【2023微博签到爬虫】用python爬上千条m端微博签到数据
一、爬取目标
大家好,我是 @马哥python说,一枚10年程序猿。
今天分享一期python爬虫案例,爬取目标是新浪微博的微博签到数据,字段包含:
页码,微博id,微博bid,微博作者,发布时间,微博内容,签到地点,转发数,评论数,点赞数
经过分析调研,发现微博有3种访问方式,分别是:
- PC端网页:https://weibo.com/
- 移动端:https://weibo.cn/
- 手机端:https://m.weibo.cn/
最终决定,通过手机端爬取。
这里,给大家分享一个爬虫小技巧。
当目标网站既存在PC网页端,又有手机移动端,建议爬取移动端,原因是:移动端一般网页结构简单,并且反爬能力较弱,更方便爬虫爬取。
二、展示爬取结果
通过爬虫代码,爬取了“环球影城”这个关键字下的前100页微博,部分数据如下:
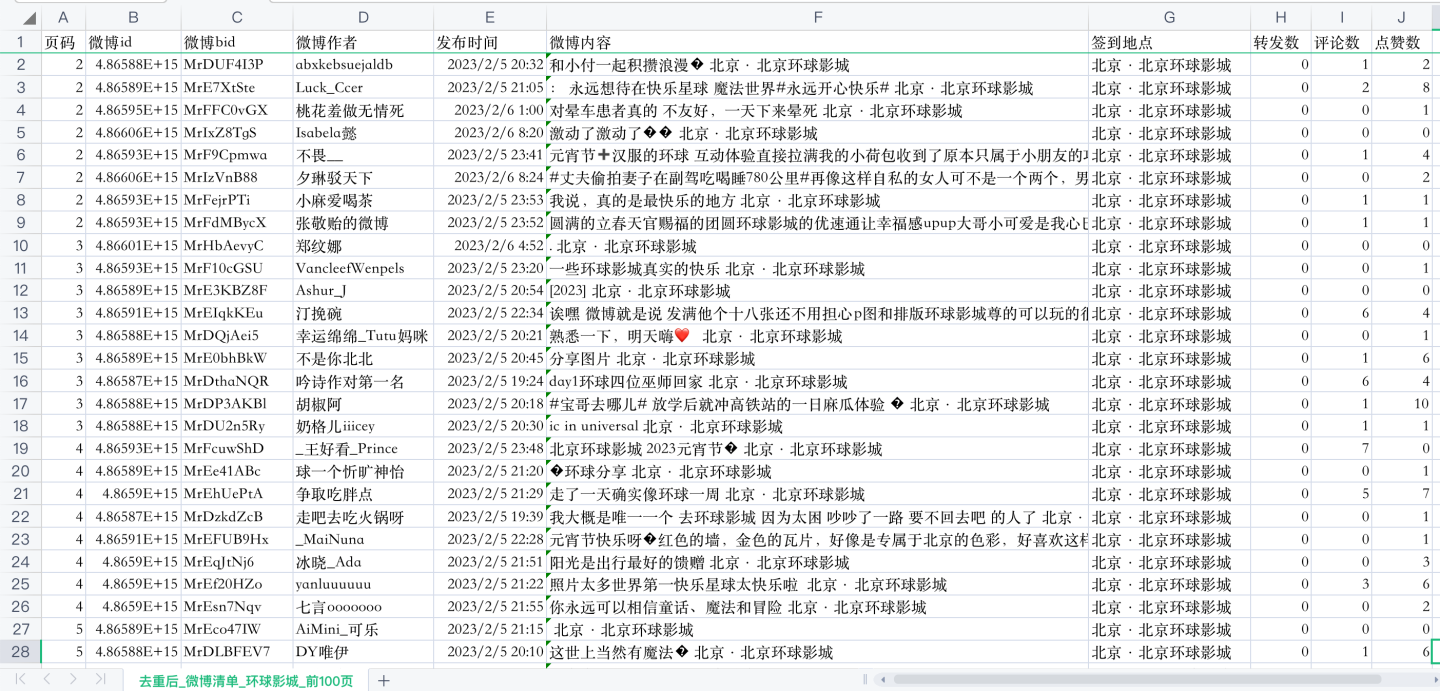
一共翻页了100页,大概1000条左右微博。
三、讲解代码
首先,导入需要用到的库:
import os # 判断文件存在
import re # 正则表达式提取文本
import requests # 发送请求
import pandas as pd # 存取csv文件
import datetime # 转换时间用
然后,定义一个转换时间字符串的函数,因为爬取到的时间戳是GMT格式(类似这种:Fri Jun 17 22:21:48 +0800 2022)的,需要转换成标准格式:
def trans_time(v_str):
"""转换GMT时间为标准格式"""
GMT_FORMAT = '%a %b %d %H:%M:%S +0800 %Y'
timeArray = datetime.datetime.strptime(v_str, GMT_FORMAT)
ret_time = timeArray.strftime("%Y-%m-%d %H:%M:%S")
return ret_time
定义一个请求头,后面发送请求的时候带上它,防止反爬:
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
}
打开chrome浏览器,在m端网址搜索"环球影城",选择地点,选择第一条搜索结果"北京环球影城",如下:
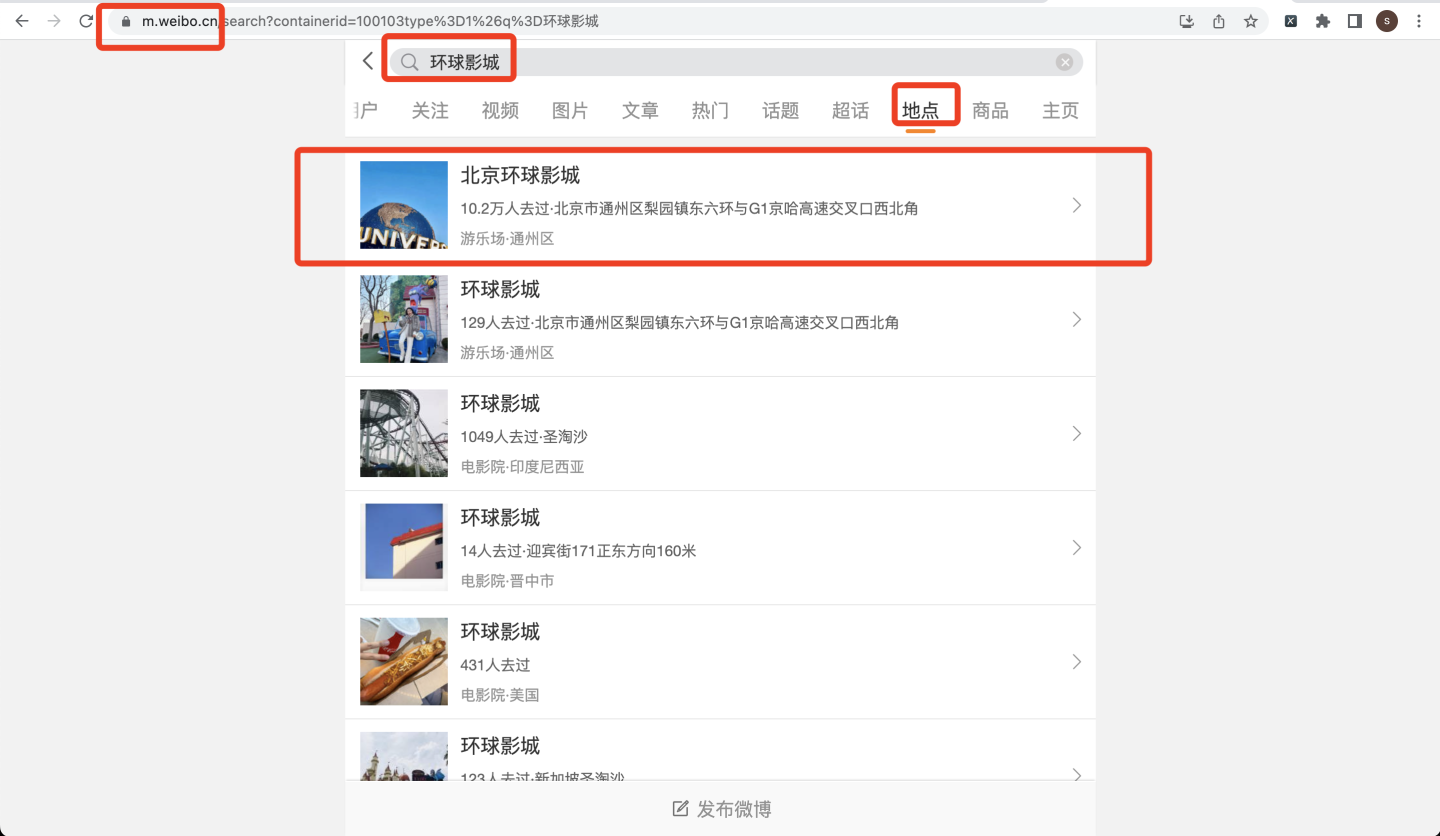
获取地点对应的containerid,后面会用到,爬虫代码如下:
def get_containerid(v_loc):
"""
获取地点对应的containerid
:param v_loc: 地点
:return: containerid
"""
url = 'https://m.weibo.cn/api/container/getIndex'
# 请求参数
params = {
"containerid": "100103type=92&q={}&t=".format(v_loc),
"page_type": "searchall",
}
r = requests.get(url, headers=headers, params=params)
cards = r.json()["data"]["cards"]
scheme = cards[0]['card_group'][0]['scheme'] # 取第一个
containerid = re.findall(r'containerid=(.*?)&', scheme)[0]
print('[{}]对应的containerid是:{}'.format(v_loc, containerid))
return containerid
点击第一个地点"北京环球影城",跳转到它对应的微博签到页面:

首先打开开发者模式,然后往下翻页,多翻几次,观察XHR页面的网络请求:
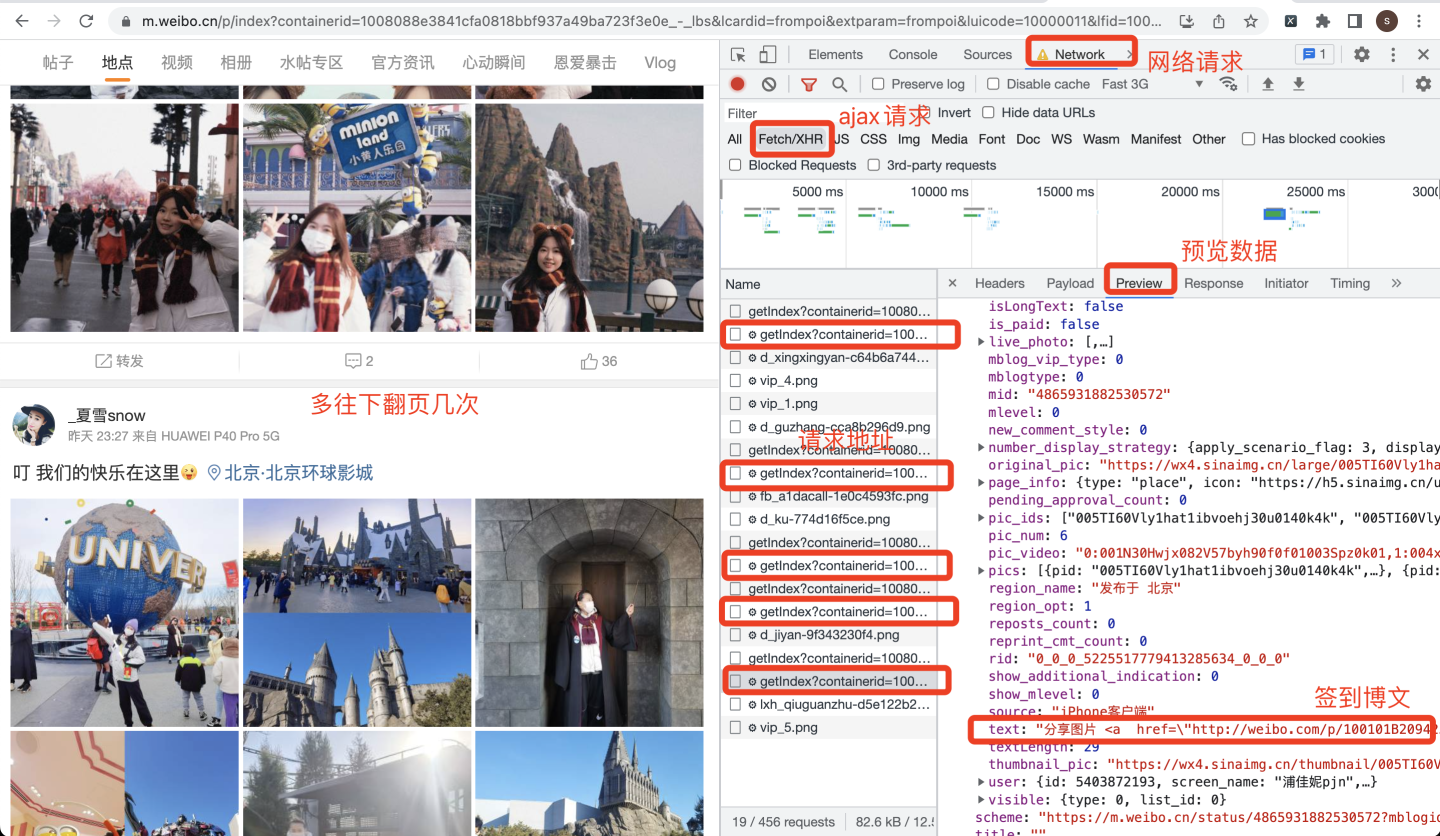
根据分析结果,编写请求代码:
# 请求地址
url = 'https://m.weibo.cn/api/container/getIndex'
# 请求参数
params = {
"containerid": containerid,
"luicode": "10000011",
"lcardid": "frompoi",
"extparam": "frompoi",
"lfid": "100103type=92&q={}".format(v_keyword),
"since_id": page,
}
其中,since_id每次翻页+1,相当于页码数值。
请求参数,可以在Payload页面获取:
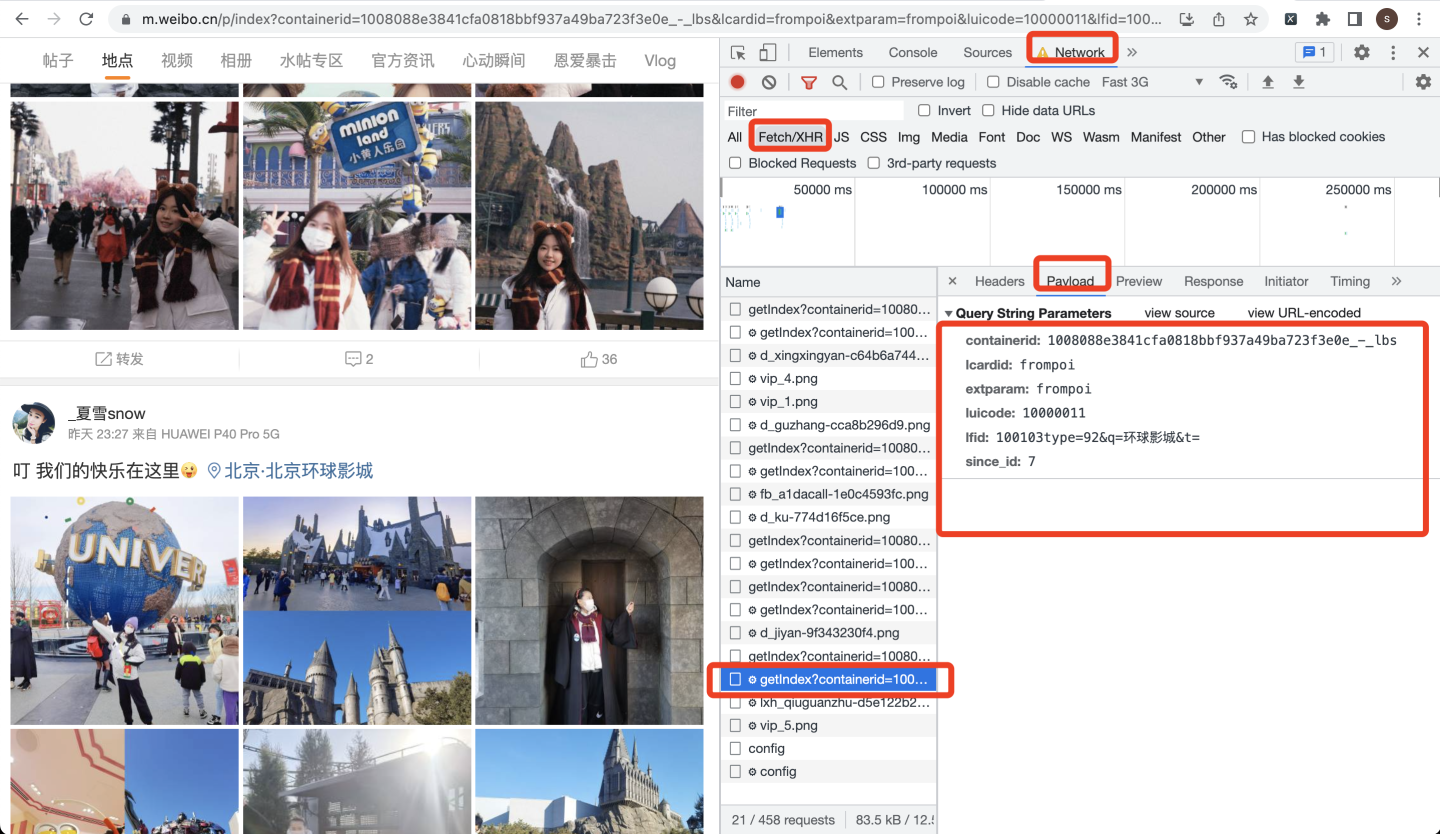
下面开始发送请求并解析数据:
# 发送请求
r = requests.get(url, headers=headers, params=params)
print(r.status_code) # 查看响应码
# 解析json数据
try:
card_group = r.json()["data"]["cards"][0]['card_group']
except:
card_group = []
定义一些空列表,用于后续保存数据:
time_list = [] # 创建时间
author_list = [] # 微博作者
id_list = [] # 微博id
bid_list = [] # 微博bid
text_list = [] # 博文
text2_list = [] # 博文2
loc_list = [] # 签到地点
reposts_count_list = [] # 转发数
comments_count_list = [] # 评论数
attitudes_count_list = [] # 点赞数
以"微博博文"为例,展示代码,其他字段同理,不再赘述。
# 微博博文
text = card['mblog']['text']
text_list.append(text)
把所有数据保存到Dataframe里面:
# 把列表数据保存成DataFrame数据
df = pd.DataFrame(
{
'页码': page,
'微博id': id_list,
'微博bid': bid_list,
'微博作者': author_list,
'发布时间': time_list,
'微博内容': text2_list,
'签到地点': loc_list,
'转发数': reposts_count_list,
'评论数': comments_count_list,
'点赞数': attitudes_count_list,
}
)
最终,把所有数据保存到csv文件:
# 表头
if os.path.exists(v_weibo_file):
header = False
else:
header = True
# 保存到csv文件
df.to_csv(v_weibo_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
print('csv保存成功:{}'.format(v_weibo_file)))
说明一下,由于每次保存csv都是追加模式(mode='a+'),所以加上if判断逻辑:
- 如果csv存在,说明不是第一次保存csv,不加表头;
- 如果csv不存在,说明是第一次保存csv,加上表头。
如此,可避免写入多次表头的尴尬局面。
整个代码中,还含有:正则表达式提取博文、爬取展开全文、从博文中提取签到地点、数据清洗(删除空数据、去重复)等功能,详细请见原始代码。
四、同步视频
代码演示视频:https://www.bilibili.com/video/BV1Pj411K7Xr
五、附完整源码
完整源码:公众号"老男孩的平凡之路"后台回复"爬微博签到"即可获取。
【python爬虫案例】爬了上千条m端微博签到数据
推荐阅读:
【python爬虫案例】爬取微博任意搜索关键词的结果,以“唐山打人”为例
【2023微博签到爬虫】用python爬上千条m端微博签到数据的更多相关文章
- XE中FMX操作ListBox,添加上千条记录(含图片)
我之前是想在ListBox的每个Item上添加一个图片,Item上所有的内容都是放在Object里赋值,结果发现加载一百条记录耗时四五秒: procedure TMainForm.AddItem; v ...
- Python爬取10000条“爆款剧”——《三十而已》热评,并做可视化
前言 继<隐秘的角落>后,又一部“爆款剧”——<三十而已>获得了口碑收视双丰收,王漫妮.顾佳.钟晓芹三个女主角的故事线频频登上微博热搜.该剧于2020年7月17日在东方卫视首播 ...
- 用Python爬取《王者荣耀》英雄皮肤数据并可视化分析,用图说话
大家好,我是辰哥~ 今天辰哥带大家分析一波当前热门手游<王者荣耀>英雄皮肤,比如皮肤上线时间.皮肤类型(勇者:史诗:传说等).价格. 1.获取数据 数据来源于<王者荣耀官方网站> ...
- Python 爬取 热词并进行分类数据分析-[拓扑数据]
日期:2020.01.29 博客期:137 星期三 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- python脚本实现接口自动化轻松搞定上千条接口用例
接口自动化目前是测试圈主流的一个话题,我也在网上搜索了很多关于自动化的关键词,大多数博主分享的python做接口自动化都是以开源的框架,比如:pytest.unittest+ddt(数据驱动) 最常见 ...
- Python爬取猪肉价格网并获取Json数据
场景 猪肉价格网站: http://zhujia.zhuwang.cc/ 注: 博客: https://blog.csdn.net/badao_liumang_qizhi 关注公众号 霸道的程序猿 获 ...
- python爬取千库网
url:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/ 有水印 但是点进去就没了 这里先来测试是否有反爬虫 import requests ...
- python爬取post请求Reque Payload的json数据
import requests,json url = "https://www.yijiupi.com/v31/Product/ListProduct" headers = { ' ...
- 将Excel上千条数据写入到数据库中
简要说明:因工作需要,需要一张Excel表格中的所有数据导入到数据库中.如下表,当然这只是一部分,一共一千多条. 前期处理: 首先要保证上图中的Excel表格中的数据不能为空,如果有为空的数据,可以稍 ...
- 四步法分析定位生产环境下MySQL上千条SQL中的问题所在
第一步:通过以下两种方式之一来打开慢查询功能 (1)方式一:通过修改mysql的my.cnf文件 如果是5.0或5.1等版本需要增加以下选项: log-slow-queries="mysql ...
随机推荐
- QT数据库学习笔记
简介 QT通过模块化管理,对于某种模块需要添加对应的模块实现.QT SQL也是需要增加对应的模块来实现.QT数据库的层次关系为: 驱动层:数据库到SQL语言之间的桥梁 SQL API层: SQL语句的 ...
- 探索华为云CCE敏捷版金融级高可用方案实践案例
本文分享自华为云社区<华为云CCE敏捷版金融级高可用方案实践>,作者: 云容器大未来. 一.背景 1.1. CCE 敏捷版介绍 云原生技术有利于各组织在公有云.私有云和混合云等新型动态环境 ...
- MobileNext:打破常规,依图逆向改造inverted residual block | ECCV 2020
论文深入分析了inverted residual block的设计理念和缺点,提出更适合轻量级网络的sandglass block,基于该结构搭建的MobileNext.根据论文的实验结果,Mobil ...
- Collation 差异导致 KingbaseES 与 Oracle 查询结果不同
问题引入 前端提了个问题,说是KingbaseES 返回的结果与 Oracle 返回的结果不一样.具体问题如下: oracle 执行结果:oracle 有结果返回. SQL> create ta ...
- Amazon免费CE2基于docker部署nginx,并实现访问
在部署之前,请确保你已经申请好了CE2免费的服务器,网上的相关教程很多,可以自由参考. 一.使用xshell+公钥连接实例 1.打开xshell,导入密钥, 选择"工具" -> ...
- SPEL表达式注入分析
环境依赖 <dependencies> <dependency> <groupId>org.springframework</groupId> < ...
- 【已解决】git reset命令误删本地文件怎么恢复
执行 git reflog 命令可以看到曾经执行过的操作,还有版本序号. 执行 git reset --hard HEAD@{[填那个序号]} 就可以恢复本地删除的文件了!
- PyQt5 GUI编程(QMainWindow与QWidget模块结合使用)
一.简介 QWidget是所有用户界面对象的基类,而QMainWindow用于创建主应用程序窗口的类.它是QWidget的一个子类,提供了创建具有菜单栏.工具栏.状态栏等的主窗口所需的功能.上篇主要介 ...
- #最小生成树,Trie#CF888G Xor-MST
题目 给定 \(n\) 个结点的无向完全图.每个点有一个点权为 \(a_i\) . 连接 \(i\) 号结点和 \(j\) 号结点的边的边权为 \(a_i\oplus a_j\) . 求这个图的 MS ...
- OpenHarmony自定义构建函数:@Builder装饰器
前面章节介绍了如何创建一个自定义组件.该自定义组件内部UI结构固定,仅与使用方进行数据传递.ArkUI还提供了一种更轻量的UI元素复用机制@Builder,@Builder所装饰的函数遵循buil ...