其它——MyCat实现分库分表
文章目录
MyCat实现分库分表
一 开源数据库中间件-MyCat
如今随着互联网的发展,数据的量级也是撑指数的增长,从GB到TB到PB。对数据的各种操作也是愈加的困难,传统的关系性数据库已经无法满足快速查询与插入数据的需求。这个时候NoSQL的出现暂时解决了这一危机。它通过降低数据的安全性,减少对事务的支持,减少对复杂查询的支持,来获取性能上的提升。
但是,在有些场合NoSQL一些折衷是无法满足使用场景的,就比如有些使用场景是绝对要有事务与安全指标的。这个时候NoSQL肯定是无法满足的,所以还是需要使用关系性数据库。如何使用关系型数据库解决海量存储的问题呢?此时就需要做数据库集群,为了提高查询性能将一个数据库的数据分散到不同的数据库中存储。
二 MyCat简介
Mycat 背后是阿里曾经开源的知名产品——Cobar。Cobar 的核心功能和优势是 MySQL 数据库分片,此产品曾经广为流传,据说最早的发起者对 Mysql 很精通,后来从阿里跳槽了,阿里随后开源的 Cobar,并维持到 2013 年年初,然后,就没有然后了。
Cobar 的思路和实现路径的确不错。基于 Java 开发的,实现了 MySQL 公开的二进制传输协议,巧妙地将自己伪装成一个 MySQL Server,目前市面上绝大多数 MySQL 客户端工具和应用都能兼容。比自己实现一个新的数据库协议要明智的多,因为生态环境在哪里摆着。
Mycat 是基于 cobar 演变而来,对 cobar 的代码进行了彻底的重构,使用 NIO 重构了网络模块,并且优化了 Buffer 内核,增强了聚合,Join 等基本特性,同时兼容绝大多数数据库成为通用的数据库中间件。
简单的说,MyCAT就是:一个新颖的数据库中间件产品支持mysql集群,或者mariadb cluster,提供高可用性数据分片集群。你可以像使用mysql一样使用mycat。对于开发人员来说根本感觉不到mycat的存在。
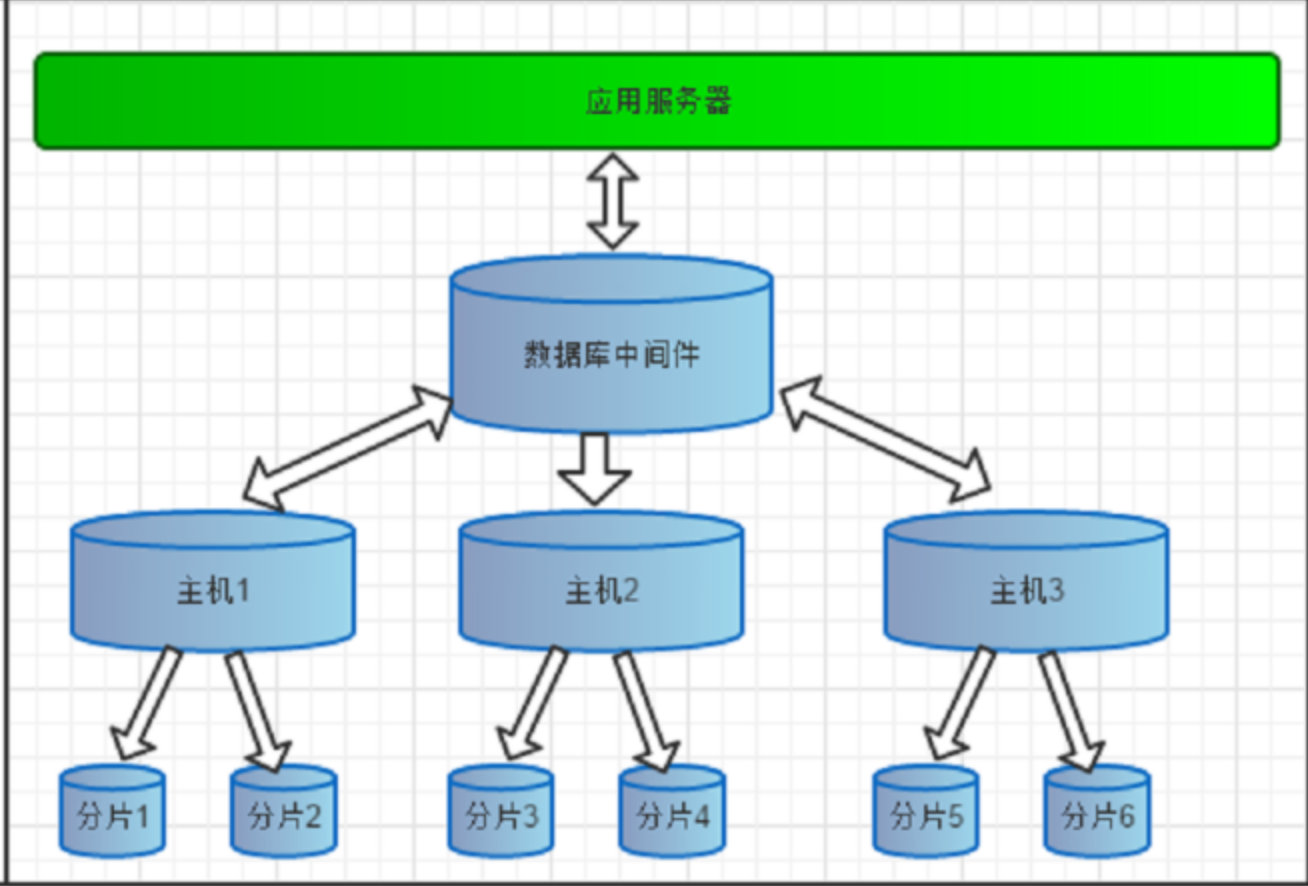

三 MyCat下载及安装
3.1 MySQL安装与启动
JDK:要求jdk必须是1.8及以上版本
MySQL:推荐mysql是5.6以上版本
MySQL安装与启动步骤如下:
检查系统是否安装其他版本的MYSQL数据
#yum list installed | grep mysql
#yum -y remove mysql-libs.x86_64
安装及配置
# wget http://repo.mysql.com/mysql-community-release-el6-5.noarch.rpm
# rpm -ivh mysql-community-release-el6-5.noarch.rpm
# yum repolist all | grep mysql
安装MYSQL数据库
# yum install mysql-community-server -y
设置为开机启动(2、3、4都是on代表开机自动启动)
# chkconfig --list | grep mysqld
# chkconfig mysqld on
启动MySQL
# service mysqld start
设置root密码
# mysql_secure_installation
输入后直接按回车,然后所有选项直接选y即可。
root账号登录
# mysql -uroot -p
#授权并刷新权限
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '你设置的密码' WITH GRANT OPTION;
mysql> flush privileges;
3.2使用docker启动多个数据库
docker run -di --name=test1_mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
docker run -di --name=test2_mysql -p 3307:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
3.3 MyCat安装及启动
MyCat:
MyCat的官方网站:
http://www.mycat.org.cn/
下载地址:https://github.com/MyCATApache/Mycat-download
第一步:将Mycat-server-1.4-release-20151019230038-linux.tar.gz上传至服务器
第二步:将压缩包解压缩。建议将mycat放到/usr/local/mycat目录下。
tar -xzvf Mycat-server-1.4-release-20151019230038-linux.tar.gz
mv mycat /usr/local
第三步:进入mycat目录的bin目录,启动mycat
./mycat start
停止:
./mycat stop
mycat 支持的命令{ console | start | stop | restart | status | dump }
Mycat的默认端口号为:8066
四 MyCat分片-海量数据存储解决方案
4.1什么是分片
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。
数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。
(1)一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切分可以称之为数据的垂直(纵向)切分

(2)另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
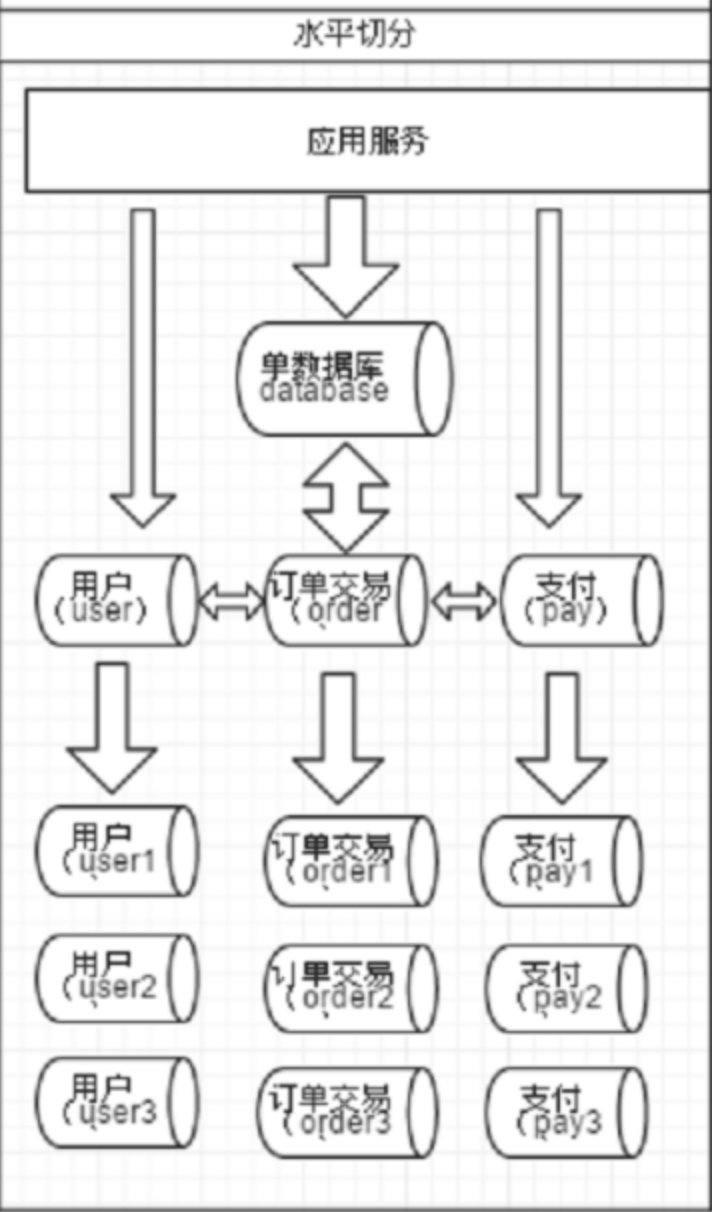
MyCat分片策略:
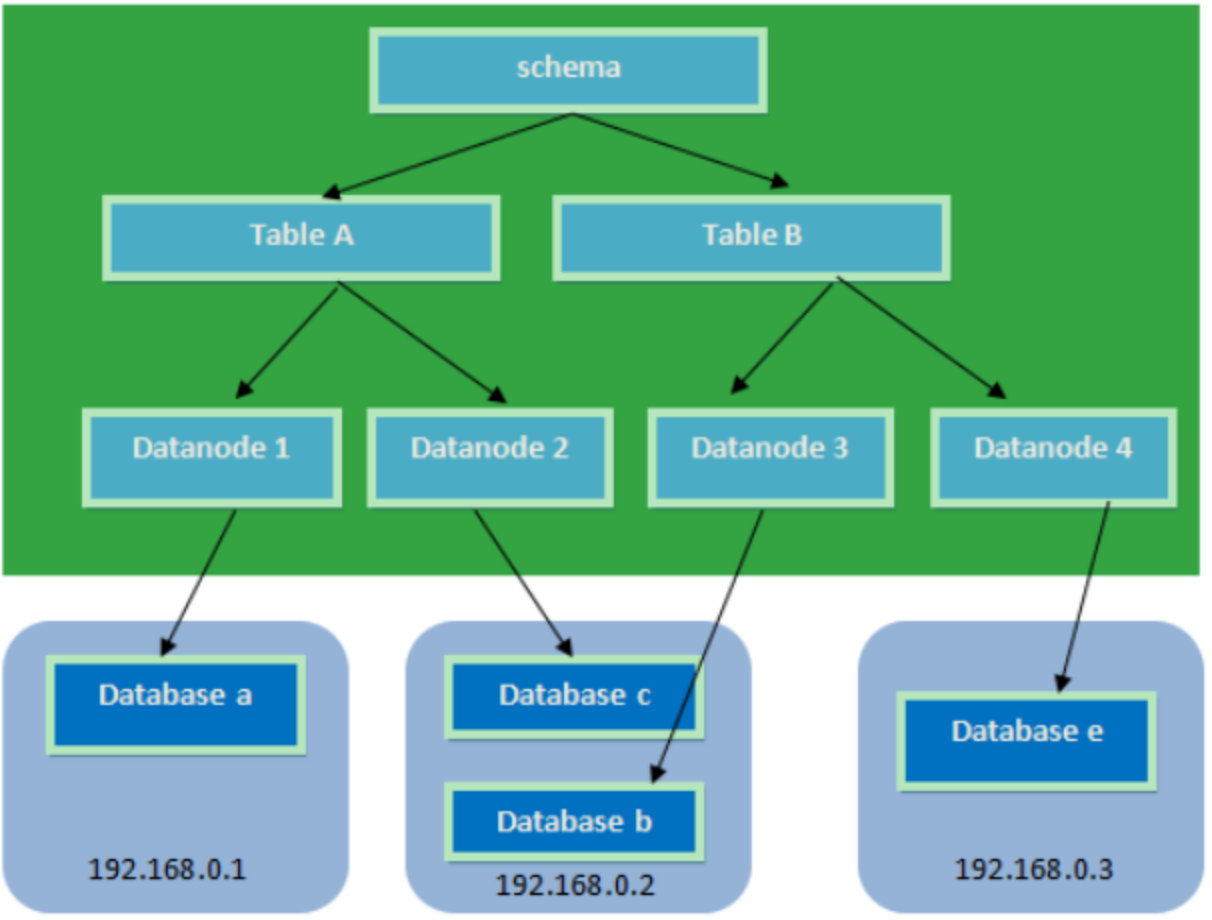
4.2 分片相关的概念
- 逻辑库(schema) :
前面一节讲了数据库中间件,通常对实际应用来说,并不需要知道中间件的存在,业务开发人员只需要知道数据库的概念,所以数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。
- 逻辑表(table):
既然有逻辑库,那么就会有逻辑表,分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。
分片表:是指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分片都有一部分数据,所有分片构成了完整的数据。 总而言之就是需要进行分片的表。
非分片表:一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。
- 分片节点(dataNode)
数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)。
- 节点主机(dataHost)
数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
- 分片规则(rule)
前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
4.3 MyCat分片配置
sever.xml:综合配置数据库的相关信息,端口,内存占用,创建账号,密码
schema.xml:对数据库表结构的定义
rule.xml:指定相关算法,来实现不同的分片数据库
4.3.1 配置schema.xml
schema.xml作为MyCat中重要的配置文件之一,管理着MyCat的逻辑库、逻辑表以及对应的分片规则、DataNode以及DataSource。弄懂这些配置,是正确使用MyCat的前提。这里就一层层对该文件进行解析。
schema 标签用于定义MyCat实例中的逻辑库
Table 标签定义了MyCat中的逻辑表 rule用于指定分片规则,auto-sharding-long的分片规则是按ID值的范围进行分片 1-5000000 为第1片 5000001-10000000 为第2片…. 具体设置我们会在第5小节中讲解。
dataNode 标签定义了MyCat中的数据节点,也就是我们通常说所的数据分片。
dataHost标签在mycat逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句。
在服务器上创建3个数据库,分别是db1 db2 db3
修改schema.xml如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="user" primaryKey="id" dataNode="dn1,dn2" rule="auto-sharding-long" autoIncrement="true" fetchStoreNodeByJdbc="true">
</table>
<table name="article" primaryKey="id" dataNode="dn1,dn2" rule="sharding-by-murmur">
</table>
</schema>
<dataNode name="dn1" dataHost="localhost1" database="lqz" />
<dataNode name="dn2" dataHost="localhost2" database="lqz" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="jdbc:mysql://101.133.225.166:3306" user="root"
password="123456">
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="jdbc:mysql://101.133.225.166:3307" user="root"
password="123456">
</writeHost>
</dataHost>
</mycat:schema>
4.3.2 配置 server.xml
server.xml几乎保存了所有mycat需要的系统配置信息。最常用的是在此配置用户名、密码及权限。在system中添加UTF-8字符集设置,否则存储中文会出现问号
<property name="charset">utf8</property>
修改user的设置 , 我们这里设置了两个用户
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="defaultSchema">TESTDB</property>
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
<property name="defaultSchema">TESTDB</property>
</user>
4.3.1 配置rule.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-date">
<rule>
<columns>createTime</columns>
<algorithm>partbyday</algorithm>
</rule>
</tableRule>
<tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>nid</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
<function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
<function name="partbyday"
class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sNaturalDay">0</property>
<property name="sBeginDate">2014-01-01</property>
<property name="sEndDate">2014-01-31</property>
<property name="sPartionDay">10</property>
</function>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
</mycat:rule>
五 分片规则之-按主键范围分片rang-long
在配置文件中我们找到
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
tableRule 是定义具体某个表或某一类表的分片规则名称 columns用于定义分片的列 algorithm代表算法名称 我们接着找rang-long的定义
<function name="rang-long"
class="org.opencloudb.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
function用于定义算法 mapFile 用于定义算法需要的数据,我们打开autopartition-long.txt
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
六 分片规则之-一致性哈希murmur
当我们需要将数据平均分在几个分区中,需要使用一致性hash规则
我们找到function的name为murmur 的定义,将count属性改为3,因为我要将数据分成3片
<function name="murmur"
class="org.opencloudb.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">3</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
我们再配置文件中可以找到表规则定义
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
但是这个规则指定的列是id ,如果我们的表主键不是id ,而是nid ,那么我们应该重新定义一个tableRule:
<tableRule name="sharding-by-murmur-order">
<rule>
<columns>nid</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
在schema.xml中配置逻辑表时,指定规则为sharding-by-murmur-order
<table name="article" dataNode="dn1,dn2,dn3" rule="sharding-by-murmur-order" />
我们测试一下,创建文章表 ,并插入数据,测试分片效果。
CREATE TABLE `article` (
`nid` bigint(20) NOT NULL COMMENT '图书id',
`name` varchar(50),
PRIMARY KEY (nid)
);
INSERT INTO tb_order(nid,`name`)VALUES(1,'张三');
INSERT INTO tb_order(nid,`name`)VALUES(2,'王五');
INSERT INTO tb_order(nid,`name`)VALUES(3,'赵柳');
INSERT INTO tb_order(nid,`name`)VALUES(4,'张飞');
INSERT INTO tb_order(nid,`name`)VALUES(5,'刘备');
INSERT INTO tb_order(nid,`name`)VALUES(6,'孙红雷');
其它——MyCat实现分库分表的更多相关文章
- Mycat使用--分库分表和读写分离
Mycat分库分表读写分离 1. 模拟多数据库节点 2. 配置文件 具体操作参看: https://blog.csdn.net/vbirdbest/article/details/83448757 写 ...
- Windows环境下使用Mycat模拟分库分表-读写分离案例
一.基本环境 W7 64位.Mycat1.6.MySQL8.0 二.Mycat核心配置文件配置 解压Mycat1.6,并对server.xml.schema.xml.rule.xml三个核心配置文件做 ...
- Mycat配置分库分表(垂直分库、水平分表)、全局序列
1. Mycat相关文章 Linux安装Mycat1.6.7.4并实现Mysql数据库读写分离简单配置 Linux安装Mysql8.0.20并配置主从复制(一主一从,双主双从) Docke ...
- MySQL:如何使用MyCAT实现分库分表?
分库分表介绍 随着微服务这种架构的兴起,我们应用从一个完整的大的应用,切分为很多可以独立提供服务的小应用.每个应用都有独立的数据库. 数据的切分分为两种: 垂直切分:按照业务模块进行切分,将不同模块的 ...
- Linux 配置 mycat 和 分库分表配置。
Linux 如何配置mycat? 3.配置mycat 3.1.规定linux的用户名和全名不能叫mycat!!!否则mycat会不生效(原因是影响整个linux系统的环境变量导致mycat的配置环境变 ...
- Mycat的分库分表
其他方法: 雪花算法或者redis来实现id不重复的问题. 数据库分库分表: 垂直拆分的优缺点: 水平拆分: 分片枚举:即根据枚举(定义的常量)进行分类存储.
- Windows环境Mycat数据库分库分表中间件部署
下载地址MYCAT官方网站 jdk安装配置 首先去oracle官网下载并安装jdk8,添加环境变量,JAVA_HOME设置为D:\Worksoftware\Java\jdk1.8 CLASSPATH设 ...
- Mycat 数据库分库分表中间件
http://www.mycat.io/ Mycat 国内最活跃的.性能最好的开源数据库中间件! 我们致力于开发高性能的开源中间件而努力! 实体书Mycat权威指南 »开源投票支持Mycat下载 »s ...
- MyCat学习 ------分库分表 随笔
垂直切分.水平切分 1.垂直分库,解决库中表太多的问题. 2.垂直分表,解决表中列太多的问题.例如 商品表 包含 产地.二维码 .时间.价格.各个列.分为不同的小表. 水平切分, 大数据表拆分为小表 ...
- Mycat读写分离、主从切换、分库分表的操作记录
系统开发中,数据库是非常重要的一个点.除了程序的本身的优化,如:SQL语句优化.代码优化,数据库的处理本身优化也是非常重要的.主从.热备.分表分库等都是系统发展迟早会遇到的技术问题问题.Mycat是一 ...
随机推荐
- 基于MQTT的弱网环境应用
MQTT(Message Queuing Telemetry Transport)是一种轻量级的消息传输协议,设计用于低带宽和不稳定网络环境下的物联网设备之间的通信. 以下是MQTT的一些关键特点和常 ...
- Windows 环境下Docker 安装伪分布式 Hadoop
1.环境 Windows 11 Docker 20.0.2 2.拉取镜像 我选择 ubuntu20.04: docker pull ubuntu:20.04 然后我们用命令看一下本地镜像: docke ...
- GGTalk 开源即时通讯系统源码剖析之:虚拟数据库
继上篇<GGTalk 开源即时通讯系统源码剖析之:服务端全局缓存>详细介绍了 GGTalk 对需要频繁查询数据库的数据做了服务端全局缓存处理,以降低数据库的读取压力以及加快客户端请求的响应 ...
- AcWing 4489. 最长子序列题解
思路 此题较为简单,简述一下思路. 设原始数列为 \(a\). 定义 \(dp\) 数组,初始值都为 \(1\). 遍历数组,如果 \(a[i-1]*2 \leq a[i]\) ,那么 \(dp[i] ...
- Android 妙用TextView实现左边文字,右边图片
原文: Android 妙用TextView实现左边文字,右边图片 - Stars-One的杂货小窝 有时候,需要文字在左边,右边有个箭头,我个人之前会有两种做法: 使用线性布局来实现 或者使用约束布 ...
- Blazor中CSS隔离无法用在子组件内部
Blazor的CSS隔离是个很好的东西,如图,只需添加一个与Razor组件同名的CSS文件,这个文件中的CSS样式只会在同名的Razor组件中使用. 原理是通过在dom元素添加一个代表标识符的属性 在 ...
- python添加水印
# coding:utf-8 from PIL import Image, ImageDraw, ImageFont def add_text_to_image(image, text): font ...
- .NET程序的 GDI句柄泄露 的再反思
一:背景 1. 讲故事 上个月我写过一篇 如何洞察 C# 程序的 GDI 句柄泄露 文章,当时用的是 GDIView + WinDbg 把问题搞定,前者用来定位泄露资源,后者用来定位泄露代码,后面有朋 ...
- Element-ui源码解析(二):最简单的组件Button
好家伙,为了有足够的能力去开发组件,先研究一下别人的组件 开始抄袭模仿我们的行业标杆element-ui 找到Button组件的源码 只有三个文件,看上去非常易读,开搞 其中最重要的部分,自然 ...
- 2021-7-6 Vue实现记事本功能
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <script sr ...