[转帖]NVIDIA超级AI服务器NVIDIA DGX GH200性能介绍
https://zhuanlan.zhihu.com/p/633219396
2023 年 5 月 28 日NVIDIA宣布推出 NVIDIA DGX GH200,这是首款 100 TB级别的GPU 内存系统。据英伟达称,Meta、微软和谷歌已经部署了这些集群,预计在 2023 年底之前全面上市。

在COMPUTEX 2023上,NVIDIA 发布了NVIDIA DGX GH200,这标志着 GPU 加速计算的又一次突破,为要求最严苛的巨型 AI 工作负载提供支持。过去 7 年来,GPU 的统一内存编程模型一直是复杂加速计算应用取得各种突破的基石。2016 年,NVIDIA 推出了NVLink技术和带有 CUDA-6 的统一内存编程模型,旨在增加 GPU 加速工作负载的可用内存。

从那时起,每个 DGX 系统的核心都是基板上的 GPU 复合体,基板上与 NVLink 互连,其中每个 GPU 都可以以 NVLink 速度访问对方的内存。许多此类带有 GPU 复合体的 DGX 通过高速网络互连,形成更大的超级计算机,例如NVIDIA Selene 超级计算机。然而,一类新兴的巨型万亿参数 AI 模型要么需要几个月的训练时间,要么即使在当今最好的超级计算机上也无法解决。
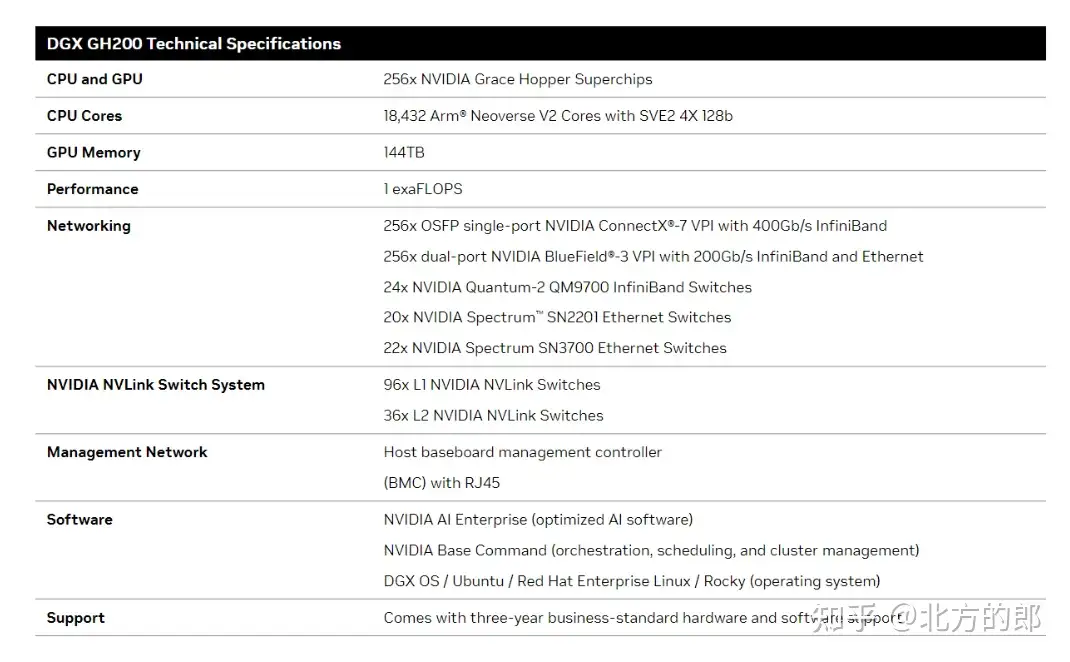
NVIDIA 将NVIDIA Grace Hopper Superchip与 NVLink 开关系统配对,在 NVIDIA DGX GH200 系统中整合了多达 256 个 GPU。在 DGX GH200 系统中,GPU 共享内存编程模型可通过 NVLink 高速访问 144 TB 内存。
与单个NVIDIA DGX A100 320 GB 系统相比,NVIDIA DGX GH200 通过 NVLink 为 GPU 共享内存编程模型提供了近 500 倍的内存,形成了一个巨大的数据中心大小的 GPU。NVIDIA DGX GH200 是第一台突破 GPU 通过 NVLink 访问内存的 100 TB 障碍的超级计算机。
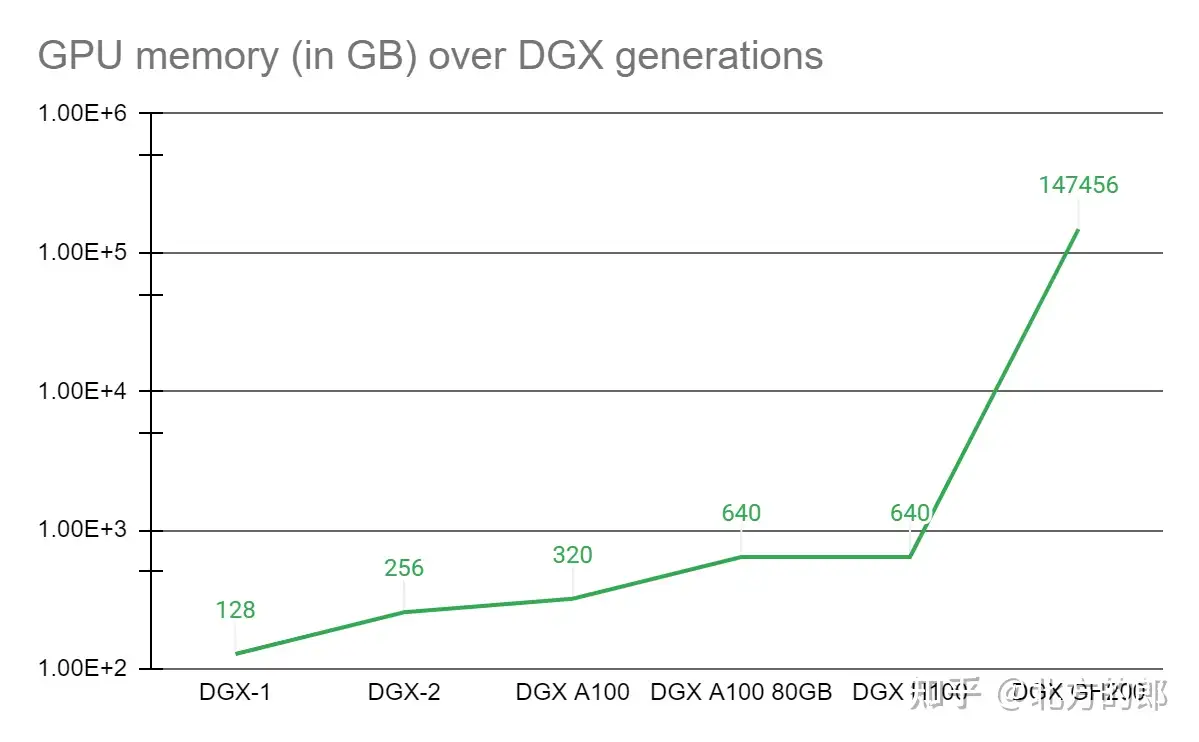
图 1. NVLink 进展带来的 GPU 内存增益
NVIDIA DGX GH200系统架构
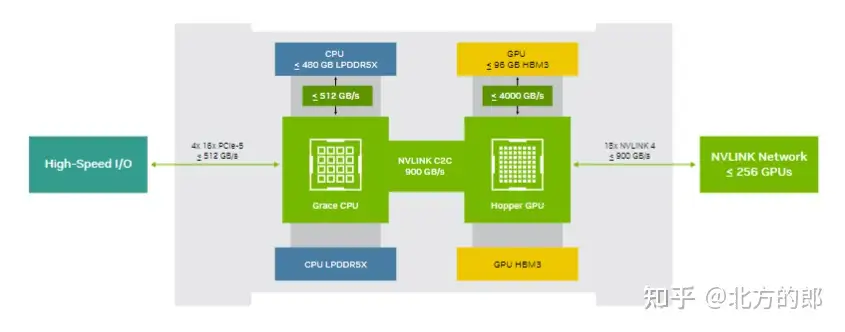
NVIDIA Grace Hopper Superchip 和 NVLink Switch System 是 NVIDIA DGX GH200 架构的构建块。NVIDIA Grace Hopper Superchip 使用NVIDIA NVLink-C2C结合了 Grace 和 Hopper 架构,以提供 CPU + GPU 一致性内存模型。由第四代 NVLink 技术提供支持的 NVLink 开关系统将 NVLink 连接扩展到超级芯片,以创建无缝、高带宽、多 GPU 系统。
NVIDIA DGX GH200 中的每个 NVIDIA Grace Hopper Superchip 都有 480 GB LPDDR5 CPU 内存,每 GB 的功率是 DDR5 和 96 GB 的快速 HBM3 的八分之一。NVIDIA Grace CPU 和 Hopper GPU 与 NVLink-C2C 互连,以五分之一的功率提供比 PCIe Gen5 多 7 倍的带宽。
NVLink 交换机系统形成了一个两级、无阻塞、胖树 NVLink 结构,可在 DGX GH200 系统中完全连接 256 个 Grace Hopper 超级芯片。DGX GH200 中的每个 GPU 都可以 900 GBps 访问其他 GPU 的内存和所有 NVIDIA Grace CPU 的扩展 GPU 内存。
托管 Grace Hopper Superchips 的计算底板使用用于第一层 NVLink 结构的定制线束连接到 NVLink 开关系统。LinkX 电缆扩展了 NVLink 结构第二层的连接性。
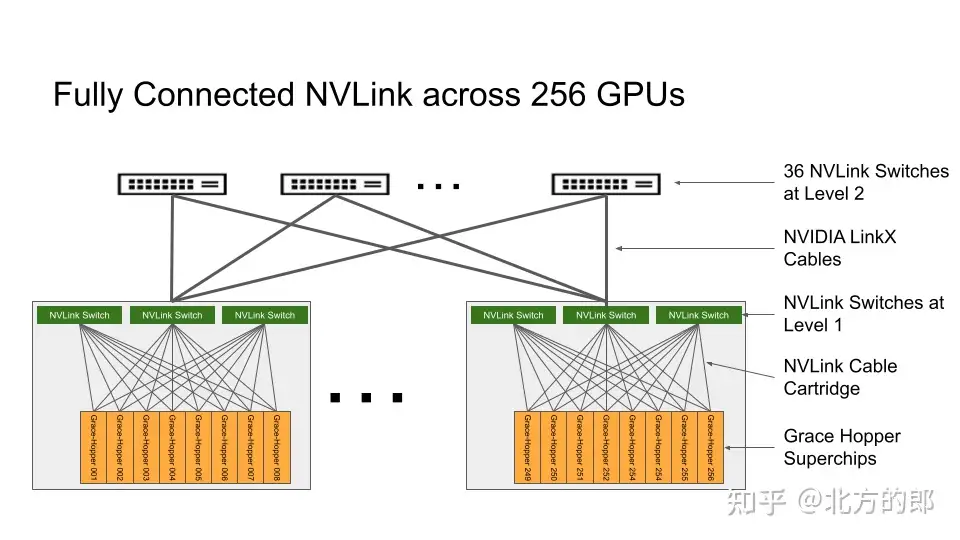
图 2. 包含 256 个 GPU 的 NVIDIA DGX GH200 上完全连接的 NVIDIA NVLink 交换机系统的拓扑结构
在 DGX GH200 系统中,GPU 线程可以使用 NVLink 页表寻址来自 NVLink 网络中其他 Grace Hopper 超级芯片的对等 HBM3 和 LPDDR5X 内存。NVIDIA Magnum IO加速库优化 GPU 通信以提高效率,增强所有 256 个 GPU 的应用程序扩展。
DGX GH200 中的每个 Grace Hopper Superchip 都与一个NVIDIA ConnectX-7网络适配器和一个NVIDIA BlueField-3 NIC配对。DGX GH200 拥有 128 TBps 对分带宽和 230.4 TFLOPS 的 NVIDIA SHARP 网内计算,可加速 AI 中常用的集体操作,并通过减少集体操作的通信开销,将 NVLink 网络系统的有效带宽提高一倍。
为了扩展到超过 256 个 GPU,ConnectX-7 适配器可以互连多个 DGX GH200 系统以扩展到更大的解决方案。BlueField-3 DPU 的强大功能可将任何企业计算环境转变为安全且加速的虚拟私有云,使组织能够在安全的多租户环境中运行应用程序工作负载。
目标用例和性能优势
GPU 内存的代际飞跃显着提高了受 GPU 内存大小瓶颈的 AI 和 HPC 应用程序的性能。许多主流 AI 和 HPC 工作负载可以完全驻留在单个NVIDIA DGX H100的聚合 GPU 内存中。对于此类工作负载,DGX H100 是性能效率最高的训练解决方案。
其他工作负载——例如具有 TB 级嵌入式表的深度学习推荐模型 (DLRM)、TB 级图形神经网络训练模型或大型数据分析工作负载——使用 DGX GH200 可实现 4 至 7 倍的加速。这表明 DGX GH200 是更高级的 AI 和 HPC 模型的更好解决方案,这些模型需要海量内存来进行 GPU 共享内存编程。
NVIDIA Grace Hopper Superchip Architecture白皮书中详细描述了加速机制。
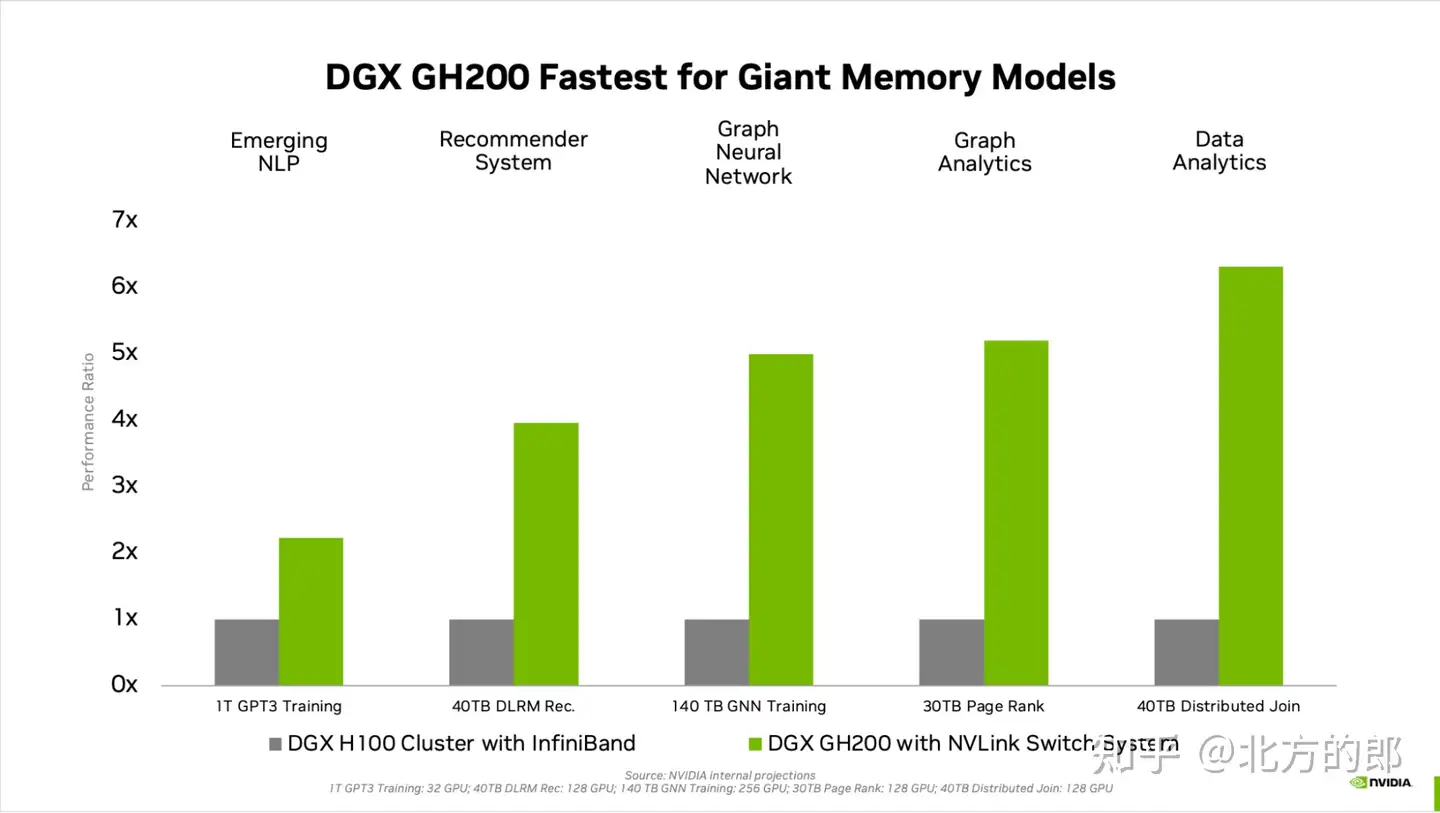
图 3. 大内存 AI 工作负载的性能比较
专为要求最严苛的工作负载而设计
DGX GH200 中的每个组件都经过精心挑选,以最大限度地减少瓶颈,同时最大限度地提高关键工作负载的网络性能,并充分利用所有扩展硬件功能。结果是线性可扩展性和海量共享内存空间的高利用率。
为了充分利用这个先进的系统,NVIDIA 还构建了一个极高速的存储结构,以峰值容量运行并处理各种数据类型(文本、表格数据、音频和视频)——并行且稳定表现。
全栈 NVIDIA 解决方案
DGX GH200 附带NVIDIA Base Command,其中包括针对 AI 工作负载优化的操作系统、集群管理器、加速计算的库、存储和网络基础设施,这些都针对 DGX GH200 系统架构进行了优化。
DGX GH200 还包括NVIDIA AI Enterprise,提供一套优化的软件和框架,以简化 AI 开发和部署。这种全堆栈解决方案使客户能够专注于创新,而不必担心管理其 IT 基础架构。

图 4. NVIDIA DGX GH200 AI 超级计算机完整堆栈包括 NVIDIA Base Command 和 NVIDIA AI Enterprise
DGX GH200技术数据
NVIDIA 正致力于在今年年底推出 DGX GH200。NVIDIA 渴望提供这款令人难以置信的同类首台超级计算机,让您能够创新并追求激情,解决当今最大的 AI 和 HPC 挑战。
巨型模型的巨型内存
NVIDIA DGX GH200 是唯一一款在 256 个NVIDIA Grace Hopper 超级芯片上提供 144TB 海量共享内存空间的 AI 超级计算机,为开发人员提供近 500 倍的内存来构建巨型模型。
超级节能计算
Grace Hopper 超级芯片通过在同一封装上结合NVIDIA Grace CPU和NVIDIA Hopper GPU ,消除了对传统 PCIe CPU 到 GPU 连接的需求,将带宽提高了 7 倍,并将互连功耗降低了 5 倍以上。
集成并准备运行
通过交钥匙 DGX GH200 部署,在数周而不是数月内构建巨型模型。这个全栈数据中心级解决方案包括来自 NVIDIA 的集成软件和白手套服务,从设计到部署,以加快 AI 的投资回报率
NVIDIA Grace Hopper 超级芯片:
NVIDIA Grace Hopper架构将NVIDIA Hopper GPU的突破性性能与NVIDIA Grace CPU的多功能性融合在单个超级芯片中,通过高带宽、内存一致性的NVIDIA,NVLink,Chip-2-Chip(C2C)互连连接在一起。
NVIDIA NVLink-C2C是一种内存一致性、高带宽、低延迟的超级芯片互连。作为Grace Hopper超级芯片的核心,它提供高达900GB/s的总带宽,比加速系统中常用的PCIe Gen5通道高7倍。NVLink-C2C使应用程序能够超量使用GPU的内存,并直接以高带宽利用NVIDIA Grace CPU的内存。每个Grace Hopper超级芯片最多可提供480GB的LPDDR5X CPU内存,使GPU能够直接访问比HMB3多7倍的快速内存。结合NVIDIA NVLink交换系统,通过最多256个NVLink连接的GPU上运行的所有GPU线程可以以高带宽访问高达150TB的内存。
相关链接:
Announcing NVIDIA DGX GH200: The First 100 Terabyte GPU Memory System | NVIDIA Technical Blog
[转帖]NVIDIA超级AI服务器NVIDIA DGX GH200性能介绍的更多相关文章
- NVIDIA CUDA-X AI
NVIDIA CUDA-X AI 面向数据科学和 AI 的 NVIDIA GPU 加速库 数据科学是推动 AI 发展的关键力量之一,而 AI 能够改变各行各业. 但是,驾驭 AI 的力量是一个复杂挑战 ...
- NVIDIA vGPU License服务器搭建详解
当配置有vGPU虚拟机发起License授权请求,授权服务器会根据License中所包含的GRID License版本,加载不同的vGPU驱动(普通驱动和专业Quodra卡驱动).目前vPC和vApp ...
- 超级rtmp服务器和屌丝wowza
超级rtmp服务器和屌丝wowza http://blog.csdn.net/win_lin/article/details/11927973
- 【转帖】处理器史话 | 服务器CPU市场的战役, AMD、Intel和ARM的厮杀
处理器史话 | 服务器CPU市场的战役, AMD.Intel和ARM的厮杀 https://www.eefocus.com/mcu-dsp/377300 说完了个性鲜明的消费类电子,接下来聊一聊通 ...
- 服务器小白的我,是如何将 node+mongodb 项目部署在服务器上并进行性能优化的
前言 本文讲解的是:做为前端开发人员,对服务器的了解还是小白的我,是如何一步步将 node+mongodb 项目部署在阿里云 centos 7.3 的服务器上,并进行性能优化,达到页面 1 秒内看到 ...
- [翻译]——SQL Server使用链接服务器的5个性能杀手
前言: 本文是对博客http://www.dbnewsfeed.com/2012/09/08/5-performance-killers-when-working-with-linked-server ...
- SQLServer通过链接服务器远程删除数据性能问题解决
原文:SQLServer通过链接服务器远程删除数据性能问题解决 在上一遍文章中介绍了SQLServer通过链接服务器访问Oracle性能问题的解决方法,本文介绍链接服务器下远程删除SQLServer数 ...
- DELL服务器管理工具和RACADM介绍
DELL服务器管理工具和RACADM介绍 一.Dell服务器管理工具介绍 Dell对服务器(DELL PowerEdge)的管理主要提供了三种管理工具,分别是Dell Remote Access Co ...
- TensorRT加速 ——NVIDIA终端AI芯片加速用,可以直接利用caffe或TensorFlow生成的模型来predict(inference)
官网:https://developer.nvidia.com/tensorrt 作用:NVIDIA TensorRT™ is a high-performance deep learning inf ...
- Ubuntu16.04 安装NVIDIA显卡驱动
1. 禁用系统默认的集成驱动 Ubuntu系统集成的显卡驱动程序是nouveau,它是第三方为NVIDIA开发的开源驱动,我们需要先将其屏蔽才能安装NVIDIA官方驱动.将驱动添加到黑名单blackl ...
随机推荐
- 通过JDK动态代理类实现一个类中多种方法的不同增强
1.为什么说JDK动态代理必须要实现当前父接口才能使用 JDK动态代理是基于接口的代理,它要求目标类(被代理的类)必须实现一个或多个接口.这是因为JDK动态代理是通过创建目标类的接口的代理对象来实现的 ...
- libGDX游戏开发之菜单界面(四)
libGDX游戏开发之菜单界面(四) libGDX系列,游戏开发有unity3D巴拉巴拉的,为啥还用java开发?因为我是Java程序员emm-国内用libgdx比较少,多数情况需要去官网和googl ...
- 从源码分析 MySQL 身份验证插件的实现细节
最近在分析ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)这个报错的常见原因. 在 ...
- 文心一言 VS 讯飞星火 VS chatgpt (36)-- 算法导论5.3 6题
六.请解释如何实现算法 PERMUTE-BY-SORTING,以处理两个或更多优先级相同的情形.也就是说,即使有两个或更多优先级相同,你的算法也应该产生一个均匀随机排列. 文心一言: 算法 PERMU ...
- Flutter GetX的事件监听
Flutter GetX的事件监听 import 'package:flutter/material.dart'; import 'package:flutter_code/page/book/boo ...
- hiveSQL常见专题
SQL强化 SQL执行顺序 --举例: select a.sex, b.city, count(1) as cnt, sum(salary) as sum1 from table1 a join ta ...
- 在Mac上打开Emoji键盘 ⌨️
因为想要输入Emoji字符,以前总上到网上搜,如 emojipedia.org ,然后复制.最近,输入Emoji有点多,就想查查有没有什么简便方法. 果然有,我用的是macOS,只要按下键盘上的 co ...
- 跟着B站UP主小姐姐去华为坂田基地采访扫地僧
摘要:谁说程序员就只能写代码呢!华为扫地僧的才艺是完全可以solo出道的那种. 忍不住想要和你们分享下我9月份的快乐呀!Mark下最近完成的一件超了不起的事情!我去你们口中别人家的公司-华为啦!这次采 ...
- GaussDB(for MySQL)如何快速创建索引?华为云数据库资深架构师为您揭秘
摘要:云服务环境下,如何解决客户基于大量数据创建索引的性能问题,成为云服务厂商的一个挑战.华为云GaussDB(for MySQL)通过引入并行创建索引技术,很好地解决了批量索引创建和临时添加索引等性 ...
- 敏捷开发专家一席谈:云原生技术下的华为云DevOps实践之路
摘要:听华为云DevCloud首席技术布道师徐毅讲述云原生下的DevOps实践. 本文分享自华为云社区<敏捷开发专家一席谈:云原生技术下的华为云DevOps实践之路>,作者:华为云社区精选 ...