TextIn文档树引擎,助力RAG知识库问答检索召回能力提升
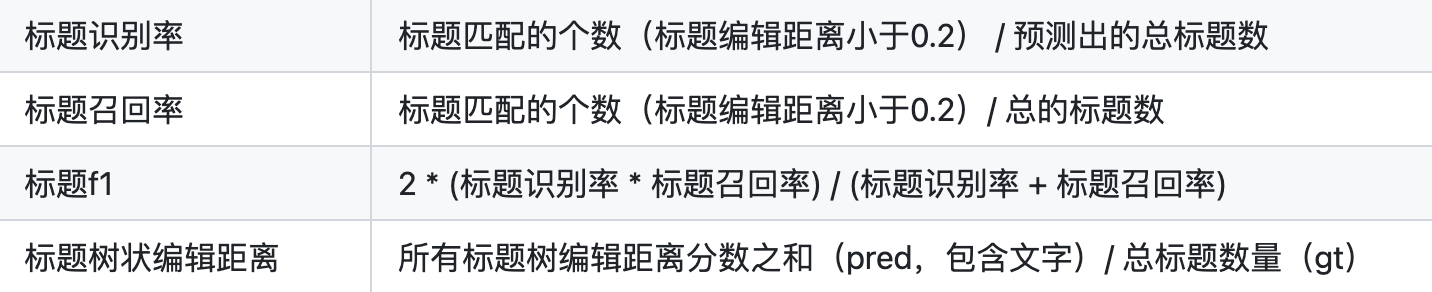
- 整份文档的段落内容,以序列化形式传入模型
- 提取当前段落的embedding值
- 预测每个段落和上一个段落的关系,分为子标题、子段落、合并、旁系、主标题、表格标题
- 如果是旁系类型,则再往上找父节点,并判断其层级关系,直到找到最终的父节点
- 基于每个段落的情况,构造该文档的文档树,并按 JSON 结构输出(右图中未渲染段落节点)
TextIn文档树引擎,助力RAG知识库问答检索召回能力提升的更多相关文章
- bs4--官文--搜索文档树
搜索文档树 Beautiful Soup定义了很多搜索方法,这里着重介绍2个: find() 和 find_all() .其它方法的参数和用法类似,请读者举一反三. 再以“爱丽丝”文档作为例子: ht ...
- bs4--官文--遍历文档树
遍历文档树 还拿”爱丽丝梦游仙境”的文档来做例子: html_doc = """ <html><head><title>The Dor ...
- bs4--官文--修改文档树
修改文档树 Beautiful Soup的强项是文档树的搜索,但同时也可以方便的修改文档树 修改tag的名称和属性 在 Attributes 的章节中已经介绍过这个功能,但是再看一遍也无妨. 重命名一 ...
- 使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解(新手必学)
为大家介绍下Python爬虫库BeautifulSoup遍历文档树并对标签进行操作的详细方法与函数下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最 ...
- Python爬虫系列(六):搜索文档树
今天早上,写的东西掉了.这个烂知乎,有bug,说了自动保存草稿,其实并没有保存.无语 今晚,我们将继续讨论如何分析html文档. 1.字符串 #直接找元素soup.find_all('b') 2.正则 ...
- 使用requests爬取梨视频、bilibili视频、汽车之家,bs4遍历文档树、搜索文档树,css选择器
今日内容概要 使用requests爬取梨视频 requests+bs4爬取汽车之家 bs4遍历文档树 bs4搜索文档树 css选择器 内容详细 1.使用requests爬取梨视频 # 模拟发送http ...
- MaltReport2:通用文档生成引擎
UPDATED: 本文仅适用 MaltReport 2.x ,3.x 版本文档还在撰写当中,目前请参考项目中的 Samples. MaltReport 是我几年前写的开源单据.报表引擎,最近进行了较大 ...
- Linux 基础命令、文档树 和 bash
最近发现了一个总结得更好的:bash cheatsheet 本文只是我对 linux 基础学习的一个总结,可能仅适用于复习用.算是我的 Linux 备忘录. 最基础 tab 补全 * 通配符 ctrl ...
- [整理] ES5 词法约定文档树状图
将ES5 词法说明整理为了树状图,方便查阅,请自行点开小图看大图:
- smarty3.0中文手册文档API及使用指南
1.安装Smarty3.0一.什么是smarty?smarty是一个使用PHP写出来的模板PHP模板引擎,它提供了逻辑与外在内容的分离,简单的讲,目的就是要使用PHP程序员同美工分离,使用的程序员改变 ...
随机推荐
- javascript深入参数传递
我们都知道javascript的基础数据类型有: Undefined . Null . Boolean . Number . String . 如果从一个变量向另一个变量复制基本类型的值,会在变量对象 ...
- 洛谷P1747
这个题被坑麻了,题目居然不给棋盘的范围,评论区居然有人说棋盘是无限大的,我想说的是如果真是这样那么第9个点答案应该是2而不是3,这个棋盘绝对是有大小的. #include<iostream> ...
- SQL去重distinct方法解析
来源:https://www.cnblogs.com/lixuefang69/p/10420186.html SQL去重distinct方法解析 一 distinct 含义:distinct用来查询不 ...
- 8行JS代码实现Vue穿梭框
实现效果 完整 demo 参考 <template> <div class="contain"> <ul class=""> ...
- [oeasy]python0072_整数类型_int_integer_整型变量
帮助手册 回忆上次内容 上次了解的是 字符串 字符串 就是 字符的串 字符串长度 可以用 len函数 字符可以用下标索引 [] 可以用str 将整型数字 转化为 字符串 字符的长度本身 有 ...
- Scratch源码下载 | 3D钻石
程序说明: <3D钻石>是一个利用Scratch平台创作的独特艺术作品.此程序在屏幕上呈现一个精致的3D钻石模型,允许用户通过鼠标操作来旋转和查看钻石的不同角度.该程序还提供了修改钻石参数 ...
- Netty的源码分析和业务场景
Netty 是一个高性能.异步事件驱动的网络应用框架,它基于 Java NIO 构建,广泛应用于互联网.大数据.游戏开发.通信行业等多个领域.以下是对 Netty 的源码分析.业务场景的详细介绍: 源 ...
- 【Spring】06 Aop切面功能
什么是Aop? Aspect Oriented Programming 面向切面编程 通过预编译的方式和运行期动态代理实现程序功能统一维护的一种技术 是OOP的延续,也是Spring第二个核心内容 可 ...
- 【Vue】Re05 操作数组的API
一.响应式处理的操作: <!DOCTYPE html> <html lang="en"> <head> <meta charset=&qu ...
- 全网最适合入门的面向对象编程教程:31 Python的内置数据类型-对象Object和类型Type
全网最适合入门的面向对象编程教程:31 Python 的内置数据类型-对象 Object 和类型 Type 摘要: Python 中的对象和类型是一个非常重要的概念.在 Python 中,一切都是对象 ...