论文解读(CBL)《CNN-Based Broad Learning for Cross-Domain Emotion Classification》
Note:[ wechat:Y466551 | 付费咨询,非诚勿扰 ]
论文信息
论文标题:CNN-Based Broad Learning for Cross-Domain Emotion Classification
论文作者:Rong Zeng, Hongzhan Liu , Sancheng Peng , Lihong Cao, Aimin Yang, Chengqing Zong,Guodong Zhou
论文来源:2023 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
出发点:许多研究者关注的是传统的跨域情感分类,即粗粒度情绪分类。然而,跨领域的情绪分类问题却很少被涉及到。
摘要:在本文中,提出了一种基于卷积神经网络(CNN)的广泛学习方法,通过结合 CNN 和广泛学习的强度来进行跨域情感分类。首先利用 CNN 同时提取领域不变和领域特定特征,通过广泛学习来训练两个更有效的分类器。然后,为了利用这两个分类器,设计了一个共同训练模型来为它们进行提升。
贡献:
- 提出了一种结合深度学习和广泛学习的模型,即基于卷积神经网络(CNN)的广泛学习(CBL);
- 开发了四个真实世界的数据集,涉及四个不同领域;
- 结果表明,该方法比基线方法能更有效地提高情绪分类的性能;
2 方法
模型框架:
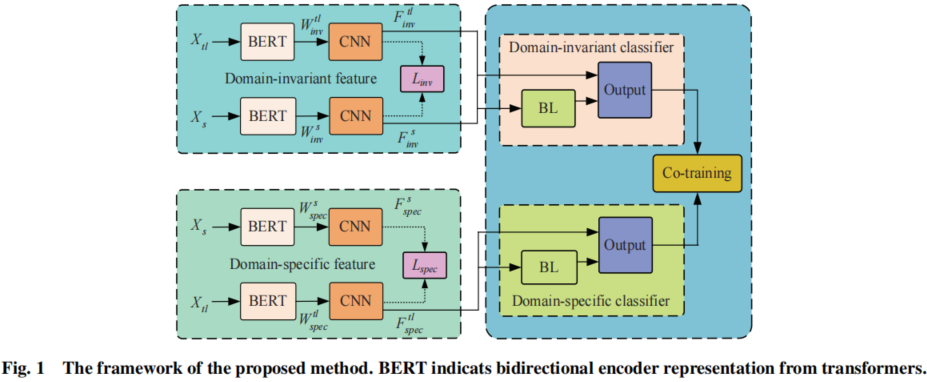
2.1 Maximum mean discrepancy
MMD 公式:
$\operatorname{MMD}\left(X_{s}, X_{t}\right)=\left\|\frac{1}{N_{s}} \sum_{i=1}^{N_{s}} \phi\left(x_{s}^{i}\right)-\frac{1}{N_{t}} \sum_{i=1}^{N_{t}} \phi\left(x_{t}^{i}\right)\right\|_{\mathcal{H}}^{2} \quad\quad(1)$
2.2 Feature extraction
首先使用 BERT 来生成 $X_s$ 和 $X_{tl}$ 的词向量,其描述如下:
$\begin{array}{l}\boldsymbol{W}_{i n v}^{s}=\operatorname{BERT}_{i n v}\left(X_{s} ; \theta_{i n v}^{\mathrm{BERT}}\right) \in \mathbf{R}^{\left(N_{s} l\right) \times 768} \\\boldsymbol{W}_{i n v}^{t l}=\operatorname{BERT}_{i n v}\left(X_{t l} ; \theta_{i n v}^{\mathrm{BERT}}\right) \in \mathbf{R}^{\left(N_{t l} l\right) \times 768} \\\boldsymbol{W}_{s p e c}^{s}=\operatorname{BERT}_{s p e c}\left(X_{s} ; \theta_{\text {spec }}^{\mathrm{BERT}}\right) \in \mathbf{R}^{\left(N_{s} l\right) \times 768} \\\boldsymbol{W}_{s p e c}^{t l}=\operatorname{BERT}_{s p e c}\left(X_{t l} ; \boldsymbol{\theta}_{\text {spec }}^{\mathrm{BERT}}\right) \in \mathbf{R}^{\left(N_{t l} l\right) \times 768}\end{array} \quad\quad(2)$
基于此,使用 CNN 和 最大池化 ,提取 n-gram feature 和 salient feature,可以描述如下:
$\begin{array}{l}\boldsymbol{F}_{i n v}^{s}=\mathrm{CNN}_{i n v}\left(\boldsymbol{W}_{i n v}^{s} ; \theta_{i n v}^{\mathrm{CNN}}\right) \in \mathbf{R}^{N_{s} \times q} \\\boldsymbol{F}_{i n v}^{t l}=\mathrm{CNN}_{i n v}\left(\boldsymbol{W}_{i n v}^{t l} ; \theta_{i n v}^{\mathrm{CNN}}\right) \in \mathbf{R}^{N_{t l} \times q} \\\boldsymbol{F}_{s p e c}^{s}=\mathrm{CNN}_{s p e c}\left(\boldsymbol{W}_{s p e c}^{s} ; \boldsymbol{\theta}_{\text {spec }}^{\mathrm{CNN}}\right) \in \mathbf{R}^{N_{s} \times q} \\\boldsymbol{F}_{\text {spec }}^{t l}=\mathrm{CNN}_{\text {spec }}\left(\boldsymbol{W}_{\text {spec }}^{t l} ; \boldsymbol{\theta}_{\text {spec }}^{\mathrm{CNN}}\right) \in \mathbf{R}^{N_{t l} \times q}\end{array} \quad\quad(3)$
对于 DIF,希望它能够编码源域和目标域共享的特性:
对于 DSF,希望它只从目标域中提取特征,这些特性通常应该出现在目标域中,而很少出现在源域中:
$L_{d i f f}=-\operatorname{MMD}\left(\boldsymbol{F}_{\text {spec }}^{s}, \boldsymbol{F}_{\text {spec }}^{t l}\right) \quad\quad(5)$
2.3 BL-Based classifier
为增强节点语义特征,设计了基于 DIF 的域不变分类器(DIC)和基于 DSF 的域特定分类器(DSC)两种分类器。
对于 DIC,第 $i$ 组增强节点可以表示如下:
$\begin{array}{l}\boldsymbol{E}_{i n v}^{i} & =\varphi\left(\theta_{i n v}^{i}\left[\boldsymbol{F}_{i n v}^{s}, \boldsymbol{F}_{i n v}^{t l}\right]+\boldsymbol{\beta}_{i n v}^{i}\right) \\i & =1,2, \ldots, n_{i n v}\end{array} \quad\quad(6)$
增强的节点特征:$\boldsymbol{E}_{i n v} \triangleq\left[\boldsymbol{E}_{i n v}^{1}, \boldsymbol{E}_{i n v}^{2}, \ldots, \boldsymbol{E}_{i n v}^{n_{i n v}}\right]$ 。
因此,DIC 的输出可以表示如下:
$\hat{\boldsymbol{Y}}_{i n v}=\left[\boldsymbol{F}_{i n v}^{s}, \boldsymbol{F}_{i n v}^{t l}, \boldsymbol{E}_{i n v}\right] \boldsymbol{\theta}_{i n v}^{\mathrm{BL}}=\boldsymbol{A}_{i n v} \theta_{i n v}^{\mathrm{BL}} \quad\quad(7)$
由于 DSC 只需要对目标域数据进行分类,因此我们对 $\boldsymbol{F}_{\text {spec }}^{\text {tl }}$ 到增强节点的 $n_{\text {spec }}$ 组进行了非线性映射。因此,第 $j$ 组增强节点可以表示如下:
$\begin{array}{l}\boldsymbol{E}_{s p e c}^{j} & =\varphi\left(\boldsymbol{\theta}_{s p e c}^{j} \boldsymbol{F}_{s p e c}^{t l}+\boldsymbol{\beta}_{s p e c}^{j}\right) \\j & =1,2, \ldots, n_{s p e c}\end{array} \quad\quad(8)$
增强的节点特征:$\boldsymbol{E}_{\text {spec }} \triangleq\left[\boldsymbol{E}_{\text {spec }}^{1}, \boldsymbol{E}_{\text {spec }}^{2}, \ldots, \boldsymbol{E}_{\text {spec }}^{n_{\text {spec }}}\right]$
因此,DSC的输出可以表示如下:
$\hat{\boldsymbol{Y}}_{s p e c}=\left[\boldsymbol{F}_{s p e c}^{t l}, \boldsymbol{E}_{s p e c}\right] \boldsymbol{\theta}_{s p e c}^{\mathrm{BL}}=\boldsymbol{A}_{s p e c} \theta_{s p e c}^{\mathrm{BL}} \quad\quad(9)$
2.4 Co-training
$L_{i n v}=L_{s i m}\left(\theta_{i n v}^{\mathrm{BERT}}, \boldsymbol{\theta}_{i n v}^{\mathrm{CNN}}\right)+\alpha L_{c}\left(\boldsymbol{\theta}_{i n v}^{\mathrm{BERT}}, \theta_{i n v}^{\mathrm{CNN}}\right) \quad\quad(10)$
$\begin{aligned}L_{c}= & \frac{1}{N_{s}+N_{t l}} \sum_{i=1}^{N_{s}}-y_{s}^{i} \ln P\left(y_{s}^{i} \mid \boldsymbol{F}_{i n v}^{s i}\right)+ \frac{1}{N_{s}+N_{t l}} \sum_{j=1}^{N_{t l}}-y_{t l}^{j} \ln P\left(y_{t l}^{j} \mid \boldsymbol{F}_{i n v}^{t l j}\right)\end{aligned} \quad\quad(11)$
在到DSF时,训练的目的是尽量减少下面的损失:
$\underset{\boldsymbol{\theta}_{i n v}^{\mathrm{BL}}}{\operatorname{argmin}}\left(\left\|\boldsymbol{Y}_{i n v}-\hat{\boldsymbol{Y}}_{i n v}\right\|_{2}^{2}+\lambda_{1}\left\|\boldsymbol{\theta}_{i n v}^{\mathrm{BL}}\right\|_{2}^{2}\right) \quad\quad(14)$
$\underset{\boldsymbol{\theta}_{\text {spec }}^{\mathrm{BL}}}{\operatorname{argmin}}\left(\left\|\boldsymbol{Y}_{\text {spec }}-\hat{\boldsymbol{Y}}_{\text {spec }}\right\|_{2}^{2}+\lambda_{2}\left\|\boldsymbol{\theta}_{\text {spec }}^{\mathrm{BL}}\right\|_{2}^{2}\right) \quad\quad(15)$
$\boldsymbol{Y}_{\text {spec }}$ 表示已标记的目标数据的地面真实标签。
因此,采用岭回归作为目标函数,得到最优解 $\theta_{i n v}^{\mathrm{BL}}$,表示如下:
$\boldsymbol{\theta}_{i n v}^{\mathrm{BL}}=\left(\lambda_{1} \boldsymbol{I}+\boldsymbol{A}_{i n v} \boldsymbol{A}_{i n v}^{\mathrm{T}}\right)^{-1} \boldsymbol{A}_{i n v}^{\mathrm{T}} \boldsymbol{Y}_{i n v} \quad\quad(16)$
其中,$I$ 表示单位矩阵。
同样,得到最优解 $\theta_{\text {spec }}^{\mathrm{BL}}$ 规范,表示如下:
$\theta_{\text {spec }}^{\mathrm{BL}}=\left(\lambda_{2} \boldsymbol{I}+\boldsymbol{A}_{\text {spec }} \boldsymbol{A}_{\text {spec }}^{\mathrm{T}}\right)^{-1} \boldsymbol{A}_{\text {spec }}^{\mathrm{T}} \boldsymbol{Y}_{\text {spec }} \quad\quad(17)$
2.5 完整算法

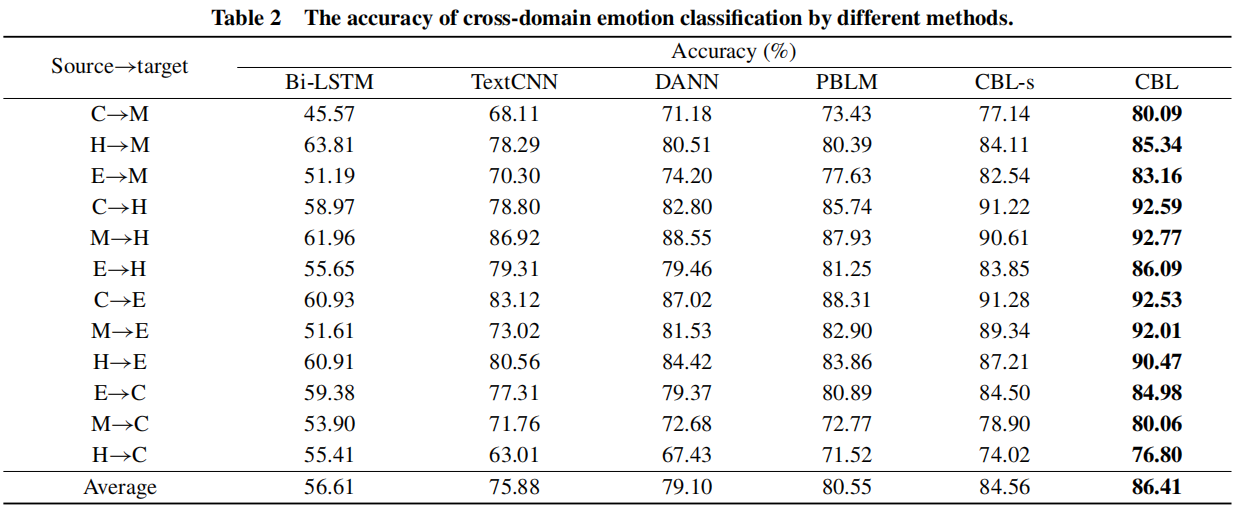
3 实验结果
数据集

情感分类
论文解读(CBL)《CNN-Based Broad Learning for Cross-Domain Emotion Classification》的更多相关文章
- CVPR2020论文解读:CNN合成的图片鉴别
CVPR2020论文解读:CNN合成的图片鉴别 <CNN-generated images are surprisingly easy to spot... for now> 论文链接:h ...
- 论文解读(LG2AR)《Learning Graph Augmentations to Learn Graph Representations》
论文信息 论文标题:Learning Graph Augmentations to Learn Graph Representations论文作者:Kaveh Hassani, Amir Hosein ...
- 论文解读(ARVGA)《Learning Graph Embedding with Adversarial Training Methods》
论文信息 论文标题:Learning Graph Embedding with Adversarial Training Methods论文作者:Shirui Pan, Ruiqi Hu, Sai-f ...
- 论文解读(GLA)《Label-invariant Augmentation for Semi-Supervised Graph Classification》
论文信息 论文标题:Label-invariant Augmentation for Semi-Supervised Graph Classification论文作者:Han Yue, Chunhui ...
- 《Stereo R-CNN based 3D Object Detection for Autonomous Driving》论文解读
论文链接:https://arxiv.org/pdf/1902.09738v2.pdf 这两个月忙着做实验 博客都有些荒废了,写篇用于3D检测的论文解读吧,有理解错误的地方,烦请有心人指正). 博客原 ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(下)
自监督学习(Self-Supervised Learning)多篇论文解读(下) 之前的研究思路主要是设计各种各样的pretext任务,比如patch相对位置预测.旋转预测.灰度图片上色.视频帧排序等 ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(上)
自监督学习(Self-Supervised Learning)多篇论文解读(上) 前言 Supervised deep learning由于需要大量标注信息,同时之前大量的研究已经解决了许多问题.所以 ...
- A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation 论文解读(SIGMOD 2021)
A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation 论文解读(SIGMOD 2 ...
- 论文解读(MGAE)《MGAE: Masked Autoencoders for Self-Supervised Learning on Graphs》
论文信息 论文标题:MGAE: Masked Autoencoders for Self-Supervised Learning on Graphs论文作者:Qiaoyu Tan, Ninghao L ...
- 论文解读(USIB)《Towards Explanation for Unsupervised Graph-Level Representation Learning》
论文信息 论文标题:Towards Explanation for Unsupervised Graph-Level Representation Learning论文作者:Qinghua Zheng ...
随机推荐
- 2022-09-02:以下go语言代码输出什么?A:9;B:11;C:编译错误;D:不确定。
2022-09-02:以下go语言代码输出什么?A:9:B:11:C:编译错误:D:不确定. package main import ( "fmt" ) func main() { ...
- 2021-06-19:交错字符串。 有三个字符串s1,s2,s3。判断s3是否由s1和s2交错组成的。比如s1=“abc“,s2=“123“,s3=“12ab3c“,应该返回true,因为s3去掉12
2021-06-19:交错字符串. 有三个字符串s1,s2,s3.判断s3是否由s1和s2交错组成的.比如s1="abc",s2="123",s3=" ...
- 2021-10-19:缺失的区间。给定一个排序的整数数组 nums ,其中元素的范围在 闭区间 [lower, upper] 当中,返回不包含在数组中的缺失区间。力扣163。
2021-10-19:缺失的区间.给定一个排序的整数数组 nums ,其中元素的范围在 闭区间 [lower, upper] 当中,返回不包含在数组中的缺失区间.力扣163. 福大大 答案2021-1 ...
- defer有什么用呢
1. 简介 本文将从一个资源回收问题引入,引出defer关键字,并对其进行基本介绍.接着,将详细介绍在资源回收.拦截和处理panic等相关场景下defer的使用. 进一步,介绍defer的执行顺序,以 ...
- Netty(1)——NIO基础
本篇主要介绍Java NIO的基本原理和主要组件 Netty是由JBOSS提供的Java开源网络应用程序框架,其底层是基于Java提供的NIO能力实现的.因此为了掌握Netty的底层原理,需要首先了解 ...
- Java(循环语句,数组)
Java循环 1.while while( 表达式 ) { //循环内容 } 2.do while do { //循环内容 }while(表达式); 3.for for(初始化; 表达式; 更新) { ...
- mysql_三大范式
介绍 数据库的三大范式就是数据库的表应该如何设计,应该注意什么. 第一范式 要求每一张表都有一个主键,每一个字段都不可再分. 举例: id username address 1 张三 中国,北京 2 ...
- Vue3基本功能实现
vue3 介绍 # Vue3的变化 # 1.性能的提升 打包大小减少41% 初次渲染快55%, 更新渲染快133% 内存减少54% # 2.源码的升级 使用Proxy代替defineProperty实 ...
- TLS详解(原理和实践)
主页 个人微信公众号:密码应用技术实战 个人博客园首页:https://www.cnblogs.com/informatics/ 引言 本文主要内容涉及到TLS协议发展历程.TLS协议原理以及在HTT ...
- 自然语言处理 Paddle NLP - 情感分析技术及应用-理论
自然语言处理 Paddle NLP - 信息抽取技术及应用 定义:对带有感情色彩的主观性文本进行 分析.处理.归纳和推理的过程 主观性文本分析:技术难点 背景知识 电视机的声音小(消极) 电冰箱的声音 ...