HDFS的HA机制
传统的HDFS机制如下图所示:
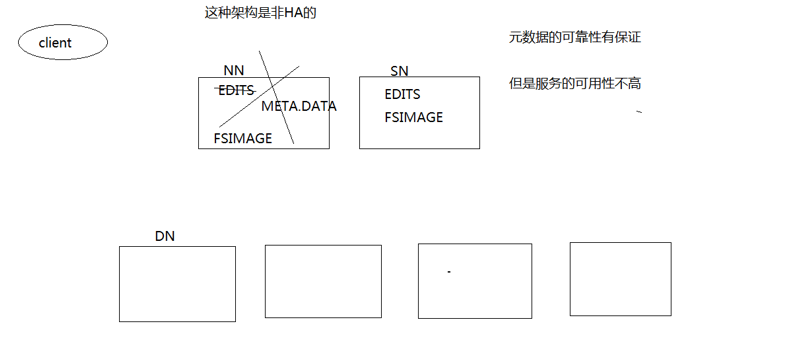
也就是存在一个NameNode,一个SecondaryNameNode,然后若干个DataNode。这样的机制虽然元数据的可靠性得到了保证(靠edits,fsimage,meta.data等文件),但是服务的可用性并不高,因为一旦NameNode出现问题,那么整个系统就陷入了瘫痪。所以,才引入了HDFS的HA机制。我们先来看一下关于HDFS的HA机制和Federation机制的简介:
HA解决了HDFS的NameNode的单点问题;
Federation解决了整个HDFS集群中只有一个名字空间,并且只有单独的一个NameNode管理所有DataNode的问题。
一、HA机制(High Availability)
1.HA集群
HDFS 的高可用性(HA, High Availability)是为了解决集群不可用的问题引入的,集群不可用主要是宕机、 NameNode 软硬件升级等导致的。 HA 机制通过提供选择运行在同一集群中的一个热备用的“主/备”两个冗余 NameNode ,使得在机器宕机或维护的过程中可以快速转移到另一个 NameNode。
典型的 HA 集群会配置两个独立机器为 NameNode ,分别为主 NameNode 和副本 NameNode 。正常情况下,主 NameNode 为 alive 状态而副本 NameNode 为休眠状态,活动 NameNode 负责处理集群中所有的客户端操作,待机时仅仅作为一个 slave ,保持足够的状态,如果有必要会提供一个快速的故障转移。
关于保持同步。为了保持备用节点与活动节点状态的同步,两个节点同时访问一个共享存储设备(例如从 NAS、NFS 挂载)到一个目录。
2.HA机制作用
HA 机制出现的作用主要是为了:
1.解决单点故障;
2.提升集群容量和集群性能。
二、Federation机制
为了防止单点失效(Single PointFailure),在 NameNode 只有命名空间的情况下。其最主要的原因是对 HDFS 系统的文件隔离,Federation 可以解决大部分单 NameNode HDFS 的问题。
总之,HDFSFederation就是使得HDFS支持多个命名空间,并且允许在HDFS中同时存在多个NameNode。
1.Federation架构
HDFS Federation使用多个独立的 NameNode / NameSpace 使得 HDFS 的命名服务能水平扩展,HDFS Federation中的 NameNode 之间为独立且不需要相互协调,Federation 中的 NameNode 提供了名字空间和块管理功能。Federation 中的 DataNode 被所有的 NameNode 用作公共存储块的地方。每个 DataNode 都会向所在集群中所有的 NameNode 注册,并且周期性发送心跳和块信息报告,同时处理来自 NameNode 的指令。
HDFS 只有一个名字空间 NameSpace 时,它使用全部的块,而 Federation HDFS 中有多个独立的NameSpace ,并且每个名字空间使用一个块池Block Pool(注:就是属于单个名字空间的一组 Block ),每个DataNode 为所有的块池存储块,DataNode是个物理概念,而块池是另一个重新将块划分的逻辑概念。
HDFS 中只有一组块。而Federation HDFS中有多组独立的块,块池就是属于同一个名字空间的一组块。
HDFS 由一个 NameNode 和一组 DataNode 组成,而 Federation HDFS 由多个 NameNode 和一组 DataNode 组成,每个 DataNode 会为多个块池存储块。同一个 DataNode 中可以存着属于多个块池的多个块。块池允许一个名字空间在不通知其他名字空间的情况下为一个新的 Block 创建 Block ID ,同时一个 NameNode 失效不会影响其下的 DataNode 为其他的 NameNode 服务。
在 HDFS 中,所有的更新、回滚都是以 NameNode 和 Block Pool 为单元发生的,即同 HDFS Federation 中不同的 NameNode/Block Pool 之间没有什么关系。
在 DataNode 中,对应于每个 NameNode 都有一个相应的线程。每个 DataNode 会去每个 NameNode 注册,并周期性地给所有的 NameNode 发送心跳和使用报告,DataNode 还会给 NameNode 发送其所在的块池报告 block report,由于有多个 NameNode 同时存在,因此任何一个 NameNode 都可以随时动态加入、删除和更新。
2.多名字空间管理
在一个集群中需要唯一的名字空间还是多个名字空间,核心问题是名字空间中数据的共享和访问的问题。解决数据共享和访问的一种方法:使用全局唯一的名字空间,在多个名字空间下,还可以使用 Client Side Mount Table 方式做到数据共享和访问。
HDFS Federation 名字空间管理基本原理:将各个名字空间挂载到全局 mount-table 中,就可以将数据到全局共享;同样,名字空间挂载到个人 mount-table 中,就成为应用程序可见的名字空间视图。
而HA架构图如下图所示:


我们需要两台NameNode,那么我们就需要保证信息的同步,因为前面介绍HDFS时讲过,edits日志里面总是存储最新的数据,所以我们就让edits共享,两台NameNode每次都往同一个edits里面进行读写。但是只有一个edits,难免会出问题,所以我们就同时有多个edits,并把他们部署到集群上。多个,又部署到集群上,肯定会涉及数据同步,切换等多个问题,这不就是之前我们讨论的Zookeeper问题吗?所以我们做了一个分布式应用qjournal,并用它管理这么多edits,每个edits又叫做journalnode。qjournal底层是基于Zookeeper实现的,所以journalnode只要有半数以上的节点活着,qjournal就不会瘫痪。
两台NameNode不能同时处于active状态,一台处于active状态,另外一台就必须是standby状态。当一台NameNode死了,另外一台就会变成active状态了。但是两台NameNode之间的切换是怎么保证的呢?
这里开了两个进程,时时刻刻监控本地NameNode的状态。当前active状态的NameNode的进程如果发现不正常,就往zookeeper里面写一些数据。另外一个进程时时刻刻从zookeeper里面读数据,来随时掌握
对方NameNode的状态,如果发现对方死了,就可以进行NameNode的切换,这个状态管理的进程就叫做zkfc。用来做两个NameNode的切换管理,包括失败切换。具体功能依赖于zookeeper实现。
这里还有一个问题,就是brain split:
所谓brain split,就是一台NameNode出现假死,而另外一台NameNode以为它真死了,所以也变成active了,等一下假死的NameNode恢复了,这样就会两台NameNode都处于active状态,显然这是不可以的。
我们有两个解决办法:
1.ssh发送kill指令,直接杀死对方NameNode进程,再进行切换。
2.ssh指令不能保证每次都执行成功,那就设置一个时间,如果一定时间ssh指令还没有返回值,就会运行自定义的脚本,将对方NameNode杀死,再进行切换。
这种解决的机制叫做fencing机制。
我们将上面一对NameNode叫做一个nameservice,访问它可以用ns1(name service 1)来表示。若干个这样的NameNode对叫做Federation。
这里需要提醒一下:不光HDFS有高可用,YARN也有高可用,只不过相对HDFS就简单多了,ResourceManager主从切换即可。
最后,介绍一下namenode的安全模式:

HDFS的HA机制的更多相关文章
- 【Hadoop】HDFS笔记(二):HDFS的HA机制和Federation机制
HA解决了HDFS的NameNode的单点问题: Federation解决了整个HDFS集群中只有一个名字空间,并且只有单独的一个NameNode管理所有DataNode的问题. 一.HA机制(Hig ...
- HDFS之HA机制
- Hadoop_HDFS架构和HA机制
Hadoop学习笔记总结 01.HDFS架构 1. NameNode和ResourceManager NameNode负责HDFS,从节点是DataNode:ResourceManager负责MapR ...
- HA机制下的Hadoop配置
[版权申明:本文系作者原创,转载请注明出处] 文章出处:http://www.cnblogs.com/sdksdk0/p/5585355.html 作者: 朱培 ID:sdksdk0 ----- ...
- Hadoop的HA机制
前言:正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 1. HA的运作机制 (1)hadoop-HA集群运作机制介绍 所谓HA,即高可用(7*24小时不中断服务) 实现高可用最关 ...
- 使用QJM实现HDFS的HA配置
使用QJM实现HDFS的HA配置 1.背景 hadoop 2.0.0之前,namenode存在单点故障问题(SPOF,single point of failure),如果主机或进程不可用时,整个集群 ...
- HDFS的HA(高可用)
HDFS的HA(高可用) 概述 (1)实现高可用最关键的策略是[消除单点故障].HA 严格来说应该分成各个组件的 HA 机制:HDFS 的 HA 和 YARN 的 HA. (2)Hadoop2.0 之 ...
- Hdfs的HA高可用
1.Hdfs的HA高可用:保证Hdfs高可用,其实就是保证namenode的高可用,保证namenode的高可用的机制有两个,editlog共享机制+ZKFC.ZKFC就是ZookeeperFailO ...
- 大数据谢列3:Hdfs的HA实现
在之前的文章:大数据系列:一文初识Hdfs , 大数据系列2:Hdfs的读写操作 中Hdfs的组成.读写有简单的介绍. 在里面介绍Secondary NameNode和Hdfs读写的流程. 并且在文章 ...
随机推荐
- scrapy-splash抓取动态数据例子六
一.介绍 本例子用scrapy-splash抓取中广互联网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- 【笔记】关于jq $.ajax 函数 success回调函数不能赋正确值或返回正确值的问题
最近在一个项目里面打算实现如下功能: 当我注册账号的时候当输入账号完毕后输入框失焦时执行一个 ajax 请求,验证账号是否被注册,并未这个输入框的 isCorrect属性赋值,如果没有被注册 isCo ...
- Android 5.0 怎样正确启用isLoggable(一)__使用具体解释
isLoggable是什么 在Android源代码中,我们常常能够看到例如以下代码: //packages/apps/InCallUI/src/com/android/incallui/Log.jav ...
- 云计算之路-阿里云上:SLB故障引发的网站不能正常访问
2013年8月22日23:50~23:58左右,由于阿里云SLB(负载均衡)故障造成网站不能正常访问,给大家带来了麻烦,望大家谅解! 8月19日我们收到阿里云的短信通知: 尊敬的阿里云用户: ...
- 浅析SQL Server中的执行计划缓存(上)
简介 我们平时所写的SQL语句本质只是获取数据的逻辑,而不是获取数据的物理路径.当我们写的SQL语句传到SQL Server的时候,查询分析器会将语句依次进行解析(Parse).绑定(Bind).查询 ...
- 使用 ssh 从 Gerrit 获取 patch 信息
使用命令行(ssh)对Gerrit进行查询, 官方地址:https://review.openstack.org/Documentation/cmd-query.html 程序例子 import os ...
- 【转】java与C++的区别
转自:http://club.topsage.com/thread-265349-1-1.html Java并不仅仅是C++语言的一个变种,它们在某些本质问题上有根本的不同: (1)Java比C++程 ...
- 二维纹理 Texture 2D
Textures bring your Meshes, Particles, and interfaces to life! They are image or movie files that yo ...
- java String->float,float->int
类型转换代码 : String sourceStr = "0.0"; String类型 float sourceF = Float.valueOf(sourceStr); floa ...
- 【Python3 爬虫】17_爬取天气信息
需求说明 到网站http://lishi.tianqi.com/kunming/201802.html可以看到昆明2018年2月份的天气信息,然后将数据存储到数据库. 实现代码 #-*-coding: ...