【爬虫案例】用Python爬取百度热搜榜数据!
一、爬取目标
您好,我是@马哥python说,一名10年程序猿。
本次爬取的目标是:百度热搜榜
分别爬取每条热搜的:
热搜标题、热搜排名、热搜指数、描述、链接地址。
下面,对页面进行分析。
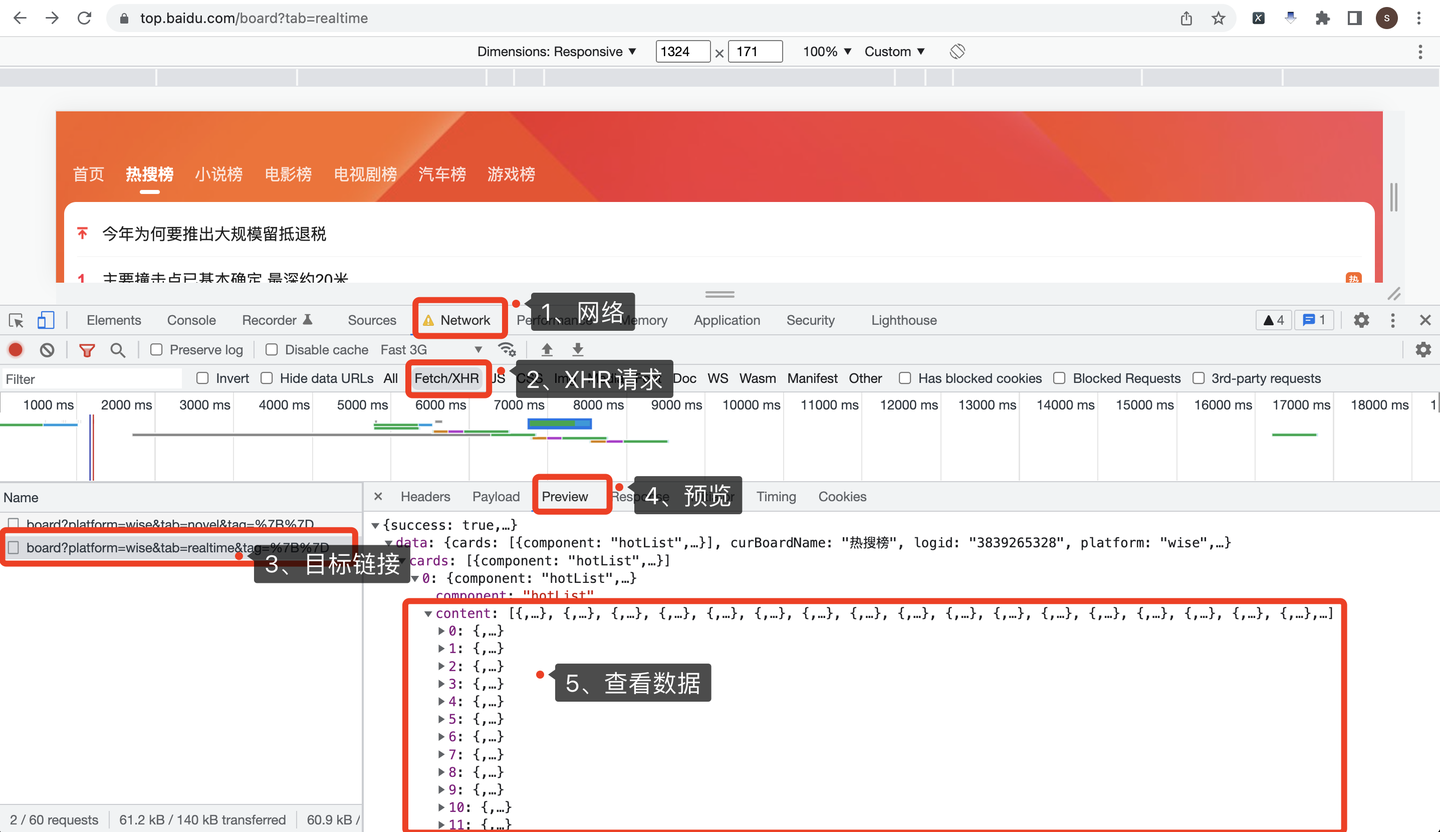
经过分析,此页面有XHR链接,可以针对接口进行爬取。
打开Chrome浏览器,按F12进入开发者模式,依次点击:
- 点击Network,选择网络
- 点击XHR,选择XHR请求
- 选择目标链接地址
- 击Preview,选择预览
- 查看返回数据
操作过程,如下图所示:
二、编写爬虫代码
首先,导入需要用到的库:
import requests # 发送请求
import pandas as pd # 存入excel数据
定义一个百度热搜榜接口地址:
# 百度热搜榜地址
url = 'https://top.baidu.com/api/board?platform=wise&tab=realtime'
构造一个请求头,伪装爬虫:
# 构造请求头
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36',
'Host': 'top.baidu.com',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://top.baidu.com/board?tab=novel',
}
向百度页面发送requests请求:
# 发送请求
r = requests.get(url, header)
返回的数据是json格式的,直接用r.json()接收:
# 用json格式接收请求数据
json_data = r.json()
这里,需要注意的是,页面上有2种热搜:
百度热搜榜最上面一条是置顶热搜,下面从1到30是普通热搜,接口返回的数据也是区分开的:
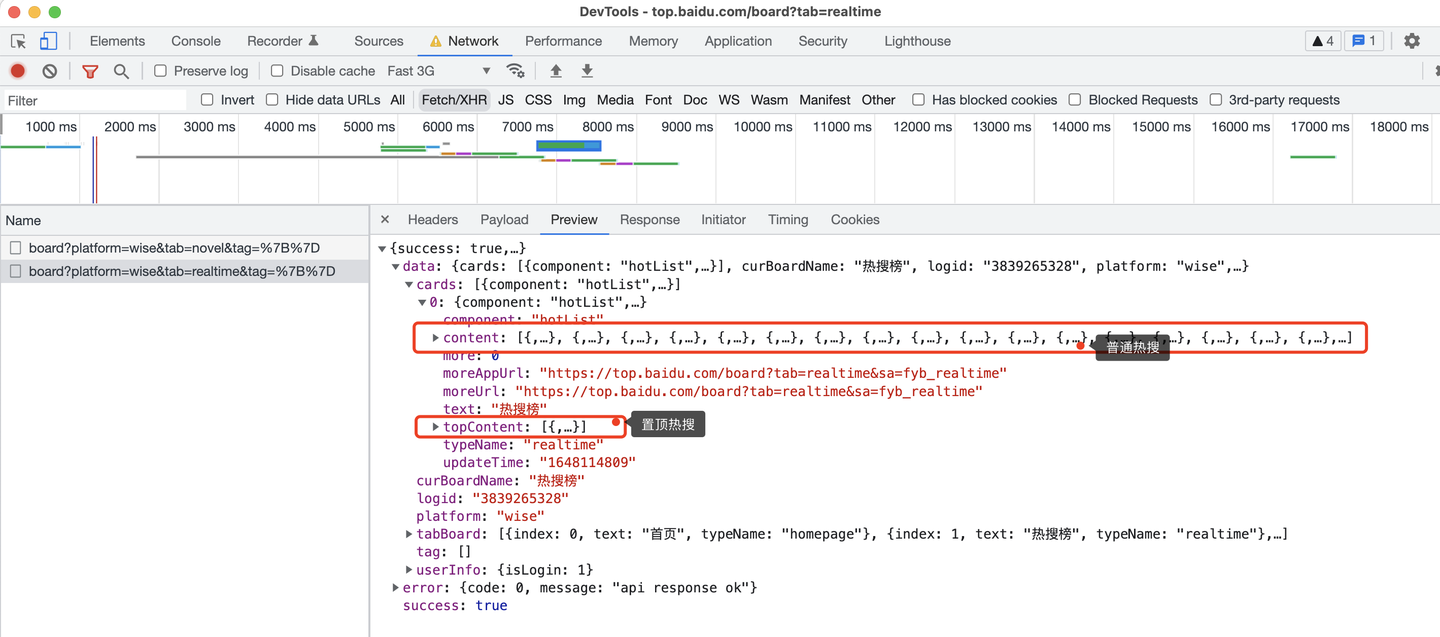
所以,爬虫代码需要分开处理逻辑:
置顶热搜:
# 爬取置顶热搜
top_content_list = json_data['data']['cards'][0]['topContent']
普通热搜:
# 爬取普通热搜
content_list = json_data['data']['cards'][0]['content']
然后再分别进行json解析,对应的字段(标题、排名、热搜指数、描述、链接地址)。
最后,保存结果数据到excel即可。
df = pd.DataFrame( # 拼装爬取到的数据为DataFrame
{
'热搜标题': title_list,
'热搜排名': order_list,
'热搜指数': score_list,
'描述': desc_list,
'链接地址': url_list
}
)
df.to_excel('百度热搜榜.xlsx', index=False) # 保存结果数据
最后,查看一下爬取到的数据:

一共31条数据(1条置顶热搜+30条普通热搜)。
每条数据包含:热搜标题、热搜排名、热搜指数、描述、链接地址。
三、同步视频讲解
讲解视频:https://www.zhihu.com/zvideo/1490668062617161728
四、完整源码
get完整源码:【爬虫案例】用Python爬取百度热搜榜数据!
我是@马哥python说,持续分享python源码干货中!
【爬虫案例】用Python爬取百度热搜榜数据!的更多相关文章
- BeautifulSoup爬取微博热搜榜
获取url 设定请求头 requests发出get请求 实例化BeautifulSoup对象 BeautifulSoup提取数据 import requests 2 from bs4 import B ...
- Python爬取微博热搜以及链接
基本操作,不再详述 直接贴源码(根据当前时间创建文件): import requests from bs4 import BeautifulSoup import time def input_to_ ...
- nodejs实现定时爬取微博热搜
The summer is coming " 我知道,那些夏天,就像青春一样回不来. - 宋冬野 青春是回不来了,倒是要准备渡过在西安的第三个夏天了. 废话 我发现,自己对 coding 这 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- python网络爬虫第三弹(<爬取get请求的页面数据>)
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是通过代码模拟浏览器发送请求,其常被用到的子模块在 python3中的为urllib.request 和 urllib ...
- Python开发简单爬虫(二)---爬取百度百科页面数据
一.开发爬虫的步骤 1.确定目标抓取策略: 打开目标页面,通过右键审查元素确定网页的url格式.数据格式.和网页编码形式. ①先看url的格式, F12观察一下链接的形式;② 再看目标文本信息的标签格 ...
- 爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释 我的第一个想法是做一个数据库,把常用的词语和词语的解释放到数据库里面,当用户查询时直接读取数据库结果 但是自己又没有心思做这样一个数 ...
- Python——爬取百度百科关键词1000个相关网页
Python简单爬虫——爬取百度百科关键词1000个相关网页——标题和简介 网站爬虫由浅入深:慢慢来 分析: 链接的URL分析: 数据格式: 爬虫基本架构模型: 本爬虫架构: 源代码: # codin ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
随机推荐
- KingbaseES中查询对象大小的SQL及函数区别
--查看所有数据库大小 select sys_database.datname, sys_size_pretty(sys_database_size(sys_database.datname)) AS ...
- KingbaseES V8R6 创建索引create index concurrently被阻塞
前言 CREATE INDEX CONCURRENTLY(CIC)是DBA们最常用的语句之一,它的好处是不阻塞DML语句. 但在大事务.长事务较多的系统,它可能被阻塞得很久. 本篇就从这个阻塞的案例开 ...
- 第十三届蓝桥杯大赛软件赛省赛【Java 大学B 组】试题C: 字符统计
1 import java.util.Scanner; 2 3 public class Main { 4 public static void main(String args[]) { 5 Sca ...
- #模拟#洛谷 5957 [POI2017]Flappy Bird
题目 分析 小鸟所在坐标的奇偶性一定相同, 考虑每次维护一个可行区间表示小鸟在当前列可以进入的纵坐标区间, 那么它有\(x_i-x_{i-1}\)的纵坐标最大改变差,然后根据奇偶性以及限制区间缩小范围 ...
- 使用site-maven-plugin在github上搭建公有仓库
目录 简介 前期准备 在maven中配置GitHub权限 配置deploy-plugin 配置site-maven-plugin 怎么使用这个共享的项目 总结 简介 Maven是我们在开发java程序 ...
- 小师妹学JavaIO之:文件读取那些事
目录 简介 字符和字节 按字符读取的方式 按字节读取的方式 寻找出错的行数 总结 简介 小师妹最新对java IO中的reader和stream产生了一点点困惑,不知道到底该用哪一个才对,怎么读取文件 ...
- 如何通过 Makefile 优化加速编译过程提高开发效率
在软件开发中,编译是一个必不可少的过程.但是,当代码规模变得越来越大时,编译时间也会变得越来越长,这会严重影响开发效率.在这种情况下,优化Makefile可以帮助我们加速编译过程,以下是一些Makef ...
- Docker学习路线11:Docker命令行
Docker CLI (命令行界面) 是一个强大的工具,可让您与 Docker 容器.映像.卷和网络进行交互和管理.它为用户提供了广泛的命令,用于在其开发和生产工作流中创建.运行和管理 Docker ...
- mysql系列之杂谈(一)
从刚开始工作到现在,除了实习的时候在国企用过oracle,毕业之后陪伴我的数据库一直都是mysql,而由于mysql的开源特性,也让成为无数公司的宠儿,越走越远. 我们在刚开始使用mysql时,会发现 ...
- java集合源码详解
一 Collection接口 1.List 1.1ArrayList 特点 1.底层实现基于动态数组,数组特点根据下表查找元素速度所以查找速度较快.继承自接口 Collection ->Lis ...