用 bitsandbytes、4 比特量化和 QLoRA 打造亲民的 LLM
众所周知,LLM 规模庞大,如果在也能消费类硬件中运行或训练它们将是其亲民化的巨大进步。我们之前撰写的 LLM.int8 博文 展示了我们是如何将 LLM.int8 论文 中的技术通过 bitsandbytes 库集成到 transformers 中的。在此基础上,我们不断努力以不断降低大模型的准入门槛。在此过程中,我们决定再次与 bitsandbytes 联手,支持用户以 4 比特精度运行任何模态 (文本、视觉、多模态等) 上的绝大多数 HF 模型。用户还可以利用 Hugging Face 生态系统中的工具在 4 比特模型之上训练适配器。这一工作基于 Dettmers 等人最近在 QLoRA 这篇论文中介绍的一种新方法,其论文摘要如下:
我们提出了 QLoRA,这是一种高效的微调方法,可减少内存使用量,使得在单个 48GB GPU 上就可以微调 65B 的模型,而且所得模型的性能与全 16 比特微调相当。QLoRA 通过冻结 4 比特量化的预训练语言模型将梯度反向传播到低秩适配器 (LoRA) 中。我们最好的模型 (我们将其命名为 Guanaco) 仅需在单个 GPU 上进行 24 小时微调,就能在 Vicuna 基准测试中优于所有之前公开发布的模型,且达到了 ChatGPT 性能水平的 99.3%。QLoRA 引入了多项创新技术,在不牺牲性能的情况下节省内存:(a) 4 位 NormalFloat (NF4),一种新的数据类型,在信息论意义上是正态分布权重的最佳表示 (b) 双量化,通过对量化系数进行二次量化来减少平均内存占用,以及 (c) 用于降低峰值内存占用的分页优化器。我们使用 QLoRA 微调了 1000 多个模型,并给出了它们在指令依从、聊天等任务上的详细性能分析,其中涵盖了 8 个指令数据集、多种模型架构 (LLaMA、T5),还包括了无法用常规方法微调的大模型 (例如 33B 和 65B 模型)。结果表明,在小型高质量数据集的进行 QLoRA 微调能带来最先进的性能,且所需的模型尺寸更小。我们使用人类和 GPT-4 对聊天机器人的性能进行了详细评估分析,结果表明 GPT-4 评估是替代人类评估的廉价且合理的方案。此外,我们发现当前的聊天机器人基准测试在准确评估聊天机器人的性能水平这一方面并不十分可信。我们还挑选了一些样本,对 Guanaco 比 ChatGPT 做得不好的案例进行了分析。我们发布了所有模型和代码,包括用于 4 比特训练的 CUDA 核函数。
资源
下面是一些 4 比特模型和 QLoRA 的入门资源:
- 原始论文
- 有关 bitsandbytes 基础用法的 Google Colab 笔记本 - 该笔记本展示了如何对 4 比特模型进行推理,以及如何在免费的 Google Colab 实例上运行 GPT-neo-X 模型 (20B) 。
- 微调的 Google Colab 笔记本 - 该笔记本展示了如何使用 Hugging Face 生态系统在下游任务上微调 4 比特模型。我们证明了可以在 Google Colab 实例上微调 GPT-neo-X 20B!
- 用于复现论文结果的原始代码库
- Guanaco 33B 的演示空间 - 下文中也包含了这个演示空间。
引言
如果你对模型精度及一些常见的数据类型 (float16、float32、bfloat16、int8) 尚不熟悉,建议你仔细阅读 我们的第一篇博文,这篇博文图文并茂地详细介绍了相关概念的细节。
如需更多信息,建议查阅 这篇 wikibook 文档 以了解浮点表示的基础知识。
QLoRA 论文中探讨了两种不同的数据类型: 4 比特 Float 和 4 比特 NormalFloat。这里我们将讨论 4 比特 Float 数据类型,因为它更容易理解。
FP8 和 FP4 分别代表浮点 8 比特和 4 比特精度。它们属于 minifloats 浮点值系列 (minifloats 系列还包括其他精度,如 bfloat16 和 float16)。
我们先看一下如何用 FP8 格式表示浮点值,然后了解 FP4 格式是什么样子的。
FP8 格式
正如之前的博文中所讨论的,n 比特的浮点数中每个比特都属于一个特定类别,负责表示数字的各个组成部分 (符号、尾数和指数)。
FP8 for Deep Learning 这篇论文首次引入了 FP8 (浮点 8) 格式,其有两种不同的编码方式: E4M3 (4 位指数,3 位尾数) 和 E5M2 (5 位指数,2 位尾数)。
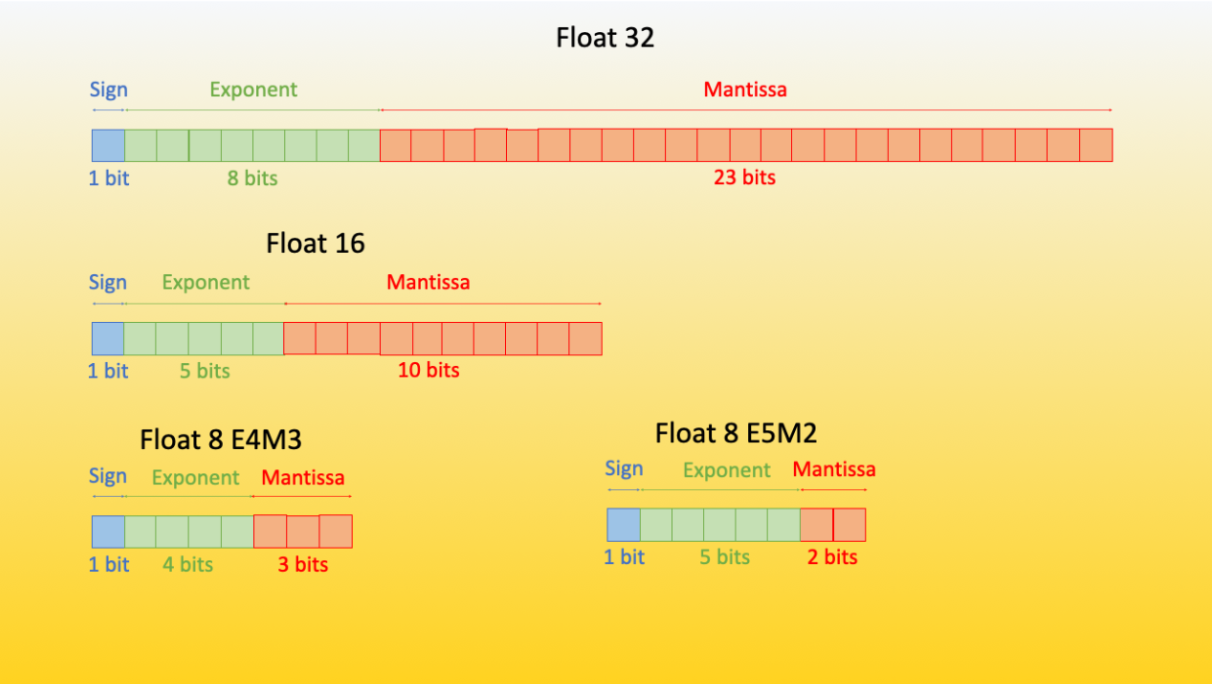
尽管随着比特数从 32 减少到 8,精度大大降低了,但这两种 8 比特编码仍有很多用武之地。目前,我们可以通过 Transformer Engine 库 来使用它们,HF 生态系统的 accelerate 库也集成了 Transformer Engine 库。
E4M3 格式可以表示的浮点数范围为 -448 到 448。而 E5M2 格式因为增加了指数位数,其表示范围扩大为 -57344 到 57344 - 但其相对 E4M3 而言精度会有损失,因为两者可表示的数的个数保持不变。经验证明,E4M3 最适合前向计算,E5M2 最适合后向计算。
FP4 精度简述
符号位表示符号 (+/-),指数位转译成该部分所表示的整数的 2 次方 (例如 2^{010} = 2^{2} = 4 )。分数或尾数位表示成 -2 的幂的总和,如果第 i 位为 1 ,则和加上 2^-i ,否则保持不变,这里 i 是该位在比特序列中的位置。例如,对于尾数 1010,我们有 (2^-1 + 0 + 2^-3 + 0) = (0.5 + 0.125) = 0.625 ,然后,我们给分数加上一个 1 ,得到 1.625 。最后,再将所有结果相乘。举个例子,使用 2 个指数位和 1 个尾数位,编码 1101 对应的数值为:
-1 * 2^(2)*(1 + 2^-1) = -1 * 4 * 1.5 = -6
FP4 没有固定的格式,因此可以尝试不同尾数/指数的组合。一般来说,在大多数情况下,3 个指数位的效果会更好一些。但某些情况下,2 个指数位加上 1 个尾数位性能会更好。
QLoRA,经由量化实现大模型自由的新途径
简而言之,与标准 16 比特模型微调相比,QLoRA 在不牺牲性能的前提下减少了 LLM 微调的内存使用量。使用该方法,我们可在单个 24GB GPU 上微调 33B 模型,还可以在单个 46GB GPU 上微调 65B 模型。
更具体地说,QLoRA 使用 4 比特量化来压缩预训练的语言模型。然后冻结基础模型的参数,并将相对少量的可训练参数以低秩适配器的形式添加到模型中。在微调过程中,QLoRA 通过冻结的 4 比特量化预训练语言模型将梯度反向传播到低秩适配器中。LoRA 层的权重是训练期间唯一可更新的参数。你可阅读 原始 LoRA 论文 以了解更多有关 LoRA 的信息。
QLoRA 有一个用于存储基础模型权重的数据类型 (通常为 4 比特 NormalFloat) 和一个用于执行计算的数据类型 (16 比特 BrainFloat)。QLoRA 将权重从存储数据类型反量化为计算数据类型,以执行前向和后向传播,但仅计算 bfloat16 的 LoRA 参数的权重梯度。权重仅在需要时才解压缩,因此在训练和推理期间内存使用率都能保持较低水平。
广泛的实验表明 QLoRA 微调与 16 比特微调的性能旗鼓相当。此外,在 OpenAssistant 数据集 (OASST1) 上对 LLaMA 模型使用 QLoRA 微调而得的 Guanaco 模型是目前最先进的聊天机器人系统,其在 Vicuna 基准测试中表现接近 ChatGPT。这是 QLoRA 微调威力的进一步展示。
如何在 transformers 中使用它?
在本节中,我们将介绍该方法在 transformers 中的集成、如何使用它以及目前支持的模型。
入门
作为快速入门,我们可以从源代码安装 accelerate 和 transformers ,以加载 4 比特模型,另请确保已安装最新版本的 bitsandbytes 库 (0.39.0)。
pip install -q -U bitsandbytes
pip install -q -U git+https://github.com/huggingface/transformers.git
pip install -q -U git+https://github.com/huggingface/peft.git
pip install -q -U git+https://github.com/huggingface/accelerate.git
快速开始
以 4 比特加载模型的基本方法是通过在调用 from_pretrained 方法时传递参数 load_in_4bit=True ,并将设备映射设置成 “auto” 。
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_4bit=True, device_map="auto")
...
这样就行了!
一般地,我们建议用户在使用 device_map 加载模型后不要手动设置设备。因此,在该行之后应避免对模型或模型的任何子模块进行任何设备分配 - 除非你知道自己在做什么。
请记住,加载量化模型会自动将模型的其他子模块转换为 float16 数据类型。你可以通过将 torch_dtype=dtype 传递给 from_pretrained 方法来修改此行为 (例如,如果你希望在层规一化算子中使用 float32 )。
高级用法
你可以使用 4 比特量化的不同变体,例如 NF4 (NormalFloat4 (默认) ) 或纯 FP4 量化。从理论分析和实证结果来看,我们建议使用 NF4 量化以获得更好的性能。
其他选项包括 bnb_4bit_use_double_quant ,它在第一轮量化之后会进行第二轮量化,为每个参数额外节省 0.4 比特。最后是计算类型,虽然 4 比特 bitsandbytes 以 4 比特存储权重,但计算仍然以 16 或 32 比特进行,这里可以选择任意组合 (float16、bfloat16、float32 等)。
如果使用 16 比特计算数据类型 (默认 torch.float32),矩阵乘法和训练将会更快。用户应该利用 transformers 中最新的 BitsAndBytesConfig 来更改这些参数。下面是使用 NF4 量化加载 4 比特模型的示例,例子中使用了双量化以及 bfloat16 计算数据类型以加速训练:
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
更改计算数据类型
如上所述,你还可以通过更改 BitsAndBytesConfig 中的 bnb_4bit_compute_dtype 参数来更改量化模型的计算数据类型。
import torch
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
嵌套量化
要启用嵌套量化,你可以使用 BitsAndBytesConfig 中的 bnb_4bit_use_double_quant 参数。这将会在第一轮量化之后启用第二轮量化,以便每个参数额外节省 0.4 比特。我们在上文提及的微调 Google Colab 笔记本中也使用了此功能。
from transformers import BitsAndBytesConfig
double_quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
)
model_double_quant = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=double_quant_config)
当然,正如本节开头提到的,所有这些功能都是可任意组合的。你可以将所有这些参数组合在一起,找到最适合你的配置。经验法则是: 如果内存有限制,使用双量化; 使用 NF4 以获得更高的精度; 使用 16 比特浮点加快微调速度。作为一个例子,在 推理演示应用 中,我们使用嵌套量化、bfloat16 计算数据类型以及 NF4 量化在单个 16GB GPU 中使用 4 比特完成了对 gpt-neo-x-20b (40GB) 模型的拟合。
常见问题
本节我们来回答一些常见问题。
FP4 量化有硬件要求吗?
请注意,此方法仅与 GPU 兼容,目前尚无法在 CPU 上对模型进行 4 比特量化。在 GPU 中,此方法没有任何硬件要求,只要安装了 CUDA>=11.2,任何 GPU 都可以用于运行 4 比特量化。
另请记住,计算不是以 4 比特完成的,仅仅是权重和激活被压缩为该格式,而计算仍在指定的或者原始数据类型上进行。
支持哪些模型?
与 这篇博文 中介绍的 LLM.int8 集成类似,我们的集成严重依赖于 accelerate 库。因此,任何支持 accelerate 库加载的模型 (即调用 from_pretrained 时支持 device_map 参数) 都可以进行 4 比特量化。另请注意,这与模态完全无关,只要可以使用 device_map 参数加载模型,就可以量化它们。
对于文本模型,截至本文撰写时,最常用的架构都是支持的,例如用于纯文本的 Llama、OPT、GPT-Neo、GPT-NeoX,用于多模态的 Blip2 等。
截至本文撰写时,支持 accelerate 的模型有:
[
'bigbird_pegasus', 'blip_2', 'bloom', 'bridgetower', 'codegen', 'deit', 'esm',
'gpt2', 'gpt_bigcode', 'gpt_neo', 'gpt_neox', 'gpt_neox_japanese', 'gptj', 'gptsan_japanese',
'lilt', 'llama', 'longformer', 'longt5', 'luke', 'm2m_100', 'mbart', 'mega', 'mt5', 'nllb_moe',
'open_llama', 'opt', 'owlvit', 'plbart', 'roberta', 'roberta_prelayernorm', 'rwkv', 'switch_transformers',
't5', 'vilt', 'vit', 'vit_hybrid', 'whisper', 'xglm', 'xlm_roberta'
]
请注意,如果你最喜欢的模型不在列表中,你可以提交一个 PR 或在 transformers 中提交一个问题,以添加对该架构的 accelerate 加载的支持。
我们可以训练 4 比特 / 8 比特模型吗?
对这些模型进行全模型 4 比特训练是不可能的。但是,你可以利用参数高效微调 (PEFT) 来训练这些模型,即在基础模型之上训练新增部分如适配器。QLoRA 论文就是这么做的,Hugging Face 的 PEFT 库也正式支持了该方法。我们提供了相应的 微调笔记本。如果大家想要复现论文的结果,还可以查阅 QLoRA 代码库。
这项工作还有什么其他意义?
这项工作可以为社区和人工智能研究带来一些积极的影响,因为它可以影响很多可能的用法或应用场景。在 RLHF (基于人类反馈的强化学习) 中,可以加载单个 4 比特基础模型,并在其上训练多个适配器,一个用于奖励建模,另一个用于价值策略训练。我们很快就会发布关于此用法的更详细的博文。
我们还针对这种量化方法对在消费类硬件上训练大模型的影响涉及了一些基准测试。我们在英伟达 T4 (16GB) 上对 2 种不同的架构 Llama 7B (fp16 时,模型大小为 15GB) 和 Llama 13B (fp16 时,模型大小为 27GB) 进行了多次微调实验,结果如下:
| 模型 | 半精度模型大小 (GB) | 硬件 / 总显存 | 量化方法 (CD = 计算数据类型 / GC = 梯度 checkpointing / NQ = 双量化) | batch size | 梯度累积步数 | 优化器 | 序列长度 | 结果 |
|---|---|---|---|---|---|---|---|---|
| <10B 模型 | ||||||||
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | LLM.int8 (8-bit) + GC | 1 | 4 | AdamW | 512 | 无 OOM |
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | LLM.int8 (8-bit) + GC | 1 | 4 | AdamW | 1024 | OOM |
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + bf16 CD + no GC | 1 | 4 | AdamW | 512 | 无 OOM |
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + FP4 + bf16 CD + no GC | 1 | 4 | AdamW | 512 | 无 OOM |
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + bf16 CD + no GC | 1 | 4 | AdamW | 1024 | OOM |
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + FP4 + bf16 CD + no GC | 1 | 4 | AdamW | 1024 | OOM |
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + bf16 CD + GC | 1 | 4 | AdamW | 1024 | 无 OOM |
| 10B+ 模型 | ||||||||
| decapoda-research/llama-13b-hf | 27GB | 2xNVIDIA-T4 / 32GB | LLM.int8 (8-bit) + GC | 1 | 4 | AdamW | 512 | 无 OOM |
| decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | LLM.int8 (8-bit) + GC | 1 | 4 | AdamW | 512 | OOM |
| decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + FP4 + bf16 CD + no GC | 1 | 4 | AdamW | 512 | OOM |
| decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + FP4 + fp16 CD + no GC | 1 | 4 | AdamW | 512 | OOM |
| decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + fp16 CD + GC | 1 | 4 | AdamW | 512 | 无 OOM |
| decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + fp16 CD + GC | 1 | 4 | AdamW | 1024 | OOM |
| decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + fp16 CD + GC + NQ | 1 | 4 | AdamW | 1024 | 无 OOM |
我们使用了 TRL 库中最新的 SFTTrainer ,你可以在 此处 找到基准测试脚本。
演示空间
想试试论文中的 Guananco 模型的话,可以玩玩这个 演示空间,我们还把它直接嵌入到了下面供你直接把玩。
致谢
HF 团队感谢华盛顿大学参与该项目的所有人员,感谢他们向社区贡献了他们的工作。
作者还要感谢 Pedro Cuenca 帮忙审阅了博文,并感谢 Olivier Dehaene 和 Omar Sanseviero 对在 HF Hub 上集成该论文提供了快速而有力的支持。
英文原文: https://hf.co/blog/4bit-transformers-bitsandbytes
原文作者: Younes Belkada,Tim Dettmers,Artidoro Pagnoni,Sylvain Gugger,Sourab Mangrulkar
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校/排版: zhongdongy (阿东)
用 bitsandbytes、4 比特量化和 QLoRA 打造亲民的 LLM的更多相关文章
- 全场景AI推理引擎MindSpore Lite, 助力HMS Core视频编辑服务打造更智能的剪辑体验
移动互联网的发展给人们的社交和娱乐方式带来了很大的改变,以vlog.短视频等为代表的新兴文化样态正受到越来越多人的青睐.同时,随着AI智能.美颜修图等功能在图像视频编辑App中的应用,促使视频编辑效率 ...
- 草莓糖CMT依旧强势,数字货币量化分析[2018-05-29]
[分析时间]2018-05-29 17:45 [报告内容]1 BTC中期 MA 空头排列中长 MA 空头排列长期 MA 空头排列 2 LTC中期 MA 空头排列中长 ...
- WeQuant教程—1.2 从简单的量化系统开始
你大概知道量化的思想最早在古巴比伦人计算行星轨迹的时候就已经诞生(算术运算),后来借助古希腊的形式化逻辑的发展,人们日益能从量化的思想中提炼和描述自然规律并运用到生产之中.不过,基于量化的思想打造一个 ...
- Megengine量化
Megengine量化 量化指的是将浮点数模型(一般是32位浮点数)的权重或激活值用位数更少的数值类型(比如8位整数.16位浮点数)来近似表示的过程. 量化后的模型会占用更小的存储空间,还能够利用许多 ...
- WIN32下使用DirectSound接口的简单音频播放器(支持wav和mp3)
刚好最近接触了一些DirectSound,就写了一个小程序练练手,可以用来添加播放基本的wav和mp3音频文件的播放器.界面只是简单的GDI,dxsdk只使用了DirectSound8相关的接口. D ...
- YCbCr 编码格式(YUV)---转自Crazy Bingo的博客
YCbCr是DVD.摄像机.数字电视等消费类视频产品中,常用的色彩编码方案. YCbCr 有时会称为 YCC..Y'CbCr 在模拟分量视频(analog component video)中也常被称为 ...
- YUV格式&像素
一幅彩色图像的基本要素是什么? 说白了,一幅图像包括的基本东西就是二进制数据,其容量大小实质即为二进制数据的多少.一幅1920x1080像素的YUV422的图像,大小是1920X1080X2=4147 ...
- YUV YCbCr
一,介绍 YUV是一种颜色空间 其中“Y”表示明亮度(Luminance或Luma),也就是灰阶值: 而“U”和“V” 表示的则是色度(Chrominance或Chroma),作用是描述影像色彩及饱和 ...
- Sensor信号输出YUV、RGB、RAW DATA、JPEG【转】
本文转载自:http://blog.csdn.net/southcamel/article/details/8305873 简单来说,YUV: luma (Y) + chroma (UV) 格式, 一 ...
- YUV主要采样格式理解
主要的采样格式有YCbCr 4:2:0.YCbCr 4:2:2.YCbCr 4:1:1和 YCbCr 4:4:4.其中YCbCr 4:1:1 比较常用,其含义为:每个点保存一个 8bit 的亮度值(也 ...
随机推荐
- WebSocket魔法师:打造实时应用的无限可能
1.背景 在开发一些前端页面的时候,总是能接收到这样的需求:如何保持页面并实现自动更新数据呢?以往的常规做法,是前端使用定时轮询后端接口,获取响应后重新渲染前端页面,这种做法虽然能达到类似的效果,但是 ...
- 聊聊Flink必知必会(五)
聊聊Flink的必知必会(三) 聊聊Flink必知必会(四) 从源码中,根据关键的代码,梳理一下Flink中的时间与窗口实现逻辑. WindowedStream 对数据流执行keyBy()操作后,再调 ...
- Python小白入门指南:避免踩雷的10大错误!
hello,大家好!新手小白踏入 Python 的大门有点像冒险,但别担心,我已经整理了一个超实用的入门指南,帮你规避学习过程中的十大雷区.这里有关于 Python 的错误你应该注意的建议,一起来看看 ...
- ConfigureAwait in .NET8
ConfigureAwait in .NET8 ConfigureAwait(true) 和 ConfigureAwait(false) 首先,让我们回顾一下原版 ConfigureAwait 的语义 ...
- 生产实践:Redis与Mysql的数据强一致性方案
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享. 数据库和Redis如何保持强一致性,这篇文章告诉你 目的 Redis和Msql来保持数据同步,并且强一致,以此来提高对应接 ...
- [AGC030D] Inversion Sum
Problem Statement You are given an integer sequence of length $N$: $A_1,A_2,...,A_N$. Let us perform ...
- 自定义线程池将异常"吃了"
今天在做项目时,写了一个使用自定义线程池执行远程调用 // 删除购物车信息 corePoolExecutor.submit(() -> { try { cartFeignClient.delet ...
- 华企盾DSC导致导出文件报错常见处理方法
1.导出文件的进程和打开该文件的进程启用OLE控制是否都是未勾选,以及启用虚拟重定向是否设置一致(要么都勾选要么都不勾) 2.用procmon监控个人模式下导出非加密的文件,搜索writefile的进 ...
- 介绍一个prometheus监控数据生成工具
prometheus-data-generator Prometheus数据模拟工具旨在通过配置文件模拟Prometheus数据,用于测试和开发目的.该工具允许您生成用于测试和开发的合成数据. 配置 ...
- 使用WPF开发自定义用户控件,以及实现相关自定义事件的处理
在前面随笔<使用Winform开发自定义用户控件,以及实现相关自定义事件的处理>中介绍了Winform用户自定义控件的处理,对于Winform自定义的用户控件来说,它的呈现方式主要就是基于 ...