基于语义增强的少样本检测,突破新类别偏见 | ICIP'24
Few-shot目标检测(FSOD)旨在在有限标注实例的情况下检测新颖对象,在近年取得了显著进展。然而,现有方法仍然存在偏见表示问题,特别是在极低标注情况下的新颖类别。在微调过程中,一种新颖类别可能会利用来自相似基础类别的知识来构建自己的特征分布,导致分类混淆和性能下降。为了解决这些挑战,论文提出了一种基于微调的FSOD框架,利用语义嵌入来实现更好的检测。在提出的方法中,将视觉特征与类名嵌入对齐,并用语义相似性分类器替换线性分类器,训练每个区域提议收敛到相应的类别嵌入。此外,引入了多模态特征融合来增强视觉-语言通信,使新颖类别可以明确地从训练有素的相似基础类别中获得支持。为了避免类别混淆,提出了一种语义感知最大间隔损失,自适应地应用于超出相似类别的间隔。因此,论文的方法允许每个新颖类别构建一个紧凑的特征空间,而不会与相似基础类别混淆。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Semantic Enhanced Few-shot Object Detection

Introduction
深度神经网络在目标检测方面最近取得了巨大进展。然而,深度检测器需要大量标注数据才能有效识别一个对象。相比之下,人类只需要少量样本就能识别一类对象。常规检测器在少样本情境下容易出现过拟合问题,缩小常规检测与少样本检测之间的性能差距已成为计算机视觉领域的一个关键研究领域。
与少样本分类和常规目标检测相比,少样本目标检测(FSOD)是一项更具挑战性的任务。在给定具有足够数据量的基础类别和仅有少量带标签边界框的新颖类别的情况下,FSOD致力于学习基础类别上的基础知识,并在新颖类别上具有良好的泛化能力。早期的FSOD方法倾向于遵循元学习范式,学习与任务无关的知识,并快速适应新任务。然而,这些方法需要复杂的训练过程,并常常在实际环境中表现不佳。另一方面,基于微调的方法采用简单而有效的两阶段训练策略,并取得可比较的结果。
近年来,许多研究集中在基于微调的FSOD上,旨在将从丰富基础数据中学到的知识转移到新颖类别。TFA揭示了在微调期间简单冻结最后几层的潜力,为基于微调的方法奠定了基础。DeFRCN通过缩放和截断梯度来解耦分类和回归,并实现了卓越的性能。尽管它们取得了成功,仍然存在两个潜在问题:
- 先前基于微调的
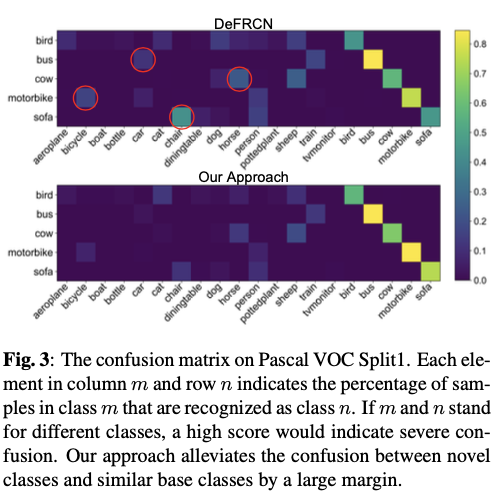
FSOD方法在训练样本极为有限时会出现性能下降,例如,当每个类别只有一个带标注的边界框时。只有一个对象无法很好地代表外观多样的类别是合理的,这种偏向性表示严重损害了新颖类别的性能。 FSOD的性能继续受到新颖类别和基础类别之间混淆的威胁。仅有少量带标注样本时,新颖类别几乎无法构建紧凑的特征空间。这可能造成新颖类可能散布在类似基础类别良好构建的特征空间中,导致分类混淆。
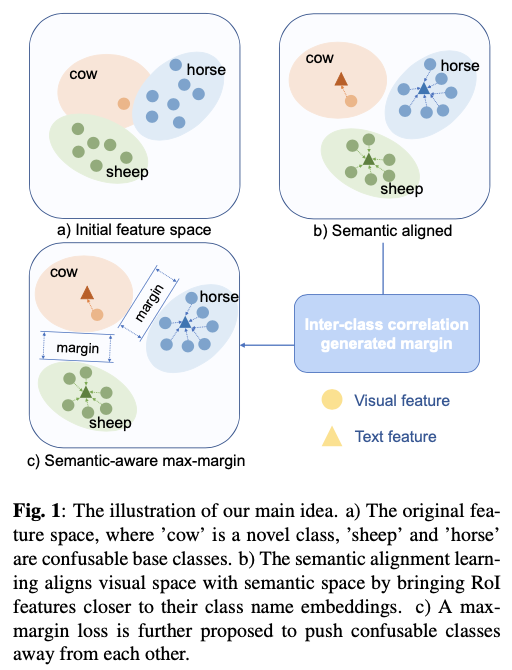
论文提出一个基于微调的框架,利用语义嵌入来提高对新颖类别的泛化能力。该框架在微调阶段用语义相似分类器(SSC)取代线性分类器,通过计算类名嵌入和提议物体区域特征之间的余弦相似度产生分类结果。此外,论文提出了多模态特征融合(MFF)来对视觉和文本特征进行深层融合。论文还在原始交叉熵损失之上应用了语义感知最大间隔(SAM)损失,以区分与自身相似的新颖类别和基础类别,如图1所示。在微调过程中,SSC和MFF通过经典的Faster R-CNN损失和SAM损失以端到端的方式进行优化。
论文的贡献可总结如下:
提出一个利用语义信息来解决少样本性能下降和类别混淆问题的框架。
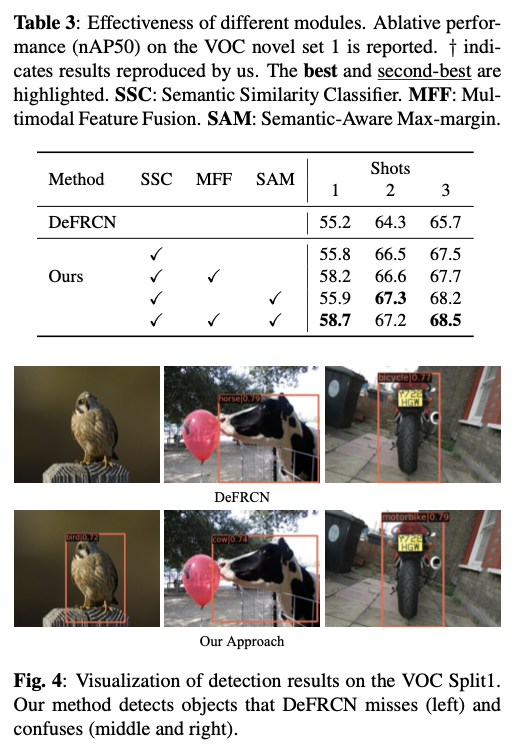
为了解决这些问题,设计了三个新模块,即
SSC、MFF和SAM损失。这些模块提供无偏表示,并增加类间分离。对
PASCAL VOC和MS COCO数据集进行了大量实验,证明方法的有效性。结果表明,论文的方法将最先进性能大幅提升。
Method
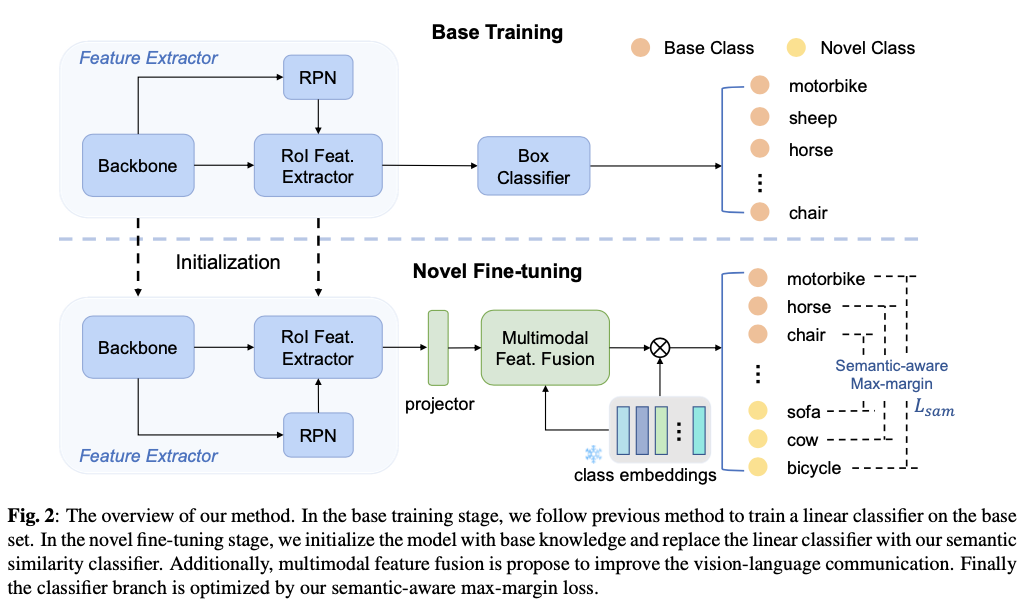
FSOD Preliminaries
论文遵循之前的工作中的Few-shot目标检测(FSOD)设置。将训练数据分为基础集合 \(\mathcal{D}_b\) 和新颖集合 \(\mathcal{D}_n\) ,其中基础类别 \(\mathcal{C}_b\) 具有丰富的标记数据,而每个新颖类别 \(\mathcal{C}_n\) 只有少量注释样本。基础类别和新颖类别之间没有重叠,即 \(\mathcal{C}_b \cap \mathcal{C}_n = \varnothing\) 。在迁移学习的背景下,训练阶段包括在 \(\mathcal{D}_b\) 上的基础训练和在 \(\mathcal{D}_n\) 上的新颖微调。目标是利用从大规模基础数据学习到的通用知识快速适应新颖类别,期望能够检测测试集中 \(\mathcal{C}_b \cup \mathcal{C}_n\) 类别中的对象。
论文的方法可以以即插即用的方式应用于任何基于微调的Few-shot检测器,并将论文的方法与之前的最先进方法DeFRCN进行集成以进行验证。与TFA不同的是,DeFRCN在第二阶段冻结大多数参数以防止过拟合,提出了Gradient Decoupled Layer来截断RPN的梯度并调整两个阶段中R-CNN的梯度。
Semantic Alignment Learning
论文旨在利用语义嵌入,为所有类别提供无偏的表示,以解决性能下降问题,特别是在极低样本情景下。
Semantic Similarity Classifier
论文的Few-shot检测器建立在流行的两阶段目标检测器Faster R-CNN之上。在Faster R-CNN中,提取区域建议,并将其传递给框分类器和框回归器以生成类别标签和准确的框坐标。以往基于微调的Few-shot目标检测方法简单地通过随机初始化来扩展分类器,以泛化到新颖类别。然而,仅给定一两个新颖对象的标记样本时,检测器很难为每个新颖类别构建无偏的特征分布,特别是当新颖样本不够具有代表性时。新颖类别的无偏特征分布将导致令人不满意的检测性能。
为了克服上述障碍,论文提出了一个语义相似度分类器,并使用固定的语义嵌入进行识别,而不是线性分类器。这是基于这样一个观察结果:类名嵌入与大量的视觉信息内在地对齐。当训练样本极为有限时,类名嵌入可作为良好的类中心。
首先通过一个投影器将区域特征与语义嵌入进行对齐,然后利用投影后的区域特征与类名嵌入之间的余弦相似度来生成分类得分 \(\mathbf{s}\) 。
\mathbf{s}=\text{softmax}(\text{D}(\mathbf{t}, \mathbf{Pv}))
\label{eq:projection}
\end{equation}
\]
其中, \(\mathbf{v}\) 是区域特征, \(\mathbf{P}\) 是投影器, \(\mathbf{t}\) 是类名嵌入, \(\text{D}\) 表示距离测量函数。
Multimodal Feature Fusion
语义相似度分类器学习将视觉空间中的概念与语义空间对齐,但仍然独立地处理每个类别,并且在除了最后一层之外,不进行模态之间的知识传播。这可能对充分利用类间相关性构成障碍。因此,论文进一步引入多模态特征融合,以促进跨模态通信。融合模块基于交叉注意力机制,在区域特征 \(\mathbf{v}\) 和类名嵌入 \(\mathbf{t}\) 上进行聚合。从数学上讲,该过程如下所示:
q_v=W^{(q)}\mathbf{v}, k_t=W^{(k)}\mathbf{t}, v_t=W^{(v)}\mathbf{t}
\label{eq:attn_proj}
\end{equation}
\]
attention=\text{softmax}(q_vk_t^T/\sqrt{d})
\label{eq:x-attn}
\end{equation}
\]
\hat{q_v}=q_v+attention\cdot v_t
\label{eq:residual}
\end{equation}
\]
其中, \(W^{(q)}, W^{(k)}, W^{(v)}\) 是交叉注意力的可训练参数, \(d\) 是中间通道的大小。
多模态融合模块确保在图像特征提取的早期阶段与文本特征进行充分的通信,从而丰富了区域特征的多样性。此外,它提高了利用语义信息中包含的类间相关性的效果。
Semantic-aware Max-margin Loss
语义相似度分类器将视觉特征与语义嵌入对齐,导致新类别的特征分布无偏。然而,语义嵌入中包含的类间相关性也可能导致相似基类和新类之间的类别混淆。为了避免这种情况,论文提出了一种基于语义感知的最大间隔损失,根据它们的语义关系在两个类别之间应用自适应边界。
在先前的研究中,分类分支通过端到端的交叉熵损失进行优化,每个区域特征被训练成靠近类中心。给定第 \(i\) 个区域特征 \(v_i\) 和标签 \(y_i\) ,分类损失计算如下。
L_{cls}=-\frac{1}{n}\sum_{i=1}^{n}\text{log} \ \frac{e^{\text{D}(v_i, t_{y_i})}}{\sum_{j=1}^{n}e^{\text{D}(v_i, t_{y_j})}}
\label{eq:cross_entropy}
\end{equation}
\]
其中 \(t_{y_i}\) 是 \(y_i\) 的类名嵌入。
论文用冻结的语义嵌入替换线性分类器。因此,新类别可以从训练良好的相似基类中学习。然而,如果两个类别之间的语义关系非常接近,这也可能造成混淆。因此,论文在交叉熵损失上添加一个自适应边界,将可能混淆的类别彼此分开。从数学上讲,语义感知最大间隔损失计算如下。
L_{sam}=-\frac{1}{n}\sum_{i=1}^{n}\text{log} \ p_i
\label{eq:max-margin1}
\end{equation}
\]
其中 \(p_i\) 表示分类分数,
p_i=\frac{e^{\text{D}(v_i, t_{y_i})}}{e^{\text{D}(v_i, t_{y_i})} + \sum_{j\neq i}^{n}e^{\text{D}(v_i, t_{y_j}) + m_{ij}}}
\label{eq:max-margin2}
\end{equation}
\]
其中 \(m_{ij}\) 表示应用于类别 \(i\) 和类别 \(j\) 之间的边界,
m_{ij}=
\begin{cases}
\text{cosine}(t_i, t_j)& \text{cosine}(t_i, t_j)-\gamma>0 \\
0& \text{cosine}(t_i, t_j)-\gamma\leq0
\end{cases}
\label{eq:max-margin3}
\end{equation}
\]
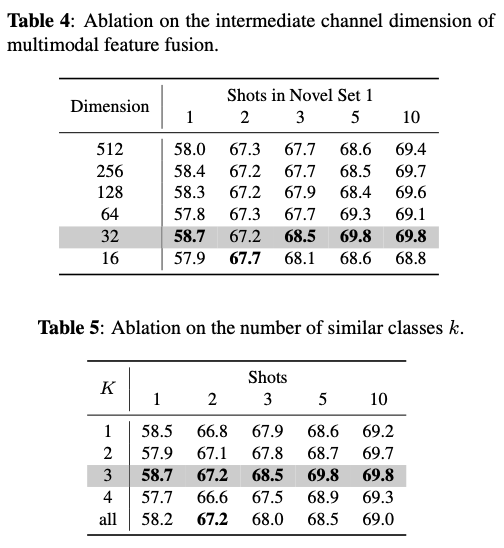
其中 \(\gamma\) 是语义相似性的阈值。对于每个类别,选择仅将前 \(k\) 个最相似的类别应用边界,以避免不必要的噪声。
Experiments
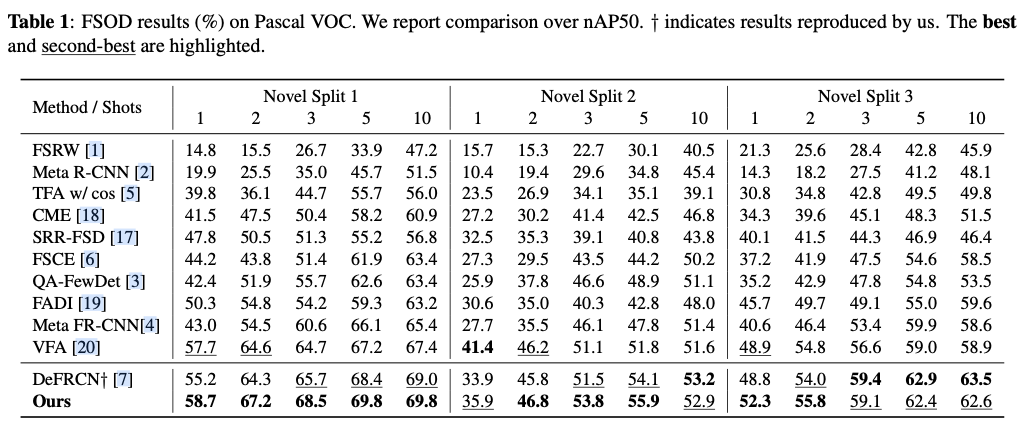
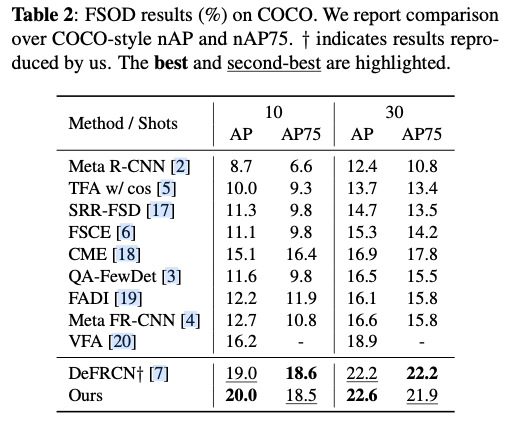
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

基于语义增强的少样本检测,突破新类别偏见 | ICIP'24的更多相关文章
- 腾讯推出超强少样本目标检测算法,公开千类少样本检测训练集FSOD | CVPR 2020
论文提出了新的少样本目标检测算法,创新点包括Attention-RPN.多关系检测器以及对比训练策略,另外还构建了包含1000类的少样本检测数据集FSOD,在FSOD上训练得到的论文模型能够直接迁移到 ...
- 增量学习不只有finetune,三星AI提出增量式少样本目标检测算法ONCE | CVPR 2020
论文提出增量式少样本目标检测算法ONCE,与主流的少样本目标检测算法不太一样,目前很多性能高的方法大都基于比对的方式进行有目标的检测,并且需要大量的数据进行模型训练再应用到新类中,要检测所有的类别则需 ...
- NeurIPS 2019 | 基于Co-Attention和Co-Excitation的少样本目标检测
论文提出CoAE少样本目标检测算法,该算法使用non-local block来提取目标图片与查询图片间的对应特征,使得RPN网络能够准确的获取对应类别对象的位置,另外使用类似SE block的sque ...
- (转载)基于比较的少样本(one/few-shoting)分类
基于比较的方法 先通过CNN得到目标特征,然后与参考目标的特征进行比较. 不同在于比较的方法不同而已. 基本概念 数据集Omniglot:50种alphabets(文字或者文明); alphabet中 ...
- 基于YOLO和PSPNet的目标检测与语义分割系统(python)
基于YOLO和PSPNet的目标检测与语义分割系统 源代码地址 概述 这是我的本科毕业设计 它的主要功能是通过YOLOv5进行目标检测,并使用PSPNet进行语义分割. 本项目YOLOv5部分代码基于 ...
- 基于深度学习的恶意样本行为检测(含源码) ----采用CNN深度学习算法对Cuckoo沙箱的动态行为日志进行检测和分类
from:http://www.freebuf.com/articles/system/182566.html 0×01 前言 目前的恶意样本检测方法可以分为两大类:静态检测和动态检测.静态检测是指并 ...
- 基于语义感知SBST的API场景测试智能生成
摘要:面对庞大服务接口群,完备的接口测试覆盖和业务上下文场景测试看护才有可能保障产品服务的质量和可信.如果你想低成本实现产品和服务的测试高覆盖和高质量看护,这篇文章将为你提供你想要的. 本文分享自华为 ...
- NeurIPS 2022:基于语义聚合的对比式自监督学习方法
摘要:该论文将同一图像不同视角图像块内的语义一致的图像区域视为正样本对,语义不同的图像区域视为负样本对. 本文分享自华为云社区<[NeurIPS 2022]基于语义聚合的对比式自监督学习方法&g ...
- Generalizing from a Few Examples: A Survey on Few-Shot Learning(从几个例子总结经验:少样本学习综述)
摘要:人工智能在数据密集型应用中取得了成功,但它缺乏从有限的示例中学习的能力.为了解决这一问题,提出了少镜头学习(FSL).利用先验知识,可以快速地从有限监督经验的新任务中归纳出来.为了全面了解FSL ...
- 每天进步一点点------Sobel算子(3)基于彩色图像边缘差分的运动目标检测算法
摘 要: 针对目前常用的运动目标提取易受到噪声影响.易出现阴影和误检漏检等情况,提出了一种基于Sobel算子的彩色边缘图像检测和帧差分相结合的检测方法.首先用Sobel算子提取视频流中连续4帧图像的 ...
随机推荐
- Error: Dynamic require of "path" is not supported
failed to load config from D:\BaiduSyncdisk\vue3\sys-manager\vite.config.jserror when starting dev s ...
- JavaScript小面试~数组相关的方法和运用(学习笔记)
1,稀疏数组 稀疏数组是指数组中的某个下标未给出值或某个下标的值被删除.例如: let arrayOne=['xiaozi',,12,,true,23] let arrayTwo=[1,2,3,3,4 ...
- Docker安装及操作
目录 docker 安装: 官方文档方法 CentOS Ubuntu docker-compose 单独安装 centos7 ubuntu22.04 docker 容器操作: docker启动与停止 ...
- 2024-07-27:用go语言,给定一个正整数数组,最开始可以对数组中的元素进行增加操作,每个元素最多加1。 然后从修改后的数组中选出一个或多个元素,使得这些元素排序后是连续的。 要求找出最多可以选
2024-07-27:用go语言,给定一个正整数数组,最开始可以对数组中的元素进行增加操作,每个元素最多加1. 然后从修改后的数组中选出一个或多个元素,使得这些元素排序后是连续的. 要求找出最多可以选 ...
- 自制基于simplefoc大功率驱动板想法的由来,同时欢迎有相同兴趣的F友一起来玩。。。
前一阵子,偶然在B站上看了一个simplefoc的介绍视频,代码简洁.算法精妙让人佩服,更让人佩服的是:开源!遂!搜索之!不搜不知道一搜吓一跳,发现太OUT了,原来玩这个算法的人这么多,让我这个整天沉 ...
- 在Linux中清理Buff/cache
在 Linux 中,缓冲区和缓存是为提高系统性能而保留的,但如果这些缓存过多,可能会消耗大量内存,影响系统的性能.有时候,您可能需要手动清理这些缓存以释放内存.但请注意,通常不建议定期或频繁地这样做, ...
- [银河麒麟] Samba的安装与配置
什么是Samba以及它是干嘛的 Samba,是种用来让UNIX系列的操作系统与微软Windows操作系统的SMB/CIFS(Server Message Block/Common Internet F ...
- 【Hearts Of Iron IV】钢铁雄心4 安装笔记
一.解决Steam购买游戏和下载问题 我可能是正版受害者 Steam平台这个游戏本体是购买锁国区的 然后在淘宝上面买激活码激活的 都激活过了的Key,所以放出来也无所谓了 钢铁雄心4学员版本体:7B0 ...
- 【Spring】03 XML配置
Alias别名设置 可以为一个Bean的ID再设置一个ID 多一个可用标识,大概... 在获取实例注入参数时,两个标识都可以使用 除了Alias可以设置别名之外,Bean的标签本身也可以设置第二别名 ...
- 【Java】JDBC Part5.1 Hikari连接池补充
Hikari Connection Pool Hikari 连接池 HikariCP 官方文档 https://github.com/brettwooldridge/HikariCP Maven依赖 ...