redis之列表 redis之hash redis其他操作 redis管道 django中使用redis celery介绍和安装 celery快速使用 celery包结构
昨日回顾
# 1 登录注册前端
-登录
-手机验证码登录---》输入框输入手机号---》监听失去焦点事件---》手机号正则校验(js),查询手机号是否存在----》发送验证码的按钮可以点击---》点击发送验证码按钮---》ajax 发送验证码---》起了个定时任务---》手机收到了验证码,填入验证码框-----》点击登录按钮----》向后端发送登录ajax请求----》返回给前端token和username----》前端保存到cookie中----》子传父,关闭了登录模态框----》在Header.vue 取了一下token和username
-多方式登录---》输入用户名和密码后----》点击登录--》后端登录成功,返回username和token---》后面的同上
-注册
-输入手机号---》监听失去焦点事件---》手机号正则校验(js),查询手机号是否存在-如果不存在---》发送验证码的按钮可以点击---》点击发送验证码按钮---》ajax 发送验证码---》起了个定时任务---》手机收到了验证码,填入验证码框-----》填入密码---》点击注册---》调用注册接口完成注册----》子传父---》Register.vue---->显示出Login.vue
# 2 redis 介绍
-数据库,非关系型数据库,缓存数据库,key-value形式存储,数据都在内存中,有5大数据类型,速度非常快,数据操作是单线程,不存在并发安全的问题
-redis的缓存更新策略
-为什么这么快:
1 纯内存操作
2 高性能的网络模型 IO多路复用(epoll)
3 单线程,不存在线程间切换
-redis版本
7.x 最新
6.x 从它后,多进程,多线程架构
5.x及之前 单进程单线程架构
-进程:资源分配的最小单位,一个程序运行起来,可能一个进程,也可能多个进程
-线程:cpu调度的最小单位,遇到io操作,操作系统层面切换
-协程:单线程下的并发,程序层面控制,遇到io操作,切换到别的任务执行
# 3 安装redis
-mac 编译完成了,bin路径下 redis-server redis-cli
-linux 编译安装
-win 专门的安装包
一路下一步
-安装完成会有两个命令:启动服务端,启动客户端 cs架构的软件
-客户端和服务端在同一台机器上
-本地的客户端可以连接远程的服务器
-mysql 也是cs架构软件
-pymysql :是mysql的客户端
-Navicate:是mysql客户端
-go语言操作mysql:是mysql客户端
-启动redis服务
-redis-server 指定配置文件
-使用服务启动
-客户端连接
-cmd中使用redis-cli
-图形化界面
-python的redis模块操作redis
# 4 python连接redis
-普通连接
-连接池连接:单例模式
-django 使用mysql连接池
# 5 redis 5大数据类型之字符串 value值是字符串
-get
-set
-strlen
-mset
-mget
-getrang
....
redis的缓存更新策略。

redis使用IO多路复用网络模型。实现了一条线程就可以监听很多请求。

单线程下实现并发,遇到IO操作就切换到别的任务。(协程)

协程不一定比多线程效率高。多线程遇到IO,会进行操作系统层面的切换,可能会切换到别的进程中的任务,这也就导致了效率低下。
今日内容
1 redis之列表
'''
1 lpush(name, values)
2 rpush(name, values) 表示从右向左操作
3 lpushx(name, value)
4 rpushx(name, value) 表示从右向左操作
5 llen(name)
6 linsert(name, where, refvalue, value))
7 r.lset(name, index, value)
8 r.lrem(name, value, num)
9 lpop(name)
10 rpop(name) 表示从右向左操作
11 lindex(name, index)
12 lrange(name, start, end)
13 ltrim(name, start, end)
14 rpoplpush(src, dst)
15 blpop(keys, timeout)
16 r.brpop(keys, timeout),从右向左获取数据
17 brpoplpush(src, dst, timeout=0)
'''
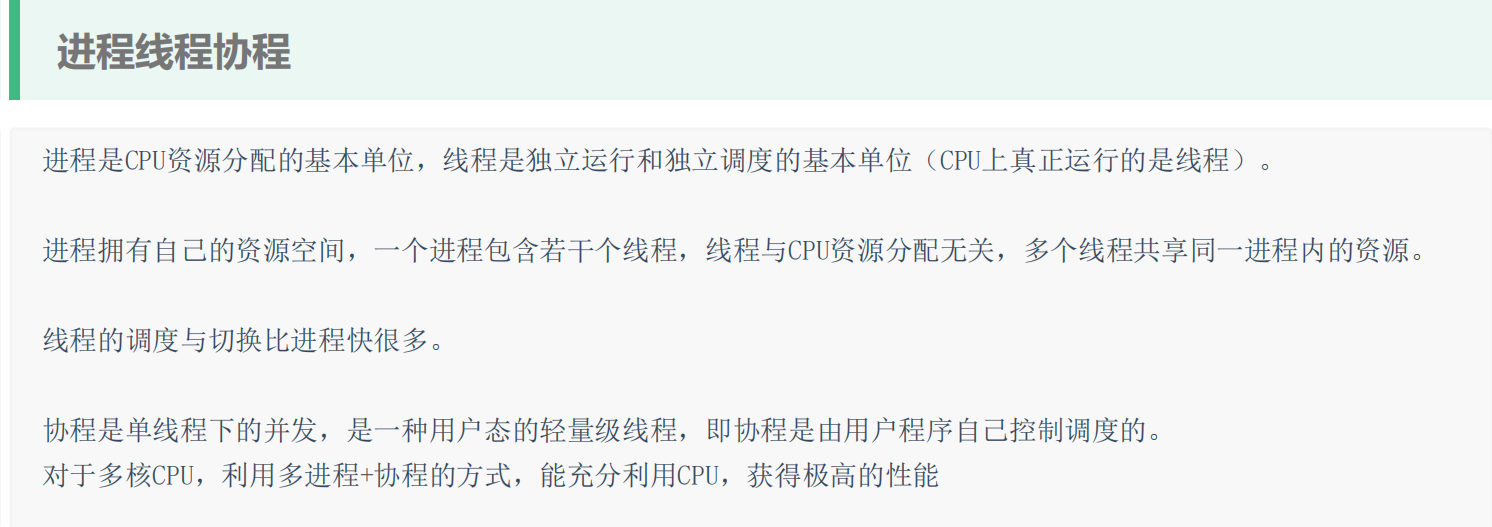
import redis
conn = redis.Redis()
# 1 lpush(name, values) 从错侧插入
# conn.lpush('girls', '刘亦菲', '迪丽热巴')
# conn.lpush('girls', '周淑怡')
# 2 rpush(name, values) 表示从右向左操作
# conn.rpush('girls', '小红')
# 3 lpushx(name, value)
# conn.lpushx('boys','小刚')
# conn.lpush('boys','小刚')
# conn.lpushx('girls','小刚')
# 4 rpushx(name, value) 表示从右向左操作
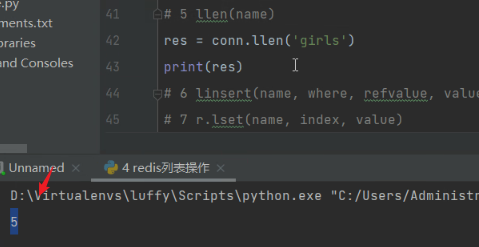
# 5 llen(name)
# res = conn.llen('girls')
# print(res)
# 6 linsert(name, where, refvalue, value))
# conn.linsert('girls','before','迪丽热巴','古力娜扎')
# conn.linsert('girls', 'after', '小红', '小绿')
# conn.linsert('girls', 'after', '小黑', '小嘿嘿') # 没有标杆,插入不进去
# 7 r.lset(name, index, value) # 按位置改值
# conn.lset('girls',1,'xxx')
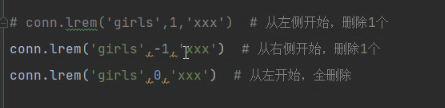
# 8 r.lrem(name, value, num)
# conn.lrem('girls',1,'xxx') # 从左侧开始,删除1个
# conn.lrem('girls',-1,'xxx') # 从右侧开始,删除1个
# conn.lrem('girls',0,'xxx') # 从左开始,全删除
# 9 lpop(name)
# res=conn.lpop('girls')
# print(res)
# 10 rpop(name) 表示从右向左操作
# 11 lindex(name, index)
# res = str(conn.lindex('girls', 1), encoding='utf-8')
# print(res)
# 12 lrange(name, start, end)
# res=conn.lrange('girls',0,0) # 前闭后闭区间
# print(res)
# 13 ltrim(name, start, end)
# conn.ltrim('girls',2,3)
# 14 rpoplpush(src, dst)
# 15 blpop(keys, timeout) # 记住 ,可以做消息队列使用 阻塞式弹出,如果没有,就阻塞
# res=conn.blpop('boys')
# print(res)
# 16 r.brpop(keys, timeout),从右向左获取数据
# 17 brpoplpush(src, dst, timeout=0)
conn.close()
'''
lpush
lpop
llen
lrange
'''
lpush:从左侧开始插入
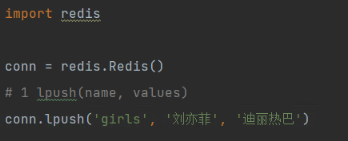
查看结果:
rpush:从右侧开始插入

查看:

lpushx:key值存在才能左侧插入

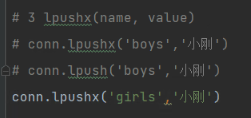
查看:
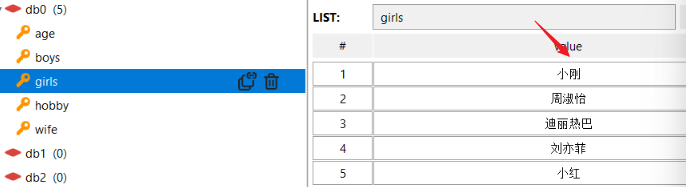
llen:
查看:
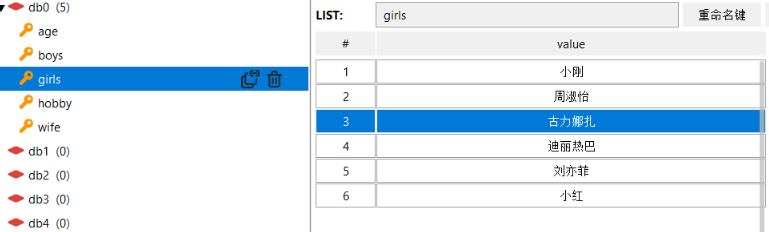
linsert:
第一个参数:key
第二个参数:代表插入的是前还是后(before\after)
第三个参数是参照值。

lset:按照位置修改值,如下修改索引为1的值。
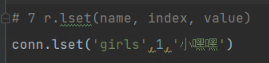
索引是从0开始的。
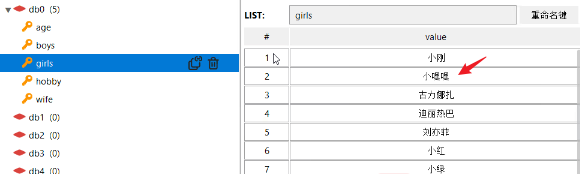
这里的数字,是图形化界面提供的,不是真正的索引。
lrem:删除

从左侧开始,删除一个xxx。
lpop:左侧弹出
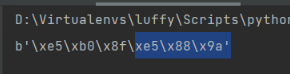
lindex:按照索引,获取值

lrange:
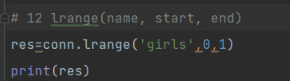
redis前闭后闭区间,会拿出两个值。

ltrim:
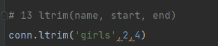
只剩余2-4区间的值。
rpoplpush:需要两个列表。
blpop:

如果没有值,程序会阻塞。等待另外一个程序插入值。当有值插入的时候,该程序再执行弹出操作。
通过blpop可以实现简单的消息队列(作为消息队列效率不高)。
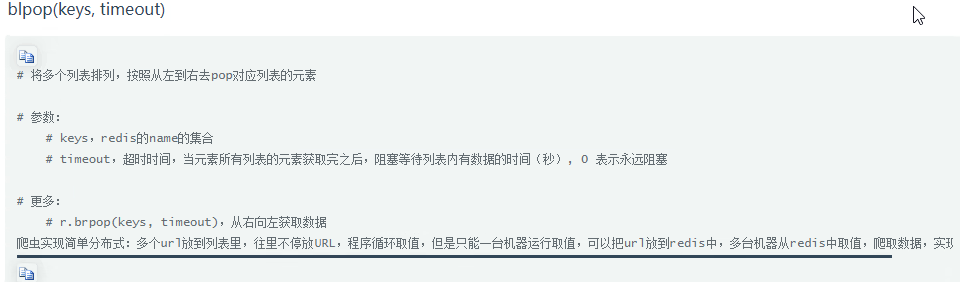
列表中的数据过大: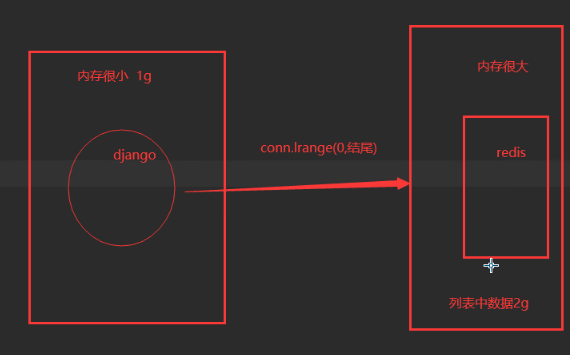
生成器实现自定义增量迭代,避免内存崩了:
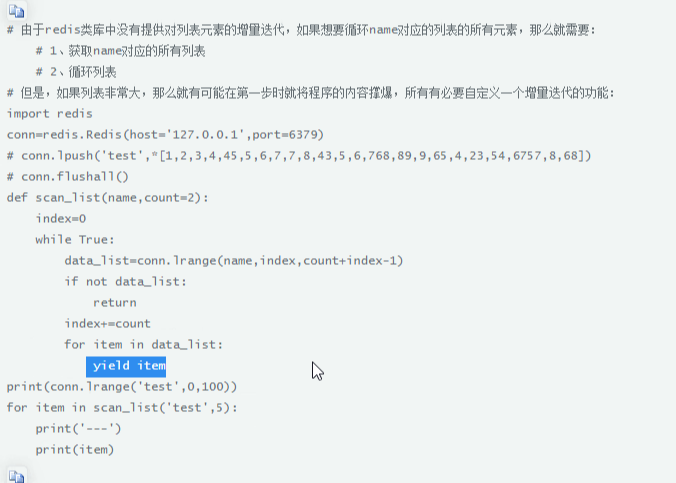
2 redis之hash
'''
1 hset(name, key, value)
2 hmset(name, mapping)
3 hget(name,key)
4 hmget(name, keys, *args)
5 hgetall(name)
6 hlen(name)
7 hkeys(name)
8 hvals(name)
9 hexists(name, key)
10 hdel(name,*keys)
11 hincrby(name, key, amount=1)
12 hincrbyfloat(name, key, amount=1.0)
13 hscan(name, cursor=0, match=None, count=None)
14 hscan_iter(name, match=None, count=None)
'''
import redis
conn = redis.Redis()
# 1 hset(name, key, value)
# conn.hset('userinfo','name','lqz')
# conn.hset('userinfo',mapping={'age':19,'hobby':'篮球'})
# 2 hmset(name, mapping) # 批量设置,被弃用了,以后都使用hset
# conn.hmset('userinfo2',{'age':19,'hobby':'篮球'})
# 3 hget(name,key)
# res=conn.hget('userinfo','name')
# print(res)
# 4 hmget(name, keys, *args)
# res=conn.hmget('userinfo',['name','age'])
# res = conn.hmget('userinfo', 'name', 'age')
# print(res)
# 5 hgetall(name) # 慎用
# res=conn.hgetall('userinfo')
# print(res)
# 6 hlen(name)
# res=conn.hlen('userinfo')
# print(res)
# 7 hkeys(name)
# res=conn.hkeys('userinfo')
# print(res)
# 8 hvals(name)
# res=conn.hvals('userinfo')
# print(res)
# 9 hexists(name, key)
# res = conn.hexists('userinfo', 'name')
# res = conn.hexists('userinfo', 'name1')
# print(res)
# 10 hdel(name,*keys)
# res = conn.hdel('userinfo', 'age')
# print(res)
# 11 hincrby(name, key, amount=1)
conn.hincrby('userinfo', 'age', 2)
# article_count ={
# '1001':0,
# '1002':2,
# '3009':9
# }
# 12 hincrbyfloat(name, key, amount=1.0)
# hgetall 会一次性全取出,效率低,可以能占内存很多
# 分批获取,hash类型是无序
# 插入一批数据
# for i in range(1000):
# conn.hset('hash_test','id_%s'%i,'鸡蛋_%s号'%i)
# res=conn.hgetall('hash_test') # 可以,但是不好,一次性拿出,可能占很大内存
# print(res)
# 13 hscan(name, cursor=0, match=None, count=None) # 它不单独使用,拿的数据,不是特别准备
# res = conn.hscan('hash_test', cursor=0, count=5)
# print(len(res[1])) #(数字,拿出来的10条数据) 数字是下一个游标位置
# 咱们用这个,它内部用了hscan,等同于hgetall 所有数据都拿出来,count的作用是,生成器,每次拿count个个数
# 14 hscan_iter(name, match=None, count=None)
res=conn.hscan_iter('hash_test',count=10)
# print(res) # generator 只要函数中有yield关键字,这个函数执行的结果就是生成器 ,生成器就是迭代器,可以被for循环
# for i in res:
# print(i)
'''
hset
hget
hmget
hlen
hdel
hscan_iter 获取所有值,但是省内存 等同于hgetall
'''
conn.close()
hset:
hmset:准备弃用
hmget:
hgetall:
hlen:
hkeys:拿出所有键
hvals:拿出所有值
hexists:
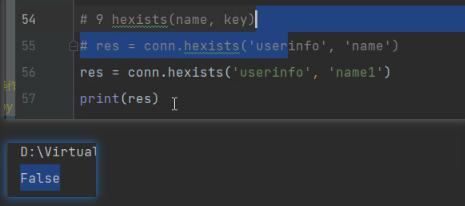
hdel:返回值是0、1
hincrgy:自增,不写默认1
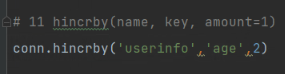
文章阅读量:
hscan:分批获取、hash类型是无序的
查看: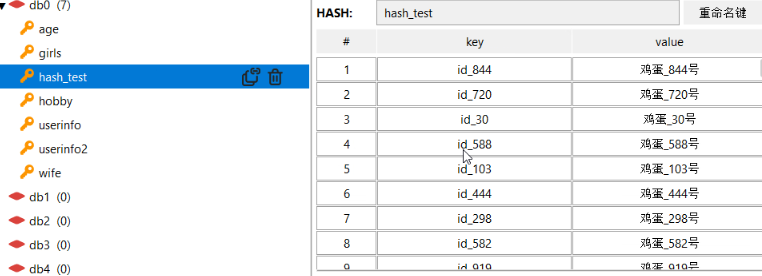 hgetall会一次性全部取出,效率低,可能占很多内存。
hgetall会一次性全部取出,效率低,可能占很多内存。
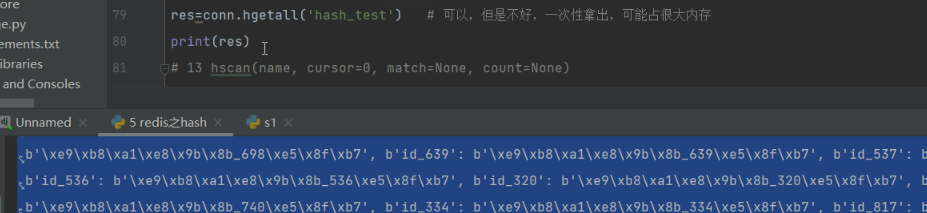
使用hscan:
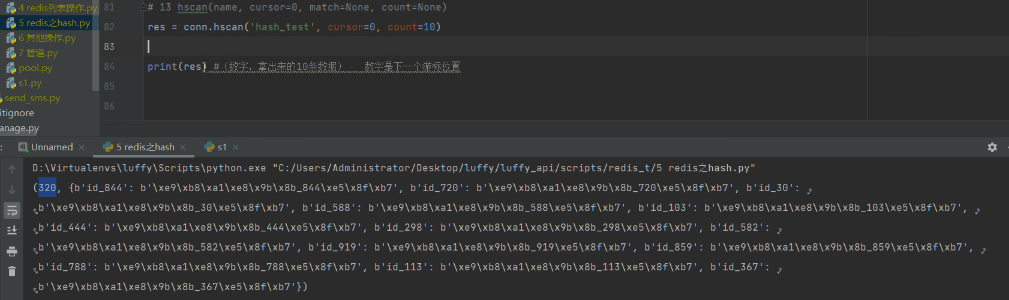
指定了count但是获取的不是我们预期的条数(可能多或少几条):
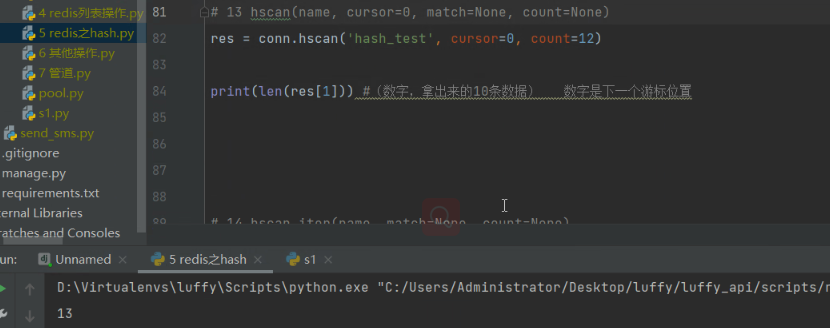
hscan是给hscan_iter用的:
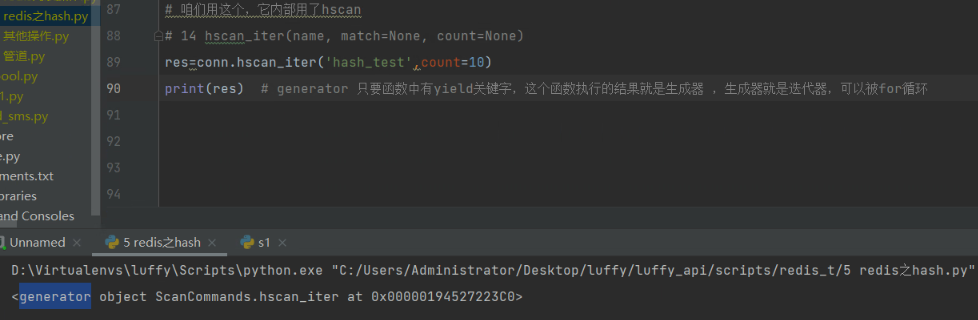
可以获取所有数据:
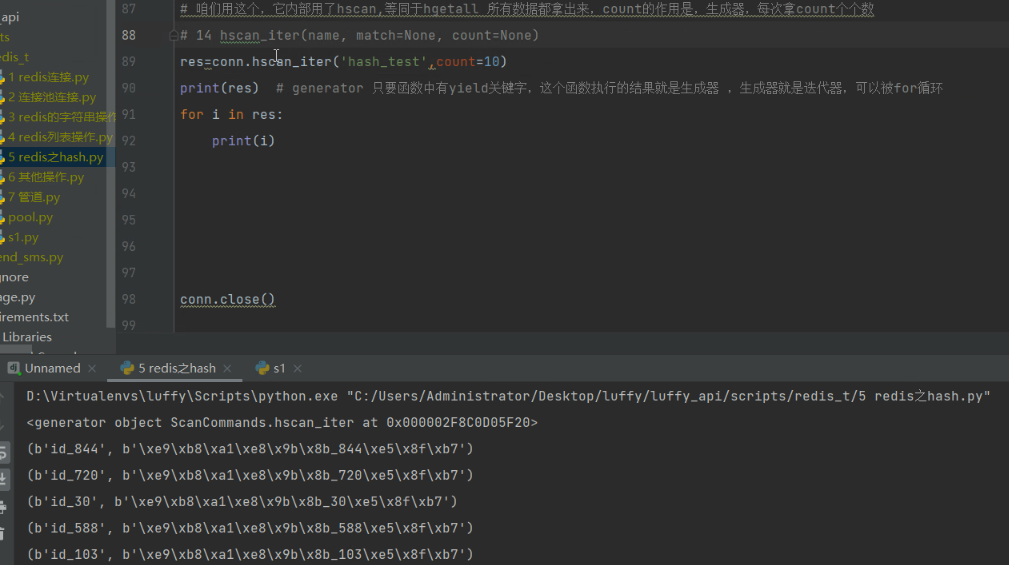
hscan_iter内部调用了hscan。
3 redis其他操作
''' 通用操作,不指定类型,所有类型都支持
1 delete(*names)
2 exists(name)
3 keys(pattern='*')
4 expire(name ,time)
5 rename(src, dst)
6 move(name, db))
7 randomkey()
8 type(name)
'''
import redis
conn = redis.Redis()
# 1 delete(*names)
# conn.delete('name', 'userinfo2')
# conn.delete(['name', 'userinfo2']) # 不能用它
# conn.delete(*['name', 'userinfo2']) # 可以用它
# 2 exists(name)
# res=conn.exists('userinfo')
# print(res)
# 3 keys(pattern='*')
# res=conn.keys('w?e') # ?表示一个字符, * 表示多个字符
# print(res)
# 4 expire(name ,time)
# conn.expire('userinfo',3)
# 5 rename(src, dst)
# conn.rename('hobby','hobby111')
# 6 move(name, db))
# conn.move('hobby111',8)
# 7 randomkey()
# res=conn.randomkey()
# print(res)
# 8 type(name)
# print(conn.type('girls'))
print(conn.type('age'))
conn.close()
匹配:
设置过期时间为3s:

移动,换个数据库:

随机弹出一个key:
4 redis 管道
# 事务---》四大特性:
-原子性
-一致性
-隔离性
-持久性
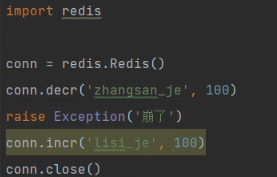
# redis支持事务吗 单实例才支持所谓的事物,支持事务是基于管道的
-执行命令 一条一条执行
-张三 金额 -100 conn.decr('zhangsan_je',100)
挂了
-你 金额 100 conn.incr('李四_je',100)
- 把这两条命令,放到一个管道中,先不执行,执行excute,一次性都执行完成
conn.decr('zhangsan_je',100) conn.incr('李四_je',100)
# 如何使用
import redis
conn = redis.Redis()
p=conn.pipeline(transaction=True)
p.multi()
p.decr('zhangsan_je', 100)
# raise Exception('崩了')
p.incr('lisi_je', 100)
p.execute()
conn.close()
redis的事务只支持四大特性的其中之几个。redis通过管道可以支持事务。通过管道一次性执行多个命令,来实现事务。
正常情况下:
使用管道:
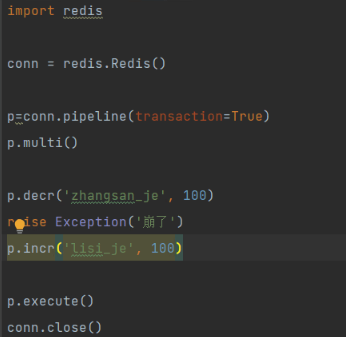
·批量放入管道,最后再一次性执行。
5 django中使用redis
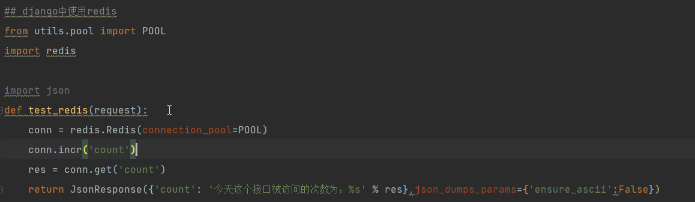
## 方式一:自定义包方案(通用的,不针对与框架,所有框架都可以用)
-第一步:写一个pool.py
import redis
POOL = redis.ConnectionPool(max_connections=100)
-第二步:以后在使用的地方,直接导入使用即可
conn = redis.Redis(connection_pool=POOL)
conn.incr('count')
res = conn.get('count')
## 方式二:django 方案,
-方案一:django的缓存使用redis 【推荐使用】
-settings.py 中配置
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100}
# "PASSWORD": "123",
}
}
}
-在使用redis的地方:cache.set('count', res+1)
-pickle序列化后,存入的
-方案二:第三方:django-redis模块
from django_redis import get_redis_connection
def test_redis(request):
conn=get_redis_connection()
print(conn.get('count'))
return JsonResponse({'count': '今天这个接口被访问的次数为:%s'}, json_dumps_params={'ensure_ascii': False})
方式一:直接导入
方式二:通过django使用redis
django配置文件:
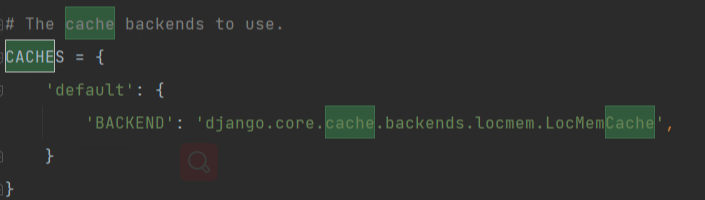
需要安装第三方包,让django使用redis做缓存:
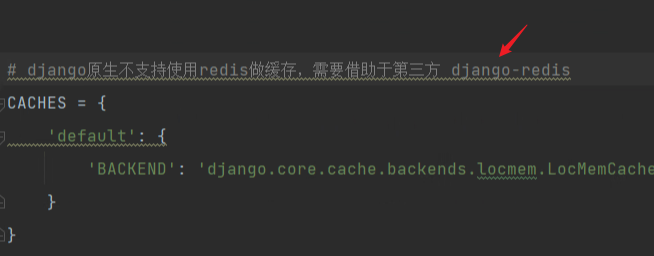
使用:

查看:
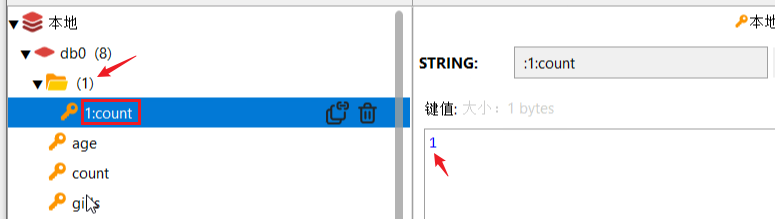
会单独生成一个 文件夹,不会和原来的redis的数据的key冲突。
pickle序列化,将对象存储到缓存:
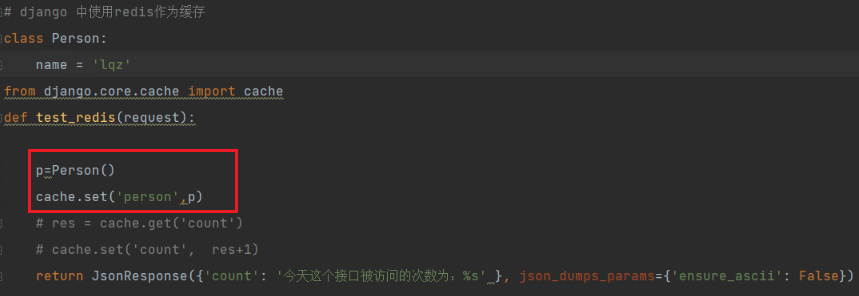
查看:这是redis的字符串类型。

取出对象使用:
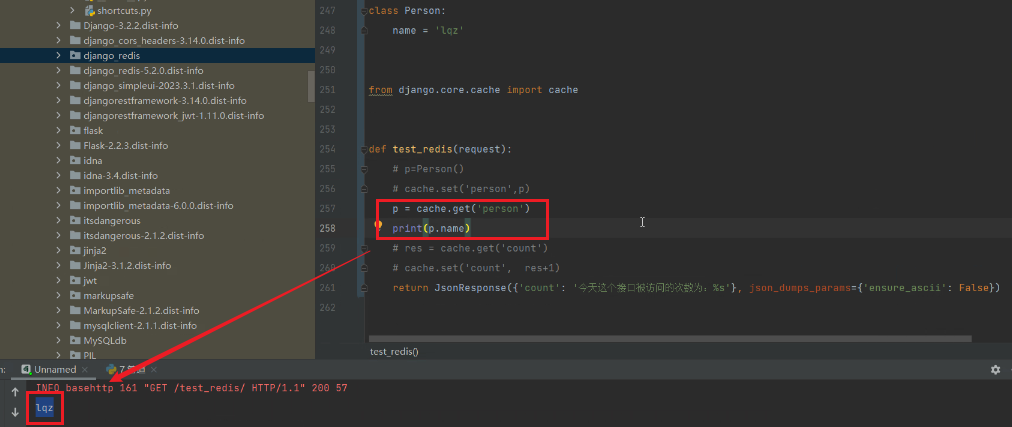
为什么把类名定义到函数内pickle模块会报错。因为pickle模块在全局作用域找不到类对象,类对象只在局部作用域,所以没法做序列化反序列化。

使用``get_redis_connection`方法,从配置文件配置的连接池中获取一个连接:

6 celery介绍和安装
# Celery 是什么
-翻译过来是 芹菜 的意思,跟芹菜没有关系
-框架:服务,python的框架,跟django无关
-能用来做什么
-1 异步任务
-2 定时任务
-3 延迟任务
# 理解celery的运行原理
"""
1)可以不依赖任何服务器,通过自身命令,启动服务
2)celery服务为为其他项目服务提供异步解决任务需求的
注:会有两个服务同时运行,一个是项目服务,一个是celery服务,项目服务将需要异步处理的任务交给celery服务,celery就会在需要时异步完成项目的需求
人是一个独立运行的服务 | 医院也是一个独立运行的服务
正常情况下,人可以完成所有健康情况的动作,不需要医院的参与;但当人生病时,就会被医院接收,解决人生病问题
人生病的处理方案交给医院来解决,所有人不生病时,医院独立运行,人生病时,医院就来解决人生病的需求
"""
# celery架构(Broker,backend 都用redis)
- 1 任务中间件 Broker(中间件),其他服务提交的异步任务,放在里面排队
-需要借助于第三方 redis rabbitmq
- 2 任务执行单元 worker 真正执行异步任务的进程
-celery提供的
- 3 结果存储 backend 结果存储,函数的返回结果,存到 backend中
-需要借助于第三方:redis,mysql
# 使用场景
异步执行:解决耗时任务
延迟执行:解决延迟任务
定时执行:解决周期(周期)任务
# celery 不支持win,通过eventlet支持在win上运行
# 补充
celery没有写消息队列,需要借助第三方。
worker可以跑在多个机器上。
7 celery快速使用
# 安装---》安装完成,会有一个可执行文件 celery
pip install celery
win:pip install eventlet
# 快速使用
######### 第一步:新建 main.py#########
from celery import Celery
# 提交的异步任务,放在里面
broker = 'redis://127.0.0.1:6379/1'
# 执行完的结果,放在这里
backend = 'redis://127.0.0.1:6379/2'
app = Celery('test', broker=broker, backend=backend)
@app.task
def add(a, b):
import time
time.sleep(3)
print('------',a + b)
return a + b
######### 第二步:其他程序,提交任务#########
res = add.delay(5,6) #原来add的参数,直接放在delay中传入即可
print(res) # f150d8a5-c955-478d-9343-f3b60d0d5bdb
### 第三步:启动worker
# 启动worker命令,win需要安装eventlet
win:
-4.x之前版本
celery worker -A 模块名 -l info -P eventlet
celery worker -A main -l info -P eventlet
-4.x之后
celery -A main worker -l info -P eventlet
mac:
celery -A main worker -l info
### 第四步:worker会执行消息中间件中的任务,把结果存起来####
### 第五步:咱们要看执行结果,拿到执行的结果#####
from main import app
from celery.result import AsyncResult
id = '51611be7-4914-4bd2-992d-749008e9c1a6'
if __name__ == '__main__':
a = AsyncResult(id=id, app=app)
if a.successful(): # 执行完了
result = a.get() #
print(result)
elif a.failed():
print('任务失败')
elif a.status == 'PENDING':
print('任务等待中被执行')
elif a.status == 'RETRY':
print('任务异常后正在重试')
elif a.status == 'STARTED':
print('任务已经开始被执行')
提交任务:同步调用
异步调用:
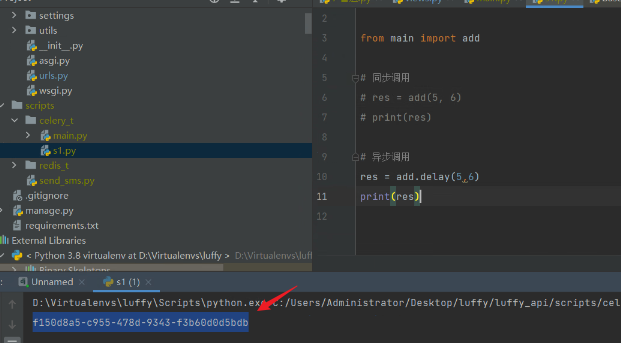
返回的是任务的id号。此时任务没有执行。在redis缓存中可以查看这个任务。
执行任务:命令行方式
老版本4.x之前celery:
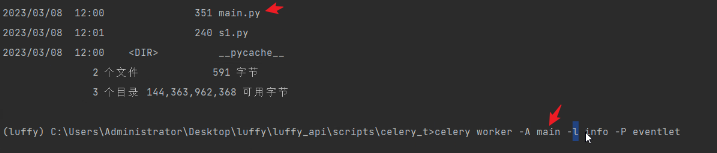
新版本:
运行完之后,结果会存放到redis结果存储的库中。
使用程序查看任务结果:
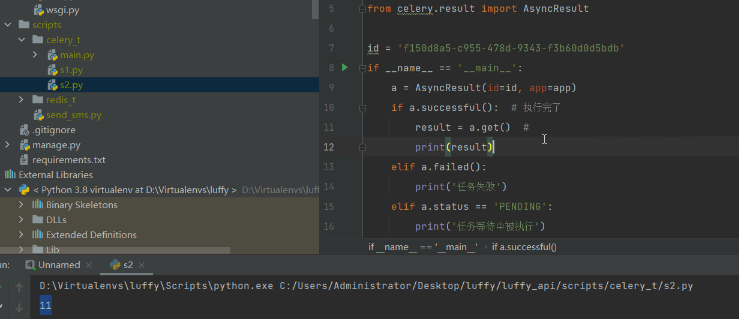
注意:第二步和第五步和celery没有必然联系,是在django中执行的。
8 celery包结构
使用包结构的原因:
两种celery任务结构:提倡用包管理,结构更清晰
# 如果 Celery对象:Celery(...) 是放在一个模块下的
1)终端切换到该模块所在文件夹位置:scripts
2)执行启动worker的命令:celery worker -A 模块名 -l info -P eventlet
注:windows系统需要eventlet支持,Linux与MacOS直接执行:celery worker -A 模块名 -l info
注:模块名随意
# 如果 Celery对象:Celery(...) 是放在一个包下的
1)必须在这个包下建一个celery.py的文件,将Celery(...)产生对象的语句放在该文件中
2)执行启动worker的命令:celery worker -A 包名 -l info -P eventlet
celery -A celery_task worker -l info -P eventlet
注:windows系统需要eventlet支持,Linux与MacOS直接执行:celery worker -A 模块名 -l info
注:包名随意
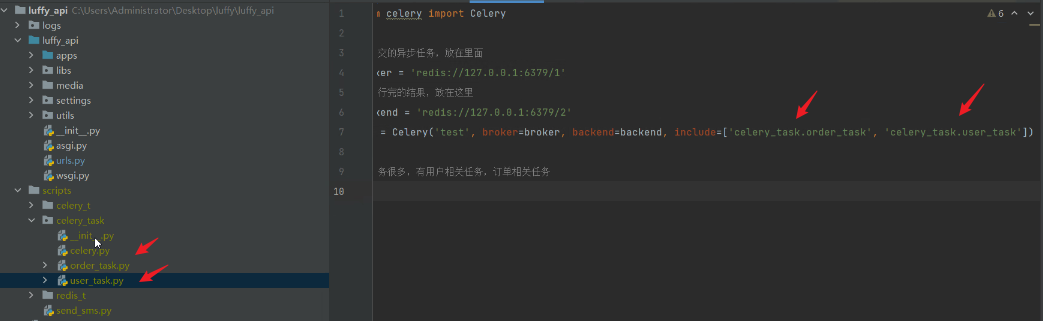
celery包结构:
project
├── celery_task # celery包
│ ├── __init__.py # 包文件
│ ├── celery.py # celery连接和配置相关文件,且名字必须交celery.py
│ └── tasks.py # 所有任务函数
├── add_task.py # 添加任务
└── get_result.py # 获取结果
############# 第一步:新建包 celery_task #############
# 在包下新建[必须叫celery]的py文件,celery.py 写代码
from celery import Celery
broker = 'redis://127.0.0.1:6379/1'
backend = 'redis://127.0.0.1:6379/2'
app = Celery('test', broker=broker, backend=backend, include=['celery_task.order_task', 'celery_task.user_task'])
##### 第二步:在包内部,写task,任务异步任务####
# order_task
from .celery import app
import time
@app.task
def add(a, b):
print('-----', a + b)
time.sleep(2)
return a + b
# user_task
from .celery import app
import time
@app.task
def send_sms(phone, code):
print("给%s发送短信成功,验证码为:%s" % (phone, code))
time.sleep(2)
return True
####第三步:启动worker ,包所在目录下
celery -A 包名 worker -l info -P eventlet
celery -A celery_task worker -l info -P eventlet
###第四步:其他程序 提交任务,被提交到中间件中,等待worker执行,因为worker启动了,就会被worker执行
from celery_task import send_sms
res=send_sms.delay('1999999', 8888)
print(res) # 7d39033c-4cc7-4af2-8d78-e62c277db183
### 第五步:worker执行完,结果存到backend中
### 第六步:我们查看结构
from celery_task import app
from celery.result import AsyncResult
id = '7d39033c-4cc7-4af2-8d78-e62c277db183'
if __name__ == '__main__':
a = AsyncResult(id=id, app=app)
if a.successful(): # 执行完了
result = a.get() #
print(result)
elif a.failed():
print('任务失败')
elif a.status == 'PENDING':
print('任务等待中被执行')
elif a.status == 'RETRY':
print('任务异常后正在重试')
elif a.status == 'STARTED':
print('任务已经开始被执行')
练习
1 redis 列表,hash,其他,管道,django中继承 代码都写一遍
---高级-----
2 安装celery 使用celery的包结构
-写一个run.py
循环打印
1 异步计算add
2 发送短信
3 查看短信发送结果
4 查看add异步的结果
用户选了发送短信 ,输入手机号,就可以异步给这个手机号发送短信
短信已发送
celery报错解决:
# 将celery打包使用
首先在项目路径创建celecy_task包,然后在包内创建celery.py文件:
1.这个文件必须叫celery。
2.然后就是编写broker和backend,让这两个连接到我的redis库,broker是负责将任务存储到任务队列、backend负责结果存储。
3.然后就是生成一个Celery对象赋值给变量app,通过include参数来注册我们的任务函数,这个include参数需要传入一个包含任务函数的列表。 比如:['celery_task.order_task']
4.然后再celery包内,编写任务函数py文件,需要注意的是任务函数被app.task装饰,并且任务函数的返回值需要是可序列化的。
5.然后导入使用即可比如:
from celery_task.user_task import send_sms
res_obj = send_sms.delay(传入参数)
需要注意的是res_obj这是一个对象,通过res_obj.id可以获取任务号
然后通过这个任务号,可以查询任务的结果存储。
# 在django中使用
如果需要在django中使用需要再celery加上代码
import os
os.environ.setdefault('DJANGO_SETTINGS_MODULE','luffy_server.settings.dev')
在任务函数中导入models的时候注意路径,这里很容易犯错。
# 定时任务
1.使用定时任务需要先配置好时区
# 时区
app.conf.timezone = 'Asia/Shanghai'
# 是否使用UTC
app.conf.enable_utc = False
2.要进行任务的定时配置,也就是规定是哪个任务为定时任务,这个任务多久执行一次
from celery.schedules import crontab
from datetime import timedelta
app.conf.beat_schedule = {
# 'send_sms': {
# 'task': 'celery_task.user_task.send_sms',
# # 'schedule': timedelta(seconds=3), # 时间对象
# # 'schedule': crontab(hour=8, day_of_week=1), # 每周一早八点
# 'schedule': crontab(hour=9, minute=43), # 每周一早八点
# 'args': ('18888888', '6666'),
# },
'update_banner': {
'task': 'celery_task.home_task.update_banner',
'schedule': timedelta(minutes=1), # 时间对象
},
}
3.配置好定时任务之后,需要启动beat,beat也是一个服务(进程),它的作用是按照你规定好的时间,定时将任务插入broker的任务列表
'''也就是说,使用定时任务,既需要开启worker,又需要开启beat'''
'''celery报错通常是因为导入路径不对引起的,所有注册都是从包名开始的。'''
redis之列表 redis之hash redis其他操作 redis管道 django中使用redis celery介绍和安装 celery快速使用 celery包结构的更多相关文章
- celery介绍、架构、快速使用、包结构,celery执行异步、延迟、定时任务,django中使用celery,定时更新首页轮播图效果实现,数据加入redis缓存的坑及解决
今日内容概要 celery介绍,架构 celery 快速使用 celery包结构 celery执行异步任务 celery执行延迟任务 celery执行定时任务 django中使用celery 定时更新 ...
- python连接redis、redis字符串操作、hash操作、列表操作、其他通用操作、管道、django中使用redis
今日内容概要 python连接redis redis字符串操作 redis之hash操作 redis之列表操作 redis其他 通用操作,管道 django中使用redis 内容详细 1.python ...
- 用Python来操作redis 以及在Django中使用redis
什么是Redis? Redis是一款开源的.高性能的键-值存储(key-value store).它常被称作是一款数据结构服务器(data structure server). Redis的键值可以包 ...
- redis的字符串操作以及在django中的使用
redis ----redis.MongoDB : 非关系型数据库 redis 存储在内存中 MongoDB 存储在硬盘中 l 简介 redis是一个key-value存储系统 , 支持持久化 ...
- Django day35 redis连接池,redis-list操作,django中使用redis,支付宝支付
一:redis连接池, 二:redis-list操作, 三:django中使用redis, 四:支付宝支付
- 在Django中使用redis:包括安装、配置、启动。
一.安装redis: 1.下载: wget http://download.redis.io/releases/redis-3.2.8.tar.gz 2.解压 tar -zxvf redis-.tar ...
- redis的介绍与操作及Django中使用redis缓存
redis VS mysql的区别 """ redis: 内存数据库(读写快).非关系型(操作数据方便) mysql: 硬盘数据库(数据持久化).关系型(操作数据间关系) ...
- 在django中使用redis
方式一 utils文件夹下,简历redis_pool.py import redis POOL = redis.ConnectionPool(host='127.0.0.1', port=6379,p ...
- 在django中使用Redis存取session
一.Redis的配置 1.django的缓存配置 # redis在django中的配置 CACHES = { "default": { "BACKEND": & ...
- django中使用redis
第一种 安装redis模块 1.1在app中定义一个redis的连接池的py文件 import redis POOL=redis.ConnectionPool(host='127.0.0.1',por ...
随机推荐
- Android 面试知识总结
Android知识点 1. 四大组件 分别是Activity.Service.ContentProvider.BroadcastReceiver. Activity称为活动,属于展示型组件,主要负责显 ...
- 一种全新的日志异常检测评估框架:LightAD
本文分享自华为云社区<[AIOps]一种全新的日志异常检测评估框架:LightAD,相关成果已被软工顶会ICSE 2024录用>,作者: DevAI. 深度学习(DL)虽然在日志异常检测中 ...
- Go笔记(2)-5种运算符总结
运算符 (1)算术运算符 (2)关系运算符 (3)逻辑运算符 (4)位运算符 (5)赋值运算符
- Android 图表开源库调研及使用示例
原文地址: Android图表开源库调研及使用示例 - Stars-One的杂货小窝 之前做的几个项目都是需要实现图表统计展示,于是做之前调研了下,做下记录 概述 AAChartCore-Kotlin ...
- LR(0)分析法
LR(0)是一种自底向上的语法分析方法.两个基本动作是移进和规约. 具体例子如下 已知文法G[E] (1) E→aА (2) E→bB (3) A→cА (4) A→d (5) B→cB (6) B→ ...
- bash shell笔记整理——which和whereis命令
which和whereis命令作用 which:显示给定命令所在路径 whereis:相比which更完善,显示命令路径.man文件路径(如果有).源代码路径 which语法 which [optio ...
- pytest框架学习-前置和后置setup和teardown
前置和后置 (1)setup和teardown,方法级 写在类中 方法级,每个用例都会执行setup和teardown. 相当于setup_method和teardown_method (2)setu ...
- stackoverflow怎么解决
stackoverflow怎么解决 栈溢出的可能原因: 函数递归调用层次过深 ,每调用一次,函数的参数.局部变量等信息就压一次栈,并且没有及时出栈. 局部变量体积太大 分析:每一个 JVM 线程都拥有 ...
- 春秋云镜 - CVE-2022-32991
靶标介绍: 该CMS的welcome.php中存在SQL注入攻击. 访问页面,先注册,使用邮箱加密码登录. bp抓包,后台挂上sqlipy然后去测welcome.php,常用的语句都没成功但过一会就有 ...
- Python——第五章:shutil模块
复制文件 把dir1的文件a.txt 移动到dir2内 import shutil shutil.move("dir1/a.txt", "dir2") 复制两个 ...