浅析 Jetty 中的线程优化思路
作者:vivo 互联网服务器团队- Wang Ke
本文介绍了 Jetty 中 ManagedSelector 和 ExecutionStrategy 的设计实现,通过与原生 select 调用的对比揭示了 Jetty 的线程优化思路。Jetty 设计了一个自适应的线程执行策略(EatWhatYouKill),在不出现线程饥饿的情况下尽量用同一个线程侦测 I/O 事件和处理 I/O 事件,充分利用了 CPU 缓存并减少了线程切换的开销。这种优化思路对于有大量 I/O 操作场景下的性能优化具有一定的借鉴意义。
一、什么是 Jetty
Jetty 跟 Tomcat 一样是一种 Web 容器,它的总体架构设计如下:
Jetty 总体上由一系列 Connector、一系列 Handler 和一个 ThreadPool组成。
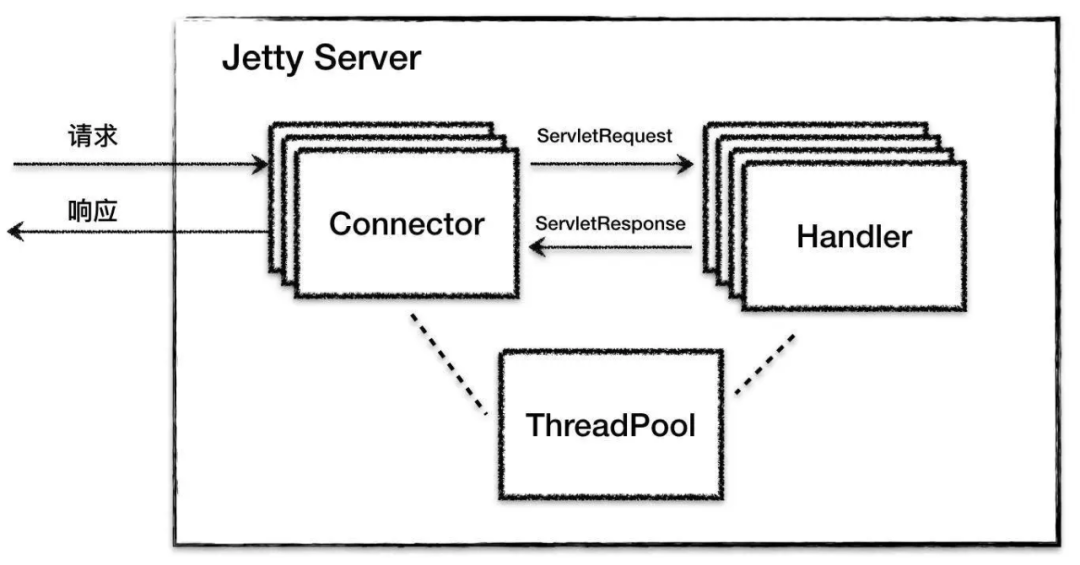
Connector 也就是 Jetty 的连接器组件,相比较 Tomcat 的连接器,Jetty 的连接器在设计上有自己的特点。
Jetty 的 Connector 支持 NIO 通信模型,NIO 模型中的主角是 Selector,Jetty 在 Java 原生 Selector 的基础上封装了自己的 Selector:ManagedSelector。
二、Jetty 中的 Selector 交互
2.1 传统的 Selector 实现
常规的 NIO 编程思路是将 I/O 事件的侦测和请求的处理分别用不同的线程处理。
具体过程是:
- 启动一个线程;
- 在一个死循环里不断地调用 select 方法,检测 Channel 的 I/O 状态;
- 一旦 I/O 事件到达,就把该 I/O 事件以及一些数据包装成一个 Runnable;
- 将 Runnable 放到新线程中去处理。
这个过程有两个线程在干活:一个是 I/O 事件检测线程、一个是 I/O 事件处理线程。
这两个线程是"生产者"和"消费者"的关系。
这样设计的好处:
将两个工作用不同的线程处理,好处是它们互不干扰和阻塞对方。
这样设计的缺陷:
当 Selector 检测读就绪事件时,数据已经被拷贝到内核中的缓存了,同时 CPU 的缓存中也有这些数据了。
这时当应用程序去读这些数据时,如果用另一个线程去读,很有可能这个读线程使用另一个 CPU 核,而不是之前那个检测数据就绪的 CPU 核。
这样 CPU 缓存中的数据就用不上了,并且线程切换也需要开销。
2.2 Jetty 中的 ManagedSelector 实现
Jetty 的 Connector 将 I/O 事件的生产和消费放到同一个线程处理。
如果执行过程中线程不阻塞,操作系统会用同一个 CPU 核来执行这两个任务,这样既能充分利用 CPU 缓存,又可以减少线程上下文切换的开销。
ManagedSelector 本质上是一个 Selector,负责 I/O 事件的检测和分发。
为了方便使用,Jetty 在 Java 原生 Selector 的基础上做了一些扩展,它的成员变量如下:
public class ManagedSelector extends ContainerLifeCycle implements Dumpable
{
// 原子变量,表明当前的ManagedSelector是否已经启动
private final AtomicBoolean _started = new AtomicBoolean(false);
// 表明是否阻塞在select调用上
private boolean _selecting = false;
// 管理器的引用,SelectorManager管理若干ManagedSelector的生命周期
private final SelectorManager _selectorManager;
// ManagedSelector的id
private final int _id;
// 关键的执行策略,生产者和消费者是否在同一个线程处理由它决定
private final ExecutionStrategy _strategy;
// Java原生的Selector
private Selector _selector;
// "Selector更新任务"队列
private Deque<SelectorUpdate> _updates = new ArrayDeque<>();
private Deque<SelectorUpdate> _updateable = new ArrayDeque<>();
...
}2.2.1 SelectorUpdate 接口
为什么需要一个"Selector更新任务"队列呢?
对于 Selector 的用户来说,我们对 Selector 的操作无非是将 Channel 注册到 Selector 或者告诉 Selector 我对什么 I/O 事件感兴趣。
这些操作其实就是对 Selector 状态的更新,Jetty 把这些操作抽象成 SelectorUpdate 接口。
/**
* A selector update to be done when the selector has been woken.
*/
public interface SelectorUpdate
{
void update(Selector selector);
}这意味着不能直接操作 ManagedSelector 中的 Selector,而是需要向 ManagedSelector 提交一个任务类。
这个类需要实现 SelectorUpdate 接口的 update 方法,在 update 方法中定义要对 ManagedSelector 做的操作。
比如 Connector 中的 Endpoint 组件对读就绪事件感兴趣。
它就向 ManagedSelector 提交了一个内部任务类 ManagedSelector.SelectorUpdate:
_selector.submit(_updateKeyAction);这个 _updateKeyAction 就是一个 SelectorUpdate 实例,它的 update 方法实现如下:
private final ManagedSelector.SelectorUpdate _updateKeyAction = new ManagedSelector.SelectorUpdate()
{
@Override
public void update(Selector selector)
{
// 这里的updateKey其实就是调用了SelectionKey.interestOps(OP_READ);
updateKey();
}
};在 update 方法里,调用了 SelectionKey 类的 interestOps 方法,传入的参数是 OP_READ,意思是我对这个 Channel 上的读就绪事件感兴趣。
2.2.2 Selectable 接口
上面有了 update 方法,那谁来执行这些 update 呢,答案是 ManagedSelector 自己。
它在一个死循环里拉取这些 SelectorUpdate 任务逐个执行。
I/O 事件到达时,ManagedSelector 通过一个任务类接口(Selectable 接口)来确定由哪个函数处理这个事件。
public interface Selectable
{
// 当某一个Channel的I/O事件就绪后,ManagedSelector会调用的回调函数
Runnable onSelected();
// 当所有事件处理完了之后ManagedSelector会调的回调函数
void updateKey();
}Selectable 接口的 onSelected() 方法返回一个 Runnable,这个 Runnable 就是 I/O 事件就绪时相应的处理逻辑。
ManagedSelector 在检测到某个 Channel 上的 I/O 事件就绪时,ManagedSelector 调用这个 Channel 所绑定的类的 onSelected 方法来拿到一个 Runnable。
然后把 Runnable 扔给线程池去执行。
三、Jetty 的线程优化思路
3.1 Jetty 中的 ExecutionStrategy 实现
前面介绍了 ManagedSelector 的使用交互:
如何注册 Channel 以及 I/O 事件
提供什么样的处理类来处理 I/O 事件
那么 ManagedSelector 如何统一管理和维护用户注册的 Channel 集合呢,答案是 ExecutionStrategy 接口。
这个接口将具体任务的生产委托给内部接口 Producer,而在自己的 produce 方法里实现具体执行逻辑。
这个 Runnable 的任务可以由当前线程执行,也可以放到新线程中执行。
public interface ExecutionStrategy
{
// 只在HTTP2中用到的一个方法,暂时忽略
public void dispatch();
// 实现具体执行策略,任务生产出来后可能由当前线程执行,也可能由新线程来执行
public void produce();
// 任务的生产委托给Producer内部接口
public interface Producer
{
// 生产一个Runnable(任务)
Runnable produce();
}
}实现 Produce 接口生产任务,一旦任务生产出来,ExecutionStrategy 会负责执行这个任务。
private class SelectorProducer implements ExecutionStrategy.Producer
{
private Set<SelectionKey> _keys = Collections.emptySet();
private Iterator<SelectionKey> _cursor = Collections.emptyIterator();
@Override
public Runnable produce()
{
while (true)
{
// 如果Channel集合中有I/O事件就绪,调用前面提到的Selectable接口获取Runnable,直接返回给ExecutionStrategy去处理
Runnable task = processSelected();
if (task != null)
return task;
// 如果没有I/O事件就绪,就干点杂活,看看有没有客户提交了更新Selector的任务,就是上面提到的SelectorUpdate任务类。
processUpdates();
updateKeys();
// 继续执行select方法,侦测I/O就绪事件
if (!select())
return null;
}
}
}SelectorProducer 是 ManagedSelector 的内部类。
SelectorProducer 实现了 ExecutionStrategy 中的 Producer 接口中的 produce 方法,需要向 ExecutionStrategy 返回一个 Runnable。
在 produce 方法中 SelectorProducer 主要干了三件事:
如果 Channel 集合中有 I/O 事件就绪,调用前面提到的 Selectable 接口获取 Runnable,直接返回给 ExecutionStrategy 处理。
如果没有 I/O 事件就绪,就干点杂活,看看有没有客户提交了更新 Selector 上事件注册的任务,也就是上面提到的 SelectorUpdate 任务类。
干完杂活继续执行 select 方法,侦测 I/O 就绪事件。
3.2 Jetty 的线程执行策略
3.2.1 ProduceConsume(PC) 线程执行策略
任务生产者自己依次生产和执行任务,对应到 NIO 通信模型就是用一个线程来侦测和处理一个 ManagedSelector 上的所有的 I/O 事件。
后面的 I/O 事件要等待前面的 I/O 事件处理完,效率明显不高。

图中,绿色代表生产一个任务,蓝色代表执行这个任务,下同。
3.2.2 ProduceExecuteConsume(PEC) 线程执行策略
任务生产者开启新线程来执行任务,这是典型的 I/O 事件侦测和处理用不同的线程来处理。
缺点是不能利用 CPU 缓存,并且线程切换成本高。
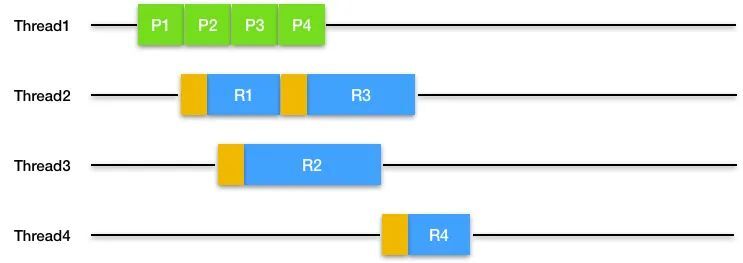
图中,棕色代表线程切换,下同。
3.2.3 ExecuteProduceConsume(EPC) 线程执行策略
任务生产者自己运行任务,这种方式可能会新建一个新的线程来继续生产和执行任务。
它的优点是能利用 CPU 缓存,但是潜在的问题是如果处理 I/O 事件的业务代码执行时间过长,会导致线程大量阻塞和线程饥饿。
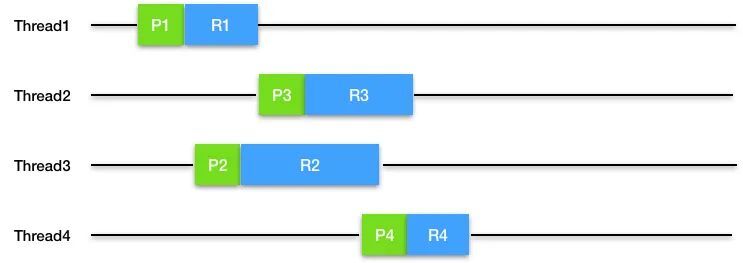
3.2.4 EatWhatYouKill(EWYK) 改良线程执行策略
这是 Jetty 对 ExecuteProduceConsume 策略的改良,在线程池线程充足的情况下等同于 ExecuteProduceConsume;
当系统比较忙线程不够时,切换成 ProduceExecuteConsume 策略。
这么做的原因是:
ExecuteProduceConsume 是在同一线程执行 I/O 事件的生产和消费,它使用的线程来自 Jetty 全局的线程池,这些线程有可能被业务代码阻塞,如果阻塞的多了,全局线程池中线程自然就不够用了,最坏的情况是连 I/O 事件的侦测都没有线程可用了,会导致 Connector 拒绝浏览器请求。
于是 Jetty 做了一个优化:
在低线程情况下,就执行 ProduceExecuteConsume 策略,I/O 侦测用专门的线程处理, I/O 事件的处理扔给线程池处理,其实就是放到线程池的队列里慢慢处理。
四、总结
本文基于 Jetty-9 介绍了 ManagedSelector 和 ExecutionStrategy 的设计实现,介绍了 PC、PEC、EPC 三种线程执行策略的差异,从 Jetty 对线程执行策略的改良操作中可以看出,Jetty 的线程执行策略会优先使用 EPC 使得生产和消费任务能够在同一个线程上运行,这样做可以充分利用热缓存,避免调度延迟。
这给我们做性能优化也提供了一些思路:
在保证不发生线程饥饿的情况下,尽量使用同一个线程生产和消费可以充分利用 CPU 缓存,并减少线程切换的开销。
根据实际场景选择最适合的执行策略,通过组合多个子策略也可以扬长避短达到1+1>2的效果。
参考文档:
浅析 Jetty 中的线程优化思路的更多相关文章
- 浅析Java中的线程池
Java中的线程池 几乎所有需要异步或并发执行任务的程序都可以使用线程池,开发过程中合理使用线程池能够带来以下三个好处: 降低资源消耗 提高响应速度 提高线程的可管理性 1. 线程池的实现原理 当我们 ...
- ubuntu之路——day7.1 衡量模型好坏的因素偏差和方差bias&variance 以及在深度学习中的模型优化思路
Error | 误差 Bias | 偏差 – 衡量准确性 Variance | 方差 – 衡量稳定性 首先我们通常在实际操作中会直接用错误率或者与之对应的准确率来衡量一个模型的好坏,但是更加准确的做法 ...
- redis在实践中的一些常见问题以及优化思路
1.fork耗时导致高并发请求延时 RDB和AOF的时候,其实会有生成RDB快照,AOF rewrite,耗费磁盘IO的过程,主进程fork子进程 fork的时候,子进程是需要拷贝父进程的空间内存页表 ...
- 转:使用RNN解决NLP中序列标注问题的通用优化思路
http://blog.csdn.net/malefactor/article/details/50725480 /* 版权声明:可以任意转载,转载时请标明文章原始出处和作者信息 .*/ author ...
- java并发学习--第八章 JDK 8 中线程优化的新特性
一.新增原子类LongAdder LongAdder是JDK8中AtomicLong的增强工具类,它与AtomicLong最大的不同就是:在多线程场景下,LongAdder中对单一的变量进行拆分成多个 ...
- 浅析Java中线程组(ThreadGroup类)
Java中使用ThreadGroup类来代表线程组,表示一组线程的集合,可以对一批线程和线程组进行管理.可以把线程归属到某一个线程组中,线程组中可以有线程对象,也可以有线程组,组中还可以有线程,这样的 ...
- 浅析Java7中的ConcurrentHashMap
引入ConcurrentHashMap 模拟使用hashmap在多线程场景下发生线程不安全现象 import java.util.HashMap; import java.util.Map; impo ...
- Kafka 协议实现中的内存优化
Kafka 协议实现中的内存优化 Kafka 协议实现中的内存优化 Jusfr 原创,转载请注明来自博客园 Request 与 Response 的响应格式 Request 与 Response ...
- PHP优化思路
想起来记录一下自己对PHP的优化思路 针对Nginx和 PHP-FPM进行优化 首先应该分为代码层面.配置层面.架构层面 代码层面 参见了https://segmentfault.com/a/1190 ...
- Kafka 协议实现中的内存优化【转】
Kafka 协议实现中的内存优化 Jusfr 原创,转载请注明来自博客园 Request 与 Response 的响应格式 Request 与 Response 都是以 长度+内容 形式描述, 见 ...
随机推荐
- centos7搭建bsc全节点
Centos7搭建bsc全链节点 服务器配置 CPU:8 Cores - 16 Threads RAM:131072 MB Storage:2x 2000GB NVMe Bandwidth:8400 ...
- Mybatis 获取自增主键 useGeneratedKeys与keyProperty解答
Mybatis 获取自增主键 31bafebb-a95b-4c35-a949-8bc335ec6e2e 今天开发的时候遇到一个疑惑,业务场景是这样的, 但是百度好久没有找到合适的解答,于是自己向同事了 ...
- [软件体系结构/架构]零拷贝技术(Zero-copy)[转发]
0 前言 近期遇到难题:1个大数据集的查询导出API,因从数据库查询后占用内存极大,每次调用将消耗近100MB的JVM内存资源.故现需考虑研究和应用零拷贝技术. 如下全文摘自: 看一遍就理解:零拷贝原 ...
- 派生,super 多态与多态性 组合
派生的方法与重用: 方法一:指名道姓的调用某一类函数 >>> class Teacher(People): ... def __init__(self,name,sex,age,ti ...
- 带你揭开神秘的javascript AST面纱之AST 基础与功能
作者:京东科技 周明亮 AST 基础与功能 在前端里面有一个很重要的概念,也是最原子化的内容,就是 AST ,几乎所有的框架,都是基于 AST 进行改造运行,比如:React / Vue /Taro ...
- MySQL匿名空用户名处理
问题描述:公司漏扫发现数据库内出现空用户名及密码,需要对这些用户进行整改 1.首先出现了疑问,这些空的用户名是怎么出现的,而且不附带密码. 2.可以手动这样创建这样的用户名和密码形式么. 3.如果能这 ...
- 企事业单位通用版招采系统(SRM),招采全过程闭环流程
前言 采购供应商管理的难点:沟通耗费精力,业务协同难,管控混乱.优质的供应商,是直接能够影响采购成本和企业采购战略落地的,而供应商管理的终极路径是建立企业自己的供应商私域流量池. 一.供应商管理 1. ...
- Ubuntu上Git的简单配置及使用(使用的代码托管平台为gitee码云)
目录 1.关于gitee 2.Ubuntu下Git的下载及配置 3.使用Git连接到远程的Gitee仓库 4.常用命令 1.关于gitee Gitee(码云) 是 OSCHINA.NET 推出的代码托 ...
- 迁移学习(PAT)《Pairwise Adversarial Training for Unsupervised Class-imbalanced Domain Adaptation》
论文信息 论文标题:Pairwise Adversarial Training for Unsupervised Class-imbalanced Domain Adaptation论文作者:Weil ...
- 关于Java中值传递和址传递
参数传递在Java中有两种类型 值和址 其实本质都是一份拷贝 在调用函数的时候 进行压栈 传进来的参数会被开辟一份新的空间 传基本类型是把值传过去 传引用数据类型是实例指向实参 void m(int ...