【转】 GRASP(通用职责分配软件模式)模式
转自:http://www.cnblogs.com/sevenyuan/archive/2010/03/05/1678730.html
及:http://blog.csdn.net/lovelion
及:http://blog.sohu.com/s/Mzc2Nzc5MjU/239020230.html
在OO分析与设计中,我们首先从问题领域中抽象出领域模型,在领域模型中以适当的粒度归纳出相关的类;然后定义各个类之间的关联关系,并给这些类分配相应的职责,同时定义这些类之间的协作方式。将相应的职责分配给具体的类是OO过程中非常重要的一步。GRASP设计模式是职责分配过程中的一套非常重要的设计模式。它给出了在给类分配职责的过程中,设计者们所需要遵从的一些原则或者指导性的建议。
说到设计模式,更为人所知的当然是GoF(Gang of Four)的23种设计模式。与GoF的23种设计模式不同的是,GRASP设计模式描述的是在OO设计中为互相协作的类分配职责的原则或者建议,而GoF的设计模式则是在更高的层次上描述一个OO系统或者其局部系统的行为以及结构上的抽象。
要学习设计模式,有些基础知识是我们必须要先知道的,设计模式是关于类和对象的一种高效、灵活的使用方式,也就是说,必须先有类和对象,才能有设计模式的用武之地,否则一切都是空谈,那么类和对象是从那冒出来的呢?这时就需要比23种设计模式更重要更经典的GRASP模式登场了,嘿嘿,原来这才是老大!
GRASP(General Responsibility Assignment Software Patterns),中文名称为“通用职责分配软件模式”,它由《UML和模式应用》(Applying UML and Patterns)一书作者Craig Larman提出。与其将它们称之为设计模式,不如称之为设计原则,因为它是站在面向对象设计的角度,告诉我们怎样设计问题空间中的类与分配它们的行为职责,以及明确类之间的相互关系等,而不像GoF模式一样是针对特定问题而提出的解决方案。因此GRASP站在一个更高的角度来看待面向对象软件的设计,它是GoF设计模式的基础。GRASP是对象职责分配的基本原则,其核心思想是职责分配(Responsibility Assignment),用职责设计对象(Designing Objects with Responsibilities)。GRASP一共包括9种模式,它们描述了对象设计和职责分配的基本原则。也就是说,如何把现实世界的业务功能抽象成对象,如何决定一个系统有多少对象,每个对象都包括什么职责,GRASP模式给出了最基本的指导原则。初学者应该尽快掌握、理解这些原则,因为这是如何设计一个面向对象系统的基础。可以说,GRASP是学习使用设计模式的基础。
1. Information Expert Pattern(信息专家模式)
信息专家模式是面向对象设计的最基本原则,是我们平时使用最多,应该跟我们的思想融为一体的原则。也就是说,我们设计对象(类)的时候,如果某个类拥有完成某个职责所需要的所有信息,那么这个职责就应该分配给这个类来实现。这时,这个类就是相对于这个职责的信息专家。
可参考如下理解:
(1) 问题:给对象分配职责的通用原则是什么?
(2) 解决方案:将职责分配给拥有履行一个职责所必需信息的类,即信息专家。
(3) 分析:信息专家模式是面向对象设计的最基本原则。通俗点来讲,就是一个类只干该干的事情,不该干的事情不干。在系统设计时,需要将职责分配给具有实现这个职责所需要信息的类。信息专家模式对应于面向对象设计原则中的单一职责原则。
信息专家模式关注这样一个问题:给对象分配职责的基本原则是什么?
在一个OO系统中可能会定义成百上千个软件类,而所有这些类必须履行的职责的数量之和甚至更多。如果能很好地给所有这些类分配好职责,那么这个系统就会易于理解、维护和扩展。信息专家模式关于这个问题给出的答案是:把职责分配给信息专家,它具有实现这个职责所必需的信息。
这一设计模式理解起来非常简单,它并不是某种深度认证的结论,而更像是一种直觉,即对象完成与它所具有的信息相关的那些职责。有许多例子都能说明这一点,其中最常见的包括各种GUI库的绘图函数。比如iOS的UIKit框架中的layoutSubviews方法、wxWidgets库中的OnPaint方法、MFC框架中的OnPaint方法、Swing库中的paint/updata/repaint方法,等等。这些方法都是将GUI界面的绘制功能分配到了每一个具体的视图类中,无论是库/框架中已经存在的具体视图,或者是用户自定义的具体视图。因为只有这些具体的视图类才拥有绘制自身所必需的信息,它们能很好地履行绘制自身的这一职责。这是信息专家模式的一个直接应用。
在信息专家模式给出的建议中,由于对象可以使用自身的信息来完成它的职责,因此信息的封装性得以维护,从而支持了低耦合;同时,由于类的职责都根据自身所拥有的信息来分配,因而该模式也支持高内聚的设计。
当然,在某些特殊的情况下,信息专家模式也许并不适用,这通常是由于内聚与耦合的问题所产生的。比如许多后台系统都有把模型(Model)类的数据存入数据库的功能。这一职责的履行所必需的信息显然是存在于各个模型类中,按照信息专家模式给出的建议,应该让这些模型类来完成把自身的数据保存到数据库中的功能。但是,这样的设计会导致内聚与耦合方面的问题。首先,在这样的设计中,所有的模型类都必须包含与数据库处理相关的逻辑,如与JDBC相关的处理逻辑。这使得模型类由于其他职责的存在而降低了它的内聚。其次,这样的设计也为所有的模型类都引入了与JDBC的耦合关系,使得系统的耦合度上升。甚至,这种设计也会导致大量重复、冗余的数据库逻辑存在于整个系统中的各个角落,这也违反了设计要分离主要的系统关注的基本架构原则。因此,在这种情况下,信息专家模式需要我们结合整个系统的耦合和内聚做出另外的考虑。
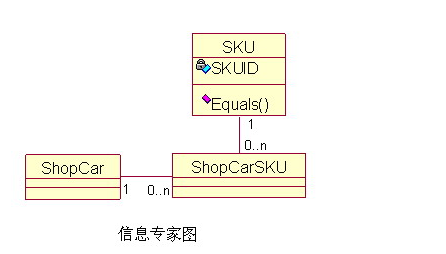
例如:常见的网上商店里的购物车(ShopCar),需要让每种商品(SKU)只在购物车内出现一次,购买相同商品,只需要更新商品的数量即可。(SKUID)来唯一区分商品,而商品编号是唯一存在于商品类里的,所以根据信息专家模式,应该把比较商品是否相同的方法放在商品类里。
2. Creator Pattern(创造者模式)
实际应用中,符合下列任一条件的时候,都应该由类A来创建类B,这时A是B的创建者:
a. A是B的聚合
b. A是B的容器
c. A持有初始化B的信息(数据)
d. A记录B的实例
e. A频繁使用B
如果一个类创建了另一个类,那么这两个类之间就有了耦合,也可以说产生了依赖关系。依赖或耦合本身是没有错误的,但是它们带来的问题就是在以后的维护中会产生连锁反应,而必要的耦合是逃不掉的,我们能做的就是正确地创建耦合关系,不要随便建立类之间的依赖关系,那么该如何去做呢?就是要遵守创建者模式规定的基本原则,凡是不符合以上条件的情况,都不能随便用A创建B。
可参考以下的理解:
(1) 问题:谁应该负责产生类的实例?
(2) 解决方案:如果符合下面的一个或者多个条件,则可将创建类A实例的职责分配给类B:
B包含A;
B聚合A;
B拥有初始化A的数据并在创建类A的实例时将数据传递给类A;
B记录A的实例;
B频繁使用A。
此时,我们称类B是类A对象的创建者。如果符合多个条件,类B聚合或者包含类A的条件优先。
(3) 分析:创建对象是面向对象系统中最普遍的活动之一,因此,确定一个分配创建对象的通用职责非常重要。如果职责分配合理,设计就能降低耦合,提高设计的清晰度、封装性和重用性。通常情况下,如果对象的创建过程不是很复杂,则根据上述原则,由使用对象的类来创建对象。但是如果创建过程非常复杂,而且可能需要重复使用对象实例或者需要从外部注入一个对象实例,此时,可以委托一个专门的工厂类来辅助创建对象。创建者模式与各种工厂模式(简单工厂模式、工厂方法模式和抽象工厂模式)相对应。
创建者模式关注这样一个问题:假设系统中存在一个类A,那么在这个系统中,谁应该负责创建类A的新实例?
创建类的实例是面向对象的系统中最常见的活动之一。合理分配类的创建职责的设计能够支持低耦合,提高封装性、可复用性、可扩展性。创建者模式为这一活动给出的指导性的建议是,将创建类A的新实例的职责分配给类B,如果以下条件成立:
l B“包含”或组成聚集A。
l B记录A。
l B直接使用A。
l B具有A的初始化数据,并且在创建A的实例时会将这些数据传递给A。
这些条件成立得越多越好。如果有一个以上的条件成立,那么通常首选聚集或包含A的类B。
举一个非常简单的例子。假设系统中存在链表类和节点类。一个链表类的对象包含了多个节点的对象,链表类的用户(这里的用户不是指现实世界中的人,而是指使用链表类的代码)可以向一个链表类的对象插入一个新的节点。那么,被插入的新的节点对象应该由谁来创建?显然,链表类的用户本身是一个创建者的候选者,因为用户本身拥有节点对象的初始化数据,由用户创建节点对象是可以实现的。然而,根据创建者模式,链表类却是一个更好的选择。因为链表类包含了节点,并直接使用、操作节点。由链表类本身创建节点可以消除链表类的用户对于节点类的依赖关系,从而消除了用户代码与节点类的耦合,使系统中仅剩下用户代码与链表类的耦合。这形成了一个良好的设计。
使用创建者模式的好处是不会增加系统的耦合度,因为根据创建者模式的建议,类的实例的创建者已经与这个类存在着某种形式的耦合。因此该模式支持低耦合的设计,能产生具有较低的维护依赖性与较高的复用性的系统。
在一个设计灵活的OO系统中,对象的创建方式往往非常复杂。比如,有些系统需要为了更好的性能而集中创建或者使用回收的实例(线程池、连接池、对象池等);有些系统需要根据某些条件来创建一族类的实例;甚至有些框架系统在框架的编写过程中根本不知道需要实例化哪一个类,等等。在这些情况下,最好的方法是将创建类的实例的职责委派给抽象工厂(Abstract Factory)、具体工厂(ConcreteFactory)、创建器(Builder)等等辅助类,而不是创建者模式所建议的类。
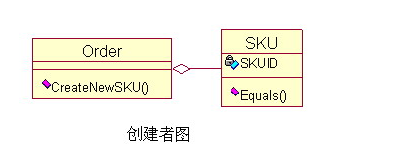
例如:因为订单(Order)是商品(SKU)的容器,所以应该由订单来创建商品。
3. Low coupling Pattern(低耦合模式)
低耦合模式的意思就是要我们尽可能地减少类之间的连接。
其作用非常重要:
a. 低耦合降低了因一个类的变化而影响其他类的范围。
b. 低耦合使类更容易理解,因为类会变得简单,更内聚。
下面这些情况会造成类A、B之间的耦合:
a. A是B的属性
b. A调用B的实例的方法
c. A的方法中引用了B,例如B是A方法的返回值或参数。
d. A是B的子类,或者A实现了B
关于低耦合,还有下面一些基本原则:
a. Don’t Talk to Strangers原则:
意思就是说,不需要通信的两个对象之间,不要进行无谓的连接,连接了就有可能产生问题,不连接就一了百了啦!
b. 如果A已经和B有连接,如果分配A的职责给B不合适的话(违反信息专家模式),那么就把B的职责分配给A。
c. 两个不同模块的内部类之间不能直接连接,否则必招报应!嘿!
可参考如下理解:
(1) 问题:怎样支持低的依赖性,减少变更带来的影响,提高重用性?
(2) 解决方案:分配一个职责,使得保持低耦合度。
(3) 分析:耦合是评价一个系统中各个元素之间连接或依赖强弱关系的尺度,具有低耦合的元素不过多依赖其他元素。此处的元素可以是类,也可以是模块、子系统或者系统。具有高耦合的类过多地依赖其他类,这种设计将会导致:一个类的修改导致其他类产生较大影响;系统难以维护和理解;系统重用性差,在重用一个高耦合的类时不得不重用它所依赖的其他类。因此需要对高耦合的系统进行重构。
类A和类B之间的耦合关系体现如下:A具有一个B类型的属性;A调用B的方法;A的方法包含对B的引用,如方法参数类型为B或返回类型为B;A是B的直接或者间接子类;B是一个接口,A实现了该接口。低耦合模式鼓励在进行职责分配时不增加耦合性,从而避免高耦合可能产生的不良后果。在进行类设计时,需要保持类的独立性,减少类变更所带来的影响,它通常与信息专家模式和高内聚模式一起出现。为了达到低耦合,我们可以通过如下方式对设计进行改进:
在类的划分上,应当尽量创建松耦合的类,类之间的耦合度越低,就越有利于复用,一个处在松耦合中的类一旦被修改,不会对关联的类造成太大波及;
在类的设计上,每一个类都应当尽量降低其成员变量和成员函数的访问权限;
在类的设计上,只要有可能,一个类型应当设计成不变类;
在对其他类的引用上,一个对象对其他对象的引用应当降到最低。
低耦合模式关注这样一个问题:怎样降低依赖性,减少变化带来的影响,提高重用性?
低耦合模式关于这个问题给出的答案是:分配职责,使耦合度尽可能低。
耦合是系统设计中最重要的概念之一,也是设计中真正的基本原则之一。所谓耦合,指的是对某元素与其他元素之间的连接、感知和依赖程度的度量。在一个OO系统中,所有的耦合形式可分为5类:
l 零耦合(nil coupling):两个类丝毫不依赖于对方。
l 导出耦合(export coupling):一个类依赖于另一个类的公有接口。
l 授权耦合(overt coupling):一个类经允许,使用另一个类的实现细节。
l 自行耦合(covert coupling):一个类未经允许,使用另一个类的实现细节。
l 暗中耦合(surreptitious coupling):一个类通过某种方式知道了另一个类的实现细节。
零耦合当然是耦合度最低的。两个丝毫互不依赖的类,意味着在维护和扩展系统时,可以随意地去掉或者修改其中的一个类而丝毫不会影响到另一个类。但是,只使用零耦合却无法创建出一个有意义的OO系统,因为所有的类都是独立、不相关的,相互之间没有消息的传递,这样最多只能创建出一个类库。导出耦合具有相当低的耦合度,因为在导出耦合中,一个类只依赖另一个类的公有接口。在一个设计良好的系统中,消息的传递只会通过类的公有接口进行,因而导出耦合可以很好地支持系统的可维护性与可扩展性。除此之外,授权耦合、自行耦合、以及暗中耦合都是耦合程度比较高的耦合形式。
有这样一条OO设计的经验原则:类与类之间应该零耦合,或者只有导出耦合关系。也即,一个类要么同另一个类毫无关系,要么就只使用另一个类提供的公有接口。授权耦合、自行耦合、暗中耦合基本上不应该在系统中被使用到。
类A到类B或接口B的常见的导出耦合形式有:
l A具有引用B的实例或B自身的属性。
l A的实例调用B的实例的服务。
l A具有以任何形式引用B的实例或B自身的方法。
l A是B的直接或间接子类。
l B是接口,而A是此接口的实现。
低耦合模式提倡职责分配要避免产生具有负面影响的高耦合。低耦合模式支持在设计时降低类的依赖性,减少变化所带来的影响。比如在通常情况下,系统往往能以使用关系来替换继承关系,因为继承关系是一种耦合程度非常高的强耦合形式,而使用关系能降低耦合度。
当然,没有绝对的度量标准来衡量耦合程度的高低。使用低耦合模式的目的是为了创建一个可灵活伸缩的、可维护的、可扩展的系统。在这个目的之下,低耦合不能脱离信息专家和高内聚等其他模式孤立地考虑,而是应该同时权衡耦合与内聚。高耦合本身也并不是问题之所在,问题是与某些方面不稳定的元素之间的高耦合,这种高耦合会严重影响系统将来的维护性和扩展性。而比如所有的Java系统都能安全地将自己去Java库(java.lang,java.util等)进行耦合,因为Java库是稳定的,与Java库的耦合不会给系统的灵活性、维护性、扩展性带来什么问题。
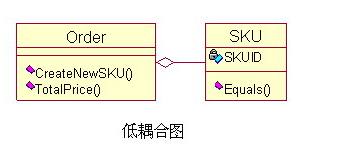
例如:Creator模式的例子里,实际业务中需要另一个出货人来清点订单(Order)上的商品(SKU),并计算出商品的总价,但是由于订单和商品之间的耦合已经存在了,那么把这个职责分配给订单更合适,这样可以降低耦合,以便降低系统的复杂性。TotalPrice()方法来执行计算总价的职责,没有增加不必要的耦合。
4. High cohesion Pattern(高内聚模式)
高内聚的意思是给类尽量分配内聚的职责,也可以说成是功能性内聚的职责。即功能性紧密相关的职责应该放在一个类里,并共同完成有限的功能,那么就是高内聚合。这样更有利于类的理解和重用,也便于类的维护。
高内聚也可以说是一种隔离,就想人体由很多独立的细胞组成,大厦由很多砖头、钢筋、混凝土组成,每一个部分(类)都有自己独立的职责和特性,每一个部分内部发生了问题,也不会影响其他部分,因为高内聚的对象之间是隔离开的。
可参考如下理解:
(1) 问题:怎样使得复杂性可管理?
(2) 解决方案:分配一个职责,使得保持高内聚。
(3) 分析:内聚是评价一个元素的职责被关联和关注强弱的尺度。如果一个元素具有很多紧密相关的职责,而且只完成有限的功能,则这个元素就具有高内聚性。此处的元素可以是类,也可以是模块、子系统或者系统。
在一个低内聚的类中会执行很多互不相关的操作,这将导致系统难于理解、难于重用、难于维护、过于脆弱,容易受到变化带来的影响。因此我们需要控制类的粒度,在分配类的职责时使其内聚保持为最高,提高类的重用性,控制类设计的复杂程度。为了达到低内聚,我们需要对类进行分解,使得分解出来的类具有独立的职责,满足单一职责原则。在一个类中只保留一组相关的属性和方法,将一些需要在多个类中重用的属性和方法或完成其他功能所需的属性和方法封装在其他类中。类只处理与之相关的功能,它将与其他类协作完成复杂的任务。
高内聚模式关注这样一个问题:怎样保持对象是有重点的、可理解的、可管理的,并且能够支持低耦合?
高内聚模式关于这个问题给出的答案是:分配职责,使其可保持较高的内聚性。
同耦合一样,内聚也是系统设计中最重要的概念之一,也是设计中真正的基本原则之一。所谓内聚(内聚有多种类型,包括偶然内聚、逻辑内聚、时间内聚、通信内聚、顺序内聚、功能内聚、信息内聚等,这里主要指的是功能内聚),是对元素(包括类、子系统等)职责的相关性和集中度的度量。如果元素具有高度相关的职责,而且没有过多工作,那么该元素具有高内聚性。
高内聚的类的方法数量较少,在功能性上有非常强的关联,而且不需要做太多的工作。如果任务的规模比较大的话,应该将任务所涉及到的各项职责按照关联的强度分配到各个类中,然后让各个类的对象进行相互协作,共同完成这项任务。高内聚的类优势明显,它易于理解、维护和复用。高度相关的功能性与少量操作相结合,也可以简化维护和改进的工作。细粒度的、高度相关的功能性也可以提高复用的潜力。
以信息专家模式一节中最后一段中所举的例子来说,如果按照信息专家给出的建议,把与数据库进行交互的职责都放进模型类中,那么这样的模型类显然做了过多的工作。这是一种不好的低内聚设计。从数据的角度来讲,内聚程度低的模型类由于加入了数据库操作职责,它需要在一个对象中同时维护两大块数据,一块是模型本身的数据,另一块则是数据库操作需要用到的数据。用于进行数据库操作的数据显然会在各个模型类的对象中形成冗余。从功能的角度来讲,数据库操作功能的加入直接导致了模型类中包含了两种截然不同的功能和逻辑,这使得模型类更加难以理解、复用和维护。这样的设计是十分脆弱的,会经常容易受到变化的影响。而一个高内聚的设计则是将数据库相关逻辑从模型类中移除,放入专门的对象或者子系统中。这样,模型类自身便能拥有更高的内聚度,它们所包含的功能容易被人理解;同时,在面向接口的良好设计中,模型类也更加容易被维护以及扩展。
在实践中,高内聚模式也不能脱离其他模式(如信息专家和低耦合)单独地考虑。高内聚与低耦合是在整个系统的设计过程中,需要不断地去考虑和评估的基本原则。
在少数情况下,较低的内聚也是被接受的。比如,为了方便专门的数据库逻辑人员统一管理SQL语句,系统中往往可以将与SQL语句相关的操作都放在一个独立的全能类中;另外,出于性能的考虑,在RPC中使用一个粗粒度的RPC服务器类,既可以减少服务器上对象的数目,可以减少网络请求和连接的数目,从而提高系统的性能。这些,都需要从系统的全局出发,结合多种设计的原则进行权衡考虑。
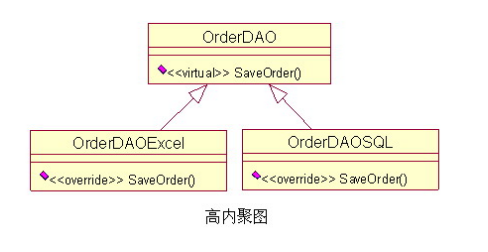
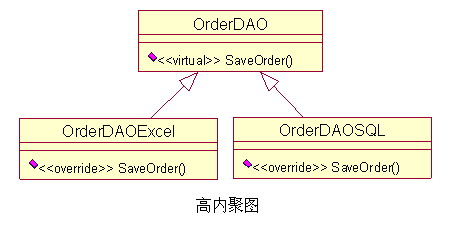
例如:一个订单数据存取类(OrderDAO),订单即可以保存为Excel模式,也可以保存到数据库中;那么,不同的职责最好由不同的类来实现,这样才是高内聚的设计,Excel的功能发生错误,那么就去检查OrderDAOExcel类就可以了,这样也使系统更模块化,方便划分任务,比如这两个类就可以分配个不同的人同时进行开发,这样也提高了团队协作和开发进度。
5. Controller Pattern(控制器模式)
用来接收和处理系统事件的职责,一般应该分配给一个能够代表整个系统的类,这样的类通常被命名为“XX处理器”、“XX协调器”或者“XX会话”。
关于控制器类,有如下原则:
a. 系统事件的接收与处理通常由一个高级类来代替。
b. 一个子系统会有很多控制器类,分别处理不同的事务。
关于这个模式更详细的论述,请参考《UML和模式应用》第16章。
可参考如下理解:
(1) 问题:谁应该负责处理一个输入系统事件?
(2) 解决方案:把接收或者处理系统事件消息的职责分配给一个类。这个类可以代表:
整个系统、设备或者子系统;
系统事件发生时对应的用例场景,在相同的用例场景中使用相同的控制器来处理所有的系统事件。
(3) 分析:一个控制器是负责接收或者处理系统事件的非图形用户界面对象。一个控制器定义一组系统操作方法。在控制器模式中,要求系统事件的接收与处理通常由一个高级类来代替;一个子系统需要定义多个控制器,分别对应不同的事务处理。通常,一个控制器应当把要完成的功能委托给其他对象,它只负责协调和控制,本身不完成太多的功能。它可以将用户界面所提交的请求转发给其他类来处理,控制器可以重用,且不能包含太多业务逻辑,一个系统通常也不能设计一个统一的控制器。控制器模式与MVC模式相对应,MVC是一种比设计模式更加高级的架构模式。
控制器模式关注这样一个问题:在UI层之上首先接收和协调(控制)系统操作的第一个对象是什么?
系统操作就是系统中的主要输入事件,比如按钮的点击、文字的输入等。控制器模式对于这个问题的回答是:使用控制器作为UI层之上的第一个对象,它负责接收和处理系统操作消息。而控制器是能代表以下选择之一的类:
l 代表整个“系统”、“根对象”、运行软件的设备或主要子系统,这些是外观控制器的变体。
l 代表用例场景,在该场景中发生系统事件,通常命名为<UseCaseName>Handler、<UseCaseName>Coordinator或<UseCaseName>Session。
在系统中,诸如“窗口”(Windows)、“视图”(View)或“文档”(Document)之类的类主要负责显示的功能,并不属于控制器。这些类不应该完成与系统事件相关的任务。通常情况下,它们接收这些事件,并将其委派给控制器,即委派模式。
例如,在iPhone应用程序的开发框架UIKit中,许多继承自UIView类的具体视图类都具有一个叫做delegate的属性。其中包括UIScrollView类,它表示一个滚动视图,添加到其中的子视图的尺寸可以超过滚动视图自身的尺寸,并在滚动视图中进行滚动显示。而所有UIScrollView类的实例都可以指定一个委派delegate,其类型是UIScrollViewDelegate(接口)。用户可以自行实现UIScrollViewDelegate这个接口,定义好处理各类事件的方法,比如滚动开始事件、滚动结束事件等等。当UIScrollView类的实例接收到系统操作之后,该实例会将这些操作委派给用户指定的delegate进行处理,即该delegate中相应的处理方法会得到调用。
控制器设计中的常见缺陷是分配的职责过多。这时,控制器会具有不好的低内聚。因而存在这样一条准则:正常情况下,控制器应当把需要完成的工作委派给其他的对象。控制器只是协调或控制这些活动,本身并不完成大量工作。
6. Polymorphism (多态)
这里的多态跟OO三大基本特征之一的“多态”是一个意思。
可参考如下理解:
(1) 问题:如何处理基于类型的不同选择?如何创建可嵌入的软件组件?
(2) 解决方案:当相关选择或行为随类型(类)变化而变化时,用多态操作为行为变化的类型分配职责。
(3) 分析:由条件变化引发同一类型的不同行为是程序的一个基本主题。如果用if-else或switch-case等条件语句来设计程序,当系统发生变化时必须修改程序的业务逻辑,这将导致很难方便地扩展有新变化的程序。另外对于服务器/客户端结构中的可视化组件,有时候需要在不影响客户端的前提下,将服务器的一个组件替换成另一个组件。此时可以使用多态来实现,将不同的行为指定给不同的子类,多态是设计系统如何处理相似变化的基本方法,基于多态分配职责的设计可以方便地处理新的变化。在使用多态模式进行设计时,如果需要对父类的行为进行修改,可以通过其子类来实现,不同子类可以提供不同的实现方式,将具体的职责分配给指定的子类。新的子类增加到系统中也不会对其他类有任何影响,多态是面向对象的三大基本特性之一(另外两个分别是封装和继承),通过引入多态,子类对象可以覆盖父类对象的行为,更好地适应变化,使变化点能够“经得起未来验证”。多态模式在多个GoF设计模式中都有所体现,如适配器模式、命令模式、组合模式、观察者模式、策略模式等等。
多态性模式关注这样一个问题:如何处理基于类型的选择?如何创建可插拔的软件构件?
关于这个问题,多态性模式给出的答案是:当相关选择或行为随类型(类)有所不同时,使用多态操作为变化的行为类型分配职责。不要测试对象的类型,也不要使用条件逻辑来执行基于类型的不同选择。
例如,在一个电子商务的系统中,有一个Order类用来表示用户提交的一份订单,其中包含了订单所需要的数据,如商品ID列表、每种商品对应的数量等等;以及相关的一些行为,如计算商品的总价格等等。根据信息专家模式给出的建议,计算该订单给消费者产生了多少消费税的这一功能,也应该由Order类来完成(假设方法名叫calculateTax)。然而,根据消费者所在国家的不同,消费税的计算方式明显是不一样的。有一种解决方案是,将用户所在国家的名称以字符串或枚举的形式,连同消费总值一起,作为参数传递给calculateTax方法。然后在calculateTax方法中,通过一连串的if else语句来判断参数传入的是哪个国家,并给出相应的计算代码。
这种方法的确能在某种程度上解决问题。但是这种方案极不利于系统的维护和扩展。首先,设想一下该商务系统支持100多个国家的业务,那么程序中的100多个elseif语句会是怎样一种壮观的景象。这是极不利于系统的维护者去阅读甚至查找某一个国家对应的elseif语句。其次,一旦将来停止了某些国家的业务,或者需要增加新国家的业务,或者需要修改已有的一些国家的税率,除了需要在一大堆的elseif中做一些很繁琐的工作之外,Order这个类本身的代码是需要被重新编译才能继续使用的。这无疑给维护和扩展带来了麻烦。
问题的另一种解决方案则是利用多态性模式。系统首先定义出一个接口,比如叫做TaxCalculator。该接口定义了唯一一个方法,calculateTax,该方法根据消费总值计算消费税。然后,对于每一个国家的不同的消费税计算方法,系统再分别定义专门的类去实现这个接口。比如,计算英国消费者的消费税的类为UKTaxCalculator,计算美国消费者的消费税的类为USTaxCalculator,等等。所有这些类都根据自身所代表的国家的具体消费税计算方法来实现了calculateTax方法。也即,前一种解决方案中的100多个elseif语句中的内容被分拆到了100多个类中。现在,当Order类需要计算消费税的时候,传递给它的calculateTax方法的参数就只需要一个消费总值和一个TaxCalculator的引用了,并且它本身不需要做任何具体的计算,它只需要将这一操作下派给这个引用就可以了。
上面的这个例子其实就是GoF设计模式中的策略模式,这的确是多态性模式的一个经典的应用场景。通过多态性模式,系统分离了接口与具体的实现,从而在保持接口不变的情况下,可以非常容易地对实现进行维护和扩展。并且,在上面的例子中,对具体策略类的各种修改都不需要在对Order类进行重编译。
多态性模式是OO设计的一个基本原则。
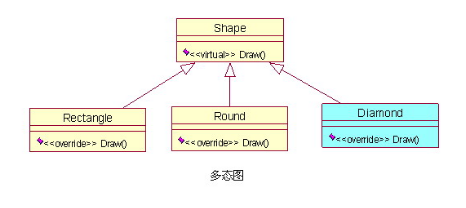
例如:我们想设计一个绘图程序,要支持可以画不同类型的图形,我们定义一个抽象类Shape,矩形(Rectangle)、圆形(Round)分别继承这个抽象类,并重写(override)Shape类里的Draw()方法,这样我们就可以使用同样的接口(Shape抽象类)绘制出不同的图形,(Diamond)类,对整个系统结构也没有任何影响,只要增加一个继承Shape的类就行了。
7. Pure Fabrication (纯虚构)
这里的纯虚构跟我们常说的纯虚构函数意思相近。高内聚低耦合,是系统设计的终极目标,但是内聚和耦合永远都是矛盾对立的。高内聚以为这拆分出更多数量的类,但是对象之间需要协作来完成任务,这又造成了高耦合,反过来毅然。该如何解决这个矛盾呢,这个时候就需要纯虚构模式,由一个纯虚构的类来协调内聚和耦合,可以在一定程度上解决上述问题。
可参考如下理解:
(1) 问题:当不想破坏高内聚和低耦合的设计原则时,谁来负责处理这种情况?
(2) 解决方案:将一组高内聚的职责分配给一个虚构的或处理方便的“行为”类,它并不是问题域中的概念,而是虚构的事务,以达到支持高内聚、低耦合和重用的目的。
(3) 分析:纯虚构模式用于解决高内聚和低耦合之间的矛盾,它要求将一部分类的职责转移到纯虚构类中,在理想情况下,分配给这种虚构类的职责是为了达到高内聚和低耦合的目的。在实际操作过程中,纯虚构有很多种实现方式,例如将数据库操作的方法从数据库实体类中剥离出来,形成专门的数据访问类,通过对类的分解来实现类的重用,新增加的数据访问类对应于数据持久化存储,它不是问题域中的概念,而是软件开发者为了处理方便而产生的虚构概念。纯虚构可以消除由于信息专家模式带来的低内聚和高耦合的坏设计,得到一个具有更好重用性的设计。在系统中引入抽象类或接口来提高系统的扩展性也可以认为是纯虚构模式的一种应用。纯虚构模式通常基于相关功能的划分,是一种以功能为中心的对象或行为对象。在很多设计模式中都体现了纯虚构模式,例如适配器模式、策略模式等等。
纯虚构模式关注这样一个问题:当你并不想违背高内聚和低耦合或其他目标,但是基于专家模式所提供的方案又不合适时,哪些对象应该承担这一职责?
OO设计中的领域模型是对领域内的概念内或现实世界中的对象的模型化表示。创建领域模型的关键思想是减小软件人员的思维与软件模式之间的表示差异。因此,在OO设计时,系统内的大多数类都是来源于现实世界中的真实类。然而,在给这些类分配职责时,有可能会遇到一些很难满足低耦合高内聚的设计原则。纯虚构模式对这一问题给出的方案是:给人为制造的类分配一组高内聚的职责,该类并不代表问题领域的概念,而代表虚构出来的事物,用以支持高内聚、低耦合和复用。
纯虚构模式强调的是职责应该置于何处。一般来说,纯虚构模式会通过表示解析或者行为解析来确定出一些纯虚构类,用于放置某一类职责。理想状况下,分配给这种虚构物的职责是要支持高内聚低耦合的,从而使整个系统处于一种良好的设计之中。
例如,在信息专家模式的最后一段所举的例子中提到,许多后台系统都需要对数据库进行操作,将系统中的一些对象进行持久化。信息专家模式给出的建议是将持久化的职责分配给具体的每一个模型类。但是这种建议已经被证明是不符合高内聚低耦合原则的,因为不会被采纳。于是,设计者往往会在系统中加入类似于DAO或者PersistentStorage这样的类。这些类在领域模型中是并不存在的,它们完全由设计者根据系统的行为而虚构得到。然而,这些类的引入,使得操作数据库进行持久化这种高内聚的职责可以顺理成章地分配给它们。从而在整个系统中实现了比较好的内聚和耦合。
在使用纯虚构模式时,不能毫无限制地对系统中的各种行为进行解析并纯虚构。如此往往会导致系统中大量的行为对象的存在,这样会对耦合产生不良的影响。
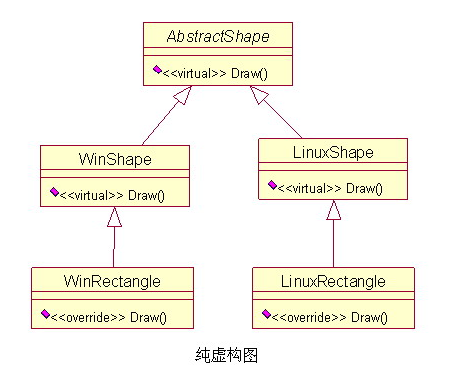
例如:上面多态模式的例子,如果我们的绘图程序需要支持不同的系统,那么因为不同系统的API结构不同,绘图功能也需要不同的实现方式,那么该如何设计更合适呢?AbstractShape,不论是哪个系统都可以通过AbstractShape类来绘制图形,我们即没有降低原来的内聚性,也没有增加过多的耦合,可谓鱼肉和熊掌兼得,哈哈哈!
8. Indirection (间接性)
“间接”顾名思义,就是这个事不能直接来办,需要绕个弯才行。绕个弯的好处就是,本来直接会连接在一起的对象彼此隔离开了,一个的变动不会影响另一个。就想我在前面的低耦合模式里说的一样,“两个不同模块的内部类之间不能直接连接”,但是我们可以通过中间类来间接连接两个不同的模块,这样对于这两个模块来说,他们之间仍然是没有耦合/依赖关系的。
可参考如下理解:
(1) 问题:如何分配职责以避免两个(或多个)事物之间的直接耦合?如何解耦对象以降低耦合度并提高系统的重用性?
(2) 解决方案:分配职责给中间对象以协调组件或服务之间的操作,使得它们不直接耦合。中间对象就是在其他组件之间建立的中介。
(3) 分析:要避免对象之间的直接耦合,最常用的做法是在对象之间引入一个中间对象或中介对象,通过中介对象来间接相连。中介模式对应于面向对象设计原则中的迪米特法则,在外观模式、代理模式、中介者模式等设计模式中都体现了中介模式。
间接性模式关注这样一个问题:为了避免两个或多个事务之间直接耦合,应该如何分配职责?如何使对象解耦合,以支持低耦合并提高复用性潜力?
间接性模式对此的回答是:将职责分配给中介对象,使其作为其他构件或服务之间的媒介,以避免它们之间的直接耦合。中介则实现了其他构件之间的间接性。
间接性模式的思想比较简单,即通过一个中介就能消除许多的耦合。在GoF的23种设计模式中,有许多模式都利用到了间接性的思想。比如桥接模式中,设计将抽象部分与其实现部分相分离,利用的就是在客户与实现之间增加了一个抽象层次。外观模式则是在整个子系统与客户之间增加了一个便于用户使用的外观类作为中介。而中介者模式中的中介者则更是典型的例子。
9. Protected Variations (受保护变化,防止变异)
预先找出不稳定的变化点,使用统一的接口封装起来,如果未来发生变化的时候,可以通过接口扩展新的功能,而不需要去修改原来旧的实现。也可以把这个模式理解为OCP(开闭原则)原则,就是说一个软件实体应当对扩展开发,对修改关闭。在设计一个模块的时候,要保证这个模块可以在不需要被修改的前提下可以得到扩展。这样做的好处就是通过扩展给系统提供了新的职责,以满足新的需求,同时又没有改变系统原来的功能。
可参考如下理解:
(1) 问题:如何分配职责给对象、子系统和系统,使得这些元素中的变化或不稳定的点不会对其他元素产生不利影响?
(2) 解决方案:找出预计有变化或不稳定的元素,为其在这些变化之外创建稳定的“接口”而分配职责。
(3) 分析:受保护变化模式简称PV,它是大多数编程和设计的基础,是模式的基本动机之一,它使系统能够适应和隔离变化。它与面向对象设计原则中的开闭原则相对应,即在不修改原有元素(类、模块、子系统或系统)的前提下扩展元素的功能。开闭原则又可称为“可变性封装原则(Principle of Encapsulation of Variation, EVP)”,要求找到系统的可变因素并将其封装起来。如将抽象层的不同实现封装到不同的具体类中,而且EVP要求尽量不要将一种可变性和另一种可变性混合在一起,这将导致系统中类的个数急剧增长,增加系统的复杂度。在具体实现时,为了符合受保护变化模式,我们通常需要对系统进行抽象化设计,定义系统的抽象层,再通过具体类来进行扩展。如果需要扩展系统的行为,无须对抽象层进行任何改动,只需要增加新的具体类来实现新的业务功能即可,在不修改已有代码的基础上扩展系统的功能。大多数设计原则和GoF模式都是受保护变化模式的体现。
防止变异(PV)是非常重要和基本的软件设计原则,几乎所有的软件或架构设计技巧都是防止变异的特例。PV是一个根本原则,它促成了大部分编程和设计的模式和机制,用来提供灵活性和防止变化。在软件设计中,除了数据封装、接口、多态、间接性等机制是PV的核心机制之外,没有一种固定的或者是通用的办法能够防止一切变化的产生。因此PV的实现依赖的是一系列的OO设计方面的经验性原则,用以产生一个设计良好的高内聚、低耦合的系统,从而支持PV。
关于OCP原则,后面还会有单独的论述。
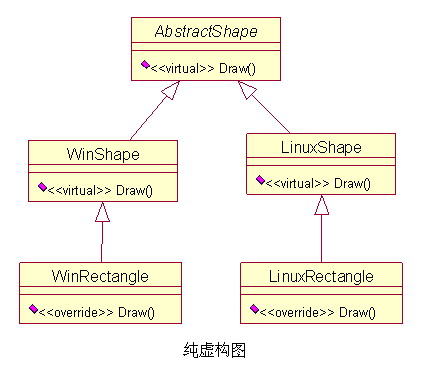
这里我们可以看到,因为增加了纯虚构类
这样的设计更符合高内聚和低耦合原则,虽然后来我们又增加了一个菱形
这里我们把两种不同的数据存储功能分别放在了两个类里来实现,这样如果未来保存到

这里我们在订单类里增加了一个
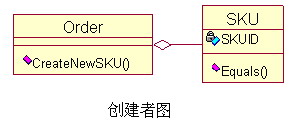
这里因为订单是商品的容器,也只有订单持有初始化商品的信息,所以这个耦合关系是正确的且没办法避免的,所以由订单来创建商品。

针对这个问题需要权衡的是,比较商品是否相同的方法需要放到那里类里来实现呢?分析业务得知需要根据商品的编号
我们生活在一个充满规则的世界里,在复杂多变的外表下,万事万物都被永恒的真理支配并有规律的运行着。模式也是一样,不论那种模式,其背后都潜藏着一些“永恒的真理”,这个真理就是设计原则。记得一次参加微软的架构师培训,期间讲到设计模式,有人问了老师一个问题:“什么东西比设计模式更重要?”,老师是一位有多年丰富实践经验的开发者,他毫不犹豫地回答到:“比模式更重要的是原则”。这句话我时常能够想起,越来越觉得这是一个伟大的答案。的确,还有什么比原则更重要呢?就像人的世界观和人生观一样,那才是支配你一切行为的根本,而对于设计模式来说,为什么这个模式要这样解决这个问题,而另一个模式要那样,它们背后都遵循的就是永恒的设计原则。可以说,设计原则是设计模式的灵魂。
对于设计原则的深入探讨我还没有那个深度,推荐大家去看《敏捷软件开发—原则、模式与实践》,下面仅对部分常用的设计原则做些简单的讲解:
1. 单一职责原则(Single Responsibility Principle, SRP)
“就一个类而言,应该仅有一个引起它变化的原因。”,这里的单一职责,或者单一的变化原因,并非指严格意义上的唯一的一个职责或者原因,而应该是指一类联系紧密的职责,或者说单一的变化动机。SRP其实是高内聚的一种形式,它要求一个类紧密围绕着一项职责进行工作,是一种内聚程度较高的设计。也就是说,不要把变化原因各不相同的职责放在一起,因为不同的变化会影响到不相干的职责。再通俗一点地说就是,不该你管的事情你不要管,管好自己的事情就可以了,多管闲事害了自己也害了别人。(当然这里说的多管闲事跟见义勇为是两回事,我们提倡见义勇为!)
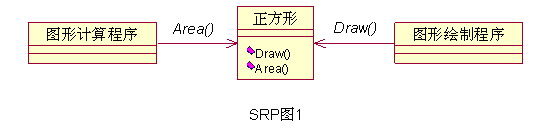
例如:参考下图中的设计,图形计算程序只使用了正方形的Area()方法,永远不会使用Draw()方法,而它却跟Draw方法关联了起来。这违反了单一原则,如果未来因为图形绘制程序导致Draw()方法产生了变化,那么就会影响到本来毫不关系的图形计算程序。
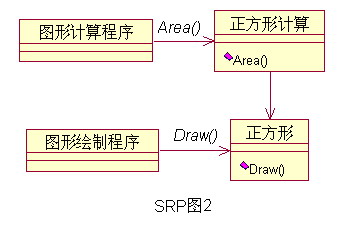
那么我们该怎么做呢?如下图,将不同的职责分配给不同的类,使单个类的职责尽量单一,就隔离了变化,这样他们也不会互相影响了。
2、开放—封闭原则(Open-Closed Principle,OCP)
“软件实体(类、模块、函数等)应该是可以扩展的,但是不可修改。”嘿!多么朴实的话语,第一次看这个原则的时候我都看傻了,我当时在想“这不是&#%做白日梦吗!不修改怎么扩展啊?”但是随着学习的深入,理解了这个“不修改”是什么意思,意思是“你可以随便增加新的类,但是不要修改原来的类”。从这个角度去理解就好多了,其实这里还是一个隔离变化的问题。
模块应该同时对扩展、可适应性开放和对影响客户的更改封闭。也即,模块应该对扩展开放,对修改关闭。OCP其实是PV的另一种描述。除了这些原则之外,还有许多各种各样的技术可以用来PV。这里就不再赘述。在一个系统中,值得应用PV的地方是可能会产生变化的地方。其中之一是系统的需求定义的一些变化点,比如包含计算消费税程序的电子商务系统需要支持在新的国家开展业务。那么在计算消费税的程序里使用策略模式便能很好地支持这一点扩展。换句话说,如果需求中明确规定了在这一点上不允许有任何变化(实际上不太可能,这里只是假设),那么在计算消费税的程序里使用if else语句也未尝不可。另外,设计者预测出来的可能会产生变化的点也可以应用PV。还是说上一个例子。计算消费税的需求规定了只包含三个国家,但是设计者如果预测出这是一个变化点,可能在将来会有各种变化,那么设计者同样可以利用策略模式来完成这一设计。但是,在预测变化点时,一定要小心谨慎,仔细考虑。否则很容易在系统中预测出大量的、实际上变化概率并不大的变化点出来,从而导致在整个系统中大量地出现了灵活的、使用模式的、支持变化的设计。而往往这些设计在整个软件的生命周期中都从未被用到过。这种现象被称为过度设计。这样的情况在软件开发的过程中是极其浪费资源的,应该努力去避免这种情况的发生。
例如:如下图,有一个客户端程序通过数据访问接口操作数据,对于这套系统来说,一开始计划使用的是SQL Server或Oracle数据库,但是后来考虑到成本,改用免费的MySQL;那么对于客户端程序来说,后来数据的扩展对它没有任何影响,它在不知不觉间就用上了免费好用的MySQL数据库,这全要感谢OCP原则。

3、依赖倒置原则(Dependence Inversion Principle,DIP)
“抽象不应该依赖于细节。细节应该依赖于抽象。”,关于这个原则,还有种说法是.“高层不应该依赖于底层,两者都应该依赖于抽象。”,其实怎么说都是对的,关键就是要理解一点,只有抽象的东西才是最稳定的,也就是说,我们依赖的是它的稳定。如果将来“抽象”也不稳定了,那么谁稳定我跟谁,其实说白了不就是傍大款吗!
DIP的核心思想是面向接口编程。一个依赖接口实现的类要比一个依赖细节实现的类更容易维护和扩展。它来源于这样一个事实:相对于细节的多变性,抽象的东西要稳定得多。比如,在一个系统中,类A依赖于类B实现。那么,当类A需要改变对类B的依赖,转而依赖类C时,类A必须修改源代码才能实现。而如果类A依赖于一个接口X实现,而类B和类C都实现这个接口,那么之后无论是类B和类C之间的替换,抑或是让类A去依赖新的类D,都是非常易于实现的。DIP的本质也是降低了耦合,将一个类与细节的耦合降低到了与接口的耦合,而与一个稳定的接口之间耦合是良好的。
例如:参考下图的设计,一个开关跟灯直接连接在一起了,也就是说开关依赖于灯的打开和关闭方法,那么如果我想用这个开关也可以打开其他东西呢,比如电视、音响。显然这个设计是无法满足这个要了,因为我们依赖了细节而不是抽象,这个开关已经等价于“灯的开关”。

那么我们该如何来设计一个通用的开关呢?参考下图的设计,OK!现在我们不仅可以打开灯,还可以打开电视和音响,甚至未来任何实现了“开关接口”的任何东西。

4、接口隔离原则(Interface Segregation Pinciple,ISP)
“不应该强迫客户依赖于它们不用的方法。接口属于客户,不属于它所在的类层次结构。类不应该依赖它不需要的接口,一个类对另一个类的依赖应建立在最小的接口上。”,ISP也是高内聚低耦合的一种表现形式。因为类对公有接口的依赖也是一种导出耦合的关系。如果一个类依赖了它不需要的接口,那么在系统中便存在了这样一种没有意义的耦合,不利于耦合度的降低。反过来,在建立接口时也不要建立臃肿的、包含一切的接口。这样的接口反而失去了高内聚性。这个说得很明白了,再通俗点说,不要强迫客户使用它们不用的方法,如果强迫用户使用它们不使用的方法,那么这些客户就会面临由于这些不使用的方法的改变所带来的改变。
例如:参考下图的设计,在这个设计里,取款、存款、转帐都使用一个通用界面接口,也就是说,每一个类都被强迫依赖了另两个类的接口方法,那么每个类有可能因为另外两个类的方法(跟自己无关)而被影响。拿取款来说,它根本不关心“存款操作”和“转帐操作”,可是它却要受到这两个方法的变化的影响,真是土鳖!

那么我们该如何解决这个问题呢?参考下图的设计,为每个类都单独设计专门的操作接口,使得它们只依赖于它们关系的方法,这样就不会互相影响,也就不会在发生土鳖的事情了!

5、里氏替换原则(Liskov Substitution Principle,LSP)
“子类型必须能够替换掉它们的基类型。”,如果对于类型S的每个对象o1存在类型T的对象o2,那么对于所有定义了T的程序P来说,当用o1替换o2并且S是T的子类型时,P的行为不会改变。也就是说继承中的“IS A”关系是必须保证的,否则还算什么继承啊!将上面的形式化定义换一种简单的说法就是:在一个系统中,任何类的对象都可以由该类的任何一个子类的任何对象给替换掉,而整个系统的行为不变。LSP是一种简单的思想,然而严格按照LSP去设计系统会使得所有基类的接口语义是完全稳定的,这非常有利于系统的扩展性。如果违反了LSP原则,常会导致在运行时(RTTI)的类型判断违反OCP原则。
例如:函数A的参数是基类型,调用时传递的对象是子类型,正常情况下,增加子类型都不会影响到函数A的,如果违反了LSP,则函数A必须小心的判断传进来的具体类型,否则就会出错,这就已经违反了OCP原则。
6、迪米特法则(Law ofDemeter, LOD)
不要历经远距离的对象结构路径去向远距离的间接对象发送消息。
假设在一个系统中,存在A、B、C、D四个类。其中,类A包含了类B,类B包含了类C,类C包含了类D。那么,一个类A的实例a中一定会存在着一个类D的实例d,这是通过类B和类C间接包含进来的。那么,LOD禁止a向d直接发送任何消息,因为这直接引入了类A同类D之间毫无道理的耦合;同时这也是一种极为脆弱的设计,它无法应对将来可能出现的任何变化,对象路径越长,其稳定性就越差。LOD要求一个类在其方法里只给有限的对象发送消息,包括:自身、方法的参数、自身的属性、作为自身属性的集合中的元素、在方法中创建的对象。
关于模式学习
深刻理解面向对象是学好设计模式的基础,掌握一定的面向对象设计原则才能掌握面向对象设计模式的精髓,从而实现灵活运用设计模式。仅知道OO的语言机制是不够的,懂得语言里的封装、继承、多态,只是满足了最最基础的条件,要真正发挥OO的强大的作用,关键是要深刻理解以上的GRASP模式和设计原则,在此基础上去再深入理解设计模式,并在实践中不断磨练。
模式跟OO原则相比其实并不重要,如果你能设计出基本符合以上原则的程序,那么可能就已经总结出了新的模式,所以学习模式的根本是为了深入理解OO思想和原则,使我们可以写出高内聚低耦合的程序。
另外最近在学习李建忠老师的“C#面向对象设计模式纵横谈系列课程”时候,李老师提出了一个“重构到模式”的理论,感觉十分有道理,模式不完全是供我们套用的模版,在特定的业务环境下,我们实现的可能只是“类似XX模式”的设计模式,因为针对这个环境,这么使用就是最合适的,而不是什么时候都必须完全照搬GOF的23种设计模式的格式,模式是死的,而人是活的,找到最合适的实现方式就好,不要为了设计模式而使用设计模式。
【转】 GRASP(通用职责分配软件模式)模式的更多相关文章
- Atitit GRASP(General Responsibility Assignment Software Patterns),中文名称为“通用职责分配软件模式”
Atitit GRASP(General Responsibility Assignment Software Patterns),中文名称为"通用职责分配软件模式" 1. GRA ...
- 7.1 通用的职责分配软件原则 GRASP原则一: 创建者 Creator
1.GRASP原则一: 创建者 Creator Who should be responsible for creating a new instance of some class 由谁来负责创 ...
- GRASP (职责分配原则)
要学习设计模式,有些基础知识是我们必须要先知道的,设计模式是关于类和对象的一种高效.灵活的使用方式,也就是说,必须先有类和对象,才能有设计模式的用武之地,否则一切都是空谈,那么类和对象是从那冒出来的呢 ...
- (转载)GRASP职责分配原则
GRASP (职责分配原则) 要学习设计模式,有些基础知识是我们必须要先知道的,设计模式是关于类和对象的一种高效.灵活的使用方式,也就是说,必须先有类和对象,才能有设计模式的用武之地,否则一切都是空谈 ...
- Atitit. 软件设计 模式 变量 方法 命名最佳实践 vp820 attilax总结命名表大全
Atitit. 软件设计 模式 变量 方法 命名最佳实践 vp820 attilax总结命名表大全 1. #====提升抽象层次1 2. #----使用通用单词1 3. #===使用术语..1 4. ...
- 四种软件开发模式:tdd、bdd、atdd和ddd的概念
看一些文章会看到TDD开发模式,搜索后发现有主流四种软件开发模式,这里对它们的概念做下笔记. TDD:测试驱动开发(Test-Driven Development) 测试驱动开发是敏捷开发中的一项核心 ...
- windows server 域分发与分配软件
参考网站:https://blog.csdn.net/southwind0/article/details/80734508 1.win 2008创建域 https://jingyan.baidu.c ...
- 软件开发模式,DevOps
参考文献:http://www.cnblogs.com/jetzhang/p/6068773.html 历史回顾 为了能够更好的理解什么是DevOps,我们很有必要对当时还只有程序员(此前还没有派生出 ...
- [Python设计模式] 第2章 商场收银软件——策略模式
github地址: https://github.com/cheesezh/python_design_patterns 题目 设计一个控制台程序, 模拟商场收银软件,根据客户购买商品的单价和数量,计 ...
随机推荐
- JS判断备忘
快速引入jquery并显示重点内容 (function(d,j,s,t){t=d.body.appendChild(d.createElement("script"));t.onl ...
- open-stf 安装篇(linux)
OpenSTF 百度MTC的远程真机调试 Testin的云真机 腾讯WeTest的云真机 阿里MQC的远程真机租用 什么是OpenSTF? OpenSTF是一个手机设备管理平台,可以对手机进行远 ...
- C语言宏中"#"和"##"的用法
转自:https://www.cnblogs.com/hnrainll/archive/2012/08/15/2640558.html 在查看linux内核源码的过程中,遇到了许多宏,这里面有许多都涉 ...
- Linux命令之查看cpu个数_核数_内存总数
http://blog.csdn.net/cgwcgw_/article/details/10000053 cpu个数 cat /proc/cpuinfo | grep "physical ...
- 从Mysql某一表中随机读取n条数据的SQL查询语句
若要在i ≤ R ≤ j 这个范围得到一个随机整数R ,需要用到表达式 FLOOR(i + RAND() * (j – i + 1)).例如, 若要在7 到 12 的范围(包括7和12)内得到一个随机 ...
- POJ3461:Oulipo——题解
http://poj.org/problem?id=3461 KMP板子,好久以前学过了,直接把板子粘上去即可. #include<cstdio> #include<cstring& ...
- float,absolute脱离文档流的总结
dom元素脱离文档流,有如下几种方式: 1. float 脱离文档流,其他dom元素无视他,在其下方布局,但是其未脱离文本流,其他元素的文本会认为他存在,环绕他布局.父元素会无视他,因此无法获取其高度 ...
- bzoj2120: 数颜色(BIT套主席树+set/分块)
带修改的 HH的项链. 带修改考虑用BIT套主席树,查区间里有几个不同的数用a[i]上次出现的位置pre[i]<l的数有几个来算就好了. 考虑怎么修改.修改i的时候,我们需要改变i同颜色的后继的 ...
- 2017-7-18-每日博客-关于Linux下的history的常用命令.doc
History history命令可以用来显示曾执行过的命令.执行过的命令默认存储在HOME目录中的.bash_history文件中,可以通过查看该文件来获取执行命令的历史记录.需要注意的是.bash ...
- pg_basebackup: invalid tar block header size
问题: 在使用pg_basebackup搭建备节点时,由于pg_basebackup本身使用的是int整型来保存传输的数据大小,当传输的数据大于4G的话,整数就会溢出,进而报出:pg_baseback ...