Quanto: PyTorch 量化工具包
量化技术通过用低精度数据类型 (如 8 位整型 (int8)) 来表示深度学习模型的权重和激活,以减少传统深度学习模型使用 32 位浮点 (float32) 表示权重和激活所带来的计算和内存开销。
减少位宽意味着模型的内存占用更低,这对在消费设备上部署大语言模型至关重要。量化技术也使得我们可以针对较低位宽数据类型进行特殊的计算优化,例如 CUDA 设备有针对 int8 或 float8 矩阵乘法的硬件优化。
市面上有许多可用于量化 PyTorch 深度学习模型的开源库,它们各有特色及局限。通常来讲,每个库都仅实现了针对特定模型或设备的特性,因而普适性不强。此外,尽管各个库的设计原理大致相同,但不幸的是,它们彼此之间却互不兼容。
因此,quanto 库应运而出,其旨在提供一个多功能的 PyTorch 量化工具包。目前 quanto 包含如下特性:
- 在 eager 模式下可用 (适用于无法成图的模型),
- 生成的量化模型可以运行于任何设备 (包括 CUDA 设备和 MPS 设备) 上,
- 自动插入量化和反量化结点,
- 自动插入量化后的
torch.nn.functional算子, - 自动插入量化后的
torch.nn模块 (具体支持列表见下文), - 提供无缝的模型量化工作流,支持包含静态量化、动态量化在内的多种模型量化方案,
- 支持将量化模型序列化为
state_dict, - 不仅支持
int8权重,还支持int2以及int4, - 不仅支持
int8激活,还支持float8。
最近,出现了很多仅专注于大语言模型 (LLM) 的量化算法,而 quanto 的目标为那些适用于任何模态的、易用的量化方案 (如线性量化,分组量化等) 提供简单易用的量化原语。
我们无意取代其他量化库,而是想通过新算法的实现门槛来促进创新,使得大家能够轻松地实现新模块,抑或是轻松组合现有模块来实现新算法。
毫无疑问,量化很困难。当前,如要实现模型的无缝量化,需要大家对 PyTorch 的内部结构有深入了解。但不用担心,quanto 的目标就是为你完成大部分繁重的工作,以便你可以集中精力在最重要的事情上,即: 探索低比特 AI 从而找出惠及 GPU 穷人的解决方案。
量化工作流
大家可以 pip 安装 quanto 包。
pip install quanto
quanto 没有对动态和静态量化进行明确区分。因为静态量化可以首先对模型进行动态量化,随后再将权重 冻结 为静态值的方式来完成。
典型的量化工作流包括以下步骤:
1. 量化
将标准浮点模型转换为动态量化模型。
quantize(model, weights=quanto.qint8, activations=quanto.qint8)
此时,我们会对模型的浮点权重进行动态量化以用于后续推理。
2. 校准 (如果上一步未量化激活,则可选)
quanto 支持校准模式。在校准过程中,我们会给量化模型传一些代表性样本,并在此过程中记录各算子激活的统计信息 (如取值范围)。
with calibration(momentum=0.9):
model(samples)
上述代码会自动使能量化模块的激活量化功能。
3. 微调,即量化感知训练 (可选)
如果模型的性能下降太多,可以尝试将其微调几轮以恢复原浮点模型的性能。
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data).dequantize()
loss = torch.nn.functional.nll_loss(output, target)
loss.backward()
optimizer.step()
4. 冻结整型权重
模型冻结后,其浮点权重将替换为量化后的整型权重。
freeze(model)
请参阅 该例 以深入了解量化工作流程。你还可以查看此 notebook,其提供了一个完整的用 quanto 量化 BLOOM 模型的例子。
效果
下面我们列出了一些初步结果,我们还在紧锣密鼓地更新以进一步提高量化模型的准确性和速度。但从这些初步结果中,我们仍能看出 quanto 的巨大潜力。
下面两幅图评估了 mistralai/Mistral-7B-v0.1 在不同的量化参数下的准确度。注意: 每组的第一根柱子均表示非量化模型。
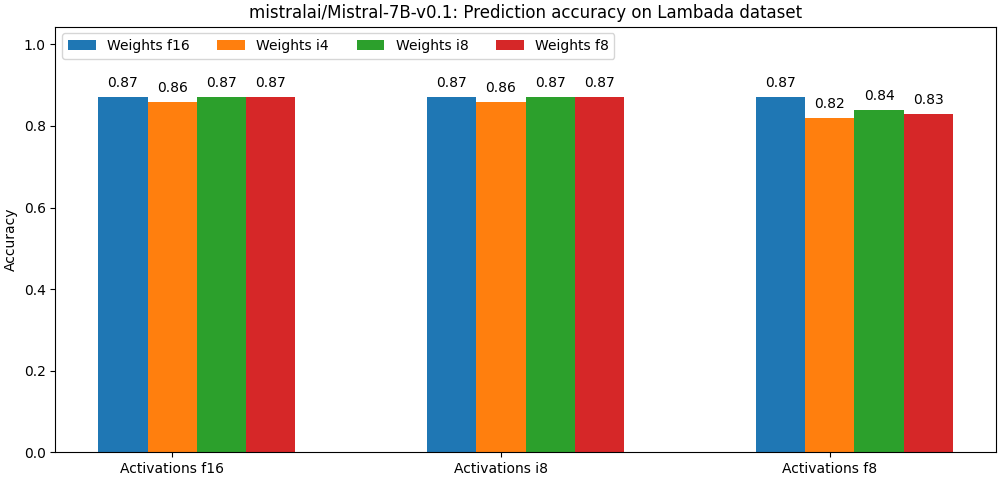
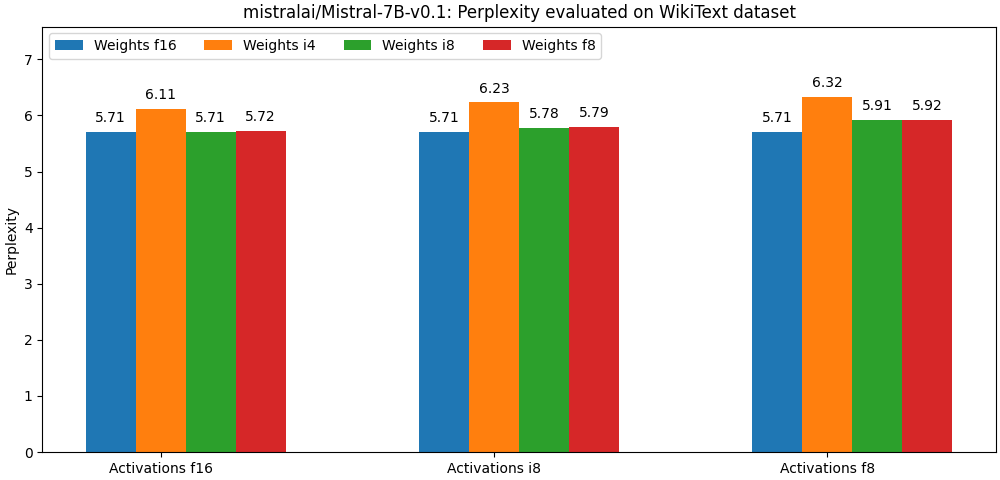
上述结果均未使用任何高级训后量化算法 (如 hqq 或 AWQ)。
下图给出了在英伟达 A100 GPU 上测到的词元延迟。
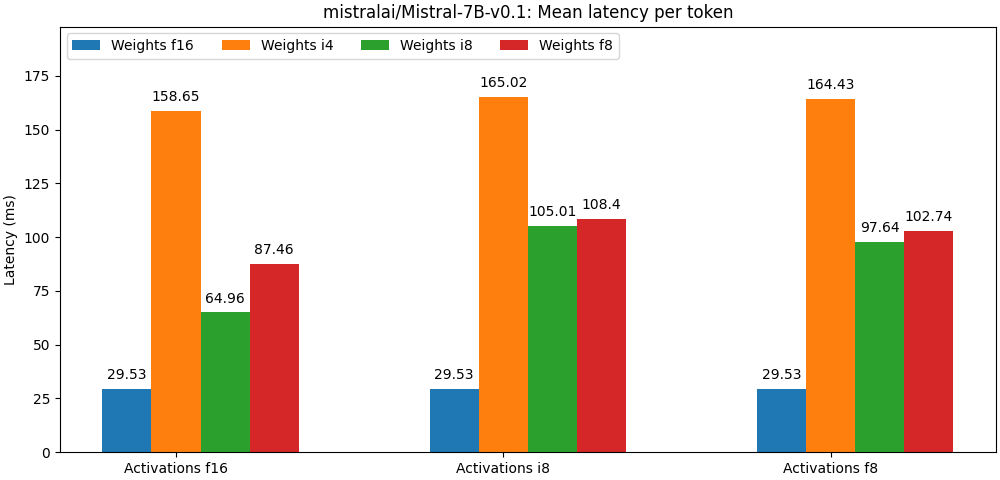
这些测试结果都尚未利用任何优化的矩阵乘法算子。可以看到,量化位宽越低,开销越大。我们正在持续改进 quanto,以增加更多的优化器和优化算子,请持续关注我们的性能演进。
请参阅 quanto 基准测试 以了解在不同模型架构及配置下的详细结果。
集成进 transformers
我们已将 quanto 无缝集成至 Hugging Face transformers 库中。你可以通过给 from_pretrained API 传 QuantoConfig 参数来对任何模型进行量化!
目前,你需要使用最新版本的 accelerate 以确保完全兼容。
from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = QuantoConfig(weights="int8")
quantized_model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config= quantization_config
)
你只需在 QuantoConfig 中设置相应的参数即可将模型的权重/激活量化成 int8 、 float8 、 int4 或 int2 ; 还可将激活量化成 int8 或 float8 。如若设成 float8 ,你需要有一个支持 float8 精度的硬件,否则当执行 matmul (仅当量化权重时) 时,我们会默认将权重和激活都转成 torch.float32 或 torch.float16 (具体视模型的原始精度而定) 再计算。目前 MPS 设备不支持 float8 , torch 会直接抛出错误。
quanto 与设备无关,这意味着无论用的是 CPU/GPU 还是 MPS (Apple 的芯片),你都可以对模型进行量化并运行它。
quanto 也可与 torch.compile 结合使用。你可以先用 quanto 量化模型,然后用 torch.compile 来编译它以加快其推理速度。如果涉及动态量化 (即使用量化感知训练或对激活进行动态量化),该功能可能无法开箱即用。因此,请确保在使用 transformers API 创建 QuantoConfig 时,设置 activations=None 。
quanto 可用于量化任何模态的模型!下面展示了如何使用 quanto 将 openai/whisper-large-v3 模型量化至 int8 。
from transformers import AutoModelForSpeechSeq2Seq
model_id = "openai/whisper-large-v3"
quanto_config = QuantoConfig(weights="int8")
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="cuda",
quantization_config=quanto_config
)
你可查阅此 notebook,以详细了解如何在 transformers 中正确使用 quanto !
实现细节
量化张量
quanto 的核心是一些 Tensor 子类,其主要做下面两件事:
- 将源张量按最优
比例投影至给定量化数据类型的取值范围内。 - 将投影后的值映射至目标数据类型。
当目标类型是浮点型时,映射由 PyTorch 原生转换接口 (即 Tensor.to() ) 完成。而当目标类型是整型时,映射可以用一个简单的舍入操作 (即 torch.round() ) 来完成。
投影的目标是提高数据类型转换的精确度,具体可以通过最小化以下两个值来达成:
- 饱和值的个数 (即有多少个数最终映射为目标数据类型的最小值/最大值),
- 归零值的个数 (即有多少个数因为小于目标数据类型可以表示的最小数字,所以被映射成了 0)。
为了提高效率起见, 8 比特 量化时,我们使用对称投影,即以零点为中心进行投影。一般而言,对称量化张量与许多标准算子兼容。
在使用较低位宽的量化 (如 int2 或 int4 ) 时,一般使用的是仿射投影。此时,会多一个 zeropoint 参数以对齐投影值和原值的零点。这种方法对量化范围的覆盖度会好些。仿射量化张量通常更难与标准算子兼容,因此一般需要自定义很多算子。
量化 torch.nn 模块
quanto 实现了一种通用机制,以用能够处理 quanto 张量的 quanto 模块替换相应的 torch 模块 ( torch.nn.Module )。
quanto 模块会动态对 weights 进行数据类型转换,直至模型被冻结,这在一定程度上会减慢推理速度,但如果需要微调模型 (即量化感知训练),则这么做是需要的。
此外,我们并未量化 bias 参数,因为它们比 weights 小得多,并且对加法进行量化很难获得太多加速。
我们动态地将激活量化至固定取值范围 (默认范围为 [-1, 1] ),并通过校准过程决定最佳的比例 (使用二阶动量更新法)。
我们支持以下模块的量化版:
- Linear (QLinear)。仅量化权重,不量化偏置。输入和输出可量化。
- Conv2d (QConv2D)。仅量化权重,不量化偏置。输入和输出可量化。
- LayerNorm。权重和偏至均 不 量化。输出可量化。
定制算子
得益于 PyTorch 出色的调度机制,quanto 支持在 transformers 或 diffusers 的模型中最常用的函数,无需过多修改模型代码即可启用量化张量。
大多数“调度”功能可通过标准的 PyTorch API 的组合来完成。但一些复杂的函数仍需要使用 torch.ops.quanto 命名空间下的自定义操作。其中一个例子是低位宽的融合矩阵乘法。
训后量化优化
quanto 中尚未支持高级的训后量化算法,但该库足够通用,因此与大多数 PTQ 优化算法兼容,如 hqq、AWQ
展望未来,我们计划无缝集成这些最流行的算法。
为 Quanto 作出贡献
我们非常欢迎大家对 quanto 作出贡献,尤其欢迎以下几类贡献:
- 实现更多针对特定设备的 quanto 优化算子,
- 支持更多的 PTQ 优化算法,
- 扩大量化张量可调度操作的覆盖面。
英文原文: https://hf.co/blog/quanto-introduction
原文作者: David Corvoysier,Younes Belkada,Marc Sun
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
Quanto: PyTorch 量化工具包的更多相关文章
- 模型压缩一半,精度几乎无损,TensorFlow推出半精度浮点量化工具包,还有在线Demo...
近日,TensorFlow模型优化工具包又添一员大将,训练后的半精度浮点量化(float16 quantization)工具. 有了它,就能在几乎不损失模型精度的情况下,将模型压缩至一半大小,还能改善 ...
- pytorch的三种量化方式详解
pytorch的三种量化方式详解 这篇博客详细介绍了pytorch官方教程提到的三种量化方式的原理,详细解释了三种量化方式的区别: 1. 静态量化 :torch.quantize_per_tensor ...
- Pytorch快速入门及在线体验
本文搭配了Pytorch在线环境,可以直接在线体验. Pytorch是Facebook 的 AI 研究团队发布了一个基于 Python的科学计算包,旨在服务两类场合: 1.替代numpy发挥GPU潜能 ...
- 对比学习:《深度学习之Pytorch》《PyTorch深度学习实战》+代码
PyTorch是一个基于Python的深度学习平台,该平台简单易用上手快,从计算机视觉.自然语言处理再到强化学习,PyTorch的功能强大,支持PyTorch的工具包有用于自然语言处理的Allen N ...
- pytorch 入门指南
两类深度学习框架的优缺点 动态图(PyTorch) 计算图的进行与代码的运行时同时进行的. 静态图(Tensorflow <2.0) 自建命名体系 自建时序控制 难以介入 使用深度学习框架的优点 ...
- 安装PyTorch后,又安装TensorFlow,CUDA相关问题思考
下面的话是我的观察和思考,请多多批评. TensorFlow 要用 CUDA.CUDA toolkit.CUDNN,看好版本的对应关系再安装,磨刀不误砍柴工. 1)NVIDIA Panel 里显示的N ...
- 实践torch.fx第二篇-fx量化实操
好久不见各位,哈哈,又鸽了好久. 本文紧接上一篇<实践torch.fx第一篇--基于Pytorch的模型优化量化神器>继续说,主要讲如何利用FX进行模型量化. 为什么这篇文章拖了这么久,有 ...
- TVM部署预定义模型
TVM部署预定义模型 本文通过深度学习框架量化的模型加载到TVM中.预量化的模型导入是在TVM中提供的量化支持之一. 本文演示如何加载和运行由PyTorch,MXNet和TFLite量化的模型.加载后 ...
- 端云协同,打造更易用的AI计算平台
内容来源:华为开发者大会2021 HMS Core 6 AI技术论坛,主题演讲<端云协同,HUAWEI HiAI Foundation打造更易用的AI计算平台>. 演讲嘉宾:华为海思AI技 ...
- HDD线上沙龙·创新开发专场:多元服务融合,助力应用创新开发
5月24日,由华为开发者联盟主办的HUAWEI Developer Day(华为开发者日,简称HDD)线上沙龙·创新开发专场在华为开发者学堂及各大直播平台与广大开发者见面.直播内容主要聚焦Harmon ...
随机推荐
- Cocos Creator 2.x升级至Cocos Creator 3.x
1.导入类时,批量导入 2.导入 override...关键字时,批量导入 3.this.node.scale = 0.6-->this.node.setScale(0.6, 0.6); 4.n ...
- 【Azure Redis 缓存】Azure Redis 异常 - 因线程池Busy而产生的Timeout异常问题
问题描述 StackExchange.Redis在使用线程池后,偶尔会出现Timeout awaiting response 或者 No connection is available to serv ...
- win10图标异常显示空白,WiFi图标消失等情况解决方案
出现WiFi图标异常不显示,但是网络却正常,以下为解决方案: Win + R 快捷键调出运行框,输入%USERPROFILE%\AppData\Local,找到IconCache.db文件并删除,之后 ...
- URLDNS链分析
一.概述 URLDNS 是ysoserial中利用链的一个名字,通常用于检测是否存在Java反序列化漏洞.该利用链具有如下特点: 不限制jdk版本,使用Java内置类,对第三方依赖没有要求 目标无回显 ...
- FFmpeg命令行之ffplay
一.简述 ffplay是以FFmpeg框架为基础,外加渲染音视频的库libSDL构建的媒体文件播放器. 二.命令格式 在安装了在命令行中输入如下格式的命令: ffplay [选项] ['输入文件'] ...
- 3、Azure Devops之Azure Repos篇
1.什么是Azure Repos Azure Repos,就是我们常说的代码仓库,相当于gitee,github,git,svn工具.主要是提供给开发人员使用的,管理.查看代码的部件.通过Files. ...
- Linux输入输出
1.重定向概述 1.什么是重定向 将原本要输出到屏幕的数据信息,重新定向到某个指定的文件中.比如:每天凌晨定时备份数据,希望将备份数据的结果保存到某个文件中. 这样第二天通过查看文件的内容就知道昨天备 ...
- 记录--vue3的宏到底是什么东西?
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言 从vue3开始vue引入了宏,比如defineProps.defineEmits等.我们每天写vue代码时都会使用到这些宏,但是你有 ...
- 记录--前端换肤方案 - element+less无感换肤(无需页面刷新)
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前端换肤方案 - element+less无感换肤(无需页面刷新) 前言 前不久在改造一个迭代了一年多的项目时,增加了一个换肤功能.通过自 ...
- 工作记录:TypeScript从入门到项目实战(基础篇)
前言 TypeScript是什么? 引用官方原话 TypeScript是JavaScript类型的超集,它可以编译成纯JavaScript.TypeScript可以在任何浏览器.任何计算机和任何操作系 ...