如何处理分析Flink作业反压的问题?
摘要:反压是 Flink 应用运维中常见的问题,它不仅意味着性能瓶颈还可能导致作业的不稳定性。
反压(backpressure)是实时计算应用开发中,特别是流式计算中,十分常见的问题。反压意味着数据管道中某个节点成为瓶颈,处理速率跟不上上游发送数据的速率,而需要对上游进行限速。
问题场景
客户作业场景如下图所示,从DMS kafka通过DLI Flink将业务数据实时清洗存储到DWS。

其中,DMS Kafka 目标Topic 6个分区,DLI Flink作业配置taskmanager数量为12,并发数为1。
问题现象
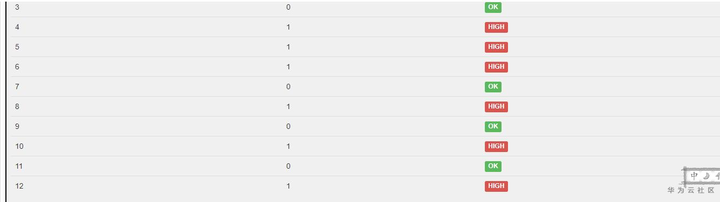
客户在DLI服务共有三个相同规格的队列,该作业在其中003号队列上运行正常,在001和002号队列上都存在严重的反压导致数据处理缓慢。作业列表显示如下图,可以看到Sink反压状态正常,Souce和Map反压状态为HIGH。

问题分析
根据反压情况分析,该作业的性能瓶颈在Sink,由于Sink处理数据缓慢导致上游反压严重。
该作业所定义的Sink类型为DwsCsvSink,该Sink的工作原理如下图所示:Sink将结果数据分片写入到OBS,每一分片写入完成后,调用DWS insert select sql将obs路径下该分片数据load到dws。
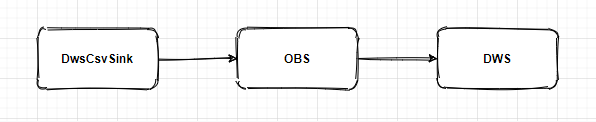
因此性能瓶颈出现在分片数据写入到OBS这一步。但问题来了,写同一个桶,为什么在不同队列上的表现不一致?
为此,我们排查了各个队列的CPU、内存和网络带宽情况,结果显示负载都很低。
这种情况下,只能继续分析FlinkUI和TaskManager日志。
数据倾斜?
然后我们在FlinkUI任务情况页面,看到如下情况:Map阶段的12个TaskManager并不是所有反压都很严重,而是只有一半是HIGH状态,难道有数据倾斜导致分配到不同TaskManager的数据不均匀?
然后看Source subTask详情,发现有两个TaskManager读取的数据量是其他几个的几十倍,这说明源端Kafka分区流入的数据量不均匀。难道就是这么简单的问题?
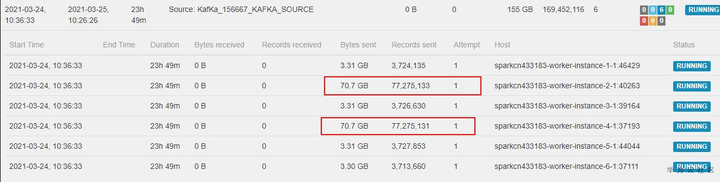
很不幸并不是,通过进一步分析源端数据我们发现Kafka 6个分区数据流入记录数相差并不大。这两个Task只是多消费了部分存量数据,接收数据增长的速度各TaskManager保持一致。
时钟同步
进一步分析TaskManager日志,我们发现单个分片数据写入OBS竟然耗费3min以上。这非常异常,要知道单个分片数据才500000条而已。
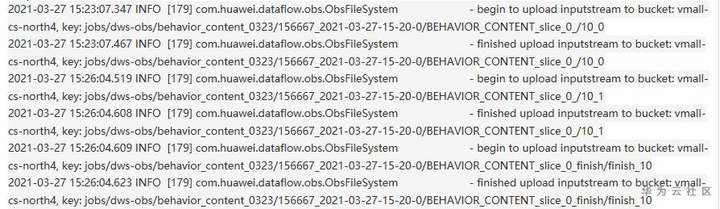
进一步通过分析代码发现如下问题:在写OBS数据时,其中一个taskmanager写分片目录后获取该目录的最后修改时间,作为处理该分片的开始时间,该时间为OBS服务端的时间。

后续其他taskmanager向该分片目录写数据时,会获取本地时间与分片开始时间对比,间隔大于所规定的转储周期才会写分片数据。
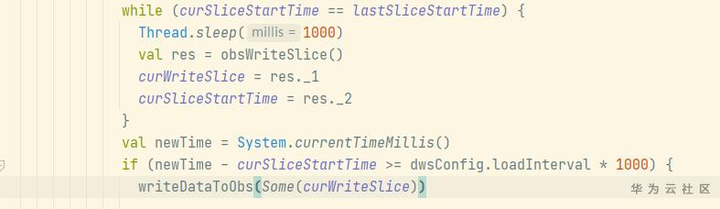
如果集群节点NTP时间与OBS服务端不同步,本地时间晚于OBS服务端时间,则会造成写入OBS等待。
后续排查集群节点,发现6个节点中一半时间同步有问题,这也和只有一半taskmanager反压严重的现象相对应。
问题修复
在集群节点上执行如下命令,强制时间同步。
systemctl stop ntp
ntpdate ntp.myhuaweicloud.com
systemctl start ntp
systemctl status ntp
date
NTP同步后,作业反压很快消失,故障恢复。

本文分享自华为云社区《一个Flink作业反压的问题分析》,原文作者:Yunz Bao 。
如何处理分析Flink作业反压的问题?的更多相关文章
- 如何分析及处理 Flink 反压?
反压(backpressure)是实时计算应用开发中,特别是流式计算中,十分常见的问题.反压意味着数据管道中某个节点成为瓶颈,处理速率跟不上上游发送数据的速率,而需要对上游进行限速.由于实时计算应用通 ...
- Flink中发送端反压以及Credit机制(源码分析)
上一篇<Flink接收端反压机制>说到因为Flink每个Task的接收端和发送端是共享一个bufferPool的,形成了天然的反压机制,当Task接收数据的时候,接收端会根据积压的数据量以 ...
- 一文搞懂 Flink 网络流控与反压机制
https://www.jianshu.com/p/2779e73abcb8 看完本文,你能get到以下知识 Flink 流处理为什么需要网络流控? Flink V1.5 版之前网络流控介绍 Flin ...
- 咱们从头到尾讲一次 Flink 网络流控和反压剖析
本文根据 Apache Flink 系列直播整理而成,由 Apache Flink Contributor.OPPO 大数据平台研发负责人张俊老师分享.主要内容如下: 网络流控的概念与背景 TCP的流 ...
- Flink 反压 浅入浅出
前言 微信搜[Java3y]关注这个朴实无华的男人,点赞关注是对我最大的支持! 文本已收录至我的GitHub:https://github.com/ZhongFuCheng3y/3y,有300多篇原创 ...
- [转帖]实时流处理系统反压机制(BackPressure)综述
实时流处理系统反压机制(BackPressure)综述 https://blog.csdn.net/qq_21125183/article/details/80708142 2018-06-15 19 ...
- Flink中接收端反压以及Credit机制 (源码分析)
先上一张图整体了解Flink中的反压 可以看到每个task都会有自己对应的IG(inputgate)对接上游发送过来的数据和RS(resultPatation)对接往下游发送数据, 整个反压机制通 ...
- flink - 反压
http://wuchong.me/blog/2016/04/26/flink-internals-how-to-handle-backpressure/ https://ci.apache.org/ ...
- 1、flink介绍,反压原理
一.flink介绍 Apache Flink是一个分布式大数据处理引擎,可对有界数据流和无界数据流进行有状态计算. 可部署在各种集群环境,对各种大小的数据规模进行快速计算. 1.1.有界数据流和无界 ...
- flink反压的监控
反压在流式系统中是一种非常重要的机制,主要作用是当系统中下游算子的处理速度下降,导致数据处理速率低于数据接入的速率时,通过反向背压的方式让数据接入的速率下降,从而避免大量数据积压在flink系统中,最 ...
随机推荐
- MPL协议原文
MPL协议原文 原文参考链接 中文翻译有一个,但是只翻译了两条 原文 Mozilla Public License Version 2.0 1. Definitions 1.1. "Cont ...
- 每天5分钟复习OpenStack(六)CPU虚拟化<2>
OpenStack是 一个IAAS(基础设施即服务)因此免不了会与硬件打交道.下面我介绍下与CPU强关联的一些知识点.1 什么是超配 2 CPU的个数是怎么统计的 3 vCPU的隔离.绑定 1.超配 ...
- GameFramework摘录 - 1. ReferencePool
GameFramework是一个结构很优秀的Unity游戏框架,但意图似乎在构建可跨引擎的框架?对要求不高的小型个人(不专业)开发来说有些设计过度了,但其中的设计精华很值得学习. 首先来说一下其中的R ...
- Mach-O Inside: 命令行工具集 otool objdump od 与 dwarfdump
1 otool otool 命令行工具用来查看 Mach-O 文件的结构. 1.1 查看文件头 otool -h -v 文件路径 -h选项表明查看 Mach-O 文件头. -v 选项表明将展示的内容进 ...
- SNN_LIF模型
LIF模型 Leaky integrity-Fire(LIF)模型 输入信号直接影响神经元的状态,即神经元膜电位,只有当膜电位上升到阈值的时候,才会产生输出信号. 膜电位:细胞膜两侧的电位差.只有当膜 ...
- centos7安装glibc_2.28和gcc 8.2
centos7默认的gcc版本是4.8.5,无法编译高版本的glibc 2.28,需要升级到gcc 8.2版本 注:gcc高版本和glibc 2.28不兼容 ## 查看自带默认的glibc strin ...
- APISIX proxy-cache 插件用法
APISIX 的 proxy-cache 插件可以对上游的查询进行缓存,这样就不需要上游的应用服务自己实现缓存了,或者也能少实现一部分缓存,通用的交给插件来做. 下面的操作都是基于 APISIX 3. ...
- 自学day7 数组
typora-copy-images-to: media 数组 一.概念 对象中可以通过键值对存储多个数据,且数据的类型是没有限制的,所以通常会存储一个商品的信息或一个人的信息: var obj = ...
- 实现金蝶云星空与赛意SMOM系统的无缝数据对接
1. 金蝶云星空:为运营协同与管控型企业提供通用ERP服务平台 金蝶云星空是基于当今先进管理理论和数十万家国内客户最佳应用实践开发的ERP服务平台.它针对事业部制.多地点.多工厂等企业和集团公司,提供 ...
- 关于Maven执行mvn help:system命令报错
报错: [ERROR] Error executing Maven.[ERROR] 2 problems were encountered while building the effective s ...