面试必备HashMap源码解析
Map的实现有很多种,而HashMap算是最经典的实现之一了吧,在平时的使用中,绝大部分的使用也都是HashMap,我记得刚入行那会,脑子里对Map的使用就是Map map = new HashMap(); ,而在面试中,HashMap的实现原理也是高频面试题。那么热度如此之高的HashMap的神秘面纱之下,究竟是怎样的呢。
HashMap<Integer,Integer> map = new HashMap();
map.put(1,2);
map.get(1);
上面这几行代码实我们平时使用频率最高的,其实要使用它很简单,我们都知道数组就是在一个连续地址下依次向后排列存储数据的数据结构,查询效率很高,但插入效率很低,像我们常用的ArrayList底层实现就是数组,而我们可以看到,它在插入新数据时,每次都要复制到一个新的数组里面;链表则是使用节点去存储下一个节点的数据,达到一种逻辑上的连续数据存储,插入速度很快,但查询却要一个一个遍历,那么有没有一种数据结构,既可以查询的很快,插入也能保持一个很快的速度呢,答案当然是有的,就是map,那么今天我们就来了解一下作为最经典的map->HashMap是如何实现的呢,首先看一下初始化方法:
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
我们发现初始化方法一共4种,第一种最简单只是初始化了一个loadFactor字段,第二种其实还是调用了第三种的,我们直接看第三种:
除去上面的三个if else ,其实也就是初始化了一个loadFactor字段,和一个threshold字段,我们看一下tableSizeFor方法:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
这个算法很牛逼,作用是让我们传入的值转为最近的上位2的n次方,我研究了一下,发现不管是传入的非2的n次方的正数是多少,都会向上进一位,可以覆盖到前32位,其实现原理是这样的:
首先减一可以保证当传入值为2的n次方时,不再向上进一位,而无论是我们传入的什么值,都可以将我们当前的位数以下0全部覆盖成1,如下示意图:
第一次运算 n |= n >>> 1 :
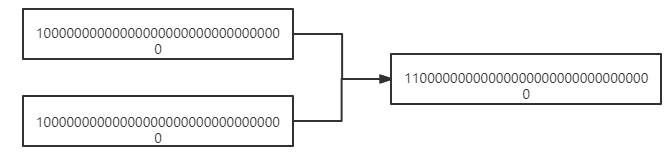
第二次运算 n |= n >>> 2 :
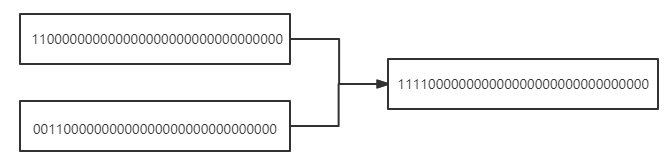
第三次运算 n |= n >>> 4 :

第四次运算 n |= n >>> 8 :
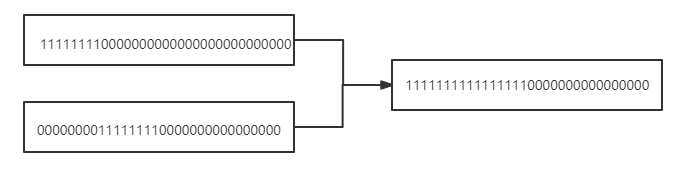
第五次运算 n |= n >>> 16:
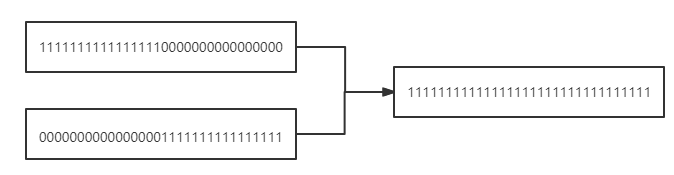
接下来我们再看第四种,传入map的,我们直接看putMapEntries方法:
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
这里首先会判断是否需要初始化,tableSizeFor方法我们刚刚介绍过其牛逼之处,就是为了让传入的值变为向上最近的一个2的n次方的值,resize()方法是用来扩容和初始化的方法,做完这些判断的处理,就会调用putVal方法,这个方法其实就是我们在put的时候调用的:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
在介绍put和get两个最核心的方法前,我们先了解一下HashMap的构造,以方便我们去深入了解代码:
了解过的同学应该都知道hashMap由数组加链表组成,那么具体是什么样的呢,我们先看一张图:
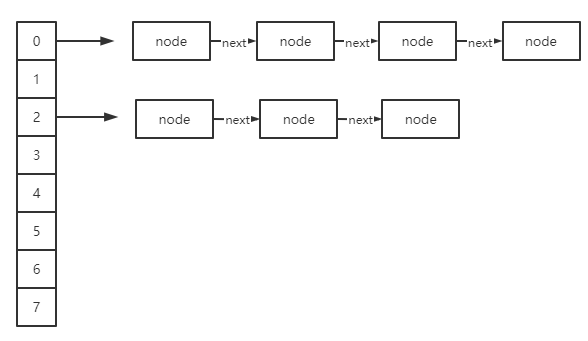
图画的可能不是很直观,从数据结构组成来看,就是一个node数组,数组的每个下标位存储了一个链表,在hashMap中实现:
transient Node<K,V>[] table; //node数组
Node实现:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
看到next估计很多人就明白了这应该是个链表,而没有prev也说明了它是一个单向链表,结合代码来看,我的图画的还是勉强可以看的懂的。
大体上了解了HashMap的构成,我们再来看刚才没有说完的putVal方法:
首先会计算key的hash值:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这里hash计算之后用高16位和低16位做了异或运算,其实就是为了保证散列的更加平均。
再看putVal方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) //初始化
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) //插入node链表为空
tab[i] = newNode(hash, key, value, null);
else { //插入node链表已存在数据
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) //说明当前node下表头和插入数据key相同
e = p;
else if (p instanceof TreeNode) //红黑树插入
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { //表示当前链表节点为最后一个节点
p.next = newNode(hash, key, value, null); //直接插入
if (binCount >= TREEIFY_THRESHOLD - 1) // 默认大于8,改为红黑树存储
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) //找到相同key数据
break;
p = e;
}
}
if (e != null) { // 表示插入数据key已存在
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); //钩子方法,LinkedHashMap中有实现
return oldValue; //返回旧值
}
}
++modCount;
if (++size > threshold)
resize(); //扩容
afterNodeInsertion(evict); //钩子方法,LinkedHashMap中有实现
return null;
}
看上面的代码加注释可以发现:
1.首先会判断链表是否为空,为空则需要初始化,初始化方法resize()我们下面单独介绍。
2.计算得到当前key的数组下标,计算方法就是用上面计算的hash值和数组长度取余(代码中使用(n - 1) & hash实现,这里希望大家知道一个公式:a%(2<<n )= a & (2<<n - 1),而n在这里必然是2的n次方,因此等于hash%n ),用计算得到的下标查询数组中链表是否存在,若为空,直接new node并赋值到数组当前下标作为链表表头
3.走到这里说明上面两者都不成立,说明数组存在并找到了数据,遍历,若为链表插入尾部,或为红黑树插入树节点
4.判断插入数据是否为已存在key,存在返回旧值,不存在返回null
上面就是put方法的大体逻辑,我们再看看刚才没有说的resize方法:
final Node<K,V>[] resize() { //这里old指初始化或扩容前,以下用前代替,new代表初始化或扩容之后,用新代替
Node<K,V>[] oldTab = table; //前node数组
int oldCap = (oldTab == null) ? 0 : oldTab.length; //前数组大小
int oldThr = threshold; //前实际可存储大小(大于则需要扩容)
int newCap, newThr = 0; //新数组大小和新实际存储大小
if (oldCap > 0) { //是否已初始化
if (oldCap >= MAXIMUM_CAPACITY) { //是否大于最大值(大于最大值后不再扩容,一般不会达到)
threshold = Integer.MAX_VALUE;
return oldTab; //等于最大值,直接返回
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY) //扩容(这里扩容其实就是扩大两倍)并判断之后是否达到最大值
newThr = oldThr << 1; // double threshold //实际大小扩容两倍
}
else if (oldThr > 0) // 这种情况一般是初始化自定义了threshold值
newCap = oldThr;
else { // 说明都没有初始化,进行默认值初始化(默认值为16和0.75*16)
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) { //初始化实际允许大小
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) { //扩容场景
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null) //当前节点中只有一个,与运算直接插入新节点
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) //树结构插入
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null; //这俩node用来记录低位链表(原位置)
Node<K,V> hiHead = null, hiTail = null; //这俩node用来记录高位链表
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) { //低位链表插入
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else { //高位链表插入
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) { //低位链表插入node
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) { //高位链表插入node
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
初始化场景就是一些if-else操作,初始化最大容量和实际存储容量,我基本上每一行代码都做了注释,应该不难懂,这里主要介绍一下扩容场景及jdk1.7中会遇到的死循环问题(其实也不算啥问题,HashMap本身就不是线程安全的,非要在并发下操作有问题也属正常,不过jdk的大牛们还是听到了呼声,在1.8的时候改了),首先看下1.8的扩容流程:
1.当前下标链表只有一个节点,直接插入
2.树结构插入
3.这一步明显就是链表多个节点场景,创建了俩新链表,其实是因为扩容之后依然是通过hash取余计算,而扩容两倍之后再取余则有可能落到两个不同的下标(如hash为7,原本长度是4,则会落到下标3的位置,扩容后长度为8,则会落到下标7的位置,而hash为3则不变),这里使用(e.hash & oldCap) == 0来计算是否落在原来的位置还是新的高位,网上看了很多解释都有点晦涩,这里我解释一下:首先oldCap是2的n次方,因此二进制必然是只有一个1(类似0000 1000这种),当hash值小于oldCap时,必然落于原下标位置,当大于时,高于oldCap的1的位置的所有1取余都会被整除掉,所以,当只需看余数是否大于oldCap就可判断是否在原位置,而当余数大于oldCap时,hash值和oldCap二进制1的相同位置处必然为1,则与运算必不等于0,否则必等于0.
扩容流程图如下:
扩容前:

扩容第一步:
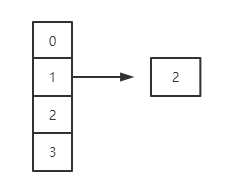
第二步:
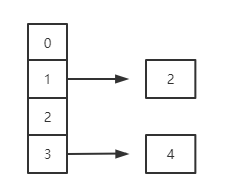
第三步:
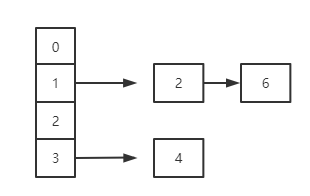
到这里我们这里已经扩容完成了,看着没啥问题吧。接下来我们看下jdk1.7是怎么实现的:
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
上面基本差不多,都是创建一个2倍大小的新数组,主要看一下遍历扩容流程,流程图如下:
扩容前:
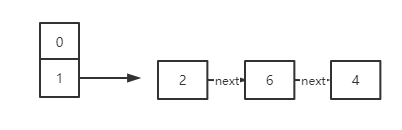
扩容:

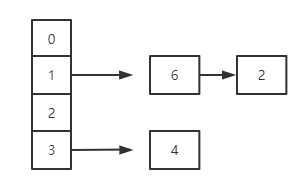
和1.8的区别在于插入链表采用倒序插入,而这正是1.7会造成死循环的关键,我们来分析一下:
hashMap死循环
在1.7中,假设有一个线程1已经执行完而线程2刚好执行到e=2,这个时候6指向了2,而e.next指向6,,此时cpu调度给了线程2,线程2开始执行又会将2指向6如此反复,形成死循环,而1.8的顺序不会颠倒,所以不会出现环形链表出现。
put方法聊完了,我们再来看看get方法,代码走起:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) { // 判断数据是否为空
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k)))) //判断hash计算位置的node第一个节点是否和key相同
return first;
if ((e = first.next) != null) { // 下一个是否为空
if (first instanceof TreeNode) //树结构,走红黑树查询
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do { //遍历查询key并返回value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null; // 查找不到返回null
}
直接看getNode方法,这比put方法简单多了:
1.首先hash取余定位到数组的下标
2.判断链表是否为空,不为空先找第一个,
3.判断是否为树,树节点查找
4.遍历链表,查找key,找到返回value,找不到返回null
总结:
如果读过我之前的synchronized源码,或者是reentrantLock源码,再来看这个会发现还是比较简单的,除了红黑树左旋右旋有点复杂,但是其实抛开红黑树,并不影响我们对HashMap的理解,红黑树这里就不讲了,之前写过一篇简单的理解,说实话,要我写写不好,实在是做不到让别人能看懂,以后在研究研究提升自己吧。
HashMap后面还会有ConcurrentHashMap,其实写这篇也就是为了给ConcurrentHashMap铺路,理解了这篇,我想到时候看再理解ConcurrentHashMap可能不会那么吃力,这篇的精髓还是在于如何结合链表和数组的长处,构造一个新增,查询都相对较快的数据结构。
面试必备HashMap源码解析的更多相关文章
- 【转】Java HashMap 源码解析(好文章)
.fluid-width-video-wrapper { width: 100%; position: relative; padding: 0; } .fluid-width-video-wra ...
- HashMap源码解析 非原创
Stack过时的类,使用Deque重新实现. HashCode和equals的关系 HashCode为hash码,用于散列数组中的存储时HashMap进行散列映射. equals方法适用于比较两个对象 ...
- Java中的容器(集合)之HashMap源码解析
1.HashMap源码解析(JDK8) 基础原理: 对比上一篇<Java中的容器(集合)之ArrayList源码解析>而言,本篇只解析HashMap常用的核心方法的源码. HashMap是 ...
- 最全的HashMap源码解析!
HashMap源码解析 HashMap采用键值对形式的存储结构,每个key对应唯一的value,查询和修改的速度很快,能到到O(1)的平均复杂度.他是非线程安全的,且不能保证元素的存储顺序. 他的关系 ...
- HashMap源码解析和设计解读
HashMap源码解析 想要理解HashMap底层数据的存储形式,底层原理,最好的形式就是读它的源码,但是说实话,源码的注释说明全是英文,英文不是非常好的朋友读起来真的非常吃力,我基本上看了差不多 ...
- 详解HashMap源码解析(下)
上文详解HashMap源码解析(上)介绍了HashMap整体介绍了一下数据结构,主要属性字段,获取数组的索引下标,以及几个构造方法.本文重点讲解元素的添加.查找.扩容等主要方法. 添加元素 put(K ...
- HashMap 源码解析
HashMap简介: HashMap在日常的开发中应用的非常之广泛,它是基于Hash表,实现了Map接口,以键值对(key-value)形式进行数据存储,HashMap在数据结构上使用的是数组+链表. ...
- 给jdk写注释系列之jdk1.6容器(4)-HashMap源码解析
前面了解了jdk容器中的两种List,回忆一下怎么从list中取值(也就是做查询),是通过index索引位置对不对,由于存入list的元素时安装插入顺序存储的,所以index索引也就是插入的次序. M ...
- 【Java深入研究】9、HashMap源码解析(jdk 1.8)
一.HashMap概述 HashMap是常用的Java集合之一,是基于哈希表的Map接口的实现.与HashTable主要区别为不支持同步和允许null作为key和value.由于HashMap不是线程 ...
- HashMap 源码解析(一)之使用、构造以及计算容量
目录 简介 集合和映射 HashMap 特点 使用 构造 相关属性 构造方法 tableSizeFor 函数 一般的算法(效率低, 不值得借鉴) tableSizeFor 函数算法 效率比较 tabl ...
随机推荐
- SwitUI初次体验
序言 开年的第一篇文章,今天分享的是SwiftUI,SwiftUI出来好几年,之前一直没学习,所以现在才开始:如果大家还留在 iOS 开发,这们语言也是一个趋势: 目前待业中.... 不得不说已逝的2 ...
- 【Azure 应用服务】查看App Service for Linux上部署PHP 7.4 和 8.0时,所使用的WEB服务器是什么?
问题描述 如何查看PHP应用部署到App Service后,Azure上面使用的应用服务器是什么呢?因为App Service支持两种操作系统,Windows 和 Linux.在Windows中,使用 ...
- 深入解析ASP.NET Core MVC应用的模块化设计[上篇]
ASP.NET Core MVC的"模块化"设计使我们可以构成应用的基本单元Controller定义在任意的模块(程序集)中,并在运行时动态加载和卸载.这种为"飞行中的飞 ...
- powershell配置自动补全
powershell配置自动补全 一.需求: 看到老师上课用mac命令行有自动补全功能,发现真的爽.但是自己的windows powershell不能使用自动补全功能.有了需求,就想找到能完成目前的任 ...
- 使用@RequestBody注解踩的坑
一.问题由来 最近在和前端调试一个自己写的接口时,频频出现问题,让我很是烦恼.因此写下这篇博文来记录开发中遇到的一些问题.第一个问题是 前端页面传递参数后,后台不能正常接收参数.我写好接口以后,通过s ...
- vue-helper 点击跳转插件 在 methods里面互相调用函数,会产生两个函数definitions ,然后就回弹出框让你选择,解决方案是加配置
vue-helper 点击跳转插件 在 methods里面互相调用函数,会产生两个函数definitions ,然后就回弹出框让你选择 原因:换了台电脑,又从新配置下vscode "edit ...
- STM32进入HardFault_Handler的调试方法
在编写STM32程序代码时由于自己的粗心会发现有时候程序跑着跑着就进入了 HardFault_Handler中断,按照经验来说进入HardFault_Handler故障的原因主要有两个方面: 1:内存 ...
- 【线段树】【leetcode 729. 我的日程安排表 I】
class MyCalendar { class Seg { int l; int r; boolean val; Seg left; Seg right; public Seg(int x, int ...
- 专访OV季军|毕业转为freelancer,他如何斩获大量CG奖项?
"新锐先锋,玩转未来"--首届实时渲染3D动画创作大赛由瑞云科技主办,英伟达.青椒云.3DCAT实时渲染云协办,戴尔科技集团.Reallusion.英迈.万生华态.D5渲染器.中视 ...
- 【Leetcode】768. 最多能完成排序的块 II
题目(链接) arr是一个可能包含重复元素的整数数组,我们将这个数组分割成几个"块",并将这些块分别进行排序.之后再连接起来,使得连接的结果和按升序排序后的原数组相同. 我们最多能 ...