爬虫之Beautifulsoup及xpath
1.BeautifulSoup (以 Python 风格的方式来对 HTML 或 XML 进行迭代,搜索和修改)
1.1 介绍
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
1.2 解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
1.3 使用
借用官方文档提供的爱丽丝梦游仙境文档内容
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
"""
1.标签获取
from bs4 import BeautifulSoup soup=BeautifulSoup(html_doc,'html.parser') # 获取a标签的所有内容
print(soup.a) # <a class="sister 123" href="http://example.com/elsie" id="link1">Elsie</a>
print(type(soup.a)) # <class 'bs4.element.Tag'> # 获取title节点的所有内容
print(soup.head.title) # <title>The Dormouse's story</title> print(soup.find_all("a")) # 获取所有符合条件的标签对象集合,以列表形式展示
2.标签对象的属性,名称,文本
from bs4 import BeautifulSoup
soup=BeautifulSoup(html_doc,'html.parser')
for link in soup.find_all('a'):
# print(link.name) # 获取标签名称
# print(link.get('href')) # 获取a标签中的所有href
# print(link["href"])
# print(link.get("id")) # 获取标签的id
# print(link.get("class")) # 获取标签的class值
# print(link.attrs) # 获取a标签中的所有属性
# del link["id"]
# print(link.attrs) # 获取除了a标签中除id属性外的所有属性
print(link.text) # 获取a标签下的文本信息
print(link.string)
print(link.get_text())
# text和string的区别
print(soup.p.string) # None
print(soup.p.text) # The Dormouse's story 123
1.4 文档树信息获取
print(soup.head.title.string) #连续跨节点获取文本信息
print(soup.body.a.string) # 获取a标签下的第一个文本信息 # 子节点,子孙节点
print(soup.p.contents) # 获取第一个p标签下的所有文本信息,最终在一个列表内
# ['\n', <b>The Dormouse's story</b>, '\n', <span alex="dsb" class="123">123</span>, '\n'] print(soup.p.children) # 包含p下所有子节点的生成器
for child in soup.p.children:
print(child) # 获取p下的所有子节点 print(soup.p.descendants) # 获取子孙节点,p下所有的标签都会选择出来
for child in soup.p.descendants:
print(child) # 父节点,祖先节点
print(soup.p.parent) # 获取p标签的父节点,得到整个body
print(soup.p.parents) # 一个生成器,找到p标签所有的祖先节点 # 兄弟节点
print(soup.a.next_sibling) # a节点的下一个兄弟,得到一个逗号
print(soup.a.next_siblings) # 一个生成器,下面的兄弟们 print(soup.a.previous_sibling) # 上一个兄弟,即得到了上面的文本信息
print(soup.a.previous_siblings) # 一个生成器,上面的兄弟们
搜索文档树下的几种过滤器(结合find_all)
还是借用官方文档提供的内容
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
"""
第一种:字符串
ret = soup.find_all(name="a") # a标签的所有节点
第二种:正则
import re
tmp = re.compile("^h")
rep = soup.find_all(name=tmp) # 获取所有以h开头的标签节点,包含html标签和head标签
第三种:列表
ret = soup.find_all(name=["a","b"]) # 获取所有的a标签和b标签
第四种:方法
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id') for tag in soup.find_all(name=has_class_but_no_id):
print(tag) # 获取具有class属性但不具有id属性的标签
关于limit参数:
如果我们不需要全部结果,可以使用 limit参数限制返回结果的数量
print(soup.find_all('a',limit=2))
关于recursive参数:
调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False
print(soup.html.find_all('a',recursive=False))
find的使用(只返回一个):
find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果
print(soup.find('a'))
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
soup.head.title 是 tag的名字 方法的简写.这个简写的原理就是多次调用当前tag的 find() 方法:
soup.head.title
# <title>The Dormouse's story</title>
soup.find("head").find("title")
# <title>The Dormouse's story</title>
1.5 css选择器
这里其实通过名称就可以知道,它是通过css属性来进行查找的
ret=soup.select("a") # 标签名查找
ret=soup.select("#link1") # 通过id查找
ret=soup.select(".sister") # 通过类名查找
ret=soup.select(".c1 p,a") # 组合查找
ret = soup.select("a[href='http://example.com/tillie']") # 通过属性查找
更多介绍可以查看官方文档
2.xpath (快速,简单易用,功能齐全的库,用来处理 HTML 和 XML)
xpath全称为XML Path Language, 一种小型的查询语言,实现的功能与re以及bs一样,但是大多数情况会选择使用xpath
由于XPath属于lxml库模块,所以首先要安装库lxml
调用方法:
from lxml import etree
selector=etree.HTML('源码') # 将源码转化为能被XPath匹配的格式
# <Element html at 0x29b7fdb6708>
ret = selector.xpath('表达式') # 返回为一列表
2.1 查询语法
原文
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
"""
这里首先需要将它转换成xpath匹配的格式
from lxml import etree
selector=etree.HTML(html_doc) # 将源码转化为能被XPath匹配的格式
节点选取
nodename 选取nodename节点的所有子节点 xpath(‘//div’) 选取了所有div节点
/ 从根节点选取 xpath(‘/div’) 从根节点上选取div节点
// 选取所有的当前节点,不考虑他们的位置 xpath(‘//div’) 选取所有的div节点
. 选取当前节点 xpath(‘./div’) 选取当前节点下的div节点
.. 选取当前节点的父节点 xpath(‘..’) 回到上一个节点
@ 选取属性 xpath(’//@calss’) 选取所有的class属性
用法
from lxml import etree
selector = etree.HTML(html_doc) ret=selector.xpath("//p")
# [<Element p at 0x2a6126569c8>, <Element p at 0x2a612656a08>, <Element p at 0x2a612656a48>]
ret=selector.xpath("//p/text()") # 打印当中的文本信息,包括换行符 ret=selector.xpath("/p") # [] ret=selector.xpath("//a[@id='link1']") # [<Element a at 0x1c541e43808>]
ret=selector.xpath("//a[@id='link1']/text()") # ['Elsie']
谓语用法(返回的都是element对象)
表达式 结果
xpath(‘/body/div[1]’) 选取body下的第一个div节点
xpath(‘/body/div[last()]’) 选取body下最后一个div节点
xpath(‘/body/div[last()-1]’) 选取body下倒数第二个div节点
xpath(‘/body/div[positon()<3]’) 选取body下前两个div节点
xpath(‘/body/div[@class]’) 选取body下带有class属性的div节点
xpath(‘/body/div[@class=”main”]’) 选取body下class属性为main的div节点
xpath(‘/body/div[price>35.00]’) 选取body下price元素值大于35的div节点
通配符
表达式 结果
xpath(’/div/*’) 选取div下的所有子节点
xpath(‘/div[@*]’) 选取所有带属性的div节点
多个路径的选取
表达式 结果
xpath(‘//div|//table’) 选取所有的div和table节点
代码
from lxml import etree
selector = etree.HTML(html_doc) ret = selector.xpath('//title/text()|//a/text()')
# ["The Dormouse's story", 'Elsie', 'Lacie', 'Tillie']
2.2 xpath轴
轴可以定义相对于当前节点的节点集
轴名称 表达式 描述
ancestor xpath(‘./ancestor::*’) 选取当前节点的所有先辈节点(父、祖父)
ancestor-or-self xpath(‘./ancestor-or-self::*’) 选取当前节点的所有先辈节点以及节点本身
attribute xpath(‘./attribute::*’) 选取当前节点的所有属性
child xpath(‘./child::*’) 返回当前节点的所有子节点
descendant xpath(‘./descendant::*’) 返回当前节点的所有后代节点(子节点、孙节点)
following xpath(‘./following::*’) 选取文档中当前节点结束标签后的所有节点
following-sibing xpath(‘./following-sibing::*’) 选取当前节点之后的兄弟节点
parent xpath(‘./parent::*’) 选取当前节点的父节点
preceding xpath(‘./preceding::*’) 选取文档中当前节点开始标签前的所有节点 preceding-sibling xpath(‘./preceding-sibling::*’) 选取当前节点之前的兄弟节点
self xpath(‘./self::*’) 选取当前节点
用法
ret = selector.xpath('//a/ancestor::*')
# [<Element html at 0x168a62717c8>, <Element body at 0x168a6271748>, <Element p at 0x168a6271708>]
ret = selector.xpath('//a/parent::*/text()')
# ['Once upon a time there were three little sisters; and their names were\n', ',\n', ' and\n',
# ';\nand they lived at the bottom of a well.']
ret = selector.xpath('//a/attribute::*')
# ['http://example.com/elsie', 'sister', 'link1', 'http://example.com/lacie', 'sister',
# 'link2', 'http://example.com/tillie', 'sister', 'link3']
2.3 功能函数
使用功能函数能够进行模糊搜索
函数 用法 解释
starts-with xpath(‘//div[starts-with(@id,”ma”)]‘) 选取id值以ma开头的div节点
contains xpath(‘//div[contains(@id,”ma”)]‘) 选取id值包含ma的div节点
and xpath(‘//div[contains(@id,”ma”) and contains(@id,”in”)]‘) 选取id值包含ma和in的div节点
text() xpath(‘//div[contains(text(),”ma”)]‘) 选取节点文本包含ma的div节点
用法
from lxml import etree
selector = etree.HTML(html_doc) # p标签class属性为story,在它下面的a标签id属性以link开头的文本信息
ret=selector.xpath("//p[@class='story']/a[starts-with(@id,'link')]/text()")
# ['Elsie', 'Lacie', 'Tillie'] # p标签class属性为story,在它下面的a标签id属性包含k的文本信息
ret=selector.xpath("//p[@class='story']/a[contains(@id,'k')]/text()")
# ['Elsie', 'Lacie', 'Tillie'] # p标签class属性为story,在它下面的a标签class属性包含is的文本信息
ret=selector.xpath("//p[@class='story']/a[contains(@class,'is')]/text()")
# ['Elsie', 'Lacie'] # 选取p标签class属性为story,在它下面的a标签文本信息包含ie的文本信息
ret=selector.xpath("//p[@class='story']/a[contains(text(),'ie')]/text()")
# ['Elsie', 'Lacie', 'Tillie']
更多介绍可以参考w3c
2.4 链家二手房信息地的抓取
打开链家网,选取我们需要的信息,点击右键在copy中点击copy xpath
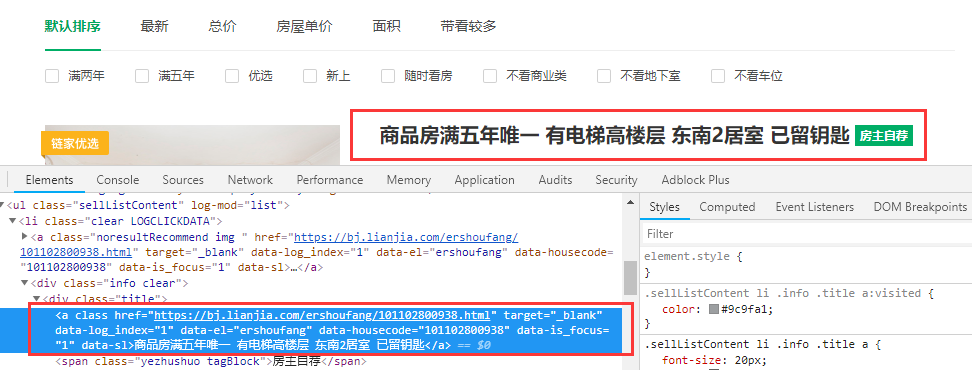
得到如下内容:
//*[@id="leftContent"]/ul/li[1]/div/div[1]/a
代码:
import requests
from lxml import etree response = requests.get("https://bj.lianjia.com/ershoufang/changping/pg1/",
headers={
'Referer':'https://bj.lianjia.com/ershoufang/changping/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3534.4 Safari/537.36',
}) selector=etree.HTML(response.content) # 将html源码转化为能被XPath匹配的格式 ret = selector.xpath("//*[@id='leftContent']/ul/li[1]/div/div[1]/a/text()")
print(ret) # ['商品房满五年唯一 有电梯高楼层 东南2居室 已留钥匙']
这里我们要获取首页所有该房源名称呢
ret = selector.xpath("//*[@id='leftContent']/ul/li[1]//div/div[1]/a/text()")
注意两个的区别,这里我们不考虑它的位置
3.总结
几种获取节点的库比较:
|
抓取方式 |
性能 |
使用难度 |
|
re正则 |
快 |
困难 |
|
BeautifulSoup |
慢 |
简单 |
|
Xpath |
快 |
快 |
通常情况下,lxml 是抓取数据的最好选择,它不仅速度快(结合谷歌浏览器),功能也更加丰富,而正则表达式和 Beautiful Soup只在某些特定场景下有用
爬虫之Beautifulsoup及xpath的更多相关文章
- 爬虫之 BeautifulSoup与Xpath
知识预览 BeautifulSoup xpath BeautifulSoup 一 简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: '' ...
- 爬虫模块BeautifulSoup
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html# 1.1 安装BeautifulSoup模块 ...
- Python爬虫教程-22-lxml-etree和xpath配合使用
Python爬虫教程-22-lxml-etree和xpath配合使用 lxml:python 的HTML/XML的解析器 官网文档:https://lxml.de/ 使用前,需要安装安 lxml 包 ...
- 爬虫解析库:XPath
XPath XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言.最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的 ...
- 使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解(新手必学)
为大家介绍下Python爬虫库BeautifulSoup遍历文档树并对标签进行操作的详细方法与函数下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最 ...
- Python爬虫之lxml-etree和xpath的结合使用
本篇文章给大家介绍的是Python爬虫之lxml-etree和xpath的结合使用(附案例),内容很详细,希望可以帮助到大家. lxml:python的HTML / XML的解析器 官网文档:http ...
- 爬虫——BeautifulSoup和Xpath
爬虫我们大概可以分为三部分:爬取——>解析——>存储 一 Beautiful Soup: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功 ...
- python爬虫之html解析Beautifulsoup和Xpath
Beautiifulsoup Beautiful Soup 是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据.BeautifulSoup 用来解析 HTML 比较简 ...
- Python爬虫利器三之Xpath语法与lxml库的用法
前面我们介绍了 BeautifulSoup 的用法,这个已经是非常强大的库了,不过还有一些比较流行的解析库,例如 lxml,使用的是 Xpath 语法,同样是效率比较高的解析方法.如果大家对 Beau ...
随机推荐
- window.open在Safari中不能打开的问题
在调移动支付问题的时候遇到过,用window.open打开一个微信支付链接,唤醒移动支付,在IOS下死活唤醒不了,是js代码冲突问题...是click事件IOS下不兼容问题...最后定位到window ...
- Javascript 多物体淡入淡出(透明度变化)
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- 【Udacity】误差原因——方差variance与偏差bias
偏差造成的误差-准确率和欠拟合 方差-精度和过拟合 Sklearn代码 理解bias &variance 在模型预测中,模型可能出现的误差来自两个主要来源,即:因模型无法表示基本数据的复杂度而 ...
- klee源码阅读笔记1--STPBuilder类
初始化过程中四个数据成员中的两个数据成员被初始化: 一.vc被初始化为STP提供的C调用接口函数vc_createValidityChecker(): 二.optimizeDivides被初始化为fa ...
- 生命不息学习不止,前端js学习笔记(一)
引言 从毕业到年已经整整7年,期间一直从事.net开发做c/s从 c# 转到 wpf 而后又开始做b/s 用silverlight,从最开始的arcgis engine 到后来的silverlight ...
- 微信小程序开发踩坑记
前言 微信小程序自去年公测以来,我司也申请了一个帐号开发,春节前后开始开发,现在终于告一个段落了.谨以此文记录下踩过的坑. 坑1:scroll-view与onPullDownRefresh冲突 由于有 ...
- Oracle基本命令(一)
1.create user username identified by password;//建用户名和密码oracle ,oracle 2.grant connect,resource,dba t ...
- python IO 文件读写
IO 由于CPU和内存的速度远远高于外设的速度,所以,在IO编程中,就存在速度严重不匹配的问题. 如要把100M的数据写入磁盘,CPU输出100M的数据只需要0.01秒,可是磁盘要接收这100M数据可 ...
- !important 语法
语法: Selector{sRule!important;} 说明: 提升指定样式规则的应用优先权. IE6及以下浏览器有个比较显式的支持问题存在,!important并不覆盖掉在同一条样式的后面的规 ...
- Python Json获取天气预报
#!/usr/bin/python # -*- coding: UTF-8 -*- import json import smtplib import urllib from email.mime.t ...