也为零。
这就是整个RateEstimator,也就是backpressure想要系统达到的状态。
这里可以定性地分析一下达到稳定状态的过程:
- 如果batch分配的消息少于最高吞吐量,就会有processingRate > latestRate, 从而使得error为负,如果忽略积分和微分项的影响,就会使得newRate = latestRate - propotional * rate,从而使得newRate增大,因此下一个batch处理的消息会变多。
- 如果batch分配的消息大于最高吞吐量,就会有processingRate < latestRate,从而使得error为正,如果此前已经有job被积累,那么historicalError也为正,考虑到dError的系数默认为0,所以此时newRate = latestRate - proportional * error -integral * historicalError 使得newRate变小,从而使得下一个batch处理的消息变少,当newRate == latestRate时,有 -proportional * error == integral * historicalError,即error为一个负值,也即processingRate > latestRate,也就是说会使得给每个batch分配的消息小于它的最大处理量。此时,由于processingDelay小于batchDuration,会使得历史上累积的job有机会得到处理,从而逐渐减少在等待的job数量。
可以看出来这个PIDRateEstimator并非是普遍最优的,因为它的假设是系统的动态特定不随时间变化,但是实际上如果没有很有效的资源隔离,系统对于Spark Streaming程度来讲,其资源是随时间变化的,而且在某些时间可能发生剧烈的变化。此时,此时RateEstimator应该做出更剧烈的变化来应对,比如通过动态调整各个部分的系数。
如果用户对自己的系统有深的了解,比如当资源和负载是周期性变化时,那就可以定制更合适的RateEstimator,比如考虑到每天同比的流量变化来调整estimatedRate。
Spark Streaming的PIDRateEstimator与backpressure的更多相关文章
- Spark Streaming Backpressure分析
1.为什么引入Backpressure 默认情况下,Spark Streaming通过Receiver以生产者生产数据的速率接收数据,计算过程中会出现batch processing time > ...
- Spark Streaming性能优化: 如何在生产环境下应对流数据峰值巨变
1.为什么引入Backpressure 默认情况下,Spark Streaming通过Receiver以生产者生产数据的速率接收数据,计算过程中会出现batch processing time > ...
- Spark Streaming反压机制
反压(Back Pressure)机制主要用来解决流处理系统中,处理速度比摄入速度慢的情况.是控制流处理中批次流量过载的有效手段. 1 反压机制原理 Spark Streaming中的反压机制是Spa ...
- Spark Streaming数据限流简述
Spark Streaming对实时数据流进行分析处理,源源不断的从数据源接收数据切割成一个个时间间隔进行处理: 流处理与批处理有明显区别,批处理中的数据有明显的边界.数据规模已知:而流处理数 ...
- Spark Streaming揭秘 Day17 资源动态分配
Spark Streaming揭秘 Day17 资源动态分配 今天,让我们研究一下一个在Spark中非常重要的特性:资源动态分配. 为什么要动态分配?于Spark不断运行,对资源也有不小的消耗,在默认 ...
- Spark Streaming 数据接收过程
SparkStreaming 源码分析 一节中从源码角度,描述了Streaming执行时代码的调用过程.下边就接收转化阶段过程再简单分析一下,为分析backpressure作准备. SparkStre ...
- Spark Streaming 调优指南
SparkStreaming是架构在SparkCore上的一个"应用",SparkStreaming主要由DStreamGraph.Job的生成.数据的接收和导入以及容错四大模块组 ...
- Apache Spark 2.2.0 中文文档 - Spark Streaming 编程指南 | ApacheCN
Spark Streaming 编程指南 概述 一个入门示例 基础概念 依赖 初始化 StreamingContext Discretized Streams (DStreams)(离散化流) Inp ...
- Spark Streaming编程指南
Overview A Quick Example Basic Concepts Linking Initializing StreamingContext Discretized Streams (D ...
随机推荐
- 176. Second Highest Salary
Write a SQL query to get the second highest salary from the Employee table. +----+--------+ | Id | S ...
- 邂逅Sass和Compass之Sass篇
对于一个从后台转到前端的web开发者来说,最大的麻烦就是写CSS,了解CSS的人都知道,它可以开发网页样式,但是没法用它编程,感觉耦合性相当的高,如果想要方便以后维护,只能逐句修改甚至重写相当一部分的 ...
- git更新远程仓库代码到本地
1 使用命令查看连接的远程的仓库 git remote -v 2 远程获取代码 git fetch origin master 如果出现 Already up-to-date 说明代码更新好了 出现 ...
- 归并排序(MergeSort)
原帖:http://blog.csdn.net/magicharvey/article/details/10192933 算法描述 归并排序(MergeSort)是采用分治法的一个非常典型的应用.通过 ...
- 洛谷P1850换教室
题目传送门 理解题意:给定你一个学期的课程和教室数量以及教室之间的距离还有换教室成功的概率,求一个学期走的距离的期望最小值 题目是有够恶心的,属于那种一看就让人不想刷的题目...很明显的动规,但是那个 ...
- 【SQL】ORACLE生成临时表
在日常的SQL查询中,我们需要对要查询的数据进行事先处理,然后再在预先处理好的数据里面进行查询.此时我们就需要用到临时表了,将数据预先处理好放到临时表里面,然后再在临时表里根据我们需要的条件进行查询. ...
- Eclipse有助于提高开发速度的快捷键
用Eclipse已经很长一段时间了,自己常用的几个快捷键也已经很熟,但还是有一些自己不经常在开发中使用,但非常使用的快捷键,记录下来,以后利用来提高开发效率. 1.ctrl + shift + r ...
- 使用keras时出现 `pydot` failed to call GraphViz的解决办法
问题来源于使用了 keras.utils.plot_model,报错内容为: 2018-08-29 08:58:21.937037: I tensorflow/core/platform/cpu_fe ...
- coreseek 段错误 (core dumped) 问题
coreseek建立索引出现上面问题经过测试发现有下面几个原因: 1. 分词配置文件不存在 uni.lib 2. uni.lib配置文件格式不正确
- Binary Tree Longest Consecutive Sequence -- LeetCode
Given a binary tree, find the length of the longest consecutive sequence path. The path refers to an ...