python 机器学习中的数据处理学习记录
在机器学习中,选择合适的算法固然重要,但是数据的处理也同样重要。通过对数据的处理,能提高计算效率,提高预测识别精确度等等
以下记录下一些数据处理的方法
一、处理缺失值
对于数据集中有缺失值的,粗暴的方法是直接删除该行或者该列的数据,但是这样不可取。可以通过计算每一列或者每一行的平均值来替代该值。
- from sklearn.preprocessing import Imputer
- import pandas as pd
- df = pd.read_csv(data_dir)
- imr = Imputer(missing_values='NaN', strategy='mean', axis=0)
- imr = imr.fit(df)
- imputed_data = imr.transform(df.values)
strategy除了mean还有其他的选项
二、处理分类数据,如果数据中有字符串,可以将字符串和数值做个映射
- from sklearn.preprocessing import LabelEncoder
- class_le = LabelEncoder()
- y = class_le.fit_transform(df['classlabel'].values)
可以使用inverse_transform得到原始字符串
如果数据中有离散的特征值,可以对其进行独热编码
比如颜色,r,g,b如果通过图片的映射得到r=1,g=2,b=3机器会认为b>g>r,显然不符合我们的要求
可以将其编码为100,010,001来识别
- from sklearn.preprocessing import OneHotEncoder
- ohe = OneHotEncoder(categorical_features=[0])
- ohe.fit_transform(X).toarray()
将数据集随机分隔成训练集和测试集
- from sklearn.cross_validation import train_test_split
- X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3, random_state=0)
将数据集分成70%训练集30%测试集
三、标准化和归一化
归一化是将特征范围缩小到0-1。主要目的是为了简化计算
计算公式
标准化是将数据按比例缩放,使其落入一个小的特定区间
四、过拟合问题
如果一个模型在训练集的表现比测试集好很多,很可能就是过拟合了,即泛化能力太差,具有高方差
产生的一个原因是对应给定的训练集数据,模型过于复杂。常用的减小泛化误差的做法
1收集更多的训练集数据
2正则化,即引入模型复杂度的惩罚项
3选择简单的模型,参数少一点的
4降低数据的维度
五、正则化(特征选择,处理过拟合问题的一种方式)
常用的正则项有
L1正则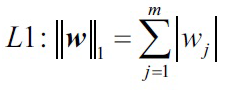 权重参数的绝对值和
权重参数的绝对值和
L2正则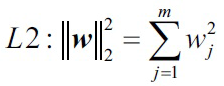 权重参数的平方和
权重参数的平方和
正则项是对现在损失函数的惩罚项,鼓励权重参数取小一点的值,惩罚大权重参数,
正则化后的新损失函数=原始损失函数+正则项
对于sklearn中支持L1正则的模型,只需要初始化的时候用penalty参数设置为L1正则即可
- from sklearn.linear_model import LogisticRegression
- LogisticRegression(penalty='l1')
六、降维(特征抽取,处理过拟合的一种方式)
1主成分分析PCA,用于无监督数据压缩
2线性判别分析LDA,用于监督降维作为一种监督降维
3核PCA
特征抽取可以理解为是一种数据压缩的手段,用于提高计算效率,减小维度诅咒。
PCA主成分分析是一种广泛使用的无监督的线性转换技术,主要用于降维
PCA的步骤
1.将d维度原始数据标准化
2.构建协方差矩阵
3.求解协方差矩阵的特征向量和特征值
4.选证值最大的k个特征值对应的特征向量,k就是新特征空间的维度,k<<d
5利用k特征向量构建映射矩阵W
6将原始d维度的数据集X,通过映射矩阵W转换到k维度的特征子空间
标准化数据集
- from sklearn.cross_validation import train_test_split
- from sklearn.preprocessing import StandardScaler
- X, y = xxx,xxx
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
- sc = StandardScaler()
- X_train_std = sc.fit_transform(X_train)
- X_test_std = sc.transform(X_test)
协方差计算公式

计算协方差矩阵
- import numpy as np
- cov_mat = np.cov(X_train_std.T)
获取特征值和特征向量
- eigen_vals, eigen_vecs = np.linalg.eig(cov_mat)
eigen_vals为特征值,eigen_vecs为特征向量
特征值越大其包含的信息越多
可以使用方差解释率(特征值占特征值总和的比例)来查看其占比,取最大的几项,舍弃占比低的
- tot = sum(eigen_vals)
- var_exp = [(i / tot) for i in sorted(eigen_vals, reverse=True)]
- cum_var_exp = np.cumsum(var_exp)
假设前两项占比最大
- eigen_pairs = [(np.abs(eigen_vals[i]), eigen_vecs[:, i]) for i in range(len(eigen_vals))]
- eigen_pairs.sort(reverse=True)
- w = np.hstack((eigen_pairs[0][1][:, np.newaxis],
- eigen_pairs[1][1][:, np.newaxis]))
- X_train_pca = X_train_std.dot(w)
将维度降到二维
更简单的方法
- from sklearn.decomposition import PCA
- pca = PCA(n_components=2)
- X_train_pca = pca.fit_transform(X_train_std)
- X_test_pca = pca.transform(X_test_std)
LDA的一个假设是数据服从正态分布,同时每个类含有相同的协方差矩阵,每个特征都统计独立。即使真是数据可能不服从假设,LDA也依然具有很好的表现
LDA的步骤
1.将d维度原始数据进行标准化.
2.对每一个类,计算d维度的平均向量.
3.构建类间(between-class)散点矩阵和类内(within-class)散点矩阵
.
4.计算矩阵的特征向量和特征值.
5.选择值最大的前k个特征值对应的特征向量,构建d*d维度的转换矩阵,每一个特征向量是
的一列.
6.使用矩阵将原始数据集映射到新的特征子空间.
简单的方法
- from sklearn.lda import LDA
- lda = LDA(n_components=2)
- X_train_lda = lda.fit_transform(X_train_std, y_train)
核PCA(处理非线性可分数据)
运用核PCA,将非线性可分的数据转换到新的,低维度的特征子空间,然后运用线性分类器解决
核函数的功能可以理解为:通过创造出原始特征的一些非线性组合,将原来的d维度数据集映射到k维度特征空间的d<k
先将数据转换到一个高维度的空间,然后在该空间运用标准PCA重新将数据映射到一个比原来还低的空间,最后就可以用线性分类器解决问题了
- from scipy.spatial.distance import pdist, squareform
- from scipy import exp
- from scipy.linalg import eigh
- def rbf_kernel_pca(X, gamma, n_components):
- sq_dists = pdist(X, 'sqeuclidean')
- mat_sq_dists = squareform(sq_dists)
- K = exp(-gamma * mat_sq_dists)
- N = K.shape[0]
- one_n = np.ones((N, N)) / N
- K = K - one_n.dot(K) - K.dot(one_n) + one_n.dot(K).dot(one_n)
- eigvals, eigvecs = eigh(K)
- X_pc = np.column_stack((eigvecs[:, -i] for i in range(1, n_components + 1)))
- return X_pc
sklearn实现核PCA
- from sklearn.datasets import make_moons
- from sklearn.decomposition import KernelPCA
- X, y = make_moons(n_samples=100, random_state=123)
- scikit_kpca = KernelPCA(n_components=2, kernel='rbf', gamma=15)
- X_skernpca = scikit_kpca.fit_transform(X)
使用PCA,我们将数据映射到一个低维度的子空间并且最大化正交特征轴的方差,PCA不考虑类别信息。LDA是一种监督降维方法,意味着他要考虑训练集的类别信息,目标是将类别最大化地可分。最后,学习了核PCA,它能够将非线性数据集映射到低维特征空间,然后数据变成线性可分了
摘自https://www.gitbook.com/book/ljalphabeta/python-/details
python 机器学习中的数据处理学习记录的更多相关文章
- [Spark][Python]DataFrame中取出有限个记录的例子
[Spark][Python]DataFrame中取出有限个记录的例子: sqlContext = HiveContext(sc) peopleDF = sqlContext.read.json(&q ...
- Python机器学习库和深度学习库总结
我们在Github上的贡献者和提交者之中检查了用Python语言进行机器学习的开源项目,并挑选出最受欢迎和最活跃的项目. 1. Scikit-learn(重点推荐) www.github.com/sc ...
- Python机器学习笔记:深入学习Keras中Sequential模型及方法
Sequential 序贯模型 序贯模型是函数式模型的简略版,为最简单的线性.从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠. Keras实现了很多层,包括core核心层,Convolution卷 ...
- python 机器学习中模型评估和调参
在做数据处理时,需要用到不同的手法,如特征标准化,主成分分析,等等会重复用到某些参数,sklearn中提供了管道,可以一次性的解决该问题 先展示先通常的做法 import pandas as pd f ...
- django中日志使用学习记录
在setting中加入以下代码 LOGGING = { 'version': 1, 'disable_existing_loggers': True, 'formatters': { 'verbose ...
- python学习过程中的踩坑记录<若干,随时更新>
问题1:python中print的连串输出与java不一样? 输入print(code +"+++"); --在代码中写入,界面未报错,但是告诉你不行 会报错,如图: 解决办法: ...
- 流畅的python第十一章接口学习记录
鸭子协议(忽略对象真正类型,转而关注对象有没有实现所需的方法,签名和语义) 标准库中的抽象基类 collections.abc模块中的抽象基类 抽象方法是抽象基类中用来强制子类必须实现的方法,如果子类 ...
- python微信公众号开发学习记录
网上有很多微信公众号的开发教程,但是都是好几年前的了,而且很多都是抄袭其他人的,内容几乎一模一样.真的无语了.只好自己总结一下开发的一些简单流程. 一先去注册个微信公众号,这个就不详细说了, 二登录后 ...
- 在MVC中使用NHibernate学习记录
NHibernate简介: NHibernate是一个面向.net环境的对象/关系数据库映射工具,对象/关系数据库映射(object/relational mapping,ORM)是一种技术,可以将对 ...
随机推荐
- 安装vmware+CentOS 7.4
安装步骤 选择第一个 按tab键 空格下一行 输入 红框内容 回车 注意事项 道路不通排查过程1.ip地址2.vmware 编辑-虚拟网络编辑器3.windows 服务 vmware相关服务 要开启 ...
- 赤峰项目目前的mysql配置项目
#BEGIN CONFIG INFO #DESCR: 4GB RAM, InnoDB only, ACID, few connections, heavy queries #TYPE: SYSTEM ...
- vivo手机的坑-禁止微信浏览器网页点击图片,图片会自动放大
这个坑让我郁闷极了,之前我的手机在微信浏览器打开网页点击图片时,啥事也没有 现在,咋回事,变了呢! 现在我打开微信浏览器网页面html,点击一个img标签的图片,图片会自动满屏放大,吓死宝宝了.其他人 ...
- bzoj 1444 AC自动机 + 矩阵乘法 | 高斯消元
恶补了一下AC自动机,花了一天时间终于全部搞明白了. 思路:将每个人的串加入AC自动机,在AC自动机生成的状态图上建边,注意单词末尾的节点只能转移到自己概率为1, 然后将矩阵自乘几十次后误差就很小了, ...
- OpenStack 存储服务 Cinder存储节点部署LVM (十四)
部署在block(10.0.0.103)主机 一)配置lvm 1.安装lvm2软件包 yum install lvm2 -y 2.启动LVM的metadata服务并且设置该服务随系统启动 system ...
- 搭建openstack系统初始化(2)
操作系统环境 :Centos 7.3 x64 1).安装需要的包 yum install wget vim chrony net-tools bash-completion -y 2)配置阿里elpl ...
- 【剑指offer】面试题 16. 数值的整数次方
面试题 16. 数值的整数次方 题目描述 题目:给定一个double类型的浮点数base和int类型的整数exponent.求base的exponent次方. 解答过程 下面的讨论中 x 代表 bas ...
- textarea 内容不可编辑 自是适应高度 只读相关属性配置
不可编辑: <textarea disabled="disabled"></textarea> 如果仅仅用于禁止输入(只读,但有用),使用readonly属 ...
- [Nescafé41]编码病毒(循环卷积)
题意看起来好麻烦实际上很简单,首先4s可以先bitset暴力一下,听说卡卡就能过:$O(2^{22}+n^2/32)$ #include<cstdio> #include<bitse ...
- 【模拟退火】poj2420 A Star not a Tree?
题意:求平面上一个点,使其到给定的n个点的距离和最小,即费马点. 模拟退火的思想是随机移动,然后100%接受更优解,以一定概率接受更劣解.移动的过程中温度缓慢降低,接受更劣解的概率降低. 在网上看到的 ...