深度学习论文翻译解析(二十二):Uniformed Students Student-Teacher Anomaly Detection With Discriminative Latent Embbeddings
论文标题:Uniformed Students Student-Teacher Anomaly Detection With Discriminative Latent Embbeddings
论文作者: Paul Bergmann Michael Fauser David Sattlegger Carsten Steger
声明:小编翻译论文仅为学习,如有侵权请联系小编删除博文,谢谢!
小编是一个机器学习初学者,打算认真研究论文,但是英文水平有限,所以论文翻译中用到了Google,并自己逐句检查过,但还是会有显得晦涩的地方,如有语法/专业名词翻译错误,还请见谅,并欢迎及时指出。
这可能是最后几篇这样翻译的文章了,因为还有一些库存会放出来,也算是纪念自己逝去的青春。经过几年的沉淀,我的英文水平稍微有所进步,我的论文阅读能力也是提高一些,当然最近新出的chatgpt也是能大大提高阅读效率。我之前将一整篇文章一词一句的翻译其实是相当的浪费时间。但是初学者不得不花费时间,精力去学习。毕竟单词,专业术语,个人能力刚开始都没有的。后面的论文精读会直接提炼文章的中心思想,并且有空会发一些复现代码方面博客。
如果需要小编其他论文翻译,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote

摘要
我们为高分辨率图像中的无监督异常检测和像素精确异常分割这一具有挑战性的问题引入了一个强大的师生框架。学生网络被训练来回归描述性教师网络的输出,该网络是在来自自然图像的补丁的大型数据集上预训练的。这就避免了对先前数据注释的需要。当学生网络的输出与教师网络的输出不同时,就会检测到异常。当他们无法在无异常训练数据的集合之外进行归纳时,就会发生这种情况。学生网络作品中固有的不确定性被用作一个额外的评分函数,用于指示异常情况。我们将我们的方法与大量现有的基于深度学习的无监督异常检测方法进行了比较。我们的实验在许多现实世界的数据集上证明了与最先进的方法相比的改进,包括最近推出的MVTec异常检测数据集,该数据集专门设计用于对异常分割算法进行基准测试。


1,简介
在计算机视觉的许多领域,对机器学习模型中出现异常或新颖的区域进行无监督像素精确分割是一项重要而富有挑战性的任务。在自动化工业检查场景中,通常希望仅在一类无异常图像上训练模型,以在推理过程中分割缺陷区域。在主动学习环境中,可以将当前模型检测为先前未知的区域包括在训练集中,以提高模型的性能。
最近,人们努力改进一类或多类分类的异常检测[2,3,10,11,21,28,29]。然而,这些算法假设异常以完全不同类别的图像的形式表现出来,并且必须做出简单的二进制图像级别的决定,即图像是否异常。很少有工作致力于开发能够分割异常区域的方法,这些异常区域仅以非常微妙的方式与训练数据不同。Bergmann等人[7]为几种最先进的算法提供了基准,并确定了很大的改进空间。
现有工作主要集中在生成算法上,如生成对抗性网络(GANs)[31,32]或变分自动编码器(VAE)[5,36]。这些方法使用每像素重建误差或通过评估从模型概率分布中获得的密度来检测异常。由于重建不准确或校准不当,这已被证明是有问题的[8,22]。



许多有监督的计算机视觉算法[16,34]的性能通过迁移学习来提高,即通过使用来自预训练网络的判别嵌入。对于无监督异常检测,到目前为止,这种方法还没有得到彻底的探索。最近的工作表明,这些特征空间在异常检测方面表现良好,即使是简单的基线也优于生成深度学习方法[10,26]。然而,现有方法在大型高分辨率图像数据集上的性能受到浅层机器学习管道的使用的阻碍,这些管道需要对所使用的特征空间进行降维。此外,它们依赖于大量的训练数据子采样,因为它们的能力不足以用大量的训练样本对高度复杂的数据分布进行建模。

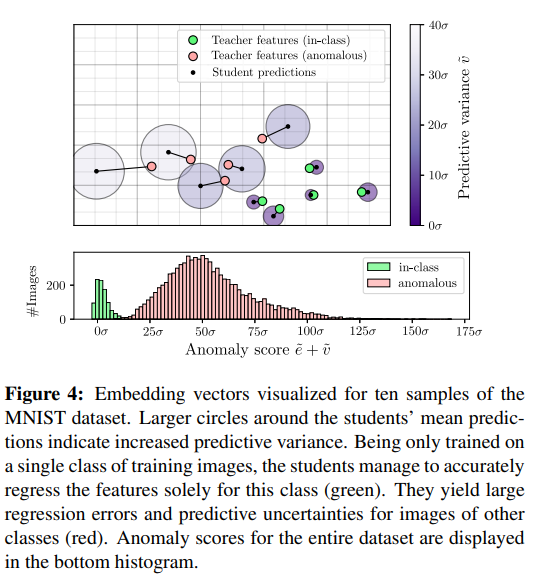
我们建议避开浅层的这些限制通过使用学生-教师方法隐式地建模训练特征的分布来进行建模。这一杠杆将深度神经网络的高容量和帧异常检测作为一个特征回归问题。给定在来自自然图像(教师)的补丁的大型数据集上预训练的描述性特征提取器,我们在无异常训练数据上训练学生网络集合,以模拟教师的输出。在推理过程中,学生的预测不确定性及其相对于教师的回归误差被组合在一起,以产生每个输入像素的密集异常分数。我们的直觉是,学生们会在没有异常的训练数据的流形之外进行糟糕的概括,并开始做出错误的预测。图1显示了我们的方法应用于从MVTec异常检测数据集[7]中选择的图像时的定性结果。整个异常检测过程的示意图如图2所示。我们的主要贡献包括:


- 我们提出了一种新的基于师生学习的无监督异常检测框架。来自预先训练的教师网络的局部描述符充当学生集合的替代标签。我们的模型可以在大型未标记的图像数据集上进行端到端训练,并利用所有可用的训练数据。
- 我们引入了基于学生预测方差和回归误差的评分函数,以获得用于自然图像中异常区域分割的密集异常图。我们描述了如何通过调整学生和教师的感受场来扩展我们的方法,以在多个尺度上分割异常。
- 我们在三个真实世界的计算机视觉数据集上展示了最先进的性能。我们将我们的方法与许多直接适应教师特征分布的浅层机器学习分类和深度生成模型进行了比较。我们还将其与最近引入的基于深度学习的无监督异常分割方法进行了比较。

2,相关工作
有大量关于异常检测的文献[27]。基于深度学习的异常分割方法主要关注生成模型,如自动编码器[1,8]或GAN[32]。这些尝试从头开始学习表示,不利用关于自然图像性质的先验知识,并通过将输入图像与像素空间中的重建进行比较来分割异常。由于简单的逐像素比较或不完美的重建,这可能导致异常检测性能较差[8]。


2.1 预训练网络的异常检测
通过将浅层机器学习模型拟合到无异常训练数据的特征,将预训练网络的非判别嵌入向量转移到异常检测任务中,取得了有希望的结果。Andrews等人[3]使用来自预训练的VGG网络不同层的激活,并使用SVM对无异常训练分布进行建模。但是,它们仅适用他们的方法对图像进行分类,不考虑异常区域的分割。Burlina等人也进行了类似的实验。[10]。他们报告了与从生成模型中获得的特征空间相比,判别嵌入的卓越性能。

Nazare等人[24]研究了在图像分类任务中预训练的不同现成特征提取器的性能,用于分割监控视频中的异常。他们的方法在从大量无异常训练补丁中提取的嵌入向量上训练1-最近邻(1-NN)分类器。在训练浅层分类器之前,使用主成分分析(PCA)来降低网络激活的维数。为了在推理过程中获得空间异常图,必须对分类器进行大量重叠补丁的评估,这很快成为性能瓶颈,并导致相当粗糙的异常图。类似地,Napoletano等人[23]从预训练的ResNet-18中提取大量裁剪训练补丁的激活,并在使用PCA进行先验降维后使用K-Means聚类对其分布进行建模。他们还在推理过程中对测试图像进行跨步评估。这两种方法都从输入图像中采样训练补丁,因此没有利用所有可能的训练特征。这是必要的,因为在他们的框架中,由于使用每个补丁只输出单个描述符的非常深入的网络,特征提取在计算上是昂贵的。此外,由于浅层模型用于学习无异常补丁的特征分布,因此必须大大减少可用的训练信息。

为了避免裁剪补丁的需要并加快特征提取,Sabokrou等人[30]以完全卷积的方式从预训练的AlexNet的早期特征图中提取解脚本,并将单峰高斯分布拟合到无异常图像的所有可用训练向量。尽管在他们的框架中可以更有效地实现特征提取,但池化层会导致输入图像的下采样。这大大降低了最终异常图的分辨率,尤其是当使用具有较大感知场的更深网络层的描述特征时。此外,一旦问题复杂性上升,单峰高斯分布将无法对训练特征分布进行建模。


2.2. 具有不确定性估计的开集识别
我们的工作从最近在图像分类或语义分割等监督环境中成功的开集识别中获得了一些启发,其中深度神经网络的不确定性估计已被用于使用MC Dropout[14]或深度集成[19]检测分布外输入。Seeboeck等人[33]证明,用MC Dropout训练的分割网络的不确定性可用于检测视网膜OCT图像中的异常。Beluch等人[6]表明,在图像分类任务上训练的网络集合的方差充当积极学习的有效获取功能。将当前模型中出现异常的输入添加到训练集中,以快速增强其性能。
然而,这种算法要求领域专家对监督任务的图像进行预先标记,这并不总是可能或可取的。在我们的工作中,我们利用预训练网络的特征向量作为代理标签来训练学生网络的集合。然后,将预测方差与集合的输出混合分布的回归误差一起用作评分函数,以分割测试图像中的异常区域。

3 学生-教师 异常检测
本节介绍了我们提出的方法的核心原则。给定一个无异常图像的训练数据集D={I1,I2,…,IN},我们的目标是创建一个学生网络集合S,该集合S稍后可以检测测试图像J中的异常。这意味着他们可以为每个像素签名一个分数,指示它与训练数据集的偏差程度。为此,针对从在大型自然图像数据集上预训练的脚本式教师网络T中获得的回归目标来训练学生模型。训练后,可以根据学生的重生成误差和预测方差导出每个图像像素的异常分数。给定一个输入图像 I∈R(w×h×d),宽度w、高度h和数量通道C,集合中的每个学生S输出一个特征图Si(I)∈R(w×h×D)。它包含第R行和第C列的每个输入图像像素的二维D的描述符y(r, c)∈R。通过设计,我们限制了学生的感受野,使得y(r, c) 描述了以边长p(R,C) 为中心的正方形局部图像区域p。教师T具有与学生网络相同的网络架构。然而,它保持不变,并为输入图像I的每个像素提取描述性嵌入向量,作为学生训练中的确定回归目标。


3.1 学习局部特征描述符
我们首先描述如何使用度量学习和知识提取技术有效地构建描述性教师网络T。在现有的使用预训练网络进行异常检测的工作中,特征提取器仅为补丁大小的输入或空间上大量下采样的特征图输出单个特征向量[23,30]。相反,我们的教师网络T有效地输出输入图像内边长p的每个可能平方的描述符。T是通过首先使用卷积层和最大池化层来训练网络T Plot以将块大小的图像p∈Rp×p×C嵌入到维度d的度量空间中而获得的。然后,可以通过如[4]中所述的T到T的确定性网络变换来实现对整个输入图像的快速密集局部特征提取。与之前引入的执行基于补丁的跨步评估的方法相比,这产生了显著的加速。为了让Tõ输出语义强的描述符,我们研究了自监督度量学习技术以及从描述性但计算效率低的预训练网络中提取知识。可以通过从任何图像数据库中随机裁剪来获得大量的训练补丁p。在这里,我们使用ImageNet[18]。
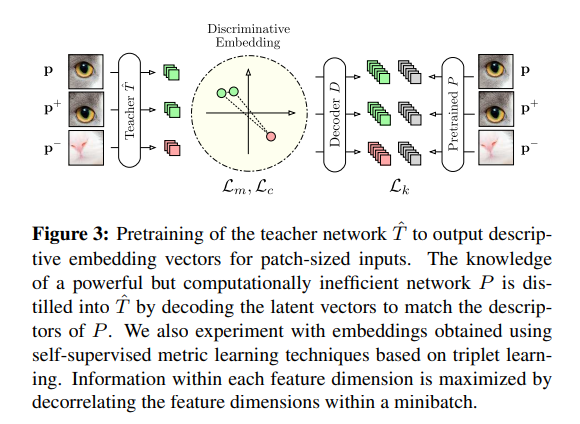

知识蒸馏
使用在图像分类任务上训练的深度卷积神经网络(CNN)的深层特征来描述局部图像块对于异常检测来说效果很好,当用浅层机器学习模型来建模它们的分布时[23,24]。然而,这种CNN的架构通常非常复杂且计算效率低下,不适合提取局部图像块的描述符。因此,我们通过将P的输出与从T^中解码得到的描述符相匹配来蒸馏一个强大的预训练网络P到T^:


度量学习
如果由于某种原因,预训练的网络不可用,也可以以完全自我监督的方式学习局部图像描述符[12]。在这里,我们研究了使用三元组学习获得的判别嵌入的性能。对于每个随机裁剪的补片p,补片的三元组(p,p+,p-) 是增强的。通过p周围的小的随机平移、图像亮度的变化和高斯噪声的添加来获得位置补丁p。负补丁p-是由随机选择的不同图像中的随机裁剪创建的。使用锚交换[37]的三元组硬负挖掘作为损失函数,用于学习对2度量敏感的嵌入

描述符紧凑性
由 Vasileios 等人[35] 提出,我们通过最小化输入 mini-batch 中描述符之间的相关性来提高描述符的紧凑性并消除不必要的冗余:
其中 cij 表示当前 mini-batch 中所有描述符 T^ (p) 的相关矩阵。
其中 λk、λm 和 λc 是每个损失项的权重,均大于等于零。图 3 总结了教师判别式嵌入的整个学习过程。





3.3 多尺度异常分割
如果异常只覆盖了接收器大小为p的小部分,则提取的特征向量主要描述了局部图像区域的无异常特性。因此,学生可以很好地预测该描述符,从而降低了异常检测性能。可以通过下采样输入图像来解决此问题。但是,这会导致输出异常地图的分辨率下降。
我们的框架允许显式控制学生和教师接收场的大小p。因此,我们可以通过训练多个具有不同p值的学生-教师集合对来检测各种尺度上的异常。在每个尺度上,都会计算一个与输入图像相同大小的异常图。给定L个具有不同接收场的学生-教师集合对,可以使用简单的平均方法组合每个尺度l的归一化异常分数e'_(l)(r,c) 和v'_(l)(r,c):

4,实验
为了证明我们方法的有效性,我们在多个数据集上进行了广泛的评估。我们比较了我们的学生教师框架与使用浅层机器学习算法来建模预训练网络特征分布的现有管道之间的性能。为此,我们将它们与一个K均值分类器、一个单类支持向量机(OC-SVM)和一个最近邻分类器进行比较。在使用PCA对教师描述符进行降维之后,这些模型被拟合到教师描述符的分布中。我们还尝试了确定性和变分自动编码器作为教师判别嵌入的深度分布模型。分别使用l2重构误差[13]和重构概率[2]作为异常分数。此外,我们还将我们的方法与最近引入的基于生成和判别式深度学习的异常检测模型进行了比较,并报告了比最新技术更好的性能。特别地,教师在预训练过程中没有观察到所评价的数据集中的图像,以避免不公正的偏见。


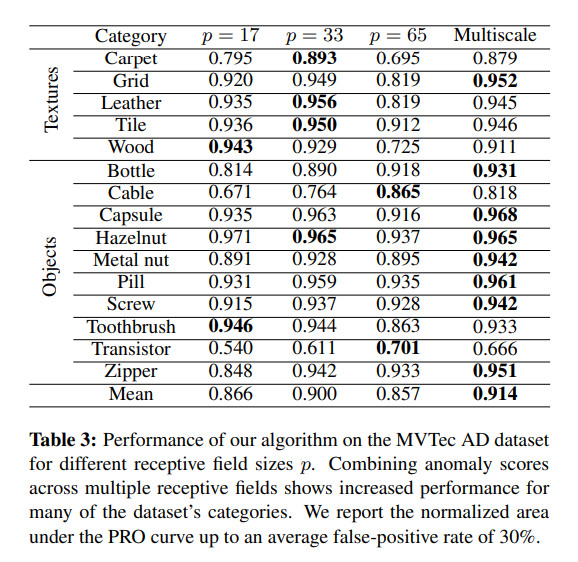
作为第一个实验,我们进行了一项消融研究来寻找合适的超参数。我们的算法应用于MNIST [20] 和CIFAR-10 [17] 数据集的一类分类设置中。然后我们在更具挑战性的MVTec异常检测(MVTec AD)数据集上进行评估,该数据集专门设计用于对异常区域进行分割的算法基准测试。它提供了超过5000张高分辨率图像,分为十个物体类别和五个纹理类别。以突出显示优势。为了验证我们多尺度方法的有效性,我们在 MVTec AD 数据集上进行了额外的消融研究,该研究探讨了不同感受野对异常检测性能的影响。
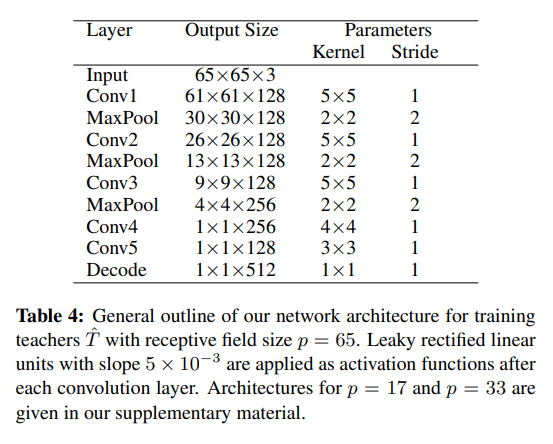
在我们的实验中,我们使用了相同的学生网络和教师网络架构,感受野大小为p∈{17, 33, 65}。所有架构都是简单的卷积神经网络,仅包含卷积层和最大池化层,并使用斜率 5 × 10−3 的Leaky ReLU 激活函数。表 4 展示了当 p = 65 时使用的具体架构。对于 p = 17 和 p = 33,我们在补充材料中提供了类似的架构。

在预训练阶段,使用来自 ImageNet 数据集的数据增强三元组来训练教师网络。 图像被缩放到相同的宽度和高度,采样自 {4p, 4p+1, ..., 16p} ,然后在随机位置裁剪一个边长为 p 的正方形区域。对于每个三元组,通过在 [-p-14, ..., p-14] 范围内随机平移裁剪区域的位置来构造一个正样本区域 p+ 。在 p+ 上添加标准差为 0.1 的高斯噪声。所有图像都以 0.1 的概率随机转换为灰度图。为了进行知识蒸馏,我们从在 ImageNet 数据集上预先训练好的用于分类的 ResNet-18 中提取 512 维特征向量。对于网络优化,我们使用了带有初始学习率为 2 × 10−4、权重衰减系数为 10−5 和批量大小为 64 的 Adam 优化器 [15]。每个教师网络输出维度为 d = 128 的描述符,并且经过 5×10^4 次迭代的训练。


4.1 MNIST 和 CIFAR-10
在预训练阶段,使用来自 ImageNet 数据集的数据增强三元组来训练教师网络。 图像被缩放到相同的宽度和高度,采样自 {4p, 4p+1, ..., 16p} ,然后在随机位置裁剪一个边长为 p 的正方形区域。对于每个三元组,通过在 [-p-14, ..., p-14] 范围内随机平移裁剪区域的位置来构造一个正样本区域 p+ 。在 p+ 上添加标准差为 0.1 的高斯噪声。所有图像都以 0.1 的概率随机转换为灰度图。为了进行知识蒸馏,我们从在 ImageNet 数据集上预先训练好的用于分类的 ResNet-18 中提取 512 维特征向量。对于网络优化,我们使用了带有初始学习率为 2 × 10−4、权重衰减系数为 10−5 和批量大小为 64 的 Adam 优化器 [15]。每个教师网络输出维度为 d = 128 的描述符,并且经过 5×10^4 次迭代的训练。
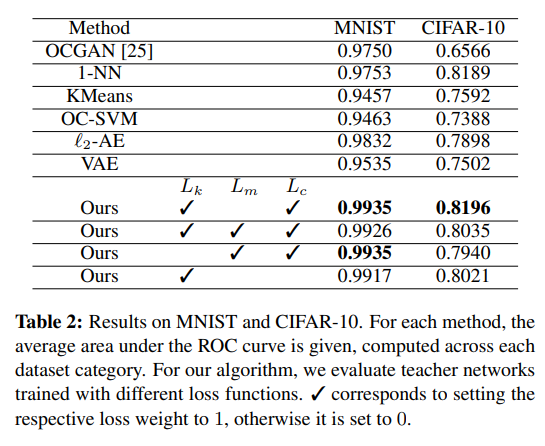

表 2 显示了我们的结果。 我们的方法在各种超参数设置上优于其他方法。 将预训练的 ResNet-18 的知识蒸馏到教师描述符中,与使用三元组学习以完全自监督方式训练教师相比,会稍微提高性能。通过最小化相关矩阵来减少描述符冗余可以得到更好的结果。平均而言,浅层模型和根据我们教师的特征分布进行训练的自动编码器超过了 OCGAN,但并未达到我们的方法的性能。由于对于最近邻 (1-NN) 来说,每个训练向量都可以存储,因此它在这类小型数据集上的表现非常出色。然而,平均而言,我们的方法仍然优于所有评估方法。

4.2 MVTec 检测数据集
在所有针对 MVTec AD 的实验中,输入图像被缩放到 w = h = 256 像素。我们在没有异常的图像上训练了 100 个 epoch,批大小为 1。由于网络的感受野有限,这相当于每个批次对大量补丁进行训练。我们使用初始学习率为 1e-4 和权重衰减系数为 1e-5 的 Adam 优化器来训练教师模型。为了获得最佳性能,MNIST 和 CIFAR-10 上的模型配置使用了 λk=λc=1 和 λm=0。集成包含三个学生模型。
为了在教师输出描述符上训练浅层分类器,从教师特征图中随机采样子集向量。然后通过PCA将其维数降低到保留95%方差。变分和确定性自编码器使用简单的全连接架构实现,并在所有可用的描述符上进行训练。除了直接拟合模型以适应教师的特征分布外,我们还将我们的方法与Bergmann等人在此数据集上提出的最佳深度学习方法进行了比较[7]。这些方法包括CNN-特征词典[23]、SSIM自编码器[8]和AnoGAN[32]。所有的超参数都在我们的补充材料中做了详细的介绍。

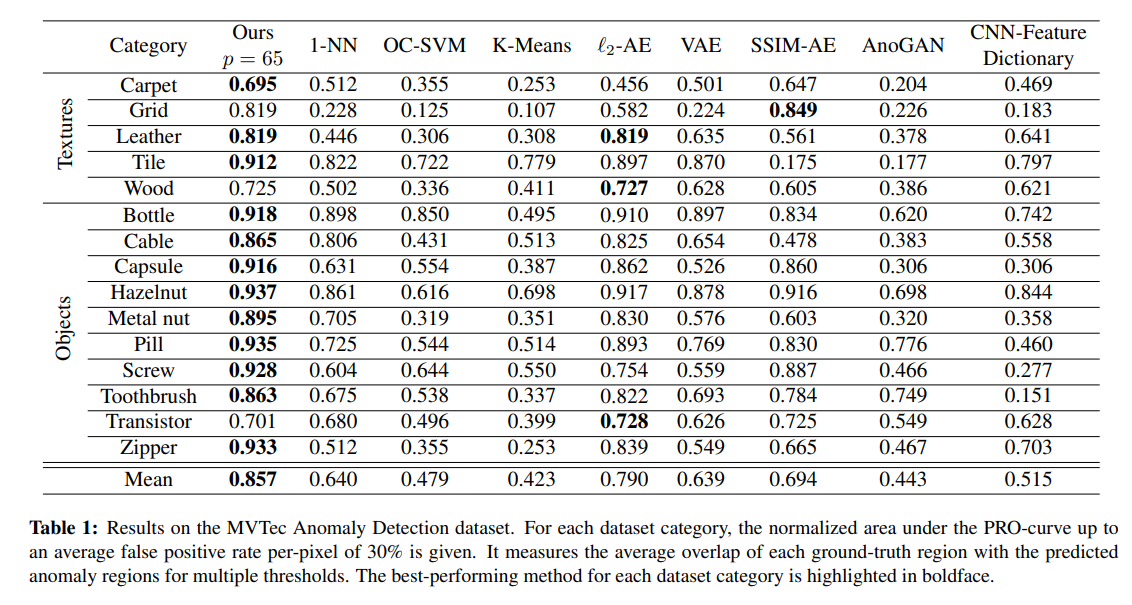
我们计算了一个基于按区域重叠度量(PRO)的阈值无关评估指标,该指标对不同大小的真实区域进行相等加权。这与简单的按像素度量(如ROC曲线)形成对比,在后者的度量中,一个正确分割的大区域可以抵消许多错误分割的小区域。Bergmann等人在[7]中也使用了这种方法。为了计算PRO度量,首先对异常分数应用阈值以对每个像素做出是否存在异常的二元决策。对于真实图像中的每个连通分量,计算其与被阈值化为异常区域的相对重叠度。我们对大量的增加的阈值计算PRO值,直到整个数据集的平均每个像素假阳性的率达到30%,并使用ROC曲线下面积作为检测性能的度量。请注意,当假阳性率很高时,输入图像的大部分会被错误地标记为异常,即使PRO值完美,也无法反映这一点。我们将积分面积归一化到最大可实现值1。


表1显示了我们训练每个算法时的结果,以使它们具有可比性。我们的方法在几乎所有数据集类别中都始终优于所有其他评估算法。在应用PCA后直接拟合教师描述符的浅层机器学习算法未能对大多数数据集类别实现令人满意的表现。这表明其容量不足以准确地建模大量可用的训练样本。同样的情况也适用于卷积神经网络特征字典。正如我们在MNIST 和CIFAR上的先前实验一样,在浅层模型中,1-NN 在所有情况下都给出了最佳结果。使用大量训练特征以及确定性自编码器可以提高性能,但仍然无法与我们的方法相媲美。目前用于异常分割的生成方法,如 AnoGAN 和 SSIM 自编码器,与针对教师判别嵌入进行拟合的浅层方法表现相似。这表明从头开始学习表示以检测异常的方法与利用判别嵌入作为先验知识的方法之间确实存在差距。
表3显示了我们的算法在不同感受野大小p∈{17,33,65}时以及结合多个尺度的情况下的性能。对于一些物体,如瓶子和电线,更大的感受野会产生更好的结果。对于其他物体,如木头和牙刷,则会观察到相反的行为。结合多个尺度可以提高许多数据集类别的性能。图5可视化了一个定性示例,以突出我们多尺度异常分割的好处。

5,结论
我们为自然图像中无监督异常分割的挑战性问题提出了一个新的框架。异常分数来源于学生网络集合的预测方差和回归误差,根据描述性教师网络的嵌入向量进行训练。集合训练可以端到端进行,完全基于无异常的训练数据,而无需重新询问先前的数据注释。我们的方法可以很容易地扩展到检测多个尺度上的异常。我们在许多真实世界的计算机视觉数据集上对当前最先进的方法进行了改进,用于一类分类和异常分割。
深度学习论文翻译解析(二十二):Uniformed Students Student-Teacher Anomaly Detection With Discriminative Latent Embbeddings的更多相关文章
- 深度学习论文翻译解析(十二):Fast R-CNN
论文标题:Fast R-CNN 论文作者:Ross Girshick 论文地址:https://www.cv-foundation.org/openaccess/content_iccv_2015/p ...
- 深度学习论文翻译解析(十):Visualizing and Understanding Convolutional Networks
论文标题:Visualizing and Understanding Convolutional Networks 标题翻译:可视化和理解卷积网络 论文作者:Matthew D. Zeiler Ro ...
- 深度学习论文翻译解析(十六):Squeeze-and-Excitation Networks
论文标题:Squeeze-and-Excitation Networks 论文作者:Jie Hu Li Shen Gang Sun 论文地址:https://openaccess.thecvf.co ...
- 深度学习论文翻译解析(十四):SSD: Single Shot MultiBox Detector
论文标题:SSD: Single Shot MultiBox Detector 论文作者:Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Sz ...
- 深度学习论文翻译解析(十五):Densely Connected Convolutional Networks
论文标题:Densely Connected Convolutional Networks 论文作者:Gao Huang Zhuang Liu Laurens van der Maaten Kili ...
- 深度学习论文翻译解析(十八):MobileNetV2: Inverted Residuals and Linear Bottlenecks
论文标题:MobileNetV2: Inverted Residuals and Linear Bottlenecks 论文作者:Mark Sandler Andrew Howard Menglong ...
- 深度学习论文翻译解析(十九):Searching for MobileNetV3
论文标题:Searching for MobileNetV3 论文作者:Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Che ...
- 深度学习论文翻译解析(二):An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
论文标题:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application ...
- 深度学习论文翻译解析(八):Rich feature hierarchies for accurate object detection and semantic segmentation
论文标题:Rich feature hierarchies for accurate object detection and semantic segmentation 标题翻译:丰富的特征层次结构 ...
- 深度学习论文翻译解析(四):Faster R-CNN: Down the rabbit hole of modern object detection
论文标题:Faster R-CNN: Down the rabbit hole of modern object detection 论文作者:Zhi Tian , Weilin Huang, Ton ...
随机推荐
- lattice crosslink开发板mipi核心板csi测试dsi屏lif md6000 fpga 常见问题解答
1. 概述 CrossLink开发板,是用Lattice的芯片CrossLink 家族系列的,LIF-MD6000-6JM80I.该芯片用于桥接视频接口功能,自带2路MIPI硬核的功能,4 LANE ...
- SVM简单分类的使用 sklearn机器学习
# sklearn 库中导入 svm 模块 from sklearn import svm # 定义三个点和标签 X = [[2, 0], [1, 1], [2,3]] y = [0, 0, 1] # ...
- .NET Emit 入门教程:第六部分:IL 指令:9:详解 ILGenerator 指令方法:运算操作指令(指令篇结束)
前言: 经过前面几篇的学习,我们了解到指令的大概分类,如: 参数加载指令,该加载指令以 Ld 开头,将参数加载到栈中,以便于后续执行操作命令. 参数存储指令,其指令以 St 开头,将栈中的数据,存储到 ...
- 【Oracle】获取字符串中特定字符在字符串中出现的次数
[Oracle]获取字符串中特定字符在字符串中出现的次数 使用regexp_count函数 例子: select regexp_count('A,B,D,E;Q;F;GQWEQWE:qwe',';') ...
- 从0开始:500行代码实现 LSM 数据库
简介: LSM-Tree 是很多 NoSQL 数据库引擎的底层实现,例如 LevelDB,Hbase 等.本文基于<数据密集型应用系统设计>中对 LSM-Tree 数据库的设计思路,结合代 ...
- 网易云音乐音视频算法的 Serverless 探索之路
简介: 基于音视频算法服务化的经验,网易云音乐曲库团队与音视频算法团队一起协作,一起共建了网易云音乐音视频算法处理平台,为整个云音乐提供统一的音视频算法处理平台.本文将分享我们如何通过 Server ...
- [Go] CORS 支持多个 origin 访问的思路 (Access-Control-Allow-Origin 部分)
以下为局部伪代码,仅供参考: var allowOrigin string allowOrigins := config.AppConf.Get("middleware.cors.allow ...
- [FE] Quasar BEX 预览版指南
BEX(Browser Extension)是 Quasar 基于同一套代码允许编译成浏览器扩展来运行,支持 Firefox & Chrome. 截止目前(2019/12/25), bex 模 ...
- git fatal detected dubious ownership in repository 的解决方法
我换了一台电脑,将旧电脑的硬盘换到新电脑上:我装了双系统,切换到另一个系统时:我发现了 git 代码仓库无法执行 git 命令,不断报错 fatal: detected dubious ownersh ...
- 2019-10-31-VisualStudio-断点调试详解
title author date CreateTime categories VisualStudio 断点调试详解 lindexi 2019-10-31 8:56:7 +0800 2019-06- ...