Coursera, Big Data 5, Graph Analytics for Big Data, Week 3
Graph Analytics 有哪些类型

node type (labels)

node schema: attributes 组成了schema.

同样的, Edge也有 Edge Type 和Edge Schema
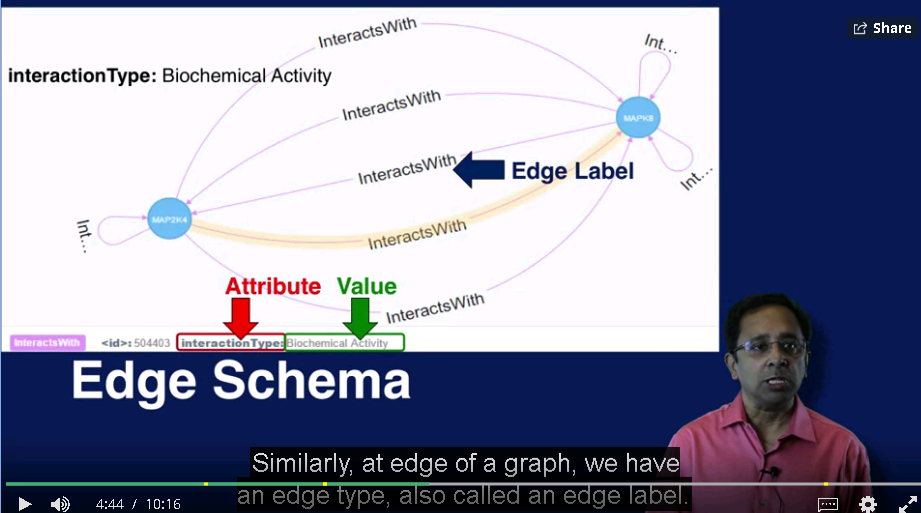
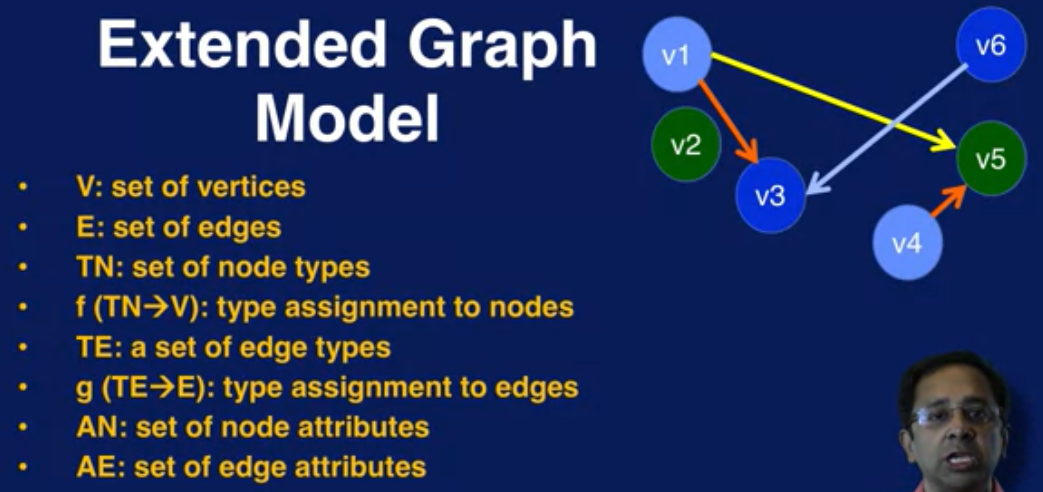
如果是一个完整的图,会包含以下信息
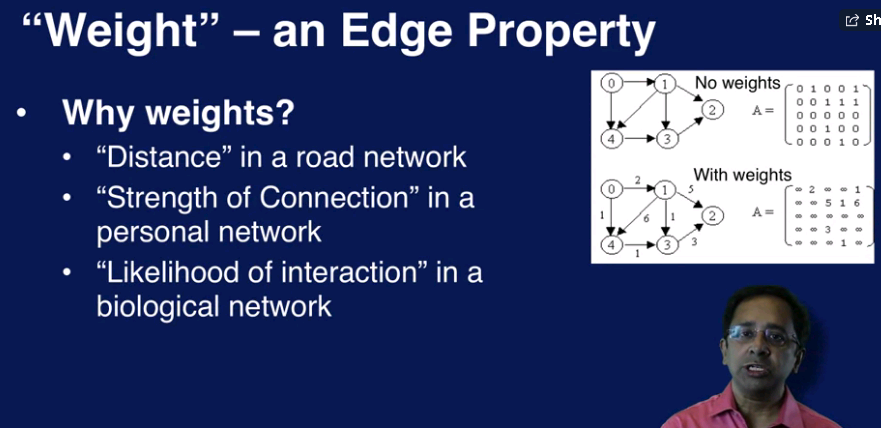
weight 权重,比如两点之间的 距离
1. Path Analytics
一些定义:
walk - 图上随便走的轨迹
path - 没有中间node重复的walk,比如 A-B-C-D-B-E 这个属于walk 不属于 path, path 是constrained 的walk
Cycle - 3个以上节点组成的环
Acyclic - 无环图, 比如最常见的说法 DAG- directed acyclic graph.
trail - 没有edge 重复的walk
dimeter of graph - 从任何一个node出发, 到任何另一个node, 走最短路径,最后得到的最大hops 就是 dimeter

最短路径问题
Dijkstra's Algorithm
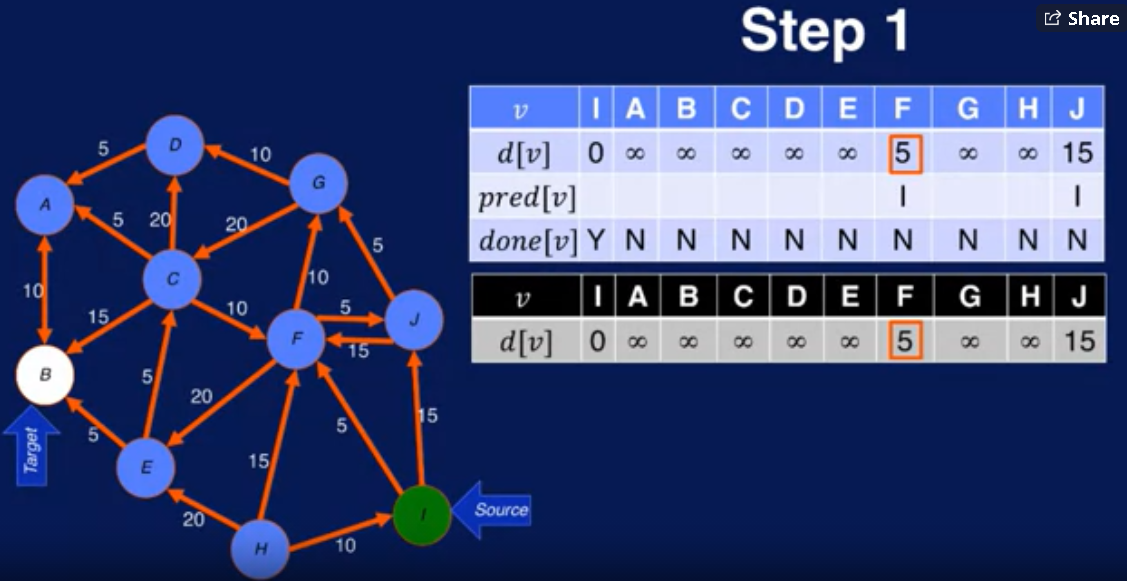
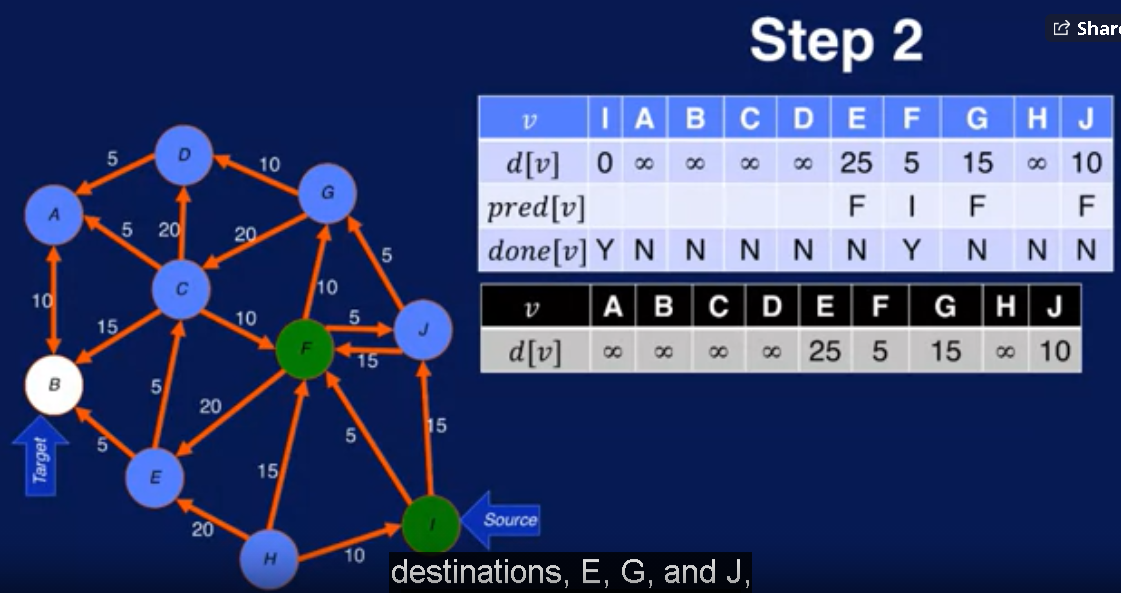
上面是简化版本的,现在考虑加上constrain

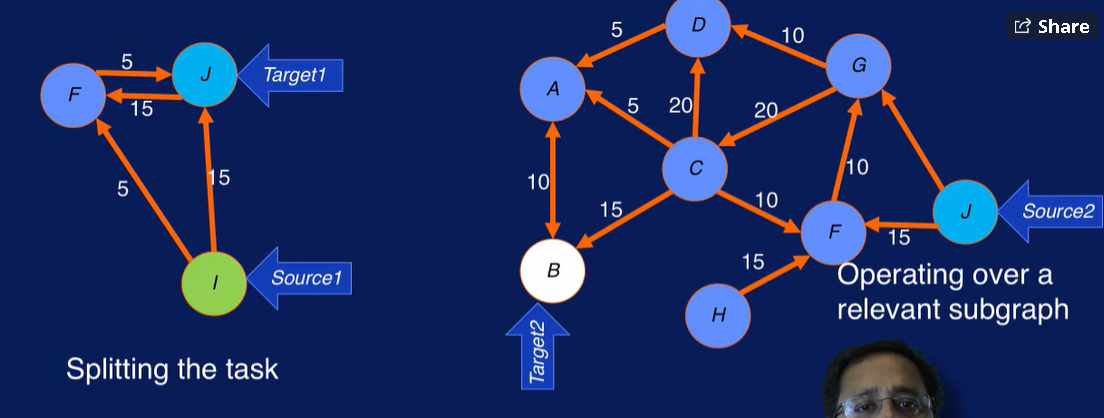
Dijkstra 算法在大数据情况下表现不好,计算量很大
2. Connectivity Analytics
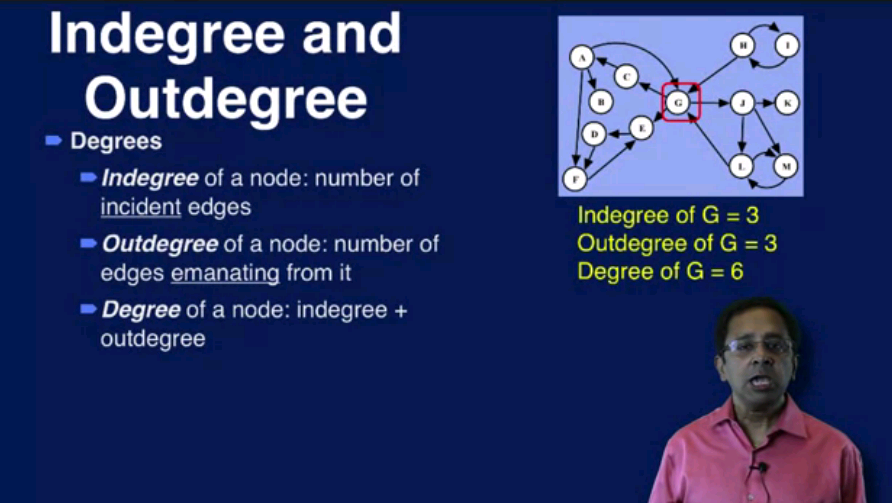
名词 degree 指这个Node有多少个连接的edge
主要关注图的 robust 和 相似性


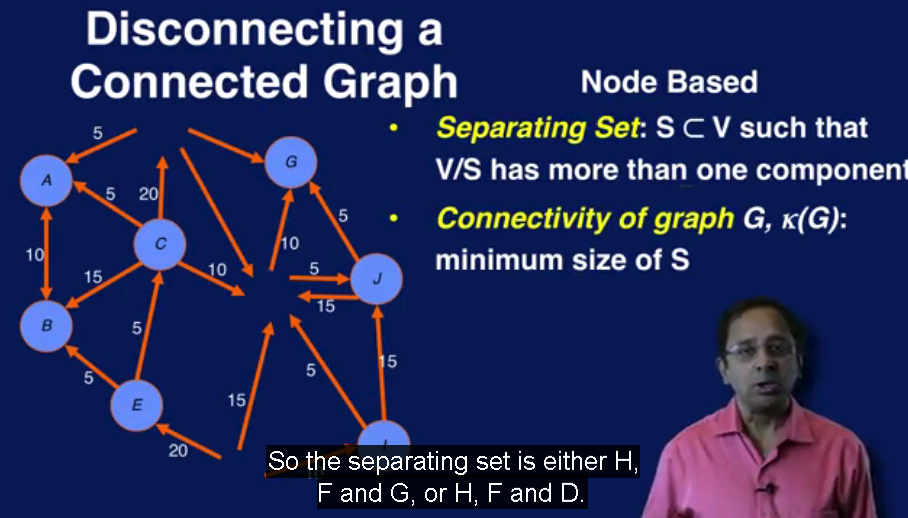
连接度 Connectivity
下图是基于node 的connectivity, 去掉三个node 就隔开了图,所有connectivity 等于 3
下图是基于edge 的connectivity, 去掉4个edge就隔开了图,所有说 edge connectivity = 4.

node degree: 就是有多少条edge连接到node上
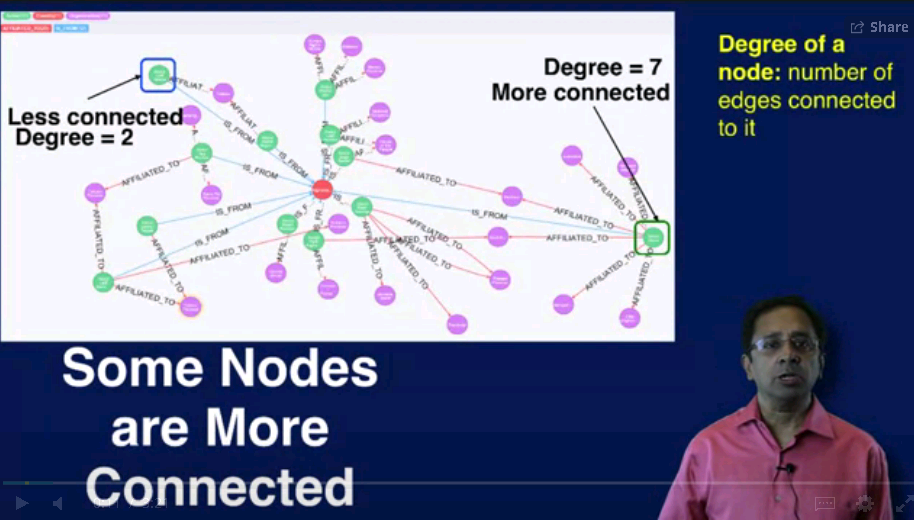
- Define a node's in-degree (# of incoming edges) and out-degree (# of outgoing edges)
- Describe a process for calculating the similarity of two graphs by finding the following for each graph and comparing them: find the degree of each node in a graph, then create a histogram of how many nodes have a certain degree.
- Define listener nodes (greater in-degree than out-degree), talker nodes (greater out-degree than in-degree) and communicator nodes (high in-degree and high out-degree).
node degree 进一步分成 indegree 和 outdegree
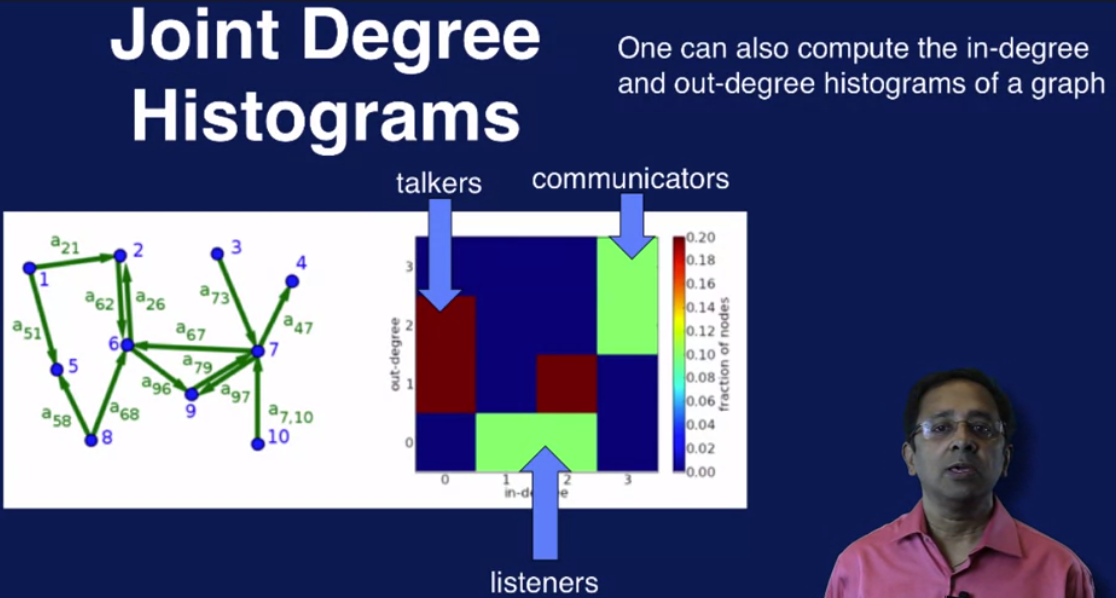
3. Community Analytics
- List the three types of analytics questions asked about communities (static, evolution, and predictions) and identify a real world example of a question in those categories.
- Calculate the internal degree and external degree of nodes in a community.
- Recognize that, for a community to really be a community, the relative number of total edges within that community (cluster) should be high relative to the total number of edges from nodes in the community to nodes outside it.



怎么从network里面找到 community呢?这里介绍了两种方法,一种是关注 Local property
Clique - 小集团的意思,每个node都和其他node有连接
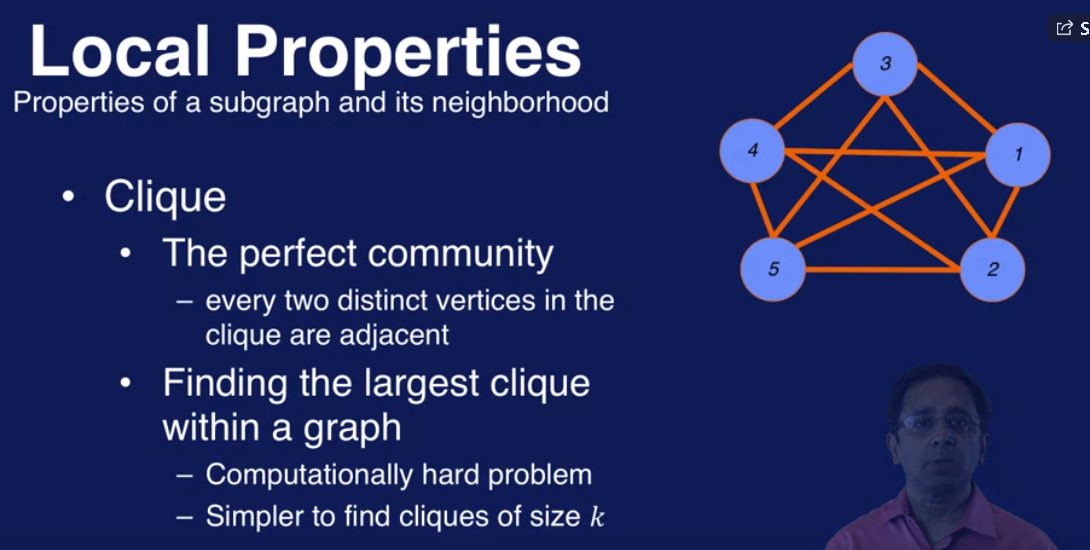
实际上,find 大于3或者4的clique比较难,所有我们要relax clique的定义,有两种relaxation, 一种基于distance, 一种基于density, 其中两种基于distance的定义是n-clique 和 n-clan, 基于density的是k-core.
下面是n-clique的说明,Mike 不属于绿色点形成的2-clique
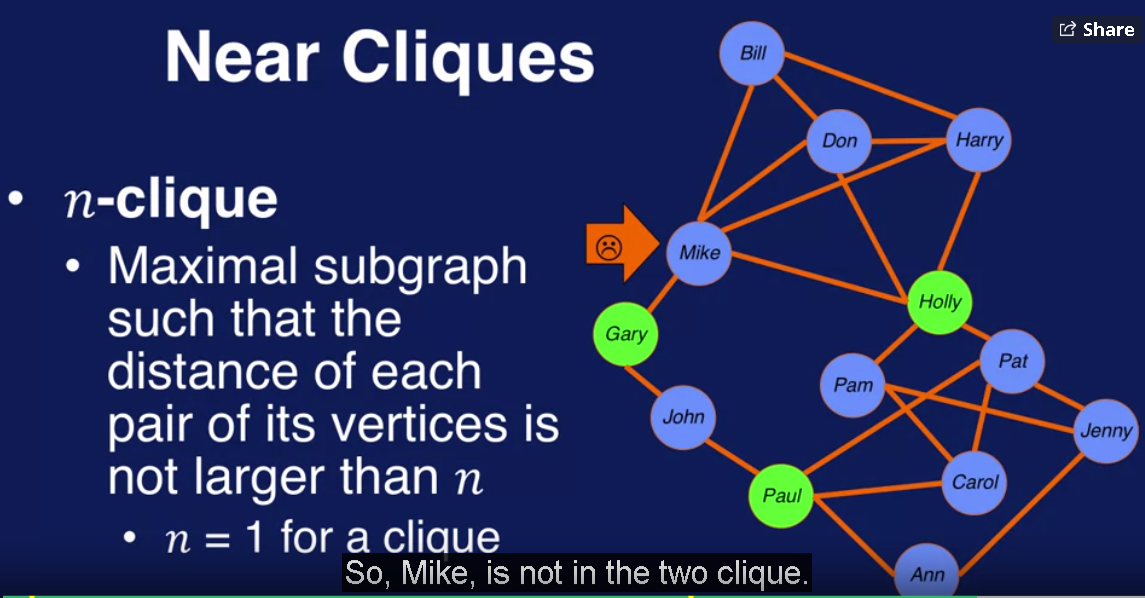
n-clan 纠正了这种情况

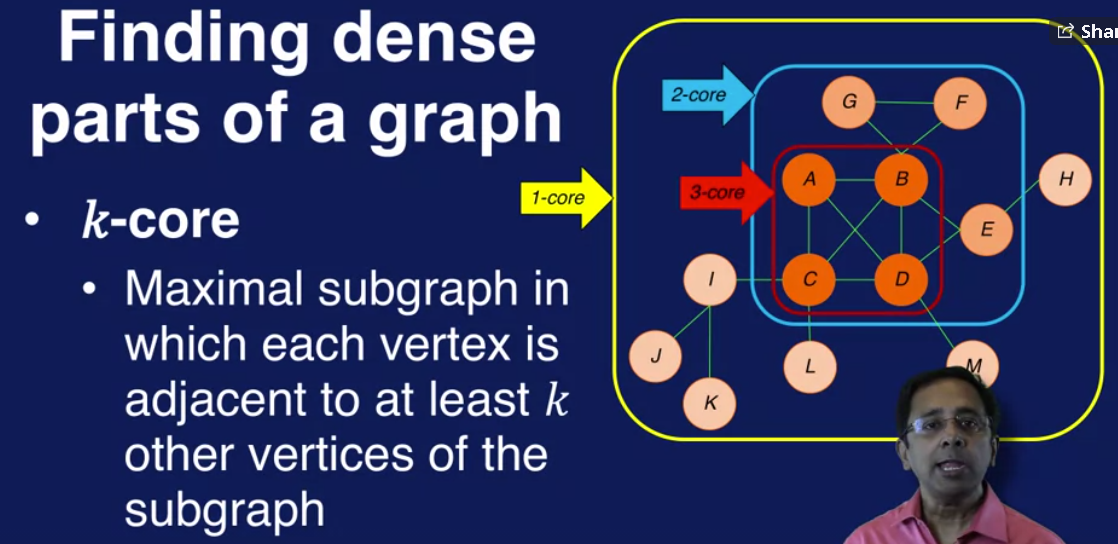
前面是讲基于 local property 的community 发现算法,接着将基于 grobal property 的community 发现算法
By the end of this video you will be able to...
- Describe modularity conceptually -- a graph is more modular if there are more edges in that community than would be likely if edges were randomly assigned.
- Given two graphs, identify visually which is more modular.
- Identify the 6 ways in which communities are often tracked over time.
- Identify which of the 6 changes would happen when two companies merge and when a company spins off a start-up.
grobal property 特别关注的property 是 modularity
然后讲到了基于modularity 的community 发现方法叫 Louvain method. 具体详情见 https://www.youtube.com/watch?v=dGa-TXpoPz8


相对于static graph, 经常见的还有 evolving graph. 有6种类型的evolving method.

4. Centrality Analytics
By the end of this video you will be able to...
- Define an influencer in a social network as a node (e.g. person) who can reach all other nodes quickly.
- Identify the 2 key (central) player problems: Which nodes when removed will maximally disrupt a network and which set of nodes can reach (almost) all other nodes in a network.
- Identify the 4 types of centrality discussed: degree, group, closeness, and betweenness.
- Identify which type of centrality you would want to identify in the following 2 cases: when you have information you want to inject quickly into a graph that follows shortest paths for dissemination and when you have a commodity that flows through a network.


两个概念 Centrality and Centralization
Centralization is for a network. As the number of nodes in a network with high centrality increases (orange nodes), then the centralization of a network decreases -- because there is less variation in the centrality values of the nodes in the network.

有超过30种的测量centrality 的方法




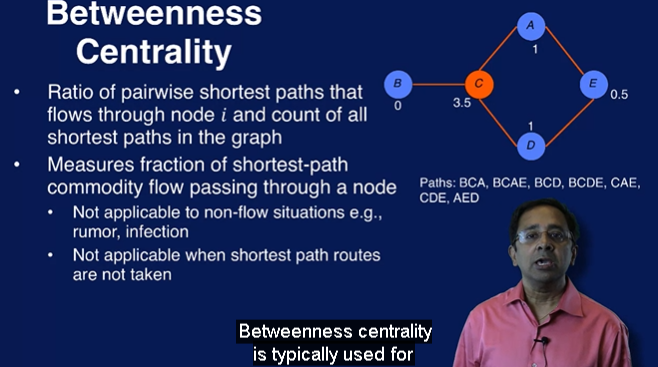
讲 connectivity 时候提到了power law 算法,不知道具体是什么
Ref
https://afteracademy.com/blog/dijkstras-algorithm Dijkstras 算法有图解,很清楚
Coursera, Big Data 5, Graph Analytics for Big Data, Week 3的更多相关文章
- 【Python学习笔记】Coursera课程《Using Python to Access Web Data》 密歇根大学 Charles Severance——Week6 JSON and the REST Architecture课堂笔记
Coursera课程<Using Python to Access Web Data> 密歇根大学 Week6 JSON and the REST Architecture 13.5 Ja ...
- 【Python学习笔记】Coursera课程《Using Python to Access Web Data 》 密歇根大学 Charles Severance——Week2 Regular Expressions课堂笔记
Coursera课程<Using Python to Access Web Data > 密歇根大学 Charles Severance Week2 Regular Expressions ...
- 论文解读(SimGRACE)《SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation》
论文信息 论文标题:SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation论文作者: ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)
Week 1 Machine Learning with Big Data KNime - GUI based Spark MLlib - inside Spark CRISP-DM Week 2, ...
- Intel® Threading Building Blocks (Intel® TBB) Developer Guide 中文 Parallelizing Data Flow and Dependence Graphs并行化data flow和依赖图
https://www.threadingbuildingblocks.org/docs/help/index.htm Parallelizing Data Flow and Dependency G ...
- SSIS Data Flow 的 Execution Tree 和 Data Pipeline
一,Execution Tree 执行树是数据流组件(转换和适配器)基于同步关系所建立的逻辑分组,每一个分组都是一个执行树的开始和结束,也可以将执行树理解为一个缓冲区的开始和结束,即缓冲区的整个生命周 ...
- Data Being Added Conflicts with Existing Data
While developing a page with multiple scrolls levels, and especially when using a grid, you may get ...
- Competing in a data science contest without reading the data
Competing in a data science contest without reading the data Machine learning competitions have beco ...
- data Mining with Weka: Trailer More Data Mining with Weka 用weka 进行数据挖掘 Weka 用weka 进行更多数据挖掘
https://www.youtube.com/user/WekaMOOC 大学公开课 视频教程 weka 入门教程 data Mining with Weka: Trailer More Dat ...
- Use Dynamic Data Masking to obfuscate your sensitive data
Data privacy is a major concern today for any organization that manages sensitive data or personally ...
随机推荐
- Vue 是如何实现数据双向绑定的?
Vue 数据双向绑定主要是指: 数据变化更新视图 视图变化更新数据. 即: 输入框内容变化时,Data 中的数据同步变化.即 View => Data 的变化. Data 中的数据变化时,文本节 ...
- css 选择器优先级?
!important > 行内样式(比重1000)> ID 选择器(比重100) > 类选择器(比重10) > 标签(比重1) > 通配符 > 继承 > 浏览 ...
- SpringBoot 整合EasyExcel 获取动态Excel列名
导读 最近负责消息网关,里面有个短信模板导入功能,因为不同模板编号对应不同参数,导入后的数据定时发送,涉及到Excel中列名不固定问题,于是想根据列名+值,组合成一个大JSON,具体代码如下. 引入依 ...
- Java Objects工具类重点方法使用
Objects工具类 jdk 1.7引进的工具类,都是静态调用的方法,jdk 1.8新增了部分方法 重点方法 equals 用于字符串和包装对象的比较,先比较内存地址,再比较值 deepEquals ...
- 实用!一键生成数据库文档的神器,支持MySQL/SqlServer/Oracle多种数据库
Screw(螺丝钉)是一款简洁好用的数据库表结构文档生成工具,它的特点是:简洁.轻量.设计良好.多数据库支持.多种格式文档.灵活扩展以及支持自定义模板,对于有经常要进行数据库设计.评审.文档整理等需求 ...
- Grafana Loki查询加速:如何在不添加资源的前提下提升查询速度
Grafana Loki查询加速:如何在不添加资源的前提下提升查询速度 来自Grafana Loki query acceleration: How we sped up queries withou ...
- DataGridView1列宽根据内容自适应
DataGridView1列宽根据内容自适应 在使用DataGridView控件时,要使列宽根据内容自适应,你可以使用DataGridView的AutoResizeColumns方法.这个方法允许你根 ...
- pyspark初步了解
spark的运行角色: 分布式代码的流程分析 pythononspark原理
- find命令在根目录查找文件
find命令在根目录查找文件 find命令口诀是: find 路 名 含 一,首先看看路径的表示方法 . 表示当前目录 .. 表示上一级目录 cd .. 表示返回上一级目录cd ../ ...
- 【Shiro】01 概述 & 快速上手
什么是Shiro? Apache Shiro 是Java的一个权限安全框架 一些功能:认证.授权.加密.会话管理.与Web 集成.缓存等 Shiro官网地址:[ 点击访问 ] http://shi ...