第 2章Python 爬虫基本库的使用
第 2章Python 爬虫基本库的使用
爬虫并没有你想象中的复杂,很多初学者一开始就担忧,比如怎么写代码去构造请求,怎么把请求发出去,怎么接收服务器的响应,需不需要学习 TCP/IP 四层模型的每一层的作用。其实,你不用担忧那么多,Python 已经为我们提供了一个功能齐全的类库——urllib,你只需要关心:要爬取哪些链接、要用到哪些请求头和参数。除此之外,还有一些功能更加强大的第三方类库等。
2.1 Chrome 抓包详解
抓包是抓取客户端与远程服务器通信时传递的数据包。Chrome 内置了一套功能强大的
Web 开发和调试工具,可用来对网站进行调试和分析,用来抓包非常方便。可以通过下面
的几种方式打开开发者工具。
(1)在 Chrome 界面按 F12 键。
(2)右键单击网页空白处,单击检查。
(3)依次单击如图所示的项目。
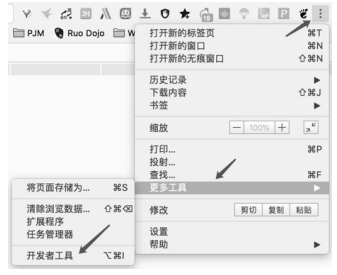
打开后的开发者工具界面
开发者工具界面中的内容依次如下。
- Elements(元素面板):当前网页的页面结构,在分析所要抓取的节点时会用到,而且可以实时修改页面内容,改成自己想要的结果。一个很常用的小技巧是把密码输入框 type 的属性由 password 改为 text,这样就可以查看明文密码了。
- Console(控制台面板):记录开发者开发过程中的日志信息,且可以作为与 JS 进行交互的命令行 Shell。
- Sources(源代码面板):可以断点调试JavaScript。
- Network(网络面板):记录从发起网页页面请求 Request 后得到的各种请求资源信息(包括状态、资源类型、大小、所用时间等),Web 开发者经常根据这些内容进行网络性能优化。
- Performance(性能面板):使用时间轴面板,可以记录或查看网站生命周期内发生的各种事件,网站开发者可以根据这些信息进行优化,以提高页面运行时的性能。
- Memory(内存面板):查看 Web 应用或页面的执行时间及内存使用情况。
- Application(应用面板):记录网站加载的所有资源信息,包括存储数据(Local ——Storage、Session Storage、IndexedDB、Web SQL、Cookies)、缓存数据、字体、
- 图片、脚本、样式表等。
- Security(安全面板):判断当前网页是否安全。
- Audits(审核面板):对当前网页进行网络利用情况、网页性能方面的诊断,并给出一些优化建议,比如列出所有没有用到的 CSS 文件。
进行抓包时,主要查看 Network 选项卡,Network 选项卡由如图所示的四部分窗格
组成。
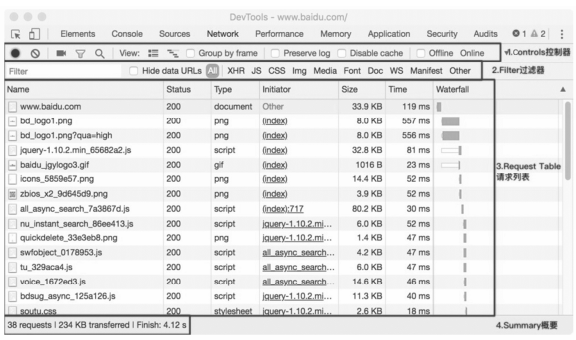
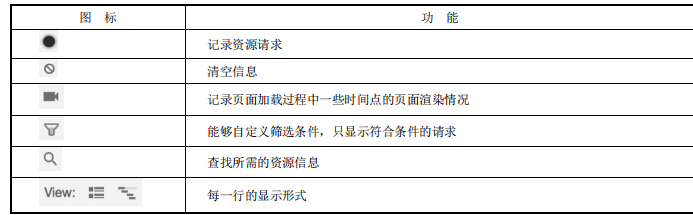
2.1.1 Controls
Controls 面板的部分图标与对应的功能

2.1.2 Filter
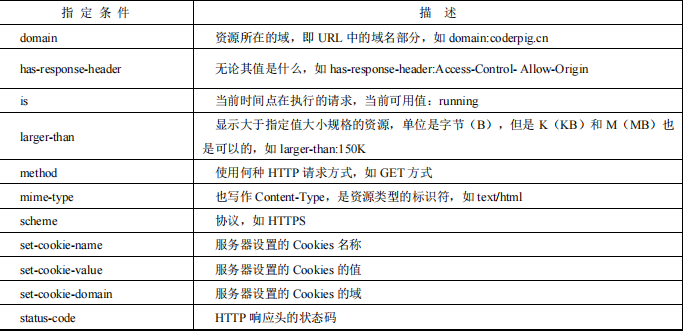
可以在 Filter 处输入指定条件,比如输入 method:GET,只显示使用 GET 请求方式的请
求。常用的指定条件。
按住 Ctrl 键单击过滤器,可以选择多个过滤器。
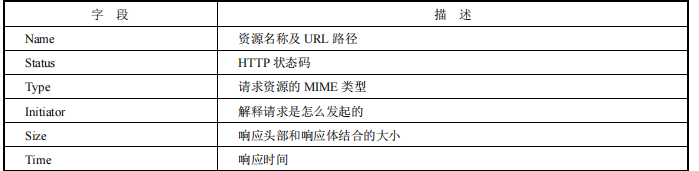
2.1.3 Request Table
请求列表对应字段描述
单击其中一个请求,进入请求的具体页面
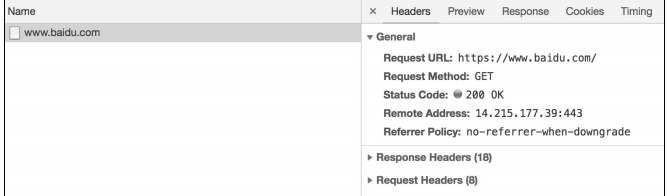
右侧顶部有如下五个选项卡
- Headers:选项卡中包含了请求的 URL、请求方法、响应码、请求头、响应头、请
- 求参数等。
- Preview:预览面板,用于资源的预览。
- Response:响应信息面板,包含资源还未进行格式处理的内容。
- Cookies:请求用到的 Cookies 内容。
- Timing:资源请求的详细时间。
编写爬虫的一般流程是查看 Headers 选项卡,查看请求需要用到的请求头、请求参数
等。然后查看 Response 返回的网页结构,查看要解析的节点,有时也可以直接查看 Elements
选项卡,但是对于 JavaScript 动态生成的网页,还是得查看 Response 选项卡返回的内容。
另外,在浏览器地址栏输入chrome://about/并回车可以看到 Chrome 浏览器中所有的地
址命令。

2.2 urllib 库详解
urllib 库是 Python 内置的一个 HTTP 请求库。在 Python 2.x 中,是由 urllib 和urllib2 两个库来实现请求发送的,在Python 3.x 中,这两个库已经合并到一起,统一为 urllib 了。urllib库由四个模块组成。
- request 模块:打开和浏览 URL 中的内容。
- error 模块:包含 urllib.request 发生的错误或异常。
- parse 模块:解析 URL。
- robotparser 模块:解析 robots.txt 文件。
官方文档:https://docs.python.org/3/library/urllib.html。
2.2.1 发送请求
我们写一个简单的模拟访问百度首页的例子,代码示例如下:
import urllib.request
resp = urllib.request.urlopen("http://www.baidu.com")
print(resp)
print(resp.read())
代码执行结果如下:
<http.client.HTTPResponse object at 0x106244e10>
b'<!DOCTYPE html>\n<!--STATUS OK-->\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n..
通过 urllib.request 模块提供的 urlopen()函数,我们构造一个 HTTP 请求,从上面的结果可知,urlopen()函数返回的是一个 HTTPResponse 对象,调用该对象的 read()函数可以获得请求返回的网页内容。read()返回的是一个二进制的字符串,明显是无法正常阅读的,要调用 decode('utf-8')将其解码为 utf-8 字符串。这里顺便把HTTPResponse 类常用的方法和属性打印出来,我们可以使用 dir()函数来查看某个对象的所有方法和属性。修改后的代码如下:
import urllib.request
resp = urllib.request.urlopen("http://www.baidu.com")
print("resp.geturl:", resp.geturl())
print("resp.msg:", resp.msg)
print("resp.status:", resp.status)
print("resp.version:", resp.version)
print("resp.reason:", resp.reason)
print("resp.debuglevel:", resp.debuglevel)
print("resp.getheaders:", resp.getheaders()[0:2])
print(resp.read().decode('utf-8'))
代码执行结果如下:
resp.geturl: http://www.baidu.com
resp.msg: OK
resp.status: 200
resp.version: 11
resp.reason: OK
resp.debuglevel: 0
resp.getheaders: [('Bdpagetype', '1'), ('Bdqid', '0xa561cc600003fc40')]
<!DOCTYPE html>
<!--STATUS OK-->
...
另外,有一点要注意,在 URL 中包含汉字是不符合 URL 标准的,需要进行编码,代
码示例如下:
urllib.request.quote('http://www.baidu.com')
# 编码后:http%3A//www.baidu.com
urllib.request.unquote('http%3A//www.baidu.com')
# 解码后:http://www.baidu.com
2.2.2 抓取二进制文件
直接把二进制文件写入文件即可,代码示例如下:
import urllib.request
pic_url = "https://www.baidu.com/img/bd_logo1.png"
pic_resp = urllib.request.urlopen(pic_url)
pic = pic_resp.read()
with open("bd_logo.png", "wb") as f:
f.write(pic)
代码执行结果如下:
...
urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate
verify failed: unable to get local issuer certificate (_ssl.c:1045)>
结果并没有像我们预期那样把图片下载下来,而是发生了报错,原因是当 urlopen()打
开一个 HTTPS 链接时,会验证一次 SSL 证书,当目标网站使用的是自签名的证书时,就会报这样的错误。解决这个错误有以下两种方法。
import ssl
# 方法一:全局取消证书验证
ssl._create_default_https_context = ssl._create_unverified_context
# 方法二:使用ssl创建未经验证的上下文,在urlopen()中传入上下文参数
context = ssl._create_unverified_context()
pic_resp = urllib.request.urlopen(pic_url,context=context)
选择其中一种方法加入代码中,代码执行后就可以看到百度的图标被下载到本地了。另外,还可以调用urllib.request.urlretrieve()函数直接进行下载,代码示例如下:
urllib.request.urlretrieve(pic_url, 'bd_logo.png')
2.2.3 模拟 GET 和 POST 请求
这里用到一个解析 JSON 数据的模块——JSON 模块,它用于 Python 原始类型与 JSON类型的相互转换。如果解析文件,可以用 dump()和 load()方法函数,如果解析字符串,则用下述两个函数:
dumps():编码 [Python -> Json]
dict => object list, tuple => array str => string True => true
int, float, int- & float-derived Enums => number False => false None => null
loads():解码 [Json -> Python]
object => dict array => list string => str number (int) => int
number(real) => float true =>True false => False null => None
模拟 GET 请求的代码示例如下:
import urllib.request
import json
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
get_url = "http://gank.io/api/data/" + urllib.request.quote("福利") + "/1/1"
get_resp = urllib.request.urlopen(get_url)
get_result = json.loads(get_resp.read().decode('utf-8'))
# 后面的参数用于格式化JSON输出格式
get_result_format = json.dumps(get_result, indent=2,
sort_keys=True, ensure_ascii=False)
print(get_result_format)
代码执行结果如下:
{
"error": false,
"results": [
{
"_id": "5b6bad449d21226f45755582",
"createdAt": "2018-08-09T10:56:04.962Z",
"desc": "2018-08-09",
"publishedAt": "2018-08-09T00:00:00.0Z",
"source": "web",
"type": "福利",
"url": "https://ww1.sinaimg.cn/large/0065oQSqgy1fu39hosiwoj30j60qyq96.jpg",
"used": true,
"who": "lijinshanmx"
}
]
}
模拟 POST 请求的代码示例如下:
import urllib.request
import urllib.parse
import json
post_url = "http://xxx.xxx.login"
phone = "13555555555"
password = "111111"
values = {
'phone': phone,
'password': password
}
data = urllib.parse.urlencode(values).encode(encoding='utf-8')
req = urllib.request.Request(post_url, data)
resp = urllib.request.urlopen(req)
result = json.loads(resp.read()) # Byte结果转JSON
print(json.dumps(result, sort_keys=True,
indent=2, ensure_ascii=False)) # 格式化输出JSON
2.2.4 修改请求头
有一些站点为了避免有人使用爬虫恶意抓取信息,会进行一些简单的反爬虫操作,比如通过识别请求头里的 User-Agent 来检查访问来源是否为正常的访问途径,还可检查 Host请求头等,我们可以修改请求头来模拟正常的访问。Request 中有个 headers 参数,可通过如下两种方法进行设置:
(1)把请求头都塞到字典里,在实例化 Request 对象的时候传入;
(2)通过 Request 对象的 add_header()方法一个个添加。
代码示例如下:
import urllib.request
# 修改请求头信息
novel_url = "http://www.biqukan.com/1_1496/"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/63.0.3239.84 Safari/537.36',
'Referer': 'http://www.baidu.com',
'Connection': 'keep-alive'}
novel_req = urllib.request.Request(novel_url, headers=headers)
novel_resp = urllib.request.urlopen(novel_req)
print(novel_resp.read().decode('gbk'))
代码执行结果如下:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gbk" />
<title>龙王传说最新章节_龙王传说无弹窗_笔趣阁</title>
<meta name="keywords" content="龙王传说,龙王传说最新章节" />
...
2.2.5 设置连接超时
urlopen()函数中有一个可选参数 timeout,单位为秒,作用是如果请求超出了这个时间还没有得到响应,就会抛出异常。如果不设置,会使用全局默认时间,代码示例如下:
urllib.request.urlopen(novel_req, timeout=20)
2.2.6 延迟提交数据
通常情况下,服务器都会对请求的客户端 IP 进行记录。如果在一定时间内访问次数达到了一个阈值,服务器会认为该 IP 地址就是爬虫,会弹出验证码验证,或者直接对 IP 进行封禁。
为了避免 IP 被封,一个最简单的方法就是延迟每次发起请求的时间,直接用 time 模块的 sleep(秒)函数休眠即可。
2.2.7 设置代理
如果遇到限制 IP 访问频率的情况,我们可以用上面这种延时发起请求的方法,但是有一些站点是限制访问次数的。比如,一个 IP 只能在一个时间间隔内访问几次,超过限制次数后 IP 会被 Block。另外,采用休眠访问的效率极低,对这种情况更好的解决方案是使用码,通过轮换代理 IP 去访问目标网站。
关于如何获取代理 IP,后面会详细介绍,这里只介绍怎样设置代理 IP。代码示例如下:
import urllib.request
# 查询IP的网址
ip_query_url = "http://ip.chinaz.com/"
# 1.创建代理处理器,ProxyHandler参数是一个字典{类型:代理IP:端口}
proxy_support = urllib.request.ProxyHandler({'http': '219.141.153.43:80'})
# 2.定制,创建一个opener
opener = urllib.request.build_opener(proxy_support)
# 3.安装opener
urllib.request.install_opener(opener)
# 请求头
headers = {
'User-Agent': 'User-Agent:Mozilla/5.0 (X11; Linux x86_64)'
' AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/63.0.3239.84 Safari/537.36',
'Host': 'ip.chinaz.com'
}
req = urllib.request.Request(ip_query_url, headers=headers)
resp = urllib.request.urlopen(req, timeout=20)
html = resp.read().decode('utf-8')
print(html)
部分代码执行结果如下:
<p class="getlist pl10"><span>您来自:</span>219.141.153.43 <span class="pl10">所
在 区 域 : </span> 北 京 市 电 信 <a href="http://tool.chinaz.com/contact" target="_blank"
class="col-blue02 pl5">(纠错)</a></p>
2.2.8 Cookie
Cookie 是某些网站为了辨别用户身份、进行 session 跟踪而存储在用户本地终端上的数据(通常经过加密),比如有些页面你在登录前是无法访问的,登录成功会给你分配Cookie,然后带着 Cookie 去请求页面才能正常访问。
使用 http.cookiejar 这个模块可以获取 Cookie,实现模拟登录。该模块的主要对象(父类→子类)为CookieJar→FileCookieJar→MozillaCookieJar 与 LWPCookieJar,示例代码如下:
# ============ 获得Cookie ============
# 1.实例化CookieJar对象
cookie = cookiejar.CookieJar()
# 2.创建Cookie处理器
handler = urllib.request.HTTPCookieProcessor(cookie)
# 3.通过CookieHandler创建opener
opener = urllib.request.build_opener(handler)
# 4.打开网页
resp = opener.open("http://www.zhbit.com")
for i in cookie:
print("Name = %s" % i.name)
print("Name = %s" % i.value)
# ============ 保存Cookie到文件 ============
# 1.用于保存Cookie的文件
cookie_file = "cookie.txt"
# 2.创建MozillaCookieJar对象保存Cookie
cookie = cookiejar.MozillaCookieJar(cookie_file)
# 3.创建Cookie处理器
handler = urllib.request.HTTPCookieProcessor(cookie)
# 4.通过CookieHandler创建opener
opener = urllib.request.build_opener(handler)
# 5.打开网页
resp = opener.open("http://www.baidu.com")
# 6.保存Cookie到文件中,参数依次是:
# ignore_discard:即使Cookie将被丢弃也将它保存下来
# ignore_expires:如果在该文件中Cookie已存在,覆盖原文件写入
cookie.save(ignore_discard=True, ignore_expires=True)
# ============ 读取Cookie文件 ============
cookie_file = "cookie.txt"
# 1.创建MozillaCookieJar对象保存Cookie
cookie = cookiejar.MozillaCookieJar(cookie_file)
# 2.从文件中读取Cookie内容
cookie.load(cookie_file, ignore_expires=True, ignore_discard=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
resp = opener.open("http://www.baidu.com")
print(resp.read().decode('utf-8'))
部分代码执行后生成的 cookie.txt 文件内容如下:
# Netscape HTTP Cookie File
# http://curl.haxx.se/rfc/cookie_spec.html
# This is a generated file! Do not edit.
.baidu.com TRUE / FALSE 3681539028 BAIDUID F16617940595A8E3EF9BB50E63AC09
54:FG=1
.baidu.com TRUE / FALSE 3681539028 BIDUPSID F16617940595A8E3EF9BB50E63AC0
954
.baidu.com TRUE / FALSE H_PS_PSSID 1442_21106_22074
.baidu.com TRUE / FALSE 3681539028 PSTM 1534055381
www.baidu.com FALSE / FALSE BDSVRTM 0
www.baidu.com FALSE / FALSE BD_HOME 0
www.baidu.com FALSE / FALSE 2480135321 delPer 0
2.2.9 urllib.parse 模块
- 拆分 URL
urlparse 函数:将 URL 拆分成六大组件。
urlsplit 函数:和 urlparse 函数类似,只是不会单独拆分 params 部分。
使用代码示例如下:
import urllib.parse
urp = urllib.parse.urlparse('https://docs.python.org/3/search.html?q=parse&check_keywords=yes&area=default')
print('urlparse执行结果:', urp)
# 可以通过.的方式获取某个部分
print('urp.scheme:', urp.scheme)
print('urp.netloc:', urp.netloc)
urp = urllib.parse.urlsplit('https://docs.python.org/3/search.html?q=parse&check_keywords=yes&area=default')
print('urlsplit执行结果:', urp)
代码执行结果如下:
urlparse执行结果:ParseResult(scheme='https', netloc='docs.python.org', path='/3/search.
html', params='', query='q=parse&check_keywords=yes&area=default', fragment='')
urp.scheme:https
urp.netloc:docs.python.org
urlsplit执行结果: SplitResult(scheme='https', netloc='docs.python.org', path='/3/search.html',
query='q=parse&check_keywords=yes&area=default', fragment='')
- 拼接 URL
urlunparse 函数:接收一个可迭代的对象,长度为 7,以此构造一个 URL。
urlunsplit 函数:接收一个可迭代的对象,长度为 6,以此构造一个 URL。
urljoin 函数:比上面两种方法简单得多,只有两个参数(基础链接、新链接),该方法
会分析基础链接的 scheme、netloc 和 path 的内容,并对新链接缺失的部分进行补充。
使用代码示例如下:
import urllib.parse
url=urllib.parse.urlunparse(['https','docs.python.org','/3/search.html','q=parse&check_keywords= yes&area=default' , '', ''])
print('urlunparse函数拼接的URL:',url)
url=urllib.parse.urlunsplit(['https','docs.python.org','/3/search.html','q=parse&check_keywords=yes&area=default',''])
print('urlunsplit函数拼接的URL:',url)
url = urllib.parse.urljoin('https://docs.python.org','/3/search.html')
url = urllib.parse.urljoin(url,'?q=parse&check_keywords=yes&area=default')
print('urljoin函数拼接的URL:',url)
代码执行结果如下:
urlunparse函数拼接的URL:https://docs.python.org/3/search.html;q=parse&check_keywords=yes&area=default
urlunsplit函数拼接的URL:https://docs.python.org/3/search.html?q=parse&check_keywords=yes&area=default
urljoin函数拼接的URL:https://docs.python.org/3/search.html?q=parse&check_keywords=yes&area=default
- 将字典形式的数据序列化为查询字符串
rlencode 函数:将字典形式的数据转换为查询字符串,常用于构造 GET 请求。
代码示例如下:
from urllib import parse
params = {
'q': 'parse',
'check_keywords': 'yes',
'area': 'default'
}
url = 'https://docs.python.org/3/search.html?' + parse.urlencode(params)
print("拼接后的URL:", url)
代码执行结果如下:
拼接后的URL:https://docs.python.org/3/search.html?q=parse&check_keywords=yes&area=default
- 查询字符串反序列化
parse_qs 函数:把 GET 请求后跟着的查询字符串反序列化为字典。
parse_qsl 函数:把 GET 请求后跟着的查询字符串反序列化为列表。
使用代码示例如下:
from urllib import parse
params_str = 'q=parse&check_keywords=yes&area=default'
print("parse_qs 反序列化结果:", parse.parse_qs(params_str))
print("parse_qsl 反序列化结果:", parse.parse_qsl(params_str))
代码执行结果如下:
parse_qs 反序列化结果: {'q': ['parse'], 'check_keywords': ['yes'], 'area': ['default']}
parse_qsl 反序列化结果: [('q', 'parse'), ('check_keywords', 'yes'), ('area', 'default')]
- 中文 URL 编解码
quote 函数:将 URL 中的中文字符转换为 URL 编码。
unquote 函数:对 URL 进行解码。
2.2.10 urllib.error 异常处理模块
urllib.error 模块定义由 urllib.request引发的异常类,异常处理主要用到两个类——URLError 和 HTTPError。
URLError 类:urllib.error 异常类的父类,具有 reason 属性,返回错误原因。发生 URLError异常的原因一般有以下几种:
- 远程地址不存在(如 404 Not Found)。
- 触发了 HTTPError 异常(如 403 Forbidden)。
- 远程服务器不存在(如[Errno 11001] getaddrinfo failed)。
- 远程服务器连接不上(如[WinError 10060],由于连接方在一段时间后没有正确答
- 复或连接的主机没有反应,连接尝试失败)。
HTTPError 类:URLError 类的子类,专门处理 HTTP 和 HTTPS 请求错误。具有三个属性:code(请求返回的状态码)、headers(请求返回的响应头信息)和 reason(错误原因)。
HTTPError 类并不能处理父类支持的异常处理,建议对两种异常分开捕获,代码示例如下:
from urllib import request, error
try:
response = request.urlopen('xxx')
except error.HTTPError as e:
print('HTTPError 异常')
print('reason:'+ str(e.reason), 'code:'+str(e.code), 'headers:'+str(e.headers), sep='\n')
except error.URLError as e:
print('URLError 异常')
print('reason:'+ str(e.reason))
else:
print('Request Successfully')
除此之外,还有 socket.timeout 请求超时的异常。
2.2.11 urllib.robotparser 模块
Robots 协议,又称爬虫协议,网站可以通过该协议告知搜索引擎站点内的哪些网页可
以抓取,哪些不可以抓取。如果想使用这个协议,可以在网站的根目录下创建一个robots.txt文本文件。
当搜索爬虫访问某个站点时会先检查是否有这个文件,如果有的话,会根据文件中定义的爬取范围来爬取;如果没有找到的话,便会访问所有可以直接访问的页面。另外有一点要注意,Robots 协议只是一个道德规范,并不是强制命令或防火墙。
下面来看淘宝 robots.txt 的文件内容,该文件的链接为 http://www.taobao.com/robots.txt。
User-Agent: Baiduspider
Allow: /article
Allow: /oshtml
Allow: /ershou
Disallow: /product/
Disallow: /
User-Agent: Googlebot
Allow: /article
Allow: /oshtml
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Allow: /ershou
Disallow: /
User-Agent: Bingbot
Allow: /article
Allow: /oshtml
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Allow: /ershou
Disallow: /
User-Agent: 360Spider
Allow: /article
Allow: /oshtml
Allow: /ershou
Disallow: /
User-Agent: Yisouspider
Allow: /article
Allow: /oshtml
Allow: /ershou
Disallow: /
User-Agent: Sogouspider
Allow: /article
Allow: /oshtml
Allow: /product
Allow: /ershou
Disallow: /
User-Agent: Yahoo! Slurp
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Allow: /ershou
Disallow: /
User-Agent: *
Disallow: /
字段解释如下。
- User-Agent:搜索引擎 spider 的名字,各大搜索引擎爬虫都有固定的名字,如百度
- 的 spider 为 Baiduspider。如果该项的值设为*(通配符),则该协议对任何搜索引
- 擎机器人均有效。
- Disallow:禁止访问的路径,比如禁止百度爬虫访问以/product 开头的任何 URL。Allow:允许访问的路径。
可以用 Python 自带的 robotparser 模块测试爬虫是否有权限爬取这个网页,代码示例
如下:
from urllib import robotparser
rp = robotparser.RobotFileParser()
# 设置robots.txt文件的链接
rp.set_url('http://www.taobao.com/robots.txt')
# 读取robots.txt文件并进行分析
rp.read()
url = 'https://www.douban.com'
user_agent = 'Baiduspider'
op_info = rp.can_fetch(user_agent, url)
print("Elsespider 代理用户访问情况:",op_info)
bdp_info = rp.can_fetch(user_agent, url)
print("Baiduspider 代理用户访问情况:",bdp_info)
user_agent = 'Elsespider'
代码执行结果如下:
Elsespider 代理用户访问情况: False
Baiduspider 代理用户访问情况: False
2.3 用 lxml 库解析网页节点
通过 urllib 库可以模拟请求,得到网页的内容,但是在大多数情况下我们并不需要整个网页,而只需要网页中某部分的信息。可以利用解析库 lxml 迅速、灵活地处理 HTML或 XML,提取需要的信息。另外,该库支持 XPath 的解析方式,效率也非常高。lxml 库的官方文档为 https://lxml.de/tutorial.html。
2.3.1 安装库
库的安装非常简单,直接通过 pip 安装即可:
pip3 install lxml
安装完 lxml 后,可以使用 import lxml 查看是否报错,没有报错就说明安装成功。
2.3.2 XPath 语法速成
XPath(XML Path Language,XML 路径语言),用于在 XML 文档中查找信息。它既适用于 XML 文档的搜索,又适用于 HTML。其核心是按照规则,通过编写路径选择表达式来筛选节点。
下面简单介绍 XPath 的语法,如果想了解更多的规则,可访问http://www.w3school.com.cn/xpath/。
- 绝对路径和相对路径
绝对路径:用/表示从根节点开始选取。
相对路径:用//表示选择任意位置的节点,而不考虑它们的位置。另外,可以使用*(通配符)来表示未知的元素。除此之外,还有两个选取节点的标记(.和..),前者用于选取当前节点,后者用于选取当前节点的父节点。 - 选择分支定位
比如存在多个元素,想唯一定位,可以使用[]来选择分支,分支的下标从 1 开始,相关的规则如下。
/tr/td[1]:取第一个td
/tr/td[last()]:取最后一个td
/tr/td[last()-1]:取倒数第二个td
/tr/td[position()<3]:取第一个和第二个td
/tr/td[@class]:选取拥有class属性的td
/tr/td[@class='xxx']:选取拥有class属性为xxx的td
/tr/td[count>10]:选取 price 元素的值大于10的td
- 选择属性
还可以通过多个属性定位,比如可以这样写:
/tr/td[@class='xxx'][@value='yyy']或者/tr/td[@class='xxx' and @value='yyy']
- 常用函数
除了 last()、position(),还有以下常用函数。
contains(string1,string2):如果前后匹配则返回 True;否则返回 False。
text():获取元素的文本内容。
starts-with():从起始位置匹配字符串。
更多的函数可以访问 http://www.w3school.com.cn/xpath/xpath_functions.asp 自行查阅。 - 轴
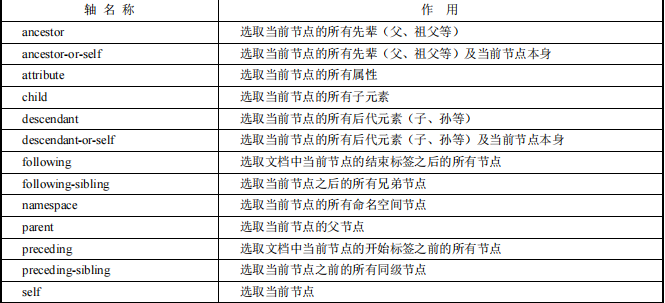
当上面的操作都不能定位时,可以考虑根据元素的父节点或兄弟节点来定位,这时就会用到 XPath 轴,利用轴可定位某个相对于当前节点的节点集,语法为轴名称::标签名,可选参数。
2.4 实战:爬取小说《剑来》
本节通过编写爬虫爬取小说《剑来》的实战案例来巩固 lxml 库的使用。小说的来源站点是(https://www.qianbitxt.com/)
F12 键打开开发者工具,单击右上角的 ,然后单击新书感言,找到节点所在的页面位置。
<'a'>标签里的 href 属性对应的是每章小说的地址,后面的内容是这章小说的名称。我
们要做的就是遍历这样的节点,提取链接并保存。编写的代码如下
import requests
from lxml import etree
def get_chapter_urls(url, headers):
response = requests.get(url, headers=headers)
if response.status_code != 200:
print("Failed to retrieve the chapter list.")
return []
html = etree.HTML(response.content)
hrefs = html.xpath('//*[@id="chapterList"]/li/a/@href')
base_url = 'https://www.qianbitxt.com'
# 确保URL是完整的
return [href if href.startswith('http') else base_url + href for href in hrefs[1:]]
def download_chapter(url, headers):
try:
response = requests.get(url, headers=headers)
response.encoding = 'gbk'
return response.text
except requests.RequestException as e:
print(f"Failed to download chapter: {e}")
return ""
def save_chapter(data, filename):
html = etree.HTML(data)
title = html.xpath('//*[@id="mlfy_main_text"]/h1/text()')
novel_txts = html.xpath('//*[@id="TextContent"]/text()')
with open(filename, 'a', encoding='utf-8') as f:
if title:
f.write(title[0] + '\n')
for novel_txt in novel_txts:
novel_txt = novel_txt.strip()
f.write(novel_txt + '\n')
f.write('\n\n')
def download_novel(novel_url, filename):
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
chapter_urls = get_chapter_urls(novel_url, headers)
if not chapter_urls:
print("No chapters found.")
return
for url in chapter_urls:
print(f"Downloading chapter from {url}")
data = download_chapter(url, headers)
if not data:
print(f"Failed to download data from {url}")
continue
save_chapter(data, filename)
print(f'小说内容已保存到{filename}文件中。')
if __name__ == "__main__":
novel_url = 'https://www.qianbitxt.com/book/2005'
filename = '剑来.txt'
download_novel(novel_url, filename)
get_chapter_urls函数:
- 功能:获取小说各章节的URL。
- 参数:url(小说目录页面的URL),headers(HTTP请求头)。
- 实现:
使用requests.get()发送GET请求到指定的URL。
检查响应状态码,如果不是200,则打印错误消息并返回空列表。
使用etree.HTML()解析响应内容。
通过XPath表达式获取章节的相对URL。
将相对URL转换为完整URL(如果需要)并返回。
download_chapter函数:
- 功能:下载单个章节的内容。
- 参数:url(章节的URL),headers(HTTP请求头)。
- 实现:
尝试发送GET请求到指定的URL。
设置响应的编码为'gbk'(针对中文网页)。
返回响应文本。
如果请求失败,打印错误信息并返回空字符串。
save_chapter函数:
- 功能:保存章节内容到本地文件。
- 参数:data(章节的HTML内容),filename(保存的文件名)。
- 实现:
解析HTML文档,获取章节标题和正文内容。
将标题和正文内容写入指定的文件中。
download_novel函数:
- 功能:下载整本小说。
- 参数:novel_url(小说目录页面的URL),filename(保存的文件名)。
- 实现:
设置HTTP请求头(模拟浏览器访问)。
获取所有章节的URL。
遍历每个章节URL,下载并保存章节内容。
main函数:
- 设置小说的目录页面URL和保存的文件名。
- 调用download_novel函数开始下载小说。
使用此类脚本下载网站内容时应遵守网站的使用条款,以及相关的法律法规。
本系列文章皆做为学习使用,勿商用。
第 2章Python 爬虫基本库的使用的更多相关文章
- python爬虫---selenium库的用法
python爬虫---selenium库的用法 selenium是一个自动化测试工具,支持Firefox,Chrome等众多浏览器 在爬虫中的应用主要是用来解决JS渲染的问题. 1.使用前需要安装这个 ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫Urllib库的基本使用
Python爬虫Urllib库的基本使用 深入理解urllib.urllib2及requests 请访问: http://www.mamicode.com/info-detail-1224080.h ...
- Python爬虫—requests库get和post方法使用
目录 Python爬虫-requests库get和post方法使用 1. 安装requests库 2.requests.get()方法使用 3.requests.post()方法使用-构造formda ...
- python爬虫 - Urllib库及cookie的使用
http://blog.csdn.net/pipisorry/article/details/47905781 lz提示一点,python3中urllib包括了py2中的urllib+urllib2. ...
- [python爬虫]Requests-BeautifulSoup-Re库方案--Requests库介绍
[根据北京理工大学嵩天老师“Python网络爬虫与信息提取”慕课课程编写 文章中部分图片来自老师PPT 慕课链接:https://www.icourse163.org/learn/BIT-10018 ...
- Python 爬虫 解析库的使用 --- XPath
一.使用XPath XPath ,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言.它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索. 所 ...
- python 爬虫第三方库
这个列表包含与网页抓取和数据处理的Python库 网络 通用 urllib -网络库(stdlib). requests -网络库. grab – 网络库(基于pycurl). pycurl – 网络 ...
- 第四章 python的turtle库的运用
我们可以尝试用python的自带turtle库绘制一条蟒蛇 首先我们设计一下蟒蛇的基本形状 我们先把这段蟒蛇绘制的实例代码贴出来,各位可以在自己的本地运行一下看看效果,然后我们再继续分析代码: 1 # ...
- Python爬虫学习==>第五章:爬虫常用库的安装
学习目的: 爬虫有请求库(request.selenium).解析库.存储库(MongoDB.Redis).工具库,此节学习安装常用库的安装 正式步骤 Step1:urllib和re库 这两个库在安装 ...
随机推荐
- 蓝牙BLE无线控制氛围灯解决方案之特色解析
谁的方案? 前几天和一个小伙伴讨论方案公司的价值,他给出定位还是比较准确地,作为一家方案公司,就是让产品公司,低成本,快速的推出具有市场竞争力的产品.凭借着本团队在无线蓝牙领域的深耕,这些年也做了 ...
- 一次对requirements环境的配置
事情是这样的,我需要跑通一个代码,因此要配置环境,但是并不能利用requirements中给的指令直接配置,于是开始找一些其他的解决方法.作为一名小白,总是绕很多弯路. 记下一些蜿蜒. 首先,摘录re ...
- 完美解决浏览器输入http被自动跳转至https问题
查阅相关资料,发现这是浏览器的HSTS(HTTP Strict Transport Security)功能引起的.在安装配置SSL证书时,可以使用一种能使数据传输更加安全的Web安全协议,即在服务器端 ...
- tomcat报错Exception loading sessions from persistent storage解决方案
现象:项目在重启时报错:严重: Exception loading sessions from persistent storage的问题.该问题的原因是tomcat的session持久化机制引起的, ...
- 记录--工程化第一步这个package.json要真的搞明白才行
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 工程化最开始就是package.json开始的,很多人学了很多年也没搞清楚这个为什么这么神奇,其实有些字段是在特定场景才有效的,那每个属性 ...
- 记录--Vue开发历程---音乐播放器
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 一.audio标签的使用 1.Audio 对象属性 2.对象方法 二.效果 效果如下: 三.代码 代码如下: MusicPlayer.vu ...
- Kubernetes客户端认证(三)—— Kubernetes使用CertificateSigningRequest方式签发客户端证书
1.概述 在<Kubernetes客户端认证(一)-- 基于CA证书的双向认证方式>和<Kubernetes客户端认证(二)-- 基于ServiceAccount的JWTToken认 ...
- KingbaseES 等待事件之 - Client ClientWrite
等待事件含义 Client:ClientWrite等待事件指数据库等待向客户端写入数据. 在正式业务系统中,客户端必然和数据库集群之间有数据交互,这里指的是数据接收,发送.数据库集群在向客户端发送更多 ...
- FR常用正则表达式
禁止输入中文字符 ^[^\u4e00-\u9fa5]{0,}$
- GeminiDB Cassandra接口新特性FLASHBACK发布:任意时间点秒级闪回
本文分享自华为云社区<GeminiDB Cassandra接口新特性FLASHBACK发布:任意时间点秒级闪回>,作者: GaussDB 数据库. 技术背景 数据库作为现代信息系统的核心组 ...