[转帖]clickHouse单机模式安装部署(RPM安装)
关于版本和系统的选择
操作系统:Centos-7
ClickHouse: rpm 在安装,20.x
安装前的准备
CentOS7 打开文件数限
在 /etc/security/limits.conf 这个文件的末尾加入一下内容:
[hadoop@hadoop001 ~]$ sudo vim /etc/security/limits.conf
-
* soft nofile 65536
-
* hard nofile 65536
-
* soft nproc 131072
-
* hard nproc 131072
/etc/security/limits.d/20-nproc.conf (centos6 是90-nproc.conf) 这个文件的末尾加入一下内容:
[hadoop@hadoop001 ~]$ sudo vim /etc/security/limits.d/20-nproc.conf
-
* soft nofile 65536
-
* hard nofile 65536
-
* soft nproc 131072
-
* hard nproc 131072
重启服务器之后生效,用 ulimit -n 或者 ulimit -a 查看设置结果
-
ulimit -n
-
ulimit -a
-
[hadoop@hadoop001 ~]$ ulimit -n
-
65536
-
[hadoop@hadoop001 ~]$ ulimit -a
-
core file size (blocks, -c) 0
-
data seg size (kbytes, -d) unlimited
-
scheduling priority (-e) 0
-
file size (blocks, -f) unlimited
-
pending signals (-i) 14994
-
max locked memory (kbytes, -l) 64
-
max memory size (kbytes, -m) unlimited
-
open files (-n) 65536
-
pipe size (512 bytes, -p) 8
-
POSIX message queues (bytes, -q) 819200
-
real-time priority (-r) 0
-
stack size (kbytes, -s) 8192
-
cpu time (seconds, -t) unlimited
-
max user processes (-u) 131072
-
virtual memory (kbytes, -v) unlimited
-
file locks (-x) unlimited
CentOS7 取消 SELINUX
修改 /etc/selinux/config 中的 SELINUX=disabled 后重启
[hadoop@hadoop001 ~]$ sudo vim /etc/selinux/config
SELINUX=disabled
关闭防火墙
-
[hadoop@hadoop001 ~]$ sudo systemctl stop firewalld.service
-
[hadoop@hadoop001 ~]$ sudo systemctl disable firewalld.servie
-
[hadoop@hadoop001 ~]$ sudo systemctl status firewalld.service
-
● firewalld.service - firewalld - dynamic firewall daemon
-
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
-
Active: inactive (dead)
-
Docs: man:firewalld(1)
-
[hadoop@hadoop001 ~]$
-
安装依赖
-
[hadoop@hadoop001 ~]$ sudo yum install -y libtool
-
[hadoop@hadoop001 ~]$ sudo yum install -y *unixODBC*
安装
官网:https://clickhouse.yandex/
具体安装细节看:https://clickhouse.tech/#quick-start
先检查是否已经安装clickhouse,如果已经安装,先卸载 clickhouse
查询是否安装 clickhouse:
[hadoop@hadoop001 software]rpm -qa | grep clickhouse
卸载 clickhouse:
-
[hadoop@hadoop001 software]rpm -e --nodeps clickhouse-client-20.1.4.14-2.noarch
-
[hadoop@hadoop001 software]rpm -e --nodeps clickhouse-server-20.1.4.14-2.noarch
-
[hadoop@hadoop001 software]rpm -e --nodeps clickhouse-common-static-20.1.4.14-2-2.x86_64
删除数据目录:
[hadoop@hadoop001 software]rm -rf /var/lib/clickhouse
删除集群配置文件:
[hadoop@hadoop001 software]rm -rf /etc/metrika.xml
删除集群配置文件:
[hadoop@hadoop001 software]rm -rf /etc/metrika.xml
删除配置文件:
[hadoop@hadoop001 software]rm -rf /etc/clickhouse-*
删除日志文件:
[hadoop@hadoop001 software]rm -rf /var/log/clickhouse-server
删除 zookeeper 上 clickhouse 的数据:
rmr /clickhouse
也可以进行全局寻找,然后执行删除操作
[hadoop@hadoop001 software]find / -name 'clickhouse'
单机模式
ClickHouse的安装可以使用 yum在线安装,也可以使用 rpm 离线安装的方式!
具体信息见官网文档:https://clickhouse.tech/#quick-start
准备操作
需要验证当前服务器的 CPU 是否支持 SSE 4.2 指令集,因为向量化执行需要用到这项特性:
-
[hadoop@hadoop001 clickhouse]$ grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
-
SSE 4.2 supported
安装
依次执行如下命令:
-
[hadoop@hadoop001 clickhouse]$ sudo yum install yum-utils -y
-
[hadoop@hadoop001 clickhouse]$ sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
-
[hadoop@hadoop001 clickhouse]$ yum-config-manager --add-repo ttps://repo.clickhouse.tech/rpm/clickhouse.repo
-
[hadoop@hadoop001 clickhouse]$ yum install clickhouse-server clickhouse-client -y
如果您没法链接互联网,则也可以使用 rpm 的方式来进行离线安装(下载地址在:https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/https://packagecloud.io/Altinity/clickhouse)需要下载的安装包有:
-
[hadoop@hadoop001 clickhouse]$ ll
-
total 1212764
-
-rw-r--r-- 1 hadoop hadoop 120430 Nov 5 18:20 clickhouse-client-20.1.4.14-2.noarch.rpm
-
-rw-r--r-- 1 hadoop hadoop 113426346 Nov 5 18:23 clickhouse-common-static-20.1.4.14-2.x86_64.rpm
-
-rw-r--r-- 1 hadoop hadoop 1128177078 Nov 6 09:18 clickhouse-common-static-dbg-20.1.4.14-2.x86_64.rpm
-
-rw-r--r-- 1 hadoop hadoop 141391 Nov 5 18:20 clickhouse-server-20.1.4.14-2.noarch.rpm
rpm安装
-
[hadoop@hadoop001 clickhouse]$ sudo rpm -ivh *.rpm
-
warning: clickhouse-client-20.1.4.14-2.noarch.rpm: Header V4 RSA/SHA1 Signature, key ID e0c56bd4: NOKEY
-
Preparing... ################################# [100%]
-
Updating / installing...
-
1:clickhouse-common-static-20.1.4.1################################# [ 25%]
-
2:clickhouse-client-20.1.4.14-2 ################################# [ 50%]
-
3:clickhouse-server-20.1.4.14-2 ################################# [ 75%]
-
Created symlink from /etc/systemd/system/multi-user.target.wants/clickhouse-server.service to /etc/systemd/system/clickhouse-server.service.
-
Path to data directory in /etc/clickhouse-server/config.xml: /var/lib/clickhouse/
-
4:clickhouse-common-static-dbg-20.1################################# [100%]
启动服务端
前段启动:
sudo -u clickhouse clickhouse-server --config-file=/etc/clickhouse-server/config.xml
后端启动
nohup sudo -u clickhouse clickhouse-server --config-file=/etc/clickhouse-server/config.xml 1>/tmp/clickhouse/clickhouse_std.log 2>/tmp/clickhouse/clickhouse_err.log &
验证测试
-
[root@hadoop001 ~]# ps aux | grep clickhouse
-
clickho+ 2955 0.1 3.1 2425796 122628 ? Ssl 00:55 0:01 /usr/bin/clickhouse-server --config=/etc/clickhouse-server/config.xml --pid-file=/run/clickhouse-server/clickhouse-server.pid
-
root 3347 0.0 0.0 112704 980 pts/1 S+ 01:08 0:00 grep --color=auto clickhouse
-
[root@hadoop001 ~]# netstat -ntlp | grep clickhouse
-
tcp6 0 0 :::8123 :::* LISTEN 3966/clickhouse-ser
-
tcp6 0 0 :::9000 :::* LISTEN 3966/clickhouse-ser
-
tcp6 0 0 :::9009 :::* LISTEN 3966/clickhouse-ser
-
[root@hadoop001 ~]# clickhouse-client
-
ClickHouse client version 20.1.4.14 (official build).
-
Connecting to localhost:9000 as user default.
-
Connected to ClickHouse server version 20.1.4 revision 54431.
-
-
hadoop001 :) show databases;
-
-
SHOW DATABASES
-
-
┌─name────┐
-
│ default │
-
│ system │
-
└─────────┘
-
-
2 rows in set. Elapsed: 0.012 sec.
-
-
hadoop001 :) create database test;
-
-
CREATE DATABASE test
-
-
Ok.
-
-
hadoop001 :) insert into test01 values (1, 'Russia'), (2, 'clickhouse'), (3, 'spark');
-
-
INSERT INTO test01 VALUES
-
-
Ok.
-
-
3 rows in set. Elapsed: 0.003 sec.
-
-
hadoop001 :) select id, name from test01;
-
-
SELECT
-
id,
-
name
-
FROM test01
-
-
┌─id─┬─name───────┐
-
│ 1 │ Russia │
-
│ 2 │ clickhouse │
-
│ 3 │ spark │
-
└────┴────────────┘
-
-
3 rows in set. Elapsed: 0.012 sec.
-
-
hadoop001 :)
-
-
-
0 rows in set. Elapsed: 0.002 sec.
问题汇总
问题一:启动报错
启动参数:sudo clickhouse-server --config-file=/etc/clickhouse-server/config.xml
2020.08.20 18:49:28.189321 [ 29338 ] {} <Error> Application: DB::Exception: Effective user of the process (root) does not match the owner of the data (clickhouse). Run under 'sudo -u clickhouse'
解决办法,已经有了提示,Run under ‘sudo -u clickhouse’.
修改后启动参数: sudo -u clickhouse clickhouse-server --config-file=/etc/clickhouse-server/config.xml
问题二:clickhouse-clict 连接失败
-
[root@hadoop001 ~]# clickhouse-client
-
ClickHouse client version 20.1.4.14 (official build).
-
Connecting to localhost:9000 as user default.
-
Code: 210. DB::NetException: Connection refused (localhost:9000)
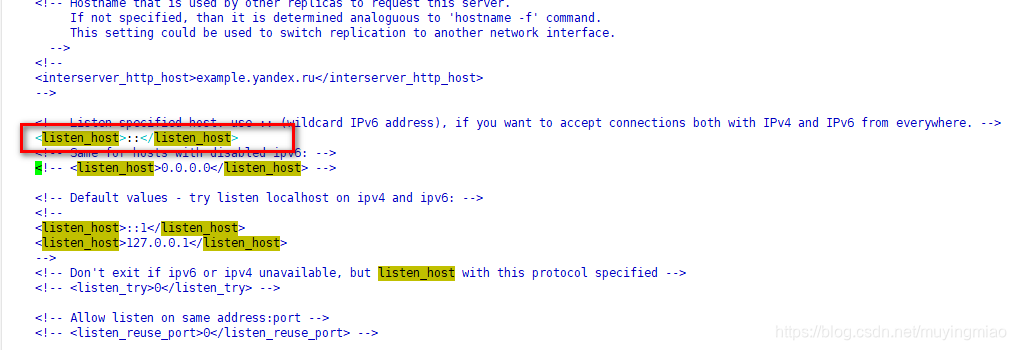
[root@hadoop001 clickhouse]# vim /etc/clickhouse-server/config.xml
打开此处注释
</article>
[转帖]clickHouse单机模式安装部署(RPM安装)的更多相关文章
- Hadoop单机模式的配置与安装
Hadoop单机模式的配置与安装 单机hadoop集群正常启动后进程情况 ResourceManager NodeManager SecondaryNameNode NameNode DataNode ...
- linux/centos下安装nginx(rpm安装和源码安装)详细步骤
Centos下安装nginx rpm包 ...
- [转]gitlab cicd (二)系列之安装git-runner rpm安装方式
本文转自:https://blog.csdn.net/qq_21816375/article/details/84308748 本编是继gitlab cicd (一)系列之安装gitlb之后,基于安装 ...
- Mysql的多种安装方法———rpm安装
下载地址 搜狐镜像:http://mirrors.sohu.com/mysql 官方网址:https://dev.mysql.com/downloads/mysql/ 一.rpm安装方式 从下载地址下 ...
- Linux下Mysql安装(RPM安装)
1. 首先检查机器里是否已经存在MySQL $ rpm -qa | grep mysql 2. 去官网下载相应的rpm包:https://dev.mysql.com/downloads/mysql/ ...
- gitlab 源码安装=》rpm安装横向迁移(version 9.0)
准备: 下载版本地址: https://packages.gitlab.com/gitlab/gitlab-ce 迁移环境: 源码安装的gitlab9.0.13 目标迁移至9.0.13 RPM安装的环 ...
- VS2013没有安装部署,安装图解
自vs2012后就已经没有安装向导了,VS2013安装是不带安装部署的,用 InstallShield Limited Edition for Visual Studio 解决安装部署问题 第一步:“ ...
- linux下安装mysql(rpm安装)
Mysql 5.7.29安装步骤 1.首先卸载自带的Mysql-libs(如果之前安装过mysql,要全都卸载掉) rpm -qa | grep -i -E mysql\|mariadb | xarg ...
- Ranger安装部署 - solr安装
1. 概述 Lucene是一个Java语言编写的利用倒排原理实现的文本检索类库: Solr是以Lucene为基础实现的文本检索应用服务.Solr部署方式有单机方式.多机Master-Slaver方法. ...
- Linux Hadoop2.7.3 安装(单机模式) 一
Linux Hadoop2.7.3 安装(单机模式) 一 Linux Hadoop2.7.3 安装(单机模式) 二 java环境安装 http://www.cnblogs.com/zeze/p/590 ...
随机推荐
- 04 链表(上):如何实现LRU缓存淘汰算法?
一.什么是链表? 1.和数组一样,链表也是一种线性表. 2.从内存结构来看,链表的内存结构是不连续的内存空间,是将一组零散的内存块串联起来,从而进行数据存储的数据结构. 3.链表中的每一个内存块被称为 ...
- 2023-08-08:给你一棵 n 个节点的树(连通无向无环的图) 节点编号从 0 到 n - 1 且恰好有 n - 1 条边 给你一个长度为 n 下标从 0 开始的整数数组 vals 分别表示每个节
2023-08-08:给你一棵 n 个节点的树(连通无向无环的图) 节点编号从 0 到 n - 1 且恰好有 n - 1 条边 给你一个长度为 n 下标从 0 开始的整数数组 vals 分别表示每个节 ...
- HDU 4641 K string 后缀自动机
原题链接 题意 每个测试点,一开始给我们n,m,k然后是一个长度为n的字符串. 之后m次操作,1 c是往字符串后面添加一个字符c,2是查询字符串中出现k次以及以上的子串个数,m为2e5 思路 首先可以 ...
- 赶在520之前,程序员如何用Python送上最特别的“我爱你”表白
摘要:每到情人节.七夕节,不少小伙伴大伙伴们都会遇到这样一个世纪问题--怎么给女朋友/老婆一个与众不同的节日惊喜.今天给大家分享一个独特的表白方法--用"我爱你"拼出心爱人的模样! ...
- Python图像处理丨图像缩放、旋转、翻转与图像平移
摘要:本篇文章主要讲解Python调用OpenCV实现图像位移操作.旋转和翻转效果,包括四部分知识:图像缩放.图像旋转.图像翻转.图像平移. 本文分享自华为云社区<[Python图像处理] 六. ...
- 下载安装Ipa Guard
可以前往ipaguard工具官网下载,工具是免费下载,免费体验使用的.下载地址是https://www.ipaguard.com. 下载后解压工具便ok了,工具是绿色软件,无需其他安装流程.双击I ...
- 如何在NET 6.0使用结构化的日志系统
在我们的系统里面,有一项技术是必须使用的,那就是日志记录.我们在调试系统或者跟踪系统运行情况,都可以通过日志了解具体的情况.在项目开发中,我们有可能使用系统本身所带的日志系统,也有 ...
- ByteHouse技术白皮书正式发布,云数仓核心技术能力首次全面解读(内附下载链接)
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 近日,<火山引擎云原生数据仓库 ByteHouse 技术白皮书>正式发布. 在数字化浪潮下,伴随着公有 ...
- MySQL 项目中 SQL 脚本更新、升级方式,防止多次重复执行
一套代码,多家部署时,在SQL脚本升级时,通过一个SQL文件给运维,避免出现SQL执行序顺出错及漏执行SQL SQL Server 项目中 SQL 脚本更新方式 Oracle 项目中 SQL 脚本更新 ...
- Spring Boot Admin 授权配置
Admin 服务端配置 添加 POM 引用 <dependency> <groupId>org.springframework.boot</groupId> < ...