Hive学习笔记——Hive中的分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
按我的理解,所谓Hive中的分桶,实际就是指的MapReduce中的分区。根据Reduce的数量,分成不同个数的文件。
我们以一个demo进行说明。
创建分桶表
drop table stu_buck;
create table stu_buck(id int, name string, score double)
clustered by(id) into 4 buckets
row format delimited
fields terminated by ',';
设置变量,设置分桶为true, 设置reduce数量是分桶的数量个数
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
我们从另外一个表student查询数据放到该表中,student中的表数据如下:

开始往创建的分桶表插入数据(插入数据需要是已分桶, 且排序的)
可以使用distribute by(id) sort by(id asc)
排序和分桶的字段相同的时候也可以使用Cluster by(字段)
注意使用cluster by 就等同于分桶+排序(sort)
可以尝试以下几种方式:
insert into table stu_buck
select id,name,score from student distribute by(id) sort by(id asc); insert overwrite table stu_buck
select id,name,score from student distribute by(id) sort by(id asc); insert overwrite table stu_buck
select id,name,score from student cluster by(id); insert overwrite table stu_buck
select id,name,score from student cluster by(id) sort by(id); 报错,cluster 和 sort 不能共存
效果:

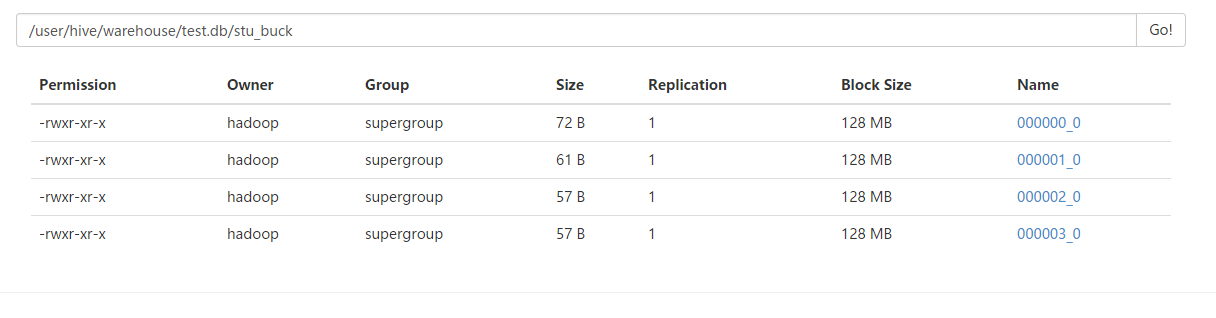
我们来查看以下文件的内容:
dfs -cat /user/hive/warehouse/test.db/stu_buck/000000_0;

dfs -cat /user/hive/warehouse/test.db/stu_buck/000001_0;

dfs -cat /user/hive/warehouse/test.db/stu_buck/000002_0;

dfs -cat /user/hive/warehouse/test.db/stu_buck/000003_0;

注:1、order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
2、sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
3、distribute by(字段)根据指定的字段将数据分到不同的reducer,且分发算法是hash散列。
4、Cluster by(字段) 除了具有Distribute by的功能外,还会对该字段进行排序。
5、创建分桶表并不意味着load进数据也是分桶的,你必须先分好桶,然后再放到表中。
因此,如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by
分桶表的作用:最大的作用是用来提高join操作的效率;但是两者的分桶数要相同或者成倍数。
为什么可以提高join操作的效率呢?因为按照MapReduce的分区算法,是Id的HashCode值模上ReduceTaskNumbers,所以一个ID会分到同一个桶中,这样合并就不用整个表遍历求笛卡尔积了,对应的桶合并就可以了。
Hive学习笔记——Hive中的分桶的更多相关文章
- hive学习笔记之五:分桶
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之一:基本数据类型
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之三:内部表和外部表
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之四:分区表
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之六:HiveQL基础
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之七:内置函数
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之九:基础UDF
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记-表操作
Hive数据类型 基本数据类型 tinyint,smallint,int,biging,float,double,decimal,char,varchar,string,binary,boolean, ...
- hive学习笔记之十:用户自定义聚合函数(UDAF)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<hive学习笔记>的第十 ...
随机推荐
- SVN配置常见错误
1.svnserve.conf:12: Option expected 为什么会出现这个错误呢,就是因为subversion读取配置文件svnserve.conf时,无法识别有前置空格的配置文件,如 ...
- Android布局基础
布局过程的含义 布局过程,就是程序在运行时利用布局文件的代码来计算出实际尺寸的过程. 布局过程的工作内容 两个阶段:测量阶段和布局阶段. 测量阶段:从上到下递归地调用每个 View 或者 ViewGr ...
- Android 网络请求框架Retrofit
Retrofit是Square公司开发的一款针对Android网络请求的框架,Retrofit2底层基于OkHttp实现的,OkHttp现在已经得到Google官方认可,大量的app都采用OkHttp ...
- 【试水CAS-4.0.3】第01节_CAS服务端搭建及导入源代码到MyEclipse
完整版见https://jadyer.github.io/2015/07/16/sso-cas-server-demo/ /** * @see ---------------------------- ...
- leetcode第一刷_Combination Sum Combination Sum II
啊啊啊啊.好怀念这样的用递归保存路径然后打印出来的题目啊.好久没遇到了. 分了两种,一种是能够反复使用数组中数字的,一种是每一个数字仅仅能用一次的.事实上没有多大差别,第一种每次进入递归的时候都要从头 ...
- 原来这是一个经典面试题-------Day61
前几天在table的操作中,记录了动态生成表格的三种方式: 1.html语言的拼接:用字符串或者数组拼接在html语言中,这个理解起来最直观 2.插入行和列:insertRow()和insertCel ...
- 【VBA编程】10.自定义集合
自定义集合类型,类似于变量声明,只是要将Dim关键字和New collection关键字搭配起来使用,其语法描述如下:其中集合名的命名方式同于标准变量的命名 Dim 集合名 As New collec ...
- Mysql 中 HAVING 和 USING 的使用
1. HAVING 在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用. 实例:现表Orders(订单)有如下字段: Id,Date,Price ,Customer ...
- Solr4.0使用
http://blog.sina.com.cn/s/blog_64dab14801013k7g.html Solr简介 Solr是一个非常流行的,高性能的开源企业级搜索引擎平台,属于Apache Lu ...
- gitlab8.0 一键安装 经过自己测试 发送邮件部分最难搞 国内没有说明白的
邮件发送部分,弄了一天终于弄好啦,FQ过去查的资料,奶奶的无语 Gitlab搭建步骤 一:操作系统环境 CentOS: 6.5 –x86-64 二:安装方式 一种是自定义安装,一种是一键安装 三:自定 ...