Transformer 估算 101
本文主要介绍用于估算 transformer 类模型计算量需求和内存需求的相关数学方法。
引言
其实,很多有关 transformer 语言模型的一些基本且重要的信息都可以用很简单的方法估算出来。不幸的是,这些公式在 NLP 社区中鲜为人知。本文的目的是总结这些公式,阐明它们是如何推导出来的及其作用。
注意: 本文主要关注训练成本,该成本主要由 GPU 的 VRAM 主导。如果你想知道有关推理成本 (通常由推理延迟主导) 的信息,可以读读 Kipply 写的 这篇精彩博文。
算力要求
下式可用于估算训练一个 transformer 模型所需的算力成本:
\]
这里:
- \(C\) 是训练 transformer 模型所需的计算量,单位为总浮点运算数 (FLOP)
- \(C=C_{\text {前向}}+C_{\text {后向}}\)
- \(C_{\text {前向}} \approx 2PD\)
- \(C_{\text {后向}} \approx 4PD\)
- \(\tau\) 是训练集群的实际总吞吐量: \(\tau=\text {GPU 数} \times \text {每 GPU 的实际每秒浮点运算数 (实际 FLOPs) }\),单位为 FLOPs
- \(T\) 是训练模型所花费的时间,以秒为单位
- \(P\) 是 transformer 模型的参数量
- \(D\) 是数据集大小,表示为数据集的总词元数
该式由 OpenAI 的缩放定律论文 和 DeepMind 的缩放定律论文 提出并经其实验验证。想要获取更多信息,可参阅这两篇论文。
下面,我们讨论一下 \(C\) 的单位。 \(C\) 是总计算量的度量,我们可以用许多单位来度量它,例如:
FLOP - 秒,单位为 \({\text {每秒浮点运算数}} \times \text {秒}\)GPU - 时,单位为 \(\text {GPU 数}\times\text {小时}\)- 缩放定律论文倾向于以
PetaFLOP - 天为单位,即单位为 \(10^{15} \times 24 \times 3600\)
这里需要注意 \(\text {实际 FLOPs}\) 的概念。虽然 GPU 的规格书上通常只宣传其理论 FLOPs,但在实践中我们从未达到过这些理论值 (尤其在分布式训练时!)。我们将在计算成本这一小节列出分布式训练中常见的 \(\text {实际 FLOPs}\) 值。
请注意,上面的算力成本公式来自于 这篇关于 LLM 训练成本的精彩博文。
参数量与数据集的权衡
严格来讲,你可以随心所欲地使用任意数量的词元来训练 transformer 模型,但由于参与训练的词元数会极大地影响计算成本和最终模型的性能,因此需要小心权衡。
我们从最关键的部分开始谈起: “计算最优” 语言模型。“Chinchilla 缩放定律”,得名于提出 “计算最优” 语言模型论文中所训练的模型名,指出计算最优语言模型的 参数量 和 数据集大小 的近似关系满足: \(D=20P\)。该关系成立基于一个前提条件: 使用 1,000 个 GPU 1 小时和使用 1 个 GPU 1,000 小时成本相同。如果你的情况满足该条件,你应该使用上述公式去训练一个性能最优且 GPU - 时 成本最小的模型。
但 我们不建议在少于 200B 词元的数据集上训练 LLM。 虽然对于许多模型尺寸来说这是 “Chinchilla 最优” 的,但生成的模型通常比较差。对于几乎所有应用而言,我们建议确定你可接受的推理成本,并训练一个满足该推理成本要求的最大模型。
计算成本的经验值
Transformer 模型的计算成本通常以 GPU - 时 或 FLOP - 秒 为单位。
- GPT-NeoX 的
实际 TFLOP/s在正常注意力机制下达到 150 TFLOP/s/A100,在 Flash 注意力机制下达到 180 FLOP/s/A100。这与其他高度优化的大规模计算库一致,例如 Megatron-DS 的值是在 137 和 163 TFLOP/s/A100 之间。 - 一个通用的经验法则是
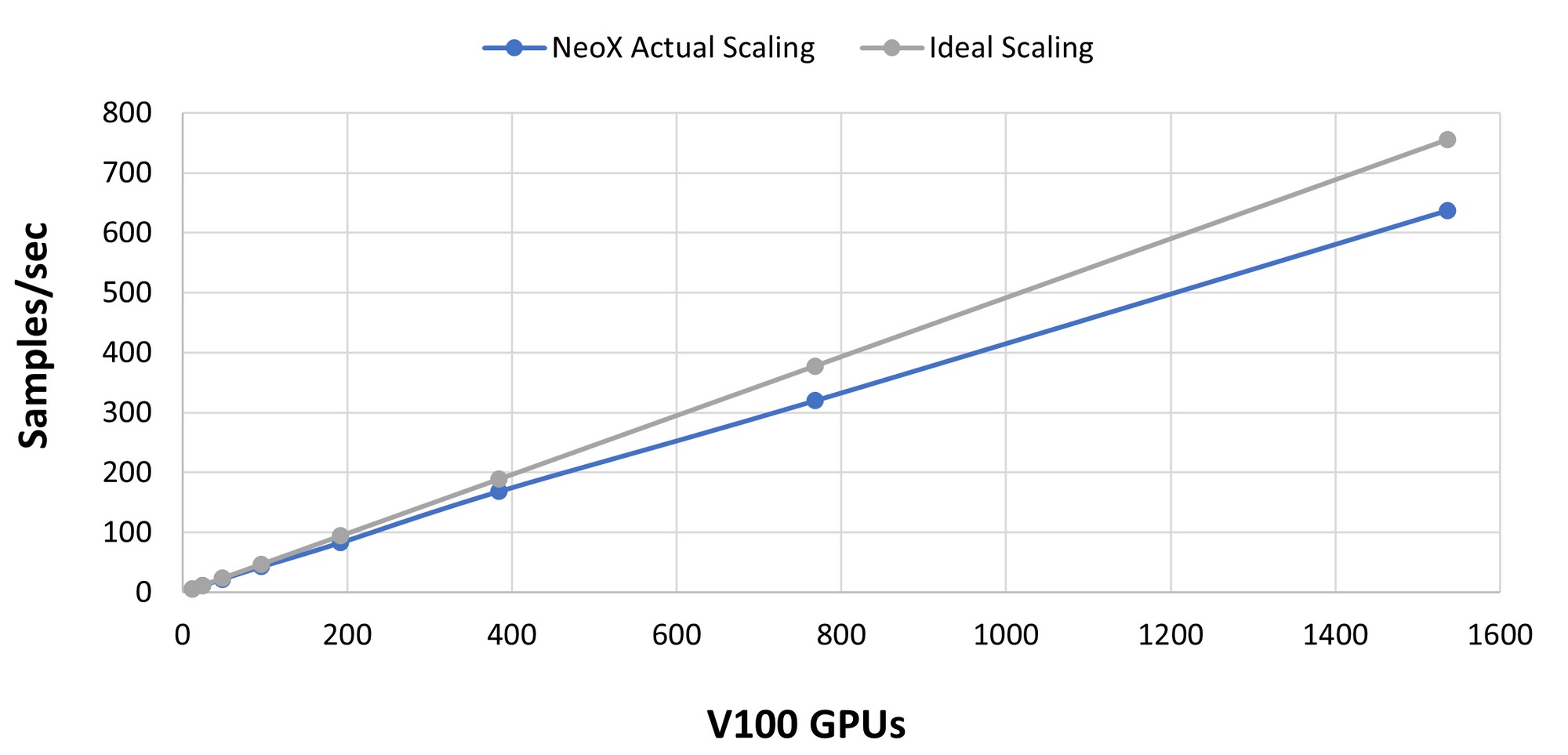
实际 TFLOP/s可至 120 TFLOP/s/A100 左右。如果你得到低于 115 TFLOP/s/A100 的值,可能是你的模型或硬件配置有问题。 - 借助 InfiniBand 等高速互连设备,你可以在数据并行维度上实现线性或亚线性扩展 (即增加数据并行度应该以近乎线性的方式增加整体吞吐量)。下图显示了在橡树岭国家实验室 (Oak Ridge National Lab) 的 Summit 超级计算机上测试出的 GPT-NeoX 库的扩展性。请注意,这张图用的是 V100,而本文中的其他大多数例子都是基于 A100 的。
内存需求
Transformer 模型通常由其 参数尺寸 来描述。但是,根据给定一组计算资源确定要训练哪些模型时,你需要知道 该模型将占用多少空间 (以字节为单位)。这不仅需要考虑你的本地 GPU 可以推理多大的模型,还需要考虑给定训练集群中的总可用 GPU 内存可供训练多大的模型。
推理
模型权重
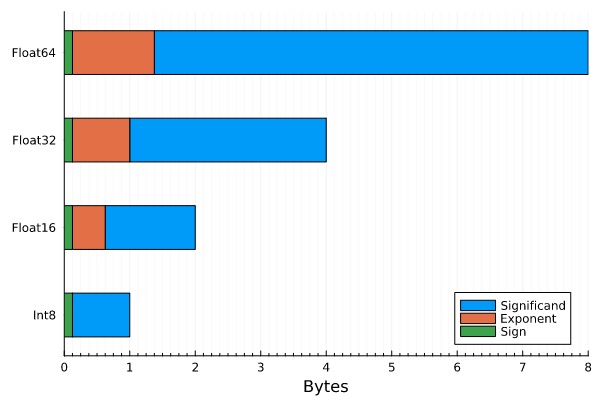
大多数 transformer 模型都使用 混合精度进行训练,可以是 fp16 + fp32 或是 bf16 + fp32。混合精度降低了模型训练和推理所需的内存量。推理时,我们还可以将语言模型从 fp32 转换为 fp16 甚至 int8,而没有实质性的精度损失。下面我们看看在不同的数据类型下,模型所需内存有什么不同 (以字节为单位):
- 对 int8 而言,\(\text {模型内存}=1 \text { 字节} /\text {参数}\cdot \text {参数量}\)
- 对 fp16 和 bf16 而言,\(\text {模型内存}=2 \text { 字节} /\text {参数} \cdot \text {参数量}\)
- 对 fp32 而言,\(\text {模型内存}=4 \text { 字节} /\text {参数}\cdot \text {参数量}\)
推理总内存
除了存储模型权重所需的内存外,实际中前向传播过程中还会有少量额外开销。根据我们的经验,此开销在 20% 以内,该比例通常与模型无关。
总的来说,回答 “这个模型是否适合推理” 这一问题,可以用下述公式来获得不错的估计:
\(\text {推理总内存} \approx 1.2 \times \text {模型内存}\)
本文不会深究该开销的来源,留待后面的文章来阐述。在本文的后续部分,我们将主要关注模型训练的内存。如果你有兴趣了解更多有关推理计算需求的信息,请查看 这篇深入介绍推理的精彩博文。现在,我们要开始训练了!
训练
除了模型权重之外,训练还需要在设备内存中存储优化器状态和梯度。这就是为什么当你问 “我需要多少内存来运行模型?”,别人会立即回答 “这取决于是训练还是推理”。训练总是比推理需要更多的内存,通常多得多!
模型权重
首先,可以使用纯 fp32 或纯 fp16 训练模型:
- 纯 fp32,\(\text {模型内存}=4 \text { 字节} /\text {参数} \cdot \text {参数量}\)
- 纯 fp16,\(\text {模型内存}=2 \text { 字节} /\text {参数} \cdot \text {参数量}\)
除了推理中讨论的常见模型权重数据类型外,训练还引入了 混合精度 训练,例如 AMP。该技术寻求在保持收敛性的同时最大化 GPU 张量核的吞吐量。现代 DL 训练领域经常使用混合精度训练,因为: 1) fp32 训练稳定,但内存开销高且不能利用到 NVIDIA GPU 张量核、2) fp16 训练稳定但难以收敛。更多混合精度训练相关的内容,我们建议阅读 tunib-ai 的 notebook。请注意,混合精度要求模型的 fp16/bf16 和 fp32 版本都存储在内存中,而模型需要的内存如下:
- 混合精度 (fp16/bf16 + fp32), \(\text {模型内存}=2 \text { 字节} /\text {参数} \cdot \text {参数量}\)
正如上面所讲,这个仅仅是模型内存,还需要额外加上 \(4 \text { 字节 / 参数} \cdot \text {参数量}\) 的 用于优化器状态计算 的模型副本,我们会在下面的 优化器状态 一节中算进去。
优化器状态
Adam 有奇效,但内存效率非常低。除了要求你有模型权重和梯度外,你还需要额外保留三个梯度参数。因此,
对于纯 AdamW,\(\text {优化器内存}=12 \text { 字节}/\text {参数}\cdot \text {参数量}\)
- fp32 主权重: 4 字节 / 参数
- 动量 (momentum): 4 字节 / 参数
- 方差 (variance): 4 字节 / 参数
对于像 bitsandbytes 这样的 8 位优化器,\(\text {优化器内存} =6 \text { 字节} /\text {参数} \cdot \text {参数量}\)
- fp32 主权重: 4 字节 / 参数
- 动量: 1 字节 / 参数
- 方差: 1 字节 / 参数
对于含动量的类 SGD 优化器,\(\text {优化器内存} =8 \text { 字节} /\text {参数} \cdot \text {参数量}\)
- fp32 主权重: 4 字节 / 参数
- 动量: 4 字节 / 参数
梯度
梯度可以存储为 fp32 或 fp16 (请注意,梯度数据类型通常与模型数据类型匹配。因此,我们可以看到在 fp16 混合精度训练中,梯度数据类型为 fp16),因此它们对内存开销的贡献为:
- 对于 fp32,\(\text {梯度内存} = 4 \text { 字节} /\text {参数} \cdot \text {参数量}\)
- 对于 fp16,\(\text {梯度内存} = 2 \text { 字节} /\text {参数} \cdot \text {参数量}\)
激活和 Batch Size
对于 LLM 训练而言,现代 GPU 通常受限于内存瓶颈,而不是算力。因此,激活重计算 (activation recomputation,或称为激活检查点 (activation checkpointing) ) 就成为一种非常流行的以计算换内存的方法。激活重计算 / 检查点主要的做法是重新计算某些层的激活而不把它们存在 GPU 内存中,从而减少内存的使用量。内存的减少量取决于我们选择清除哪些层的激活。举个例子,Megatron 的选择性重计算方案的效果如下图所示:
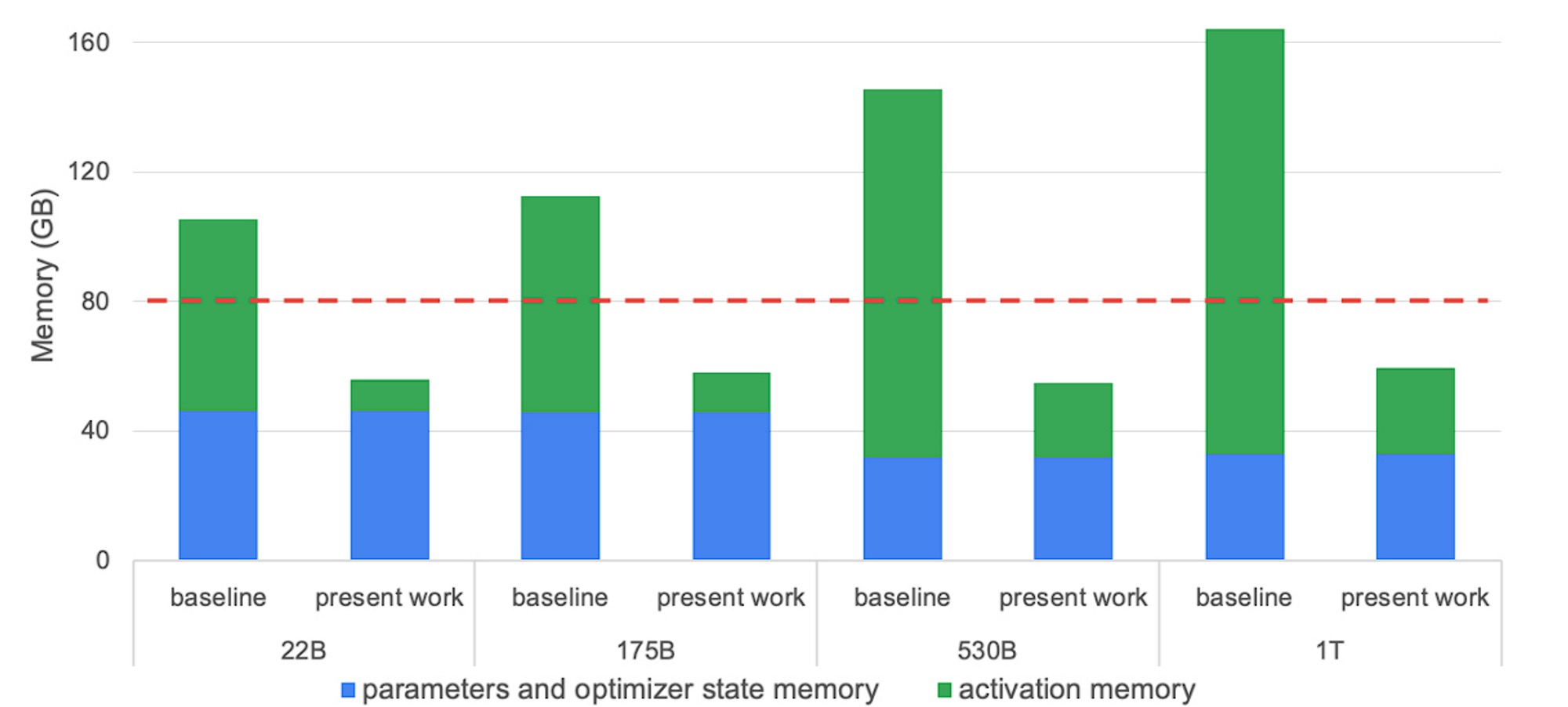
图中,红色虚线表示 A100-80GB GPU 的内存容量,“present work” 表示使用选择性激活重计算后的内存需求。请参阅 Reducing Activation Recomputation in Large Transformer Models 一文,了解更多详细信息以及下述公式的推导过程。
下面给出存储 transformer 模型激活所需内存的基本公式:
\]
\]
\]
其中:
- \(s\) 是序列长度,即序列中词元的个数
- \(b\) 是每个 GPU 的 batch size
- \(h\) 是每个 transformer 层的隐含维度
- \(L\) 是 transformer 模型的层数
- \(a\) 是 transformer 模型中注意力头 (attention heads) 的个数
- \(t\) 是张量并行度 (如果无张量并行,则为 1)
- 我们假设没有使用序列并行
- 我们假设激活数据类型为 fp16
由于重计算的引入也会引起计算成本的增加,具体增加多少取决于选择了多少层进行重计算,但其上界为所有层都额外多了一次前向传播,因此,更新后的前向传播计算成本如下:
\]
训练总内存
至此,我们得到了回答 “这个模型是否适合训练” 这一问题的一个很好的估算公式:
\]
分布式训练
分片优化器 (sharded optimizer)
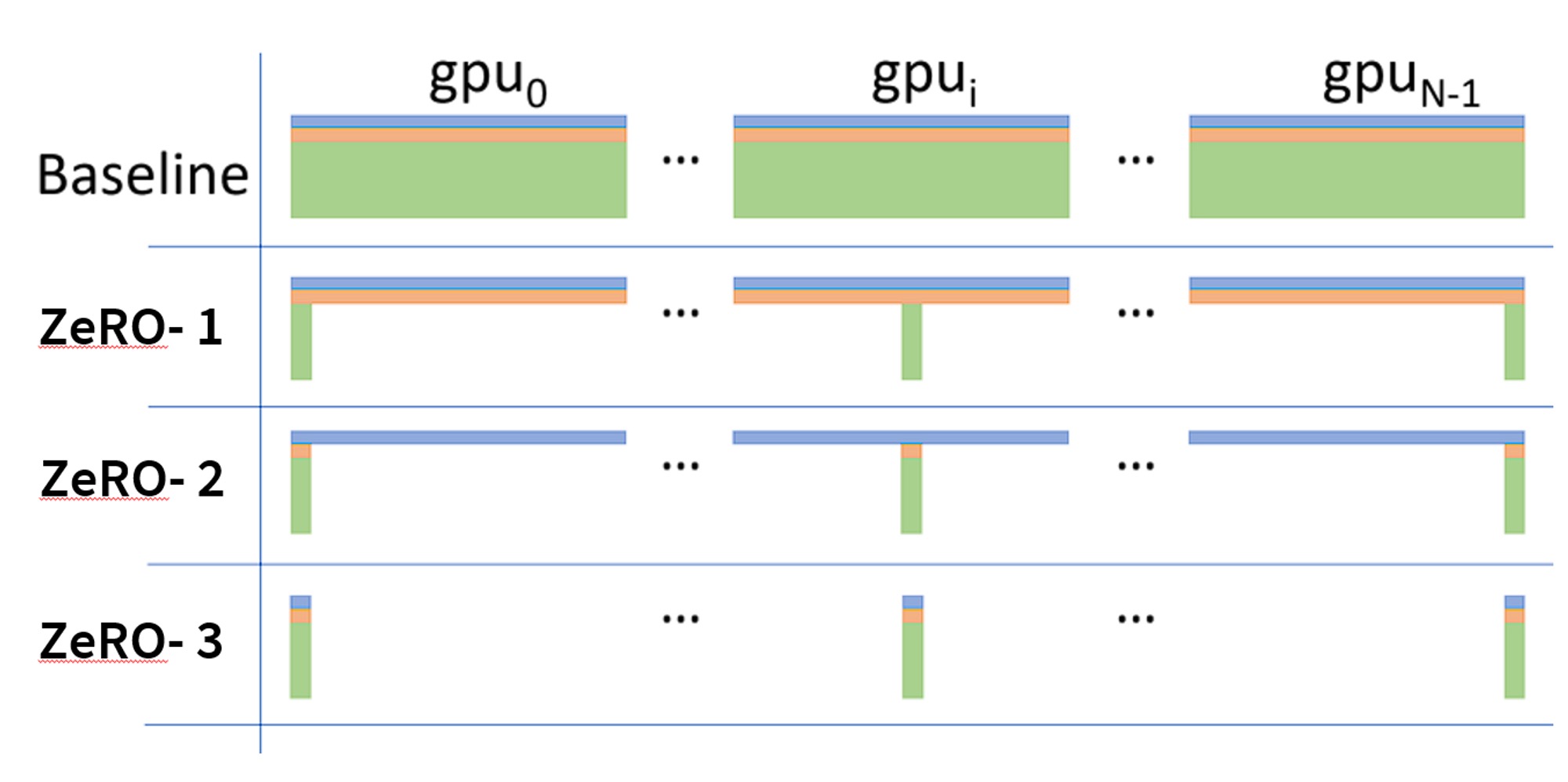
巨大的优化器内存开销促使大家设计和实现了分片优化器,目前常用的分片优化器实现有 ZeRO 和 FSDP。该分片策略可以使单 GPU 的优化器内存开销随 \(\text {GPU 个数}\) 线性下降,这就是为什么你会发现某个模型及其训练配置可能在大规模集群上能跑,但到小规模集群时就 OOM (Out Of Memory,内存耗尽) 了。下图来自于 ZeRO 论文,它形象地说明了不同的 ZeRO 阶段及它们之间的区别 (注意 \(P_{os}\)、\(P_{os+g }\) 和 \(P_{os+g+p}\) 通常分别表示为 ZeRO-1、ZeRO-2、ZeRO-3。ZeRO-0 通常表示 “禁用 ZeRO”):

下面,我们总结一下 ZeRO 各阶段的内存开销公式 (假定我们使用混合精度及 Adam 优化器):
- 对于 ZeRO-1,
\]
- 对于 ZeRO-2,
\]
- 对于 ZeRO-3,
\]
其中,在训练过程没有使用流水线并行或张量并行的条件下,\(\text {GPU 数}\) 即为 \(\text {DP 并行度}\)。更多详细信息,请参阅 Sharded Optimizers + 3D Parallelism 一文。
请注意,ZeRO-3 引入了一组实时参数。这是因为 ZeRO-3 引入了一组配置项 ( stage3_max_live_parameters, stage3_max_reuse_distance, stage3_prefetch_bucket_size, stage3_param_persistence_threshold) 来控制同一时刻 GPU 内存中可以放多少参数 (较大的值占内存更多但需要的通信更少)。这些参数会对总的 GPU 内存使用量产生重大影响。
请注意,ZeRO 还可以通过 ZeRO-R 在数据并行 rank 间划分激活,这样 \(\text {激活内存}\) 还可以再除以张量并行度 \(t\)。更详细的信息,请参阅相关的 ZeRO 论文 及其 配置选项 (注意,在 GPT-NeoX 中,相应的配置标志为 partition_activations)。如果你正在训练一个大模型,激活放不下内存而成为一个瓶颈,你可以使用这个方法用通信换内存。把 ZeRO-R 与 ZeRO-1 结合使用时,内存消耗如下:
\]
3D 并行
LLM 主要有 3 种并行方式:
数据并行: 在多个模型副本间拆分数据
流水线或张量 / 模型并行: 在各 GPU 之间拆分模型参数,因此需要大量的通信开销。它们的内存开销大约是:
\]
\]
请注意,这是个近似公式,因为 (1) 流水线并行对降低激活的内存需求没有帮助、(2) 流水线并行要求所有 GPU 存储所有正在进行的 micro batch 的激活,这对大模型很重要、(3) GPU 需要临时存储并行方案所需的额外通信缓冲区。
分片优化器 + 3D 并行
当 ZeRO 与张量并行、流水线并行结合时,由此产生的 GPU 间的并行策略如下:
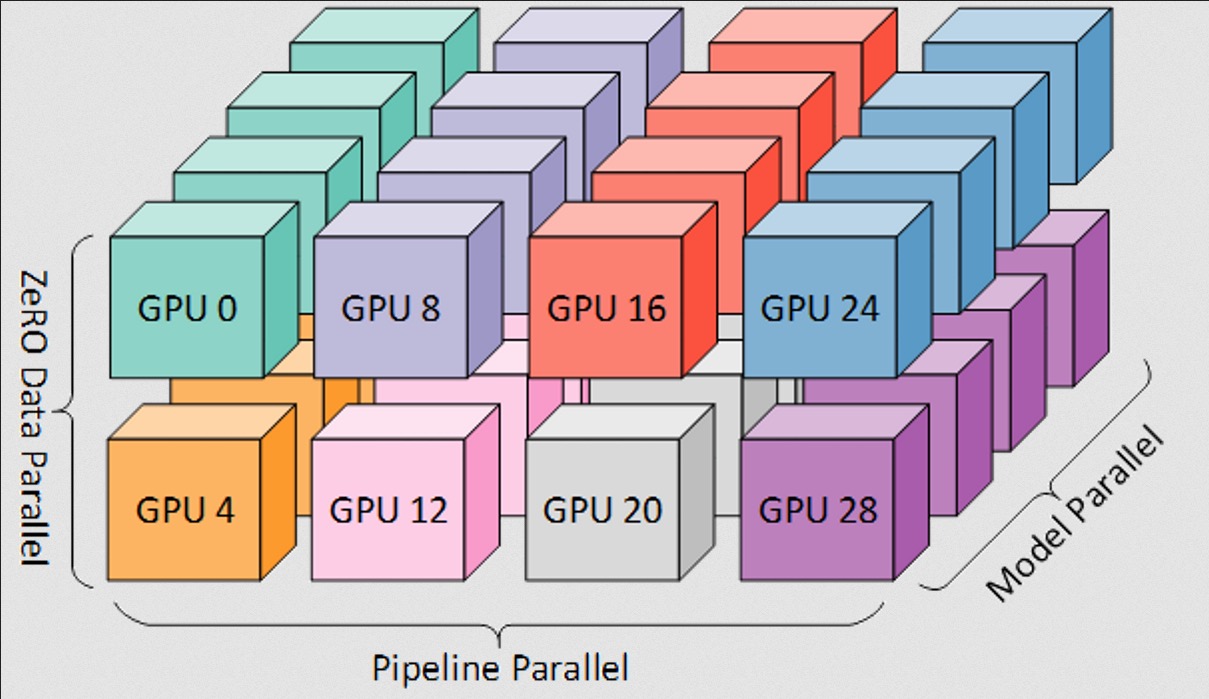
值得一提的是,数据并行度对于计算训练的全局 batch size 至关重要。数据并行度取决于你想在训练集群中保持几份完整模型副本:
\]
虽然流水线并行和张量并行与所有 ZeRO 阶段都兼容 (例如,张量并行叠加上 ZeRO-3 后,我们会首先对张量进行切片,然后在每个张量并行单元中应用 ZeRO-3),但只有 ZeRO-1 与张量和 / 或流水线并行相结合时会效果才会好。这是由于梯度划分在不同并行策略间会有冲突 (如流水线并行和 ZeRO-2 都会对梯度进行划分),这会显著增加通信开销。
把所有东西打包到一起,我们可以得到一个典型的 3D 并行 + ZeRO-1 + 激活分区 方案:
\]
总结
EleutherAI 的工程师经常使用上述估算方法来高效规划、调试分布式模型训练。我们希望澄清这些经常被忽视的但很有用的实现细节,如果你想与我们讨论或认为我们错过了一些好的方法,欢迎你通过 contact@eleuther.ai 联系我们!
请使用如下格式引用本文:
@misc {transformer-math-eleutherai,
title = {Transformer Math 101},
author = {Anthony, Quentin and Biderman, Stella and Schoelkopf, Hailey},
howpublished = \url {blog.eleuther.ai/},
year = {2023}
}
英文原文: https://blog.eleuther.ai/transformer-math/
原文作者: Quentin Anthony,Stella Biderman,Hailey Schoelkopf,作者均来自 EleutherAI
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校/排版: zhongdongy (阿东)
Transformer 估算 101的更多相关文章
- 常用tcode
SAP常用TCODE 1 MMBE 查询库存 2 CO01 生产订单创建 3 ME2N-按采购订单编号 ME2B/ME2M/ME2C/ME2W 采购订单查询 清单范围ALV 4 MB51 物料凭证清单 ...
- zz全面拥抱Transformer
放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较 在辞旧迎新的时刻,大家都在忙着回顾过去一年的成绩(或者在灶台前含泪数锅),并对2019做着规划,当然也 ...
- ICCV2021 | Tokens-to-Token ViT:在ImageNet上从零训练Vision Transformer
前言 本文介绍一种新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT将原始ViT的参数数量和MAC减少了一半,同时在ImageNet上从 ...
- DataStage中Transformer的函数大全
一. 类型转换函数 类型转换函数用于更改参数的类型. 以下函数位于表达式编辑器的"类型转换"类别中.方括号表示参数是可选的.缺省日期格式为 %yyyy-%mm-%dd. 以下示例按 ...
- 大规模 Transformer 模型 8 比特矩阵乘简介 - 基于 Hugging Face Transformers、Accelerate 以及 bitsandbytes
引言 语言模型一直在变大.截至撰写本文时,PaLM 有 5400 亿参数,OPT.GPT-3 和 BLOOM 有大约 1760 亿参数,而且我们仍在继续朝着更大的模型发展.下图总结了最近的一些语言模型 ...
- 了解 ARDUINO 101* 平台
原文链接 简介 作为一名物联网 (IoT) 开发人员,您需要根据项目的不同需求,选择最适合的平台来构建应用. 了解不同平台的功能至关重要. 本文第一部分比较了 Arduino 101 平台和 Ardu ...
- Entity Framework 6 Recipes 2nd Edition(10-1)译->非Code Frist方式返回一个实体集合
存储过程 存储过程一直存在于任何一种关系型数据库中,如微软的SQL Server.存储过程是包含在数据库中的一些代码,通常为数据执行一些操作,它能为数据密集型计算提高性能,也能执行一些为业务逻辑. 当 ...
- 虚拟 router 原理分析- 每天5分钟玩转 OpenStack(101)
上一节我们创建了虚拟路由器"router_100_101",并通过 ping 验证了 vlan100 和 vlan101 已经连通. 本节将重点分析其中的原理. 首先我们查看控制节 ...
- VS:101 Visual Studio 2010 Tips
101 Visual Studio 2010 Tips Tip #1 How to not accidentally copy a blank line TO – Text Editor ...
- Spatial Transformer Networks(空间变换神经网络)
Reference:Spatial Transformer Networks [Google.DeepMind]Reference:[Theano源码,基于Lasagne] 闲扯:大数据不如小数据 这 ...
随机推荐
- 【LeetCode回溯算法#08】递增子序列,巩固回溯算法中的去重问题
递增子序列 力扣题目链接(opens new window) 给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2. 示例 1: 输入:nums = [4,6,7,7] ...
- 【建造者设计模式详解】Java/JS/Go/Python/TS不同语言实现
简介 建造者模式(Builder Pattern),也叫生成器模式,属于创建型模式.它使用多个简单的对象一步一步构建成一个复杂的对象.它允许你使用相同的创建代码生成不同类型和形式的对象. 当你希望使用 ...
- Github账户的注册
注册步骤 首先进入github官网界面(注意,只能用Chrome或者Firefox浏览器.这样保险性更强一些) 官网地址:https://github.com/ 映入眼帘的界面是这样的: 点击右上角的 ...
- Javaweb基础复习------EL表达式+JSTL-if&foreach
EL表达式------简化JSP页面的Java代码 主要功能是------获取数据(语法:${data}) 举例: //ServletDemo1.java package com.example.se ...
- Redis6.0.9集群搭建
前提条件: Redis版本:6.0.9(因为5.0之前创建用的是redis-trib,还需要ruby,ruby-gem) 安装环境: Centos7 1. 准备配置文件 一个是通用文件:redis-c ...
- c++的thread小测试
windows环境还用不了thread,得下一些mingw,弄了半天没弄好,直接用了商店中心就有的Ubuntu了,但是sudo install g++出现了下载不了的问题,解决方案:https://b ...
- Yolov5——训练目标检测模型
项目的克隆 打开yolov5官网(GitHub - ultralytics/yolov5 at v5.0),下载yolov5的项目: 环境的安装(免额外安装CUDA和cudnn) 打开anaconda ...
- 声网 X 在线自习室 同学陪伴、老师监督的在线自习是如何火出圈的?
实时互联网像触角一样,通过情景的共享延伸开来,链接着我们彼此的线下.线上生活,形成一张不可分割的网络.随着社交直播.在线教育.视频会议成为大众生活不可或缺的一部分的同时,智能手表.智能作业灯.视频双录 ...
- java数据类型转换有哪几种?看这篇就够了!
前言 在上一篇文章中,壹哥给大家讲解了Java中的数据类型,从此大家就知道了基本类型和引用类型,尤其是8种基本类型的使用和各自特点.但实际上数据类型的使用还有很多更深入的内容,比如java数据类型直接 ...
- 数据挖掘关联分析—R实现
关联分析 关联分析又称关联挖掘,就是在交易数据.关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式.关联.相关性或因果结构.或者说,关联分析是发现交易数据库中不同商品(项)之间的联系 ...